






本文记录各经典目标检测网络的主要特性,便于随时查找。
目录
SSD: Single Shot MultiBox Detector(2016)
Focal Loss for Dense Object Detection(RetinaNet,2017)
YOLOv3: An Incremental Improvement(2018)
CornerNet: Detecting Objects as Paired Keypoints(2018)
FCOS: Fully Convolutional One-Stage Object Detection(2019)
Probabilistic Anchor Assignment with IoU Prediction for Object Detection(2020)
YOLOX: Exceeding YOLO Series in 2021(2021)
You Only Look One-level Feature(2021)
SSD: Single Shot MultiBox Detector(2016)

网络结构:单阶网络,使用多层特征进行多尺度预测。检测头部分使用卷积操作在每个特征点处生成k个边框,输出通道数为k*(c+4),其中c为类别数,意味着各类别的置信度,4为边框相较于默认框(default box)的偏置(cx,cy,w,h)。每一个特征层default box的尺度由公式

决定,其中为0.2,
为0.9,m为特征层数量。设置默认的长宽比
,则default box的宽为
,高为
,并额外添加一个长宽比为1,尺度为
。因此每个特征点产生6个default box。
匹配策略:对gt与default box进行匹配。每个gt首先匹配其对应最高jaccard overlap的default box,然后匹配所有与任意gt的IoU大于阈值0.5的default box。简化了学习过程,使网络同时从多个box中学习。同时为了避免正负样本不均衡,对所有负样本的conf进行排序取其最高者,控制正负例比例为1:3.
训练过程:网络输出(l)与标签(g)的关联是基于default box(d)的,损失函数包括置信度损失和定位损失
两部分。具体的定位损失计算为:

置信度损失为softmax损失:

Focal Loss for Dense Object Detection(RetinaNet,2017)

网络结构:采用了ResNet + Feature Pyramid Network (FPN)结构和anchor预设。检测头对每层特征层后面加两个全卷积网络FCN,其共享结构但不共享参数,分别进行cls和reg。每层特征的strides从32到512,预设anchor三种长宽比,三个尺度
,因此每层有A=9个anchor,尺度范围从32到813.每个特征点最终输出通道数为A*(c+4)。
匹配策略:将IoU大于0.5的anchor与gt匹配,将IoU小于0.4的记为背景。对于IoU在[0.4, 0.5)之间的anchor训练过程中忽略不计。
训练过程:边框回归通过计算anchor与匹配gt的偏置。对置信度使用Focal Loss,实验中使用
![]()
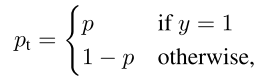
推理阶段:为了提高速度,对每层输出以阈值0.05过滤后解码前1k得分的anchor,然后集合所有层的结果以阈值0.5进行NMS。
YOLOv3: An Incremental Improvement(2018)
网络结构:提出Darknet-53作为主干网络,并使用FPN在三个尺度上检测目标。使用K-Means聚类产生9个预设框。对COCO数据集结果为(10×13), (16×30), (33×23), (30×61), (62×45), (59× 119), (116 × 90), (156 × 198), (373 × 326),将其分到三个尺度,因此各尺度的输出通道数为3*(c+1+4)。
匹配策略:对于置信度,对每个gt匹配其IoU最高的先验框。然后对于其他先验框,若其与gt的IoU大于阈值0.5,则在训练过程中忽略,否则为负例。
训练过程:网络输出转换到输出边框的过程为:

其中t为网络输出,p为先验anchor,b为最终输出结果。计算时将gt通过上式反转得到
,然后计算
。分类损失
使用logistic+BCELoss。
CornerNet: Detecting Objects as Paired Keypoints(2018)
网络结构:主干网络采用Hourglass network,其后添加两个预测模块,其包括corner pooling模块,分别预测左上角点和右下角点的热力图、两个点的embedding关系、以及边框offsets。其中corner热力图通道数为c,offsets为1,即所有类别共享边框偏置。embedding为向量,文中设定维度为1,目的是使同一gt的embedding距离更小,不同gt的距离更大。

匹配策略:对每个gt,只有两个corner为正例,其余为负例。同时通过一个2d高斯函数来减少gt角点附近区域点的loss值,其中xy为gt角点位置,
为1/3半径,半径内的角点产生的边框至少与gt有0.3的IoU。
训练过程: 热力图即为置信度,使用Focal Loss的一种变体:

offsets使用smooth L1 Loss。Embedding使用pull和push来进行训练:

附:Corner pooling和作者对Hourglass网络的改进暂未记录。
Objects as Points(2019)
网络结构:核心思想是基于中心点进行目标检测。主干网络可以选择ResNet、DLA、Hourglass等,下采样倍数为4.输出为关键点热力图、偏置和边框宽高。
匹配策略:产生关键点热力图,1表示检测到关键点,0表示背景。每个gt的关键点使用高斯核函数
分布到热力图上。
训练过程:关键点热力图的目标为gt的高斯核,损失由下式计算:

