







 本文介绍了一个从文件收集数据通过Flume发送到Kafka,再由Kafka流转至HDFS的具体配置方案。涵盖了Flume和Kafka的基本配置、自定义拦截器实现精确时间记录等功能。
本文介绍了一个从文件收集数据通过Flume发送到Kafka,再由Kafka流转至HDFS的具体配置方案。涵盖了Flume和Kafka的基本配置、自定义拦截器实现精确时间记录等功能。
文章目录
1、前言
Flume基础:https://yellow520.blog.csdn.net/article/details/112758144
Kafka基础:https://yellow520.blog.csdn.net/article/details/112701565
2、架构图
2.1、前半part:File->Flume->Kafka
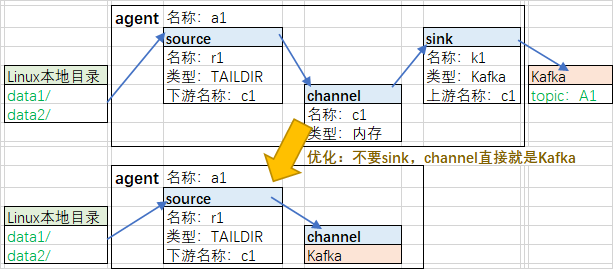
2.2、后半part:Kafka->Flume->HDFS

2.3、总

3、代码
mkdir -p /opt/test/data
3.1、File->Flume->Kafka
vi /opt/test/ffk
# 定义agent、source、channel名称,并绑定关系
a1.sources = r1
a1.channels = c1
a1.sources.r1.channels = c1
# source
a1.sources.r1.type = TAILDIR
# 指定文件组的名称
a1.sources.r1.filegroups = f1
# 指定组监控的目录(支持正则表达式)
a1.sources.r1.filegroups.f1 = /opt/test/data/.+txt
# 指定断点续传文件
a1.sources.r1.positionFile = /opt/test/data/position.json
# 指定一个批次采集多少数据
a1.sources.r1.batchSize = 100
# channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
# kafka服务地址
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092
# 主题
a1.channels.c1.kafka.topic = A1
# 数据写入时,是否以event格式写入,false表示只写body
a1.channels.c1.parseAsFlumeEvent = false
3.2、Kafka->Flume->HDFS
vi /opt/test/kfh
# 定义agent、channel、source、sink名称,并关联
a2.sources = r2
a2.channels = c2
a2.sinks = k2
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
# source
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
# kafka服务地址
a2.sources.r2.kafka.bootstrap.servers = hadoop102:9092
# 主题
a2.sources.r2.kafka.topics = A1
# 消费者组
a2.sources.r2.kafka.consumer.group.id = g1
# 消费者组第一个消费topic的数据的时候从哪里开始消费
a2.sources.r2.kafka.consumer.auto.offset.reset = earliest
# source从Kafka拉消息的批次大小
a2.sources.r2.batchSize = 50
# 拦截器
a2.sources.r2.interceptors = i1
a2.sources.r2.interceptors.i1.type = a.b.c.TimeInterceptor$Builder
# channel
a2.channels = c2
# channel类型:内存(断电可能会丢失数据)
a2.channels.c2.type = memory
# sink
a2.sinks.k2.type = hdfs
# 指定数据存储目录
a2.sinks.k2.hdfs.path = hdfs://hadoop100:8020/kf/%Y-%m-%d
# 指定文件的前缀
a2.sinks.k2.hdfs.filePrefix = log-
# 指定滚动生成文件的时间间隔
a2.sinks.k2.hdfs.rollInterval = 30
# 指定滚动生成文件的大小(133169152=127*1024*1024<128M)
a2.sinks.k2.hdfs.rollSize = 133169152
# 写入多少个event之后滚动生成新文件,通常选0,表示禁用
a2.sinks.k2.hdfs.rollCount = 0
# 文件写入格式:SequenceFile-序列化文件、DataStream-文本文件、CompressedStream-压缩文件
a2.sinks.k2.hdfs.fileType = DataStream
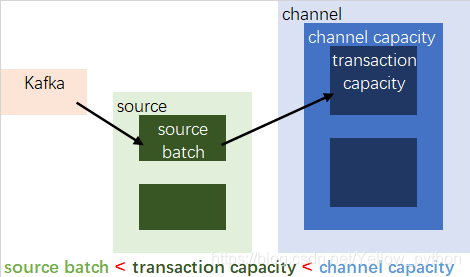
<注意:
因为source的batch size默认值1000,channel的transaction capacity默认值100
所以要把source’s batch size调小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











