









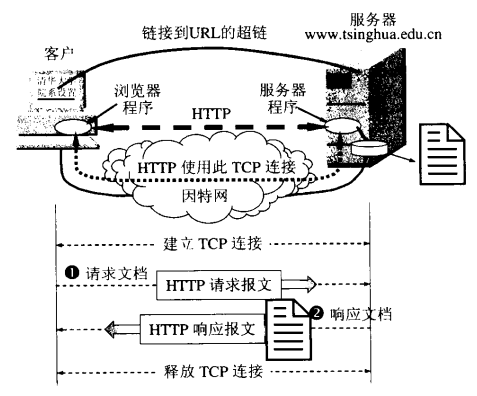
HTTP操作过程
- 建立TCP连接
- HTTP请求报文,请求文档
- HTTP响应报文,响应文档
- 释放TCP连接
HTTP版本
HTTP/1.0 缺点:非持续连接。每请求一个稳定,就要有两倍的RTT开销。
HTTP/1.1 优点:持续连接。服务器在发送响应后,在一段时间内保持这条连接。同一浏览器和该服务器可以继续在该连接上,传送后续的HTTP请求报文和响应报文。
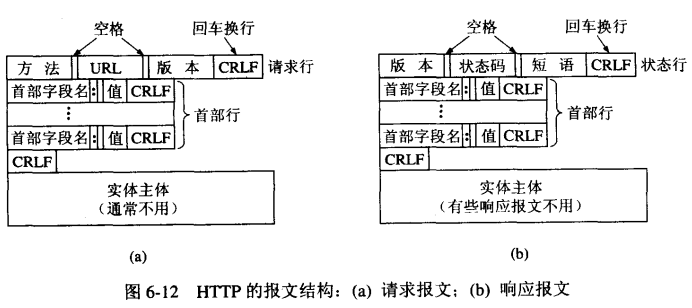
HTTP报文结构
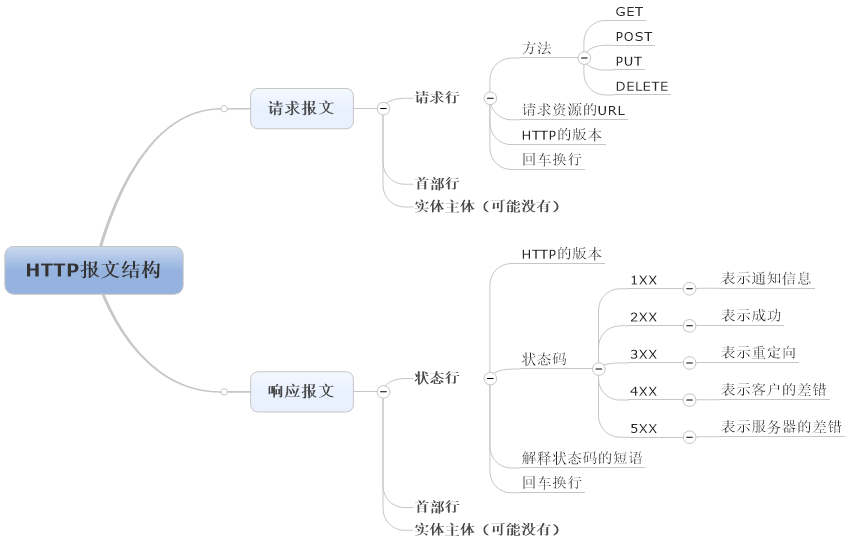
请求报文的方法
| 方法(操作) | 意义 |
|---|---|
| OPTION | 请求一些选项的信息 |
| GET | 请求读取由URL所标志的信息 |
| HEAD | 请求读取由URL所标志的信息的首部 |
| POST | 给服务器添加信息(注释等) |
| PUT | 在指明的URL下存储一个文档 |
| DELETE | 删除指明的URL所标志的资源 |
| TRACE | 用来进行环回测试的请求报文 |
| CONNECT | 用于代理服务器 |
HTTP请求报文的开始行:
GET http://www.baidu.com HTTP/1.1
响应报文的状态码
- 200:响应成功
- 301:永久性转移
- 302:暂时性转移
- 400:客户端有语法错误,不能被服务器识别
- 403:服务器收到请求,但拒绝提供服务
- 404:请求资源不存在
- 500:服务器内部错误
在浏览器输入网址,回车
- 浏览器分析URL
- 浏览器向DNS请求解析网址的IP地址
- 浏览器与服务器建立TCP连接(80端口)
- 浏览器发出取文件命令:GET /baidu.com
- 服务器给出响应,把文件发送给浏览器
- 释放TCP连接
- 浏览器显示网页
Cookie
HTTP是无状态的,但是某些时候,服务器希望识别用户。可以在HTTP中使用Cookie来跟踪用户。
- 用户A浏览某个网站,该网站服务器就A产生一个唯一的识别码,并在服务器的后端数据库产生一个项目。
- 在给A的HTTP响应报文中,添加Set-cookie的首部行。Set-cookie:123456
- A收到响应后,在特定cookie文件中添加一行:服务器主机名 + 识别码
- A继续浏览这个网站时,每一个HTTP请求报文,浏览器会从cookie文件中取出这个网站的识别码,放到首部行中:Cookie:123456
- 网站能够跟踪A在该网站的活动。
说明
- HTTP协议是无状态的,简化了服务器的设计,使服务器更容易支持大量并发的HTTP请求。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









