







一、什么是数据仓库
1.1 数据仓库概念
数据仓库(Data Warehouse),可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。
1.2 数据仓库特点
1.2.1面向主题
普通的操作型数据库主要面向事务性处理,而数据仓库中的所有数据一般按照主题进行划分。主题是对业务数据的一种抽象,是从较高层次上对信息系统中的数据进行归纳和整理。
面向主题的数据可划分成两部分----根据原系统业务数据的特点进行主题的抽取和确定每个主题所包含的数据内容。例如客户主题、产品主题、财务主题等;而客户主题包括客户基本信息、客户信用信息、客户资源信息等内容。分析数据仓库主题的时候,一般方法是先确定几个基本的主题,然后再将范围扩大,最后再逐步求精。
1.2.2集成性
面向操作型的数据库通常是异构的、并且相互独立,所以无法对信息进行概括和反映信息的本质。而数据仓库中的数据是经过数据的抽取、清洗、切换、加载得到的,所以为了保证数据不存在二义性,必须对数据进行编码统一和必要的汇总,以保证数据仓库内数据的一致性。数据仓库在经历数据集成阶段后,使数据仓库中的数据都遵守统一的编码规则,并且消除许多冗余数据。
1.2.3稳定性
数据仓库中的数据反映的都是一段历史时期的数据内容,它的主要操作是查询、分析而不进行一般意义上的更新(数据集成前的操作型数据库主要完成数据的增加、修改、删除、查询),一旦某个数据进入到数据仓库后,一般情况下数据会被长期保留,当超过规定的期限才会被删除。
1.2.4反映历史变化(即时变性)
数据仓库不断从操作型数据库或其他数据源获取变化的数据,从而分析和预测需要的历史数据,所以一般数据仓库中数据表的键码(维度)都含有时间键,以表明数据的历史时期信息,然后不断增加新的数据内容。通过这些历史信息可以对企业的发展历程和趋势做出分析和预测。数据仓库的建设需要大量的业务数据作为积累,并将这些宝贵的历史信息经过加工、整理,最后提供给决策分析人员,这是数据仓库建设的根本目的。
1.3 数据仓库发展历程
数据仓库的发展大致经历了这样的三个过程:
简单报表阶段、数据集市阶段、数据仓库阶段;通过数据仓库建设的发展阶段,我们能够看出,数据仓库的建设和数据集市的建设的重要区别就在于数据模型的支持。因此,数据模型的建设,对于我们数据仓库的建设,有着决定性的意义。
1.4 数据仓库意义
建立公司统一数据中心
为数据BP、运营人员提供数据支持
为领导提供决策支持
1.5 数据库和数据仓库的区别
1.5.1数据库
是一种逻辑概念,用来存放数据的仓库,通过数据库软件来实现,数据库由许多表组成,表是二维的,一张表里面可以有很多字段,数据库的表,在与能够用二维表现多维关系。
1.5.2数据仓库
是数据库概念的升级。从逻辑上理解,数据库和数据仓库没有区别,都是通过数据库软件实现的存放数据的地方,只不过从数据量来说,数据仓库要比数据库更庞大得多。数据仓库主要用于数据挖掘和数据分析,辅助领导做决策。
数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别。
1.5.3 对比
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。

1.6 数据仓库和数据集市的区别
数据仓库是面向整个集团组织的数据,数据集市是面向单个部门使用的。可以认为数据集市是数据仓库的子集,也有人把数据集市叫做小型数据仓库。数据集市通常只涉及一个主题领域,例如市场营销或销售。因为它们较小且更具体,所以它们通常更易于管理和维护,并具有更灵活的结构。
二、离线数据仓库架构
2.1 数据调研
涉及业务调研、需求调研和数据调研。
2.2 数据采集
2.2.1 日志数据
包括埋点日志(浏览日志、点击日志)、服务日志(应用访问日志、接口调用日志)、NG日志、采集字段等
2.2.2 业务数据
包括来自MySQL、MongoDB、Oracle等
2.2.3 爬虫数据
如竞品数据、维度数据
2.2 ETL
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据
2.2.1 数据抽取(Extract)
主要是从业务库把数据抽取到数据仓库或者把日志采集到数据仓库
2.2.1.1 业务数据抽取
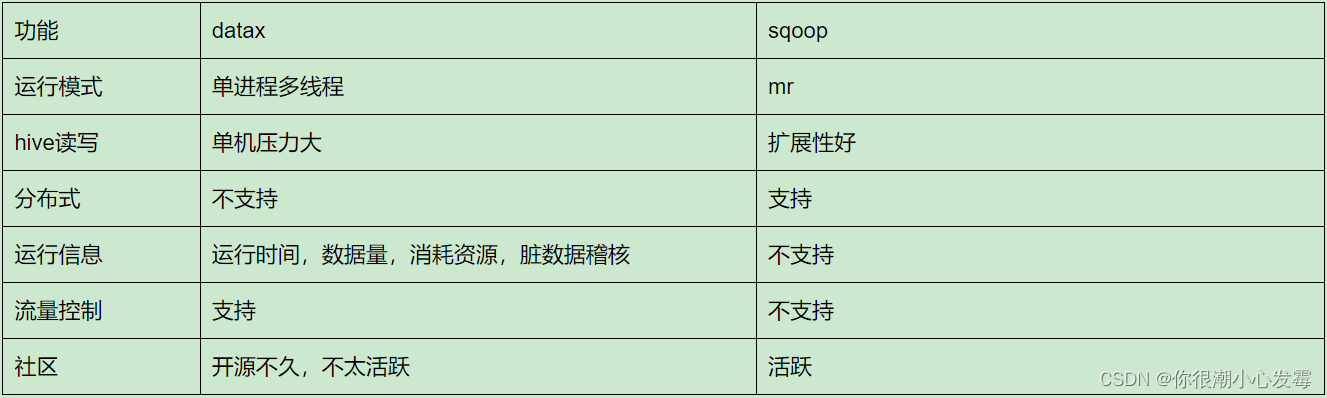
sqoop和datax作为2款优秀的数据同步工具:
1)sqoop
