







实验内容与要求:
1. Spark Streaming基本知识总结
2. Spark Streaming的操作实践:
2.1 SparkStreaming的workCount案例
2.2 Spark Streaming与Flume和Kafka 的整合实践
1. Spark Streaming基本知识的总结
- Spark Streaming
是Spark软件栈中一个用于流计算的组件,它将数据流沿时间轴分片,再交给Spark对分片的数据进行批处理,所以SparkStreaming并没有真正地实现流计算,但也能满足许多场景下的流计算需求。其数据来源可以是文件系统、socket、Kafka、Flume等。 - 基本概念:
1.Dstream:离散数据流,基本数据类型,只能通过外部接入的数据流或经过对其他Dstream对象的转换操作得到。
2.Dstream graph:Dstream对象之间的依赖关系称为Dstream graph - Dstream支持的操作:
1.支持大部分RDD的转换操作
2.窗口操作
3.输出操作 - Spark Streaming 的架构
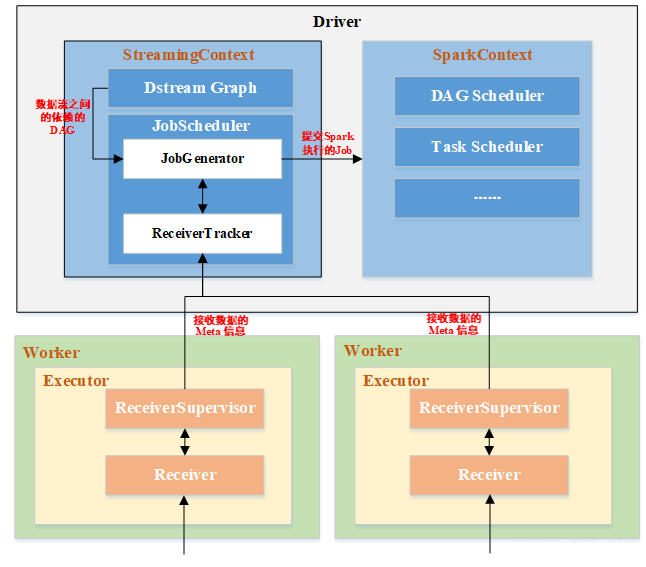
DstreamGraph:用于保存DStream和DStream之间依赖关系等信息
JobScheduler:通过JobGenerator产生job并管理job,通过ReceiverTracker管理流数据接收器Receiver
Receive
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









