






- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、我的環境
-
電腦系統:Windows 10
-
顯卡:NVIDIA Quadro P620
-
語言環境:Python 3.7.0
-
開發工具:Sublime Text,Command Line(CMD)
-
深度學習環境:Tensorflow 2.5.0
二、準備套件
# 提供一些與操作系統交互的功能,例如文件路徑操作等
import os
# 用於圖像處理,例如打開、操作、保存圖像文件
import PIL
# 用於處理文件路徑的模塊,提供一種更加直觀和面向對象的操作文件路徑方式
import pathlib
# 用於繪圖,可以創建各種類型的圖表和圖形
import matplotlib.pyplot as plt
# 數值計算庫,用於處理大型多維數組和矩陣的
import numpy as np
# 開源的機器學習框架
import tensorflow as tf
# 導入 keras 模塊,為 tensorflow 的高級 API 之一,操作起來更加簡單、易用
from tensorflow import keras
# layers模組包含了各種類型的神經網絡層
# models模組包含了用於定義神經網絡模型的類
# Input類用於定義模型的輸入
from tensorflow.keras import layers, models, Input
# 用於定義自定義的神經網絡模型
from tensorflow.keras.models import Model
# 導入Keras API中的一些常用神經網絡層
# 包括卷積層(Conv2D)、池化層(MaxPooling2D)、全連接層(Dense)、展平層(Flatten)、失活層(Dropout)、批量規範(BatchNormalization)
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, BatchNormalization
# 供了一個名為 tqdm 的進度條,可以在迭代過程中顯示進度,讓用戶了解運行的進度
# 它是一個很常用的進度條庫,對於長時間運行的程式非常有用
from tqdm import tqdm
# 將 Keras 的後端函數庫引入為 K
# Keras 的後端函數庫提供了一系列與計算圖和張量操作相關的功能,
# 例如張量的數學運算、梯度計算等。通常,我們可以通過 K. 來訪問這些函數和類
import tensorflow.keras.backend as K
#隱藏警告
import warnings
warnings.filterwarnings('ignore')
# 用來在 Matplotlib 圖表中設置刻度的類
# 通過它,可以指定刻度的位置和間隔,以便更好地控制圖表的顯示效果
from matplotlib.ticker import MultipleLocator三、設定GPU
# 列出系統中的GPU裝置列表
gpus = tf.config.list_physical_devices("GPU")
# 如果有GPU
if gpus:
# 挑選第一個 GPU
gpu0 = gpus[0]
# 僅在需要的時候分配記憶體
tf.config.experimental.set_memory_growth(gpu0, True)
# 將 GPU0 設置為 TensorFlow 中可見的唯一 GPU ,將運算限制在特定的 GPU 上
tf.config.set_visible_devices([gpu0],"GPU")
plt.rcParams['axes.unicode_minus'] = False # 顯示負號四、載入資料
# 設定數據目錄的相對路徑,也可以使用絕對路徑
# D:/AI/ai_note/T6,這邊要注意斜線的方向
data_dir = "T6/"