sqoop 是 apache 旗下一款Hadoop中的各种存储系统(HDFS、HIVE、HBASE) 和关系数据库(mysql、oracle、sqlserver等)服务器之间传送数据的工具;
导入数据:MySQL、Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统;
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等,Sqoop 的本质还是一个命令行工具。
底层工作机制:将导入或导出命令翻译成 MapReduce 程序来实现。在翻译出的 MapReduce 中主要是对InputFormat 和OutputFormat 进行定制
2)datax
DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
2.2.1.2 日志采集
2.2.1.2.1 flume
Apache Flume是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务。flume具有高可用,分布式和丰富的配置工具,其结构如下图所示:
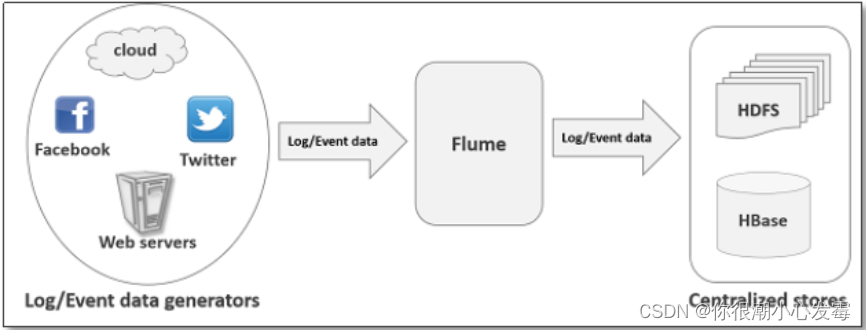
Flume作为数据采集工具,是一个分布式、可靠、和高可用的海量日志采集、汇聚和传输的系统。Flume可以采集文件,socket数据包(网络端口)、文件夹、kafka、mysql数据库等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中。安装部署、修改配置文件即可使用。
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。对于每一个Agent来说,它就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发往下一个目的地。
采集需求案例:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
根据需求,首先定义以下3大要素:
采集源,即source——监控文件内容更新 : exec ‘tail -F file’
下沉目标,即sink——HDFS文件系统 : hdfs sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path =hdfs://hadoop1:9000/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
2.2.1.2.2 logstash
Logstash是一个开源的服务器端数据处理管道,它可以同时从多个源中提取数据,对其进行转换,然后将其发送其他存储。主要由input filter和output组成。
2.2.1.2.3 对比
l Logstash和flume都能作为日志采集工具
l Logstash是由ruby开发,flume使用java语言开发
l Logstash每起一个进程,默认占用1G内存,如果进程起的多的话给应用服务器带来很大的压力
2.2.2 数据清洗转换(Cleaning、Transform)
数据清洗的任务是过滤那些不符合要求的数据,数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些业务规则的计算。
2.2.2.1 ID-MAPPING
2.2.2.2 数据清洗
单位统一,比如金额单位统一为元
字段类型统一
注释补全
空值用默认值或者中位数填充
时间字段格式统一,如2020-10-16,2020/10/16,20201016统一格式为2020-10-16
过滤没有意义的数据等等
2.2.2.3 数据转换
下面会介绍模型建设
2.2.3 数据加载(load)
数据同步到其他存储系统,如mysql,hbase
2.3 数据存储
数据存储在hdfs,包含元数据和主数据的存储
2.4 数据应用
数据同步到mysql提供接口
数据同步到需求方mysql库直接调用
数据同步到kylin(olap)做预计算,为需求方提供数据做多维分析
数据同步到hbase提供接口服务
数据同步到pg提供数据
用户画像
推荐系统
运营系统
报表系统
业务系统
BI可视化
2.5 简单架构
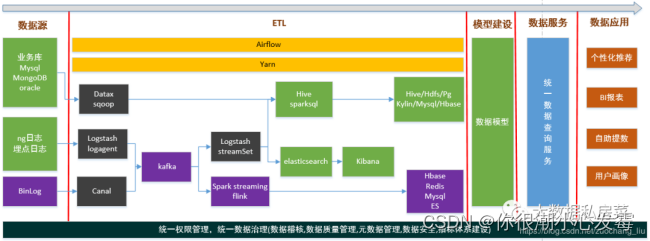
2.5.1数仓分层思想和标准
数据仓库的特点是本身不生产数据,也不最终消费数据。按照数据流入流出数仓的过程进行分层就显得水到渠成。
