







一、源码下载
二、环境配置
1、基础环境
python=3.8,pytorch=1.9.1+cu111,torchvision=1.10.1+cu111
conda create -n rcnn python=3.8 -yconda activate rcnn
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html2、其他依赖包安装
pip install -r requirements.txt3、预训练权重下载
将预训练权重下载至代码的根目录

三、制作自己的数据集
数据集依然采用的是VOC格式的数据集
1、数据集存放
将数据集所有的xml标签放在VOCdevkit\VOC2007\Annotations里,所有的图片文件(强烈建议图片格式为jpg)放在VOCdevkit\VOC2007\JPEGImages里。
2、数据集划分
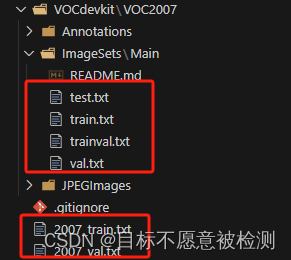
根据自己的需要修改训练集和验证集的比例,运行voc_annotation.py,会在根目录生成2007_train.txt和2007_val.txt,以及会在VOCdevkit\VOC2007\ImageSets\Main文件夹下生成三个txt文件,分别为train.txt,val.txt,trainval.txt和test.txt
3、建立标签文件
在model_data文件夹内建立mydata.txt,里面存放你所有的标签名称(按顺序)

四、修改参数进行训练
在train.py文件内修改参数
1、显卡
默认0卡,多卡训练请修改,双卡为[0, 1]、三卡为[0, 1, 2]

2、标签路径
修改为三.3中的标签文件路径

3、预训练权重路径
![]()
4、 调整batch和线程数


5、训练集、测试集图片索引文件

6、开始训练
python train.py














 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