# 將路徑轉換成 pathlib.Path 對象,更易操作
data_dir = pathlib.Path(data_dir)
# 使用 glob 方法獲取指定目錄下所有以 '.png' 為副檔名的文件迭代器
# '*/*.png 是一個通配符模式,表示所有直接位於子目錄中的以 .png 結尾的文件
# 第一個星號表示所有目錄
# 第二個星號表示所有檔名
image_count = len(list(data_dir.glob('*/*')))
# 印出圖片數量
print("圖片總數:",image_count)
五、數據預處理
# 設置批量大小,即每次訓練模型時輸入到模型中的圖像數量
# 在每次訓練跌代時,模型將同時處理16張圖像
# 批量大小的選擇會影響訓練速度和內存需求
batch_size = 16
# 圖像的高度,在加載圖像數據時,將所有的圖像調整為相同的高度,這裡設定為 336 像素
img_height = 336
# 圖像的寬度,在加載圖像數據時,將所有的圖像調整為相同的寬度,這裡設定為 336 像素
img_width = 336
# 創建訓練數據集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir, # 數據集所在目錄
validation_split=0.2, # 將數據集的20%用於驗證
subset="training", # 指定該部分為訓練數據集
seed=12, # 隨機種子,保證數據劃分的可重複性
image_size=(img_height, img_width), # 調整圖像尺寸
batch_size=batch_size) # 每個批次的圖像數量
# 創建驗證數據集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir, # 數據集所在目錄
validation_split=0.2, # 將數據集的20%用於驗證
subset="validation", # 指定該部分為驗證數據集
seed=12, # 隨機種子,保證數據劃分的可重複性
image_size=(img_height, img_width), # 調整圖像尺寸
batch_size=batch_size) # 每個批次的圖像數量
# 獲取數據集中類別的名稱
class_names = train_ds.class_names
print(class_names) # 輸出類別名稱
六、檢查數據
# 查看一個批次的圖像和標籤的形狀
for image_batch, labels_batch in train_ds:
print(image_batch.shape) # 打印圖像批次的形狀
print(labels_batch.shape) # 打印標籤批次的形狀
break # 只查看第一個批次
七、配置數據集
AUTOTUNE = tf.data.AUTOTUNE
# 定義訓練數據預處理函數
def train_preprocessing(image, label):
return (image / 255.0, label) # 將圖像數據歸一化到[0, 1]範圍
# 設置訓練數據集的預處理流程
train_ds = (
train_ds.cache() # 將數據集緩存到內存中,提高讀取速度
.shuffle(1000) # 將數據集隨機打亂
.map(train_preprocessing) # 應用預處理函數
.prefetch(buffer_size=AUTOTUNE) # 預取數據以提高性能
)
# 設置驗證數據集的預處理流程
val_ds = (
val_ds.cache() # 將數據集緩存到內存中,提高讀取速度
.shuffle(1000) # 將數據集隨機打亂
.map(train_preprocessing) # 應用預處理函數
.prefetch(buffer_size=AUTOTUNE) # 預取數據以提高性能
