






前言
- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、我的環境
-
電腦系統:Windows 10
-
顯卡:NVIDIA Quadro P620
-
語言環境:Python 3.7.0
-
開發工具:Sublime Text,Command Line(CMD)
-
深度學習環境:Tensorflow 2.5.0
二、套件準備
# 開源的機器學習框架
import tensorflow as tf
# tensorflow.keras 是 TensorFlow 中的一個 API,用於構建和訓練神經網絡模型
from tensorflow.keras import datasets, layers, models
# 用於繪製數據可視化的庫
import matplotlib.pyplot as plt
# 供了高效的多維數組(通常稱為 numpy 數組)操作和數學函數
import numpy as np三、GPU設置
# 列出系統中的GPU裝置列表
gpus = tf.config.list_physical_devices("GPU")
# 如果有GPU
if gpus:
# 挑選第一個 GPU
gpu0 = gpus[0]
# 僅在需要的時候分配記憶體
tf.config.experimental.set_memory_growth(gpu0, True)
# 將 GPU0 設置為 TensorFlow 中可見的唯一 GPU ,將運算限制在特定的 GPU 上 四、導入數據
# 導入CIFAR-10數據集
# train_images = 訓練集圖片
# train_labels = 訓練集標籤
# test_images = 測試集圖片
# test_labels = 測試集標籤
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 印出數據形狀
print("訓練集圖片的形狀:", train_images.shape) # (50000, 32, 32, 3)
print("訓練集標籤的形狀:", train_labels.shape) # (50000, 1)
print("測試集圖片的形狀:", test_images.shape) # (10000, 32, 32, 3)
print("測試集標籤的形狀:", test_labels.shape) # (10000, 1)  datasets.cifar10.load_data() 是 TensorFlow 提供用於加載 CIFAR-10 數據集的函式,此數據集常用於圖像分類任務上,包含了 10 個類別的彩色圖像,每個類別包含了 6000 張尺寸 32x32 像素的圖像,共計 60000 張圖
datasets.cifar10.load_data() 是 TensorFlow 提供用於加載 CIFAR-10 數據集的函式,此數據集常用於圖像分類任務上,包含了 10 個類別的彩色圖像,每個類別包含了 6000 張尺寸 32x32 像素的圖像,共計 60000 張圖
圖像類別包括:飛機、汽車、鳥類、貓、鹿、狗、青蛙、馬、船、卡車
五、歸一化
# 將像素的值標準化成0~1區間內的數字
# 像素值通常介於0~255之間,所以直接除上255即可完成歸一化
train_images, test_images = train_images / 255.0, test_images / 255.0
