






 本文详细介绍了如何准备YOWOv2的开发环境,包括Python虚拟环境创建、依赖包安装,以及UCF101-24数据集的准备。复现过程中涉及的代码修改和常见问题的解决方案也进行了分享。
本文详细介绍了如何准备YOWOv2的开发环境,包括Python虚拟环境创建、依赖包安装,以及UCF101-24数据集的准备。复现过程中涉及的代码修改和常见问题的解决方案也进行了分享。
一、代码、环境和数据集准备
1、代码
YOWOv2的官方代码已经开源在Github上了,可以通过下面的链接下载源码。
https://github.com/yjh0410/YOWOv2
2、环境
下载完毕后,创建python版本为3.6的新虚拟环境:
conda create -n yowov2 python=3.6创建环境完毕后,进入所创建的环境中:
conda activate yowov2
运用cd命令转到项目所在文件夹(先输这个指令,这个命令中的X代表着你项目所在的磁盘):
cd /d X:
cd xxx/xxxx/xxxx安装所需要的包:
pip install -r requirements.txt如果下载过慢,建议将config改成清华源镜像,具体步骤请移步其他博客。至此,复现YOWOv2所需的环境已经搭建完毕。
3、数据集准备
YOWOv2复现仍然使用UCF101-24数据集,读者可自行在项目文件中README.MD文件中找到数据集的下载链接,亦可通过下方百度网盘链接进行下载。
获取链接: https://pan.baidu.com/s/11GZvbV0oAzBhNDVKXsVGKg
提取码: hmu6
二、复现过程
在我们准备好环境,代码和数据集后,我们就可以着手进行复现了
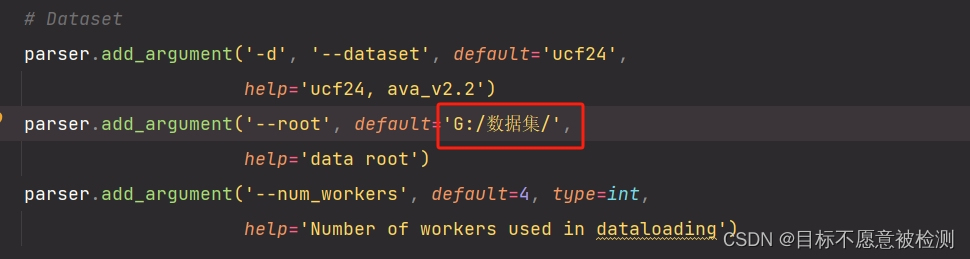
1、数据集根目录更改
源码的数据集目录和我们存放的目录不一致,所以我们要进行修改,在dataset/ucf_jhmdb.py中,修改如下图所示的地方,修改为自己存放UCF24数据集的目录。

为了检测正确性,请运行ucf_jhmdb.py,如果得到下图,则证明数据集配置正确。
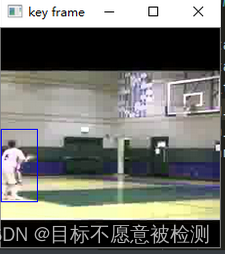
2、开始训练
在训练之前,我们需要对train.py进行配置修改:

下图之所以将version修改为yowo_v2_nano,是因为YOWOv2家族有很多分支,我这里采用的是nano,也是YOWOv2家族最轻量化的一个版本。
如果你的电脑有GPU,则将下图中标记的地方改为True,训练速度可提升2-3倍,没有GPU的读者无需修改(如何查看自己有没有GPU,请自行百度一下)

训练完成后,所得到的权重会存放在/weights/ucf24/yowo_v2_nano文件夹中,文件后缀名为.pth
3、验证YOWOv2
为了验证我们所训练的权重在视频检测中的正确性,我们需要下载一个包含动作的视频,然后在demo.py文件中进行配置修改。
将下图中的标记处修改为自己视频的存放目录:

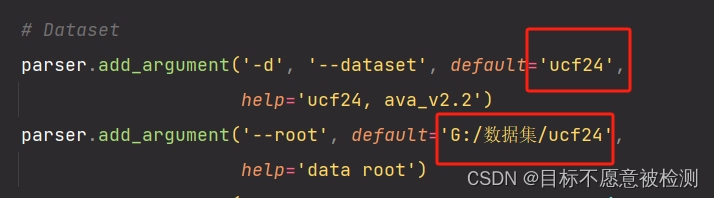
下图源码写的是AVA,这里我们用的是ucf24数据集,所以改为ucf24:

这里将default修改成刚刚自己训练模型的版本:

这里修改为自己刚刚训练好的权重的存放目录(其中./代表相对目录):

修改完上述配置后,即可运行demo.py,检测完成后的视频存放在下方的目录中:
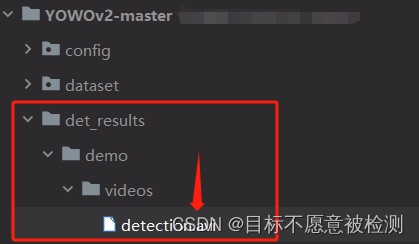
下面就是检测完成后的视频截图:


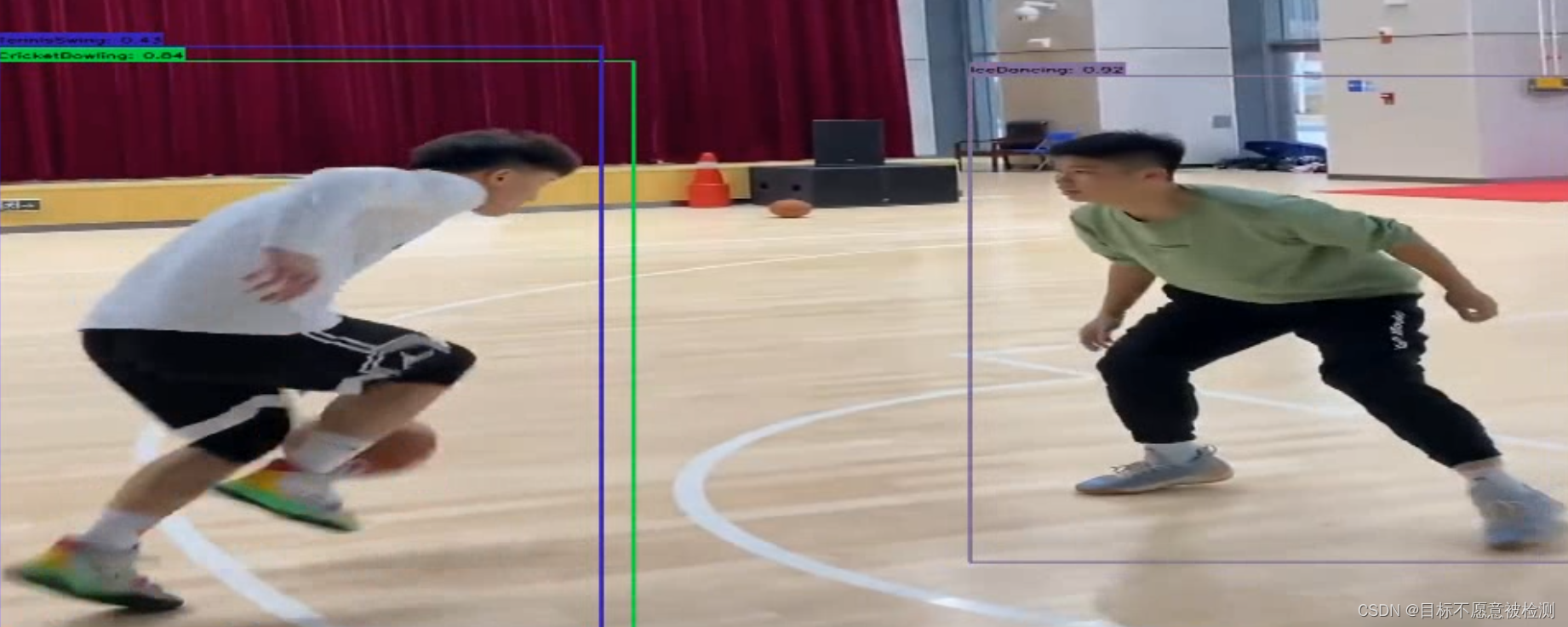
三、遇到的问题
在运行的过程中,遇到了很多的问题,我将我遇到的问题和解决方式写在下方(下面所有的解决措施均基于torch=1.9.1+cu111,torchvision=0.10.1+cu111的基础上,版本不对的读者请自行更换torch版本)
1、Torch not compiled with CUDA enabled(用GPU的读者注意,CPU读者可忽略)
这是说当前的虚拟环境中没有安装GPU版本的torch,解决方法就是重新安装GPU版本的torch,进入虚拟环境yowov2后,运行下方指令:
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html安装完成后即代表GPU版本的torch已经安装到此虚拟环境中了。
2、AttributeError:model "torch.jit. has no attribute ‘unused‘
说明当前torch版本和torchvision版本不对应,解决方案如上所示。
3、ModuleNotFoundError: No module named 'torch.fx'
也是说明torch版本不匹配,解决方案如1。
4、"xxx.pt is a zip archive(did you mean to use torch.jit.load()?)"
这个错误极有可能出现在自己没有训练,直接使用别人的权重文件的读者中,这是由于权重是在torch>=1.6版本上训练的,而运行的torch版本<1.6,解决方式就是将自己环境中的torch版本升级到1.6以上。
pip install torch==xxxxx -f https://download.pytorch.org/whl/torch_stable.html5、FileNotFoundError: [Errno 2] No such file or directory: 'G:/XXX/ucf24\\ucf24\\trainlist.txt'
这个错误频繁出现在运行train.py的过程中,这是因为路径冲突,应该在ucf24的上一级目录就截止,如下图所示:
四、总结
目前时序动作检测在各大会议和顶刊上发表的论文很少,而且网上对于YOWO的介绍和复现少之又少,希望大家在时序动作检测过程中遇到了任何困难都不要灰心,我们一起度过这个难关!
五、参考链接
https://blog.csdn.net/weixin_44769214/article/details/108188126
https://www.cnblogs.com/HuangYJ/p/13844757.html
已解决:Torch not compiled with CUDA enabled_Jenny300的博客-CSDN博客
导入torchvision时出现:AttributeError: module 'torch.jit' has no attribute 'unused'错误 - 知乎
解决ModuleNotFoundError: No module named ‘torch.fx‘_小雲啊的博客-CSDN博客

















 7934
7934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