)八、數據展示
plt.figure(figsize=(10, 8)) # 設置圖像大小
plt.suptitle("數據展示") # 設置整體標題
# 從訓練數據集中取一個批次的圖像和標籤
for images, labels in train_ds.take(1):
for i in range(15): # 顯示前15張圖像
plt.subplot(4, 5, i + 1) # 創建子圖,4行5列
plt.xticks([]) # 隱藏X軸刻度
plt.yticks([]) # 隱藏Y軸刻度
plt.grid(False) # 隱藏網格線
plt.imshow(images[i]) # 顯示圖像
plt.xlabel(class_names[labels[i]]) # 顯示圖像對應的類別名稱
plt.show() # 顯示圖像
九、建構模型
def create_model(optimizer='adam'):
# 加載預訓練模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
# 冻結預訓練模型的所有層
for layer in vgg16_base_model.layers:
layer.trainable = False
# 添加自定義的全連接層
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
# 添加輸出層,使用softmax激活函數進行多分類
output = Dense(len(class_names), activation='softmax')(X)
# 創建完整的模型
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
# 編譯模型
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
# 使用不同的優化器創建模型
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
# 打印模型結構
model2.summary()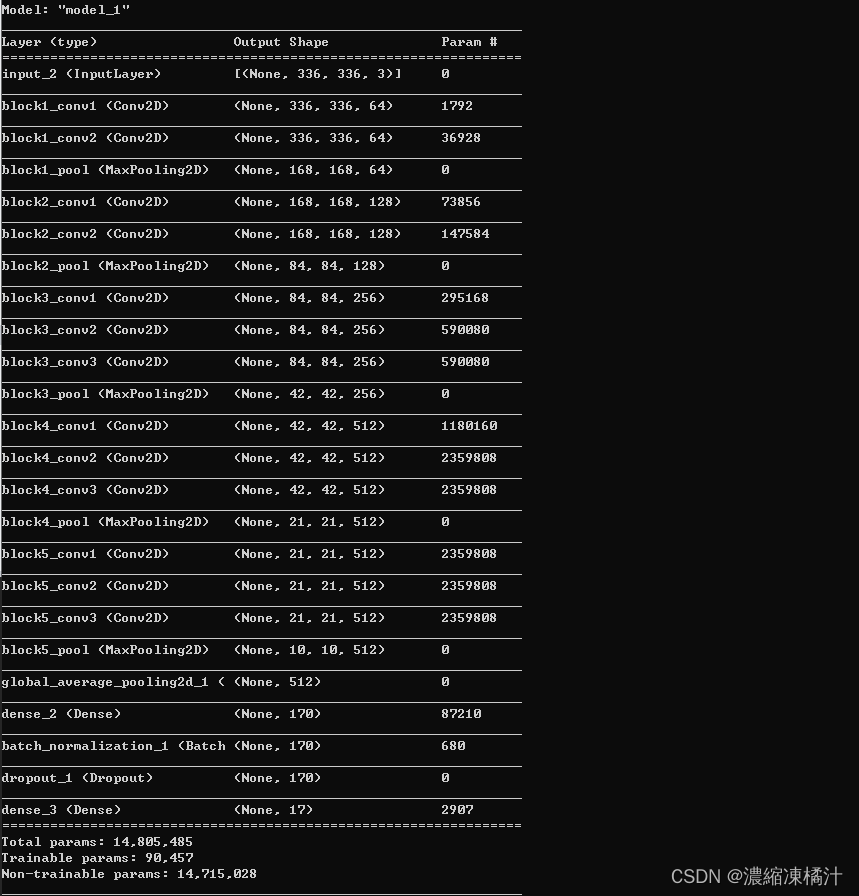
十、 訓練模型
NO_EPOCHS = 10 # 訓練的輪數
# 使用 model1 進行訓練
history_model1 = model1.fit(
train_ds, # 訓練數據集
epochs=NO_EPOCHS, # 訓練輪數
verbose=1, # 顯示訓練過程的詳細信息
validation_data=val_ds # 驗證數據集
)
# 使用 model2 進行訓練
history_model2 = model2.fit(
train_ds, # 訓練數據集
epochs=NO_EPOCHS, # 訓練輪數
verbose=1, # 顯示訓練過程的詳細信息
validation_data=val_ds # 驗證數據集
)
十一、模型評估
plt.rcParams['savefig.dpi'] = 300 # 圖片像素
plt.rcParams['figure.dpi'] = 300 # 分辨率
# 從訓練歷史中提取準確率和損失
acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']
loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']
epochs_range = range(len(acc1)) # 訓練的輪數範圍
plt.figure(figsize=(16, 4))