中心点偏置和尺度均使用L1loss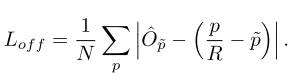 ,其中
,其中为该点坐标,
为输出值。
推理阶段:选择热力图中比周围8个点都高的极大值并保留前100个作为结果,因此不需要NMS操作。
FCOS: Fully Convolutional One-Stage Object Detection(2019)
网络结构:主干网络ResNet-50+FPN。其中由主干网路的
经过1*1卷积和top-down连接,
通过在
上使用stride=2的卷积层产生,因此最终P3-7的stride分别为8,16,32,64,128。 每个特征层后面加四个卷积层来进行分类和回归。网络基于点而不是anchor框来进行预测,每个特征点产生四个坐标,其分别对应该点到gt框四条边的距离
,因此不同层最后得到距离时尺度不同,因此引入一个可学习的E指数变换
。

匹配策略:把包含在gt框内的特征带即为正例。这样做带来两个问题:1)考虑到在大尺度特征图上stride较大可能漏掉很多目标,因此作者提出使用FPN进行多尺度预测,限制每一层预测的尺度范围。对于层i,其回归的边框满足,其中
用来将gt按照尺度分给不同层。如果一个点匹配到多个gt,则取最小的gt作为目标;2)一个框内所有特征点均与之匹配,则边界处会引入很多低质量的预测框,因此作者引入了分支Center-ness,计算方式为

中心度衡量一个点距离gt中心的距离大小,用BCELoss训练。测试时使用中心度乘以分类分数。
ultralytics / yolov5(2020)
网络结构:使用Focus+CSPDarknet-53+SPP+PANet+yolov3Head组成网络。anchor仍然由K-means聚类产生9个先验框,分至三个特征层。
匹配策略:基于三个特征层各自设置的三个默认anchor进行尺度区分。正例anchor要满足两个条件:1)该anchor与gt的宽高比值差距小于4倍;2)anchor中心点位于gt中心的三近邻处。

训练过程:由于匹配策略的特殊性,输出中心坐标回归的范围应位于(-0.5, 1.5)之间,宽高在0~4anchor之间。网络输出与最终结果中间的关系为:
然后计算所有匹配anchor与相应gt之间的CIoU作为,conf和cls均使用Sigmoid+BCELoss。相应的1-CIoU作为
。
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection(ATSS,2020)
网络结构:匹配算法是该文章核心,其可以使用到任意的网络结构中,只对训练过程作用。
匹配策略:如下图。基本思路为:首先根据中心距离选择k个距离gt最近的anchor组成预选集,然后计算预选anchor与gt的IoU,求出均值和标准差加起来作为阈值。然后以该IoU与阈值比较和中心点是否位于gt框内为标准筛选预选集,留下来的即为正例。

Probabilistic Anchor Assignment with IoU Prediction for Object Detection(2020)
匹配策略:如下图。基本思路为:第一部筛选:对于某个gt,选出与其IoU最大的anchor;第二步:对每层输出,考虑cls和iou,选择其中K个于gt最接近的anchor;第三步:对剩余anchor的得分使用GMM建模得到两个高斯分布,确定阈值并划分正负。
注意点:1)anchor的得分同时考虑其类别和box,而不是置信度,计算公式如下图:

2)得到两个高斯分布后阈值选取有四种方式,下下图,实验表明图c效果最好;
3)文中选用EM算法求解GMM模型。


YOLOX: Exceeding YOLO Series in 2021(2021)

网络结构:基于YOLOv3-SPP,使用解耦检测头。并将yolo转换为anchor-free,使每个特征点直接输出两个偏置和预测框的宽高。
匹配策略:提出SimOTA:首先以是否在gt框内和是否在gt中心3*3区域内来筛选anchor点。然后计算这些anchor与gt的cost,然后对每个gt选择k个最小cost的pred作为正例,其余为负例。如果有一个pred匹配到多个gt则只保留cost最小的那个gt。其中的cost计算公式为:
其中为分类BCELoss,
为对数的iou。
训练过程:边框回归reg训练使用IoU损失,obj和cls使用BCEWithLogitsLoss。使用了MixUp和Mosaic增强,并在最后15个epoch关闭。
You Only Look One-level Feature(2021)
网络结构: 包括三个部分:backbone、encoder和decoder。主干网络使用ResNet和ResNeXt,并只用C5层(通道数2048,下采样率为32)作为输出;Encoder通过1*1卷积和3*3卷积把通道数降至512,然后加上residual blocks,其包括不同dilation rates的卷积以实现检测不同尺度的目标,如下图;Decoder分为cls和reg两个检测头,分别有2和4个卷积层。


匹配策略:由于使用了SiSo encoder,anchor数量大量减少。在这种稀疏情况下,大gt目标容易获得更多正例匹配而小目标易被忽略。因此作者提出了Uniform Matching,即对每个gt匹配于其最近的k个anchor。同时忽略IoU>0.7的负例和IoU<0.15的正例。
训练过程:加入random shift操作,即随机将图像沿四个方向平移32像素,以增加gt匹配到好anchor的概率。此外限制anchor中心的偏移在32像素之内。















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