# 印出
print('train_images:', train_images)
print('test_images:', test_images)
六、可視化
# 定義類別名稱
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck']
# 將訓練集前20張圖片作可視化處理
# 畫出大小為寬20*長10的圖(英吋)
plt.figure(figsize=(20,10))
# 繪製訓練集前20張圖,並在下方顯示對應的標籤(即類別)
for i in range(20):
# 將figure分成2行10列,繪製第+1個子圖
plt.subplot(2,10,i+1)
# 不顯示x軸
plt.xticks([])
# 不顯示y軸
plt.yticks([])
# 不顯示網格
plt.grid(False)
# cmap=plt.cm.binary参数指定使用二進制顏色映射,黑色表示低像素值,白色表示高像素值
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 設置x軸標籤為圖片對應的類別
plt.xlabel(class_names[train_labels[i][0]])
# 顯示圖片
plt.show()
七、建構CNN模型
# 創建並設置模型
model = models.Sequential([
# 創建一個卷積層,其中包含32個卷積核
# 每個卷積核的大小為3x3
# 使用ReLU激活函數作為該卷積層的激活函數
# 設置輸入形狀為(32, 32, 3),表示輸入圖像的高度為32像素,寬度為32像素,通道數為3(彩色圖像)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
# 創建一個最大池化層
# 池化窗口設置為2x2,即在每個2x2區域內取最大值
layers.MaxPooling2D((2, 2)),
# 創建一個卷積層,其中包含64個卷積核
# 每個卷積核的大小為3x3
# 使用ReLU激活函數作為該卷積層的激活函數
layers.Conv2D(64, (3, 3), activation='relu'),
# 創建一個最大池化層
# 池化窗口設置為2x2,即在每個2x2區域內取最大值
layers.MaxPooling2D((2, 2)),
# 創建一個卷積層,其中包含64個卷積核
# 每個卷積核的大小為3x3
# 使用ReLU激活函數作為該卷積層的激活函數
# 寫兩層一樣的卷積層是可以的,這層將會在上一層的輸出上進行操作,目的是希望能更好的捕捉圖像數據中的特徵
layers.Conv2D(64, (3, 3), activation='relu'),
# 將多維輸入數據平坦化成一維數組
# 將多維輸入數據(如卷積層的輸出)展平成一個一維數組,以便將其餵入全連接層
layers.Flatten(),
# 全連接層
# 有64個神經元
# 使用ReLU激活函數作為該全連接層的激活函數
layers.Dense(64, activation='relu'),
# 輸出層
# 有10個神經元
# 輸出預期結果
layers.Dense(10)
])
# 印出模型結構
model.summary() 
八、編譯模型
# 編譯模型的函數
# 編譯模型前要先進行配置,包括優化器(optimizer)、損失函數(loss function)、評估指標(metrics)
model.compile(
