






- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、我的環境
-
電腦系統:Windows 10
-
顯卡:NVIDIA Quadro P620
-
語言環境:Python 3.7.0
-
開發工具:Sublime Text,Command Line(CMD)
-
深度學習環境:1.12.1+cu113Tensorflow
二、準備套件
# PyTorch 的核心模組,包含了張量操作、自動微分、神經網絡構建、優化器等
import torch
# PyTorch 的神經網絡模組,包含了各種神經網絡層和相關操作的類別和函數
import torch.nn as nn
# Matplotlib 的繪圖模組,用於創建各種圖表和視覺化數據
import matplotlib.pyplot as plt
# PyTorch 的計算機視覺工具包,包含了常用的數據集、模型和圖像轉換操作
import torchvision
# 一個用於數值計算的 Python 庫,提供了高效的數組和矩陣操作功能
import numpy as np
# PyTorch 的函數式神經網絡操作模組,包含了神經網絡中常用的操作,例如激活函數、損失函數等
import torch.nn.functional as F
# 提供 PyTorch 模型的詳細摘要信息,包括層數、參數數量和輸出形狀等,類似於 Keras 的 model.summary()
from torchinfo import summary
# 隱藏警告
import warnings三、設定GPU
# 設置硬體設備,如果有GPU則使用,沒有則使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)四、載入資料
# 載入 MNIST 訓練數據集
train_ds = torchvision.datasets.MNIST(
'data', # 存放數據集的目錄
train=True, # 指定這是訓練集
transform=torchvision.transforms.ToTensor(), # 轉換圖像為 PyTorch 張量
download=True # 如果指定目錄中沒有數據集,則下載數據集
)
# 載入 MNIST 測試數據集
test_ds = torchvision.datasets.MNIST(
'data', # 存放數據集的目錄
train=False, # 指定這是測試集
transform=torchvision.transforms.ToTensor(), # 轉換圖像為 PyTorch 張量
download=True # 如果指定目錄中沒有數據集,則下載數據集
)五、數據預處理
batch_size = 32 # 設定每個批次包含32個數據樣本
# 創建訓練數據加載器
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size, # 設定每個批次的大小
shuffle=True) # 在每個epoch開始前隨機打亂數據
# 創建測試數據加載器
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size) # 設定每個批次的大小,不打亂數據
# 從訓練數據加載器中取出一個批次的數據
imgs, labels = next(iter(train_dl))
# 打印取出批次的圖像形狀
print(imgs.shape)
# 設置圖像顯示區域大小
plt.figure(figsize=(20, 5))
# 遍歷前20張圖像
for i, img in enumerate(imgs[:20]):
# 將Tensor轉換為numpy數組,並去除多餘的維度
npimg = np.squeeze(img.numpy())
# 在子圖中顯示圖像
plt.subplot(2, 10, i + 1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off') # 隱藏坐標軸
# 顯示圖像
plt.show()
# 定義分類數目,MNIST數據集中有10個類別(數字0到9)
num_classes = 10 ![]()
六、定義模型
# 定義模型類
class Model(nn.Module):
def __init__(self):
super().__init__()
# 定義第一個卷積層,輸入通道為1(灰度圖像),輸出通道為32,卷積核大小為3
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
# 定義第一個池化層,池化區域大小為2x2
self.pool1 = nn.MaxPool2d(2)
# 定義第二個卷積層,輸入通道為32,輸出通道為64,卷積核大小為3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
# 定義第二個池化層,池化區域大小為2x2
self.pool2 = nn.MaxPool2d(2)
# 定義第一個全連接層,輸入特徵數量為1600,輸出特徵數量為64
self.fc1 = nn.Linear(1600, 64)
# 定義第二個全連接層,輸入特徵數量為64,輸出特徵數量為num_classes(類別數目)
self.fc2 = nn.Linear(64, num_classes)
def forward(self, x):
# 前向傳播,首先通過第一個卷積層和激活函數,再通過第一個池化層
x = self.pool1(F.relu(self.conv1(x)))
# 通過第二個卷積層和激活函數,再通過第二個池化層
x = self.pool2(F.relu(self.conv2(x)))
# 將輸出展平成一維向量
x = torch.flatten(x, start_dim=1)
# 通過第一個全連接層和激活函數
x = F.relu(self.fc1(x))
# 通過第二個全連接層,得到最終輸出
x = self.fc2(x)
return x
