







 本文详细介绍了KNN(K近邻)算法,包括其基本思想、距离度量(如欧氏距离、曼哈顿距离等)和相似度度量。KNN算法在图像处理中用于分类,通过计算新样本与训练样本的距离,选取最近的K个邻居进行投票以决定新样本的类别。文章还探讨了K值选择、样本权重、算法优缺点以及解决计算复杂度的方法。
本文详细介绍了KNN(K近邻)算法,包括其基本思想、距离度量(如欧氏距离、曼哈顿距离等)和相似度度量。KNN算法在图像处理中用于分类,通过计算新样本与训练样本的距离,选取最近的K个邻居进行投票以决定新样本的类别。文章还探讨了K值选择、样本权重、算法优缺点以及解决计算复杂度的方法。
1、kNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
2. 最近邻法:下面通过一个简单的例子说明一下KNN的出现:最近邻法是KNN算法的前身,最近邻法为了判别未知样本的类别,把全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本的唯一依据。
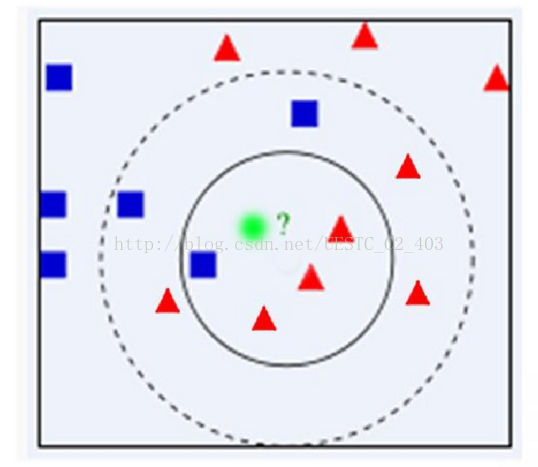
由上面的例子说明,绿色的用最近邻算法该分为哪一类,蓝色的,如果是用最近邻算法,但是很有可能蓝色的这个点是错误的,也就是被噪声干扰才这样,实际是红色这一类的,所以可能发现最近算法存在明显的缺陷,那就是对噪声过于敏感,为了解决这个问题,我们可以计算与它距离比较近的多个样本,提高算法鲁棒性,避免个别数据决定命运的情况,所以引进K近邻算法(KNN)。
3. KNN的基本思路:它是最近邻算法的一个延伸,选择未知样本在一定范围内确定个数的K个样本,该K个样本大多数属于哪一类型,就判定未知样本属于哪一类型。这K个样本的选择就是选择最相似(距离的话就是最近的距离)的K个样本。
算法实现步骤:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