# 設置Adam優化器
optimizer='adam',
# 設置損失函數為交叉熵損失函數损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits = True,將y_pred轉化為概率(softmax),否則不進行轉換,通常情況下用True會讓結果更穩定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 設置評估指標
metrics=['accuracy'])九、訓練模型
# 訓練模型
history = model.fit(
# 訓練集圖片
train_images,
# 訓練集標籤
train_labels,
# 設置10個epoch(迭代次數),每執行一次迭代都會把所有數據輸入模型完成一次訓練
epochs=10,
# 測試圖片集、測試標籤
validation_data=(test_images, test_labels))
# 儲存模型,方便下次直接載入進行預測
# 載入方式 model = tf.keras.models.load_model('my_model')
model.save('my_model')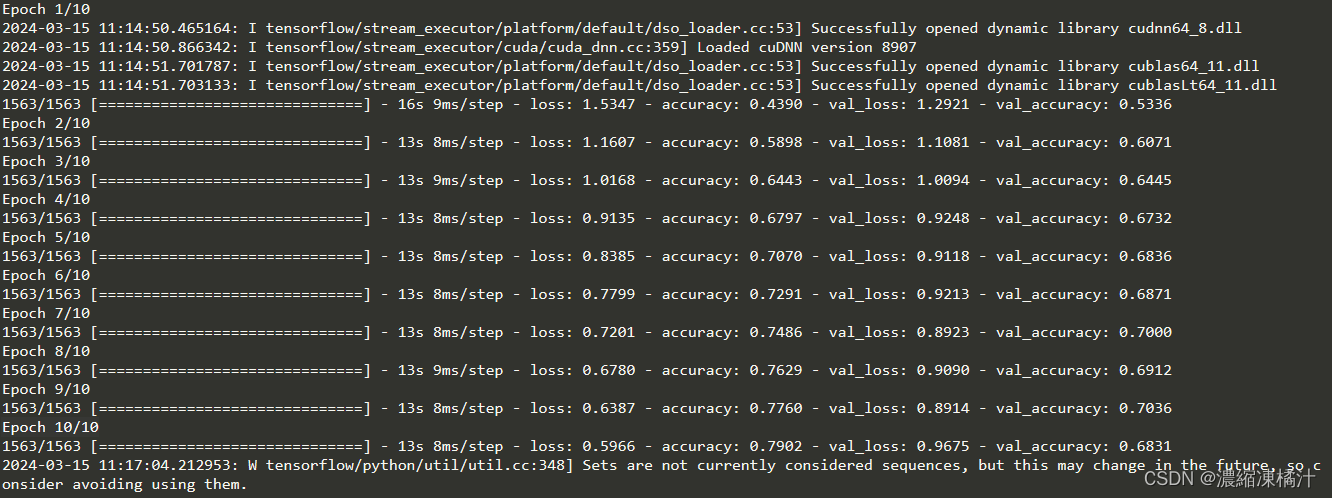
十、預測
# 顯示出測試圖片的樣子
plt.imshow(test_images[1])
# 對所有測試圖片進行預測
pre = model.predict(test_images)
#印出測試圖片的預測結果
print(class_names[np.argmax(pre[1])])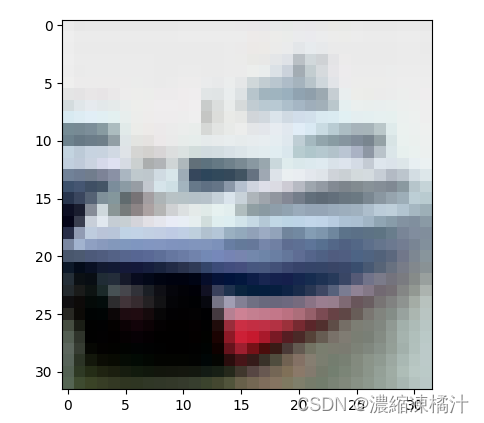
 結果正確
結果正確
十一、模型評估
# 模型評估
# 以線圖表示
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('test_loss:', test_loss)
print('test_acc:', test_acc) 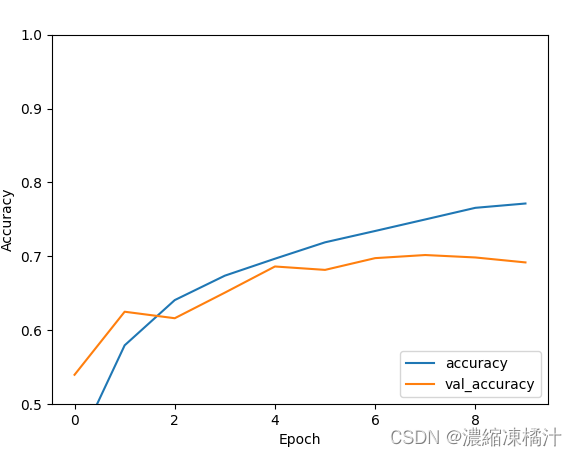

test_loss 是模型在測試集上的損失值,它衡量了模型在預測時與真實值之間的差距。損失值越低表示模型的預測與真實值越接近,表示模型的性能越好
test_acc 是模型在測試集上的準確率,它表示模型在測試集上正確預測的樣本比例。準確率越高表示模型的預測能力越強,對於未見過的數據的預測效果越好
十一、總結
在這次的實作中我學習到了如何使用 TensorFlow 來實現彩色圖片的分類任務。
具體而言,完成了以下步驟:
-
數據準備:使用 datasets.cifar10.load_data() 加載了 CIFAR-10 數據集並將像素值標準化到 0 到 1 的範圍內,該數據集包含了 10 類不同的彩色圖片
-
構建模型:使用 TensorFlow 的 Keras API 構建了一個卷積神經網絡(CNN)模型。該模型包含多個卷積層和池化層,最後是一個全連接層用於分類
-
訓練模型:使用訓練集來訓練模型,並使用驗證集來驗證模型的性能
-
模型評估:使用測試集來評估訓練好的模型性能,計算了模型在測試集上的準確率,並可視化了混淆矩陣來更好地理解模型的分類效果
結合上一篇灰度圖片辨識,能更加了解CNN模型的運用















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