# 畫出訓練和驗證準確率
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc1, label='Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label='Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label='Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label='Validation Accuracy-SGD')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# 設置刻度間隔,x軸每1一個刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
# 畫出訓練和驗證損失
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label='Training Loss-Adam')
plt.plot(epochs_range, loss2, label='Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label='Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label='Validation Loss-SGD')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
# 設置刻度間隔,x軸每1一個刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.show() # 顯示圖像
def test_accuracy_report(model):
# 評估模型在驗證數據集上的性能
score = model.evaluate(val_ds, verbose=0)
# 打印損失值和準確率
print('Loss function:', score[0], ', accuracy:', score[1])
# 測試 model2 的準確率報告
test_accuracy_report(model2) 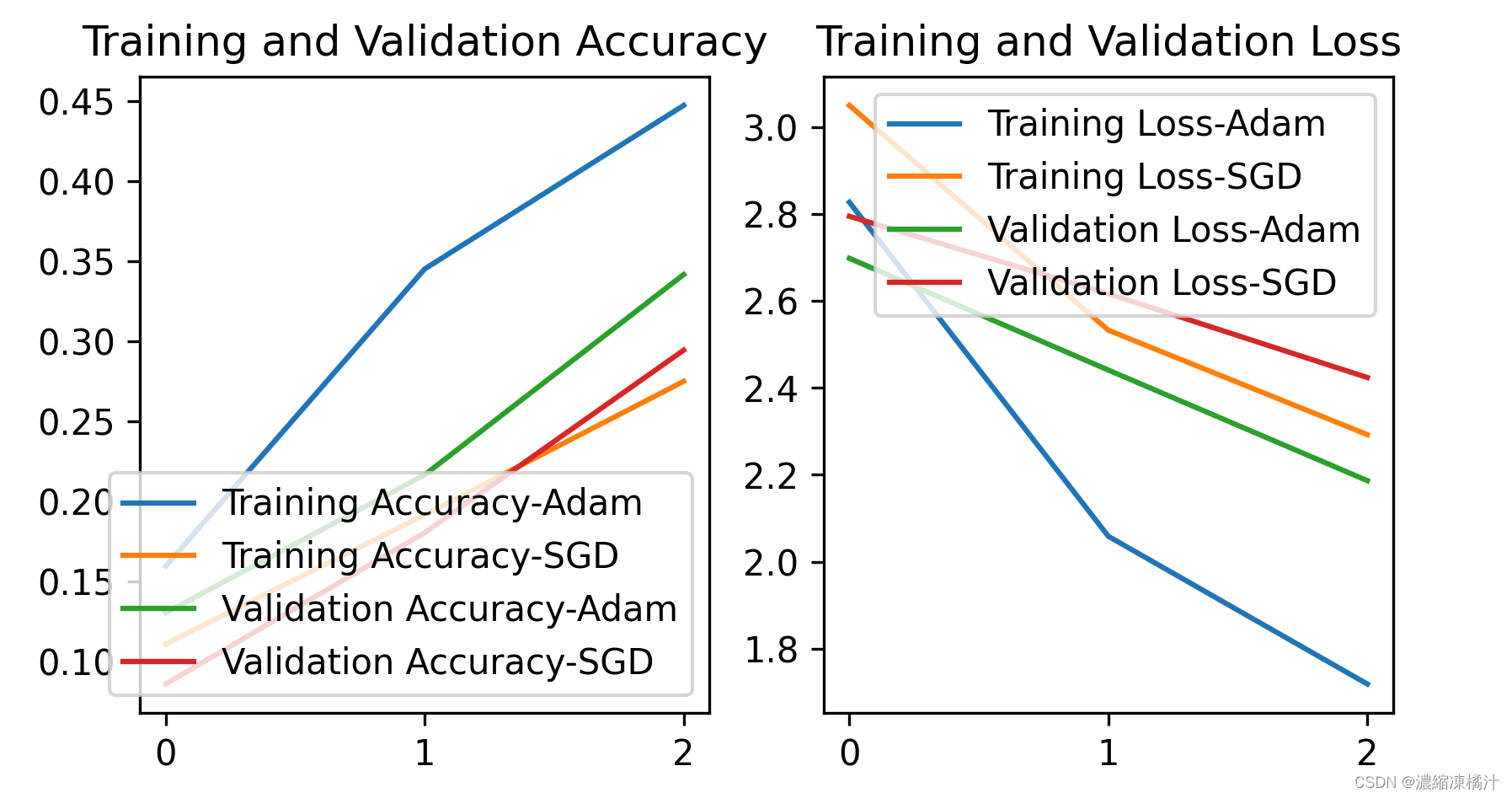
![]()
十二、總結
在深度學習中,選擇適當的優化器及其相應的參數配置對模型的訓練和性能表現具有重要影響
-
優化器的選擇:
- Adam 優化器通常是一個不錯的默認選擇,它結合了動量梯度下降和自適應學習率調整。它對於大多數情況下能夠提供良好的性能表現,並且相對容易調參
- SGD(隨機梯度下降) 需要精心調參,特別是學習率、動量等參數的設置。在某些情況下,SGD 可以通過仔細調整參數實現更好的性能,特別是在計算資源有限的情況下
-
學習率的調整:
- Adam 優化器通常不需要手動調整學習率,因為它會自適應調整。但是,如果遇到訓練過程中性能停滯或不收斂的情況,可以考慮進行小幅度調整
- SGD 優化器需要仔細調整學習率,通常會隨著訓練進行進行衰減或者動態調整
-
批量大小的影響:
- 選擇合適的批量大小對訓練速度和收斂性能至關重要。通常來說,較大的批量大小可以加速訓練,但可能會導致內存壓力或過擬合問題。較小的批量大小則可以提升模型的泛化能力
-
其他參數的影響:
- 動量(Momentum):對於 SGD,動量可以幫助加速收斂,特別是在具有高曲率的梯度表面上
- 權重衰減(Weight Decay):可以用來控制模型的正則化,減少過擬合的風險
- Dropout:隨機失活在訓練過程中可以有效防止過擬合,通常設置在 0.2 到 0.5 之間
選擇最佳的優化器及參數配置需要透過實驗和觀察來得出,在實際應用中,可以通過監控訓練和驗證的損失與準確率來評估不同設置的效果,並根據實際情況做出調整















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