数据分层每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层,操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
企业在实际运用中可以基于这个基础分层之上添加新的层次,来满足不同的业务需求
2.5.2数仓三层架构
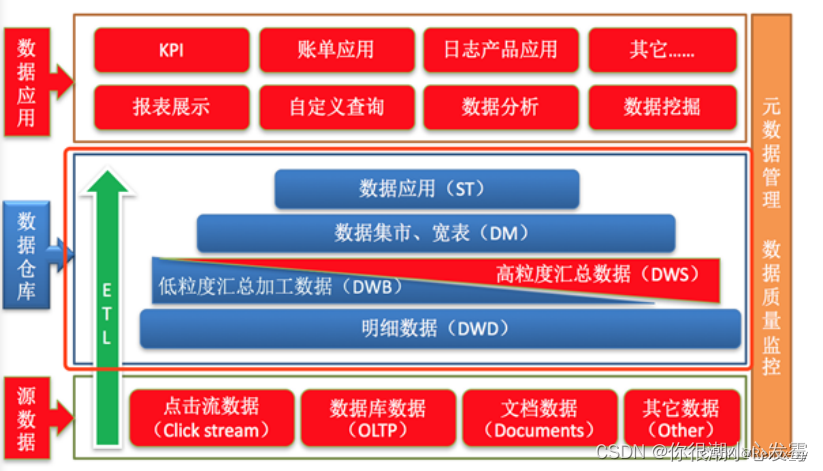
1、ODS层(Operation Data Store)
直译:操作型数据层。也称为源数据层、数据引入层、数据暂存层、临时缓存层。此层存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到数仓的职责,和数据源系统进行解耦合,同时记录基础数据的历史变化。
2、DW层(Data Warehouse)
数据仓库层。内部具体包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念思想,建立整个企业一致性维度。
公共汇总粒度事实层(DWS、DWB):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型
明细粒度事实层(DWD): 将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
3、数据应用层(DA或ADS)
面向最终用户,面向业务定制提供给产品和数据分析使用的数据。包括前端报表、分析图表、KPI、仪表盘、OLAP专题、数据挖掘等分析。
2.5.3软件选型
数据采集:DataX、Flume、Sqoop、Logstash、Kafka
数据存储:HDFS、HBase
数据计算:Hive、MapReduce、Tez、Spark、Flink
调度系统:Airflow、azkaban、Oozie
元数据管理:Atlas
数据质量管理:Griffin
即席查询(快速):Impala、Kylin、ClickHouse、Presto、Druid
其他:MySQL
框架、软件尽量不要选择最新的版本,选择半年前左右稳定的版本
三、数据建模
3.1 前言
3.1.1 什么是数据建模
数据建模简单来说就是基于对业务的理解,将各种数据进行整合和关联,并最终使得这些数据可用性,可读性增强,让使用方能快速的获取到自己关心的有价值的信息并且及时的作出响应,为公司带来效益。
3.1.2 为什么要数据建模
数据建模是一套方法论,主要是对数据的整合和存储做一些指导,强调从各个角度合理的存储数据。
· 进行全面的业务梳理,改进业务流程。
通过业务模型的建设,我们应该能够全面了解该单位的业务架构图和整个业务的运行情况,能够将业务按照特定的规律进行分门别类和程序化,同时,帮助我们进一步的改进业务的流程,提高业务效率,指导我们的业务部门的生产。
· 建立全方位的数据视角,消灭信息孤岛和数据差异。
通过数据仓库的模型建设,能够为企业提供一个整体的数据视角,不再是各个部门只是关注自己的数据,而且通过模型的建设,勾勒出了部门之间内在的联系,帮助消灭各个部门之间的信息孤岛的问题,更为重要的是,通过数据模型的建设,能够保证整个企业的数据的一致性,各个部门之间数据的差异将会得到有效解决。
· 解决业务的变动和数据仓库的灵活性。
通过数据模型的建设,能够很好的分离出底层技术的实现和上层业务的展现。当上层业务发生变化时,通过数据模型,底层的技术实现可以非常轻松的完成业务的变动,从而达到整个数据仓库系统的灵活性。
· 帮助数据仓库系统本身的建设。
通过数据仓库的模型建设,开发人员和业务人员能够很容易的达成系统建设范围的界定,以及长期目标的规划,从而能够使整个项目组明确当前的任务,加快整个系统建设的速度。
有了合适的数据模型,是会带来很多好处的:
查询使用性能提升
用户效率提高,改善用户体验
数据质量提升
降低企业成本
…
所以大数据系统需要数据模型方法来更好的组织和存储,以便在性能,成本,效率和质量之间取的平衡。
3.2 建模工具
PowerDesigner:
Power Designer 是Sybase公司的CASE工具集,使用它可以方便地对管理信息系统进行分析设计,他几乎包括了数据库模型设计的全过程。利用Power Designer可以制作数据流程图、概念数据模型、物理数据模型,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