# 創建模型實例,並將其移動到指定設備(例如GPU)
model = Model().to(device)
summary(model) # 打印模型結構和參數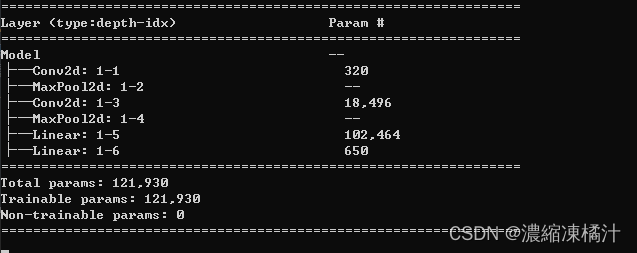
七、定義損失函數、優化器
# 定義損失函數和優化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵損失函數
learn_rate = 1e-2 # 學習率
opt = torch.optim.SGD(model.parameters(), lr=learn_rate) # 隨機梯度下降優化器
# 訓練函數
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 訓練集的總樣本數
num_batches = len(dataloader) # 訓練集批次數
train_loss, train_acc = 0, 0 # 初始化訓練損失和準確率
for X, y in dataloader: # 遍歷每個批次
X, y = X.to(device), y.to(device) # 將數據移動到設備
pred = model(X) # 前向傳播
loss = loss_fn(pred, y) # 計算損失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向傳播
optimizer.step() # 更新權重
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item() # 計算準確率
train_loss += loss.item() # 累計損失
train_acc /= size # 平均準確率
train_loss /= num_batches # 平均損失
return train_acc, train_loss
# 測試函數
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 測試集的總樣本數
num_batches = len(dataloader) # 測試集批次數
test_loss, test_acc = 0, 0 # 初始化測試損失和準確率
with torch.no_grad(): # 不計算梯度
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device) # 將數據移動到設備
target_pred = model(imgs) # 前向傳播
loss = loss_fn(target_pred, target) # 計算損失
test_loss += loss.item() # 累計損失
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() # 計算準確率
test_acc /= size # 平均準確率
test_loss /= num_batches # 平均損失
return test_acc, test_loss八、訓練模型
# 訓練和測試模型
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train() # 設置模型為訓練模式
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt) # 訓練一個 epoch
model.eval() # 設置模型為評估模式
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) # 測試模型
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
九、繪製訓練曲線
# 設置 matplotlib 參數
warnings.filterwarnings("ignore") # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用 SimHei 字體
plt.rcParams['axes.unicode_minus'] = False # 確保圖中正常顯示負號
plt.rcParams['figure.dpi'] = 100 # 設置圖形的分辨率
# 繪製訓練和測試的準確率和損失曲線
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()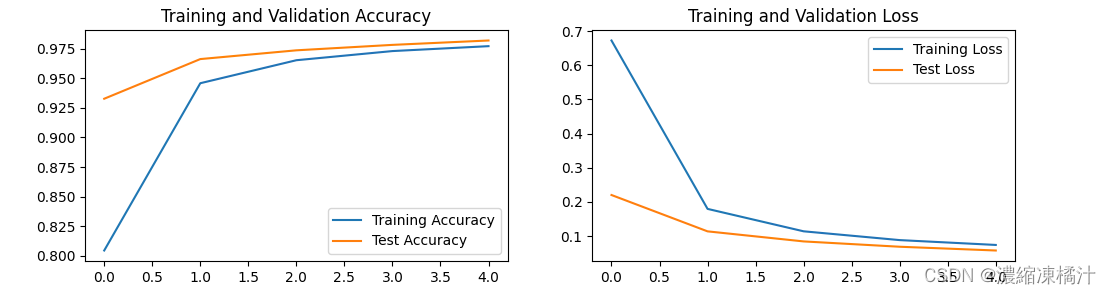
十、心得
當使用 PyTorch 進行 MNIST 手寫數字識別的學習時,我學到了:
構建深度學習模型
使用了 PyTorch 的 nn.Module 來構建卷積神經網絡(CNN),使用 Conv2d、MaxPool2d 和 Linear 等層來建立模型架構
數據準備和訓練過程
使用 DataLoader 來加載和處理 MNIST 數據集,這能夠將數據分為訓練集和測試集並進行批次訓練,在訓練過程中,我學會了如何定義訓練迴圈和測試迴圈,如何使用不同的優化器(例如 SGD)和損失函數(如交叉熵損失 CrossEntropyLoss)來優化和評估模型
模型評估和性能改進
通過在訓練過程中監視和記錄準確率和損失,我能夠對模型的性能進行評估並定期檢查其在測試集上的表現。這有助於我了解模型的泛化能力以及進行進一步的調整和改進,例如增加模型的深度或寬度、調整學習率或應用正則化技術
深入理解深度學習和 PyTorch
在整個過程中,我學會了如何實現一個基本的手寫數字識別系統,還深入理解了深度學習模型的內部運作機制,PyTorch 的靈活性使我能夠直接訪問和調整模型的權重、計算梯度,這加深了我對深度學習算法背後原理的理解
這個作業讓我掌握了基本的深度學習模型構建和訓練技能,還加深了我對深度學習原理和 PyTorch 框架的理解















 2784
2784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









