






TL; DR
1. 通过案例研究开发语言模型存在片面、耗时的问题,并且受到数据限制。
2. 开发人员寻求一种成本更低、质量更高、针对延迟进行优化的流线型prompt评估过程。
3. 开发人员希望自动生成提示词(prompt)和测试数据集。
4. 通过YiVal框架完成提示词自动调优(prompt autotune)。
介绍
使用大语言模型(LLM)去构建语言机器人时,业务团队需要一段时间来更新prompt。Yival花了近一周的时间在本地测试一些案例,使用非常特殊的场景来证明新的prompt表现得更好。然而,当我们开始进行A/B测试时,发现新的prompt在实践中表现不佳。经过反思,我们发现仅基于案例研究评估prompt存在以下问题:
1. 主观性:在评估大语言模型的输出时,相关性、准确性和完整性等因素很难量化。评估可能会受到个人解释和以往类似案例经验的影响。
2. 限制:通常,开发人员可能只测试十几个案例来评估prompt,这对于实现全面的评估来说是不够的。
3. 耗时:手动审查和评估案例耗费精力和时间。
目前,业界尚未建立成熟的autotune框架。然而,使用像YiVal这样的工具可以通过提供全面的解释来弥合这一差距。只需配置GenAI应用的任一参数,即可使用YiVal的autotune功能对prompt进行优化。
案例研究
Google colab:
https://colab.research.google.com/drive/1EYyz5NKW6xDOLZt2r9CoahY_dTGgjW0B?usp=sharing
以最简单的GenAI App为例,它会根据公司名称、业务领域和目标群体自动生成登录页标题。
YiVal将通过GPT-4自动创建测试数据、生成prompt、完成结果评估和性能增强,简化标题的生成。
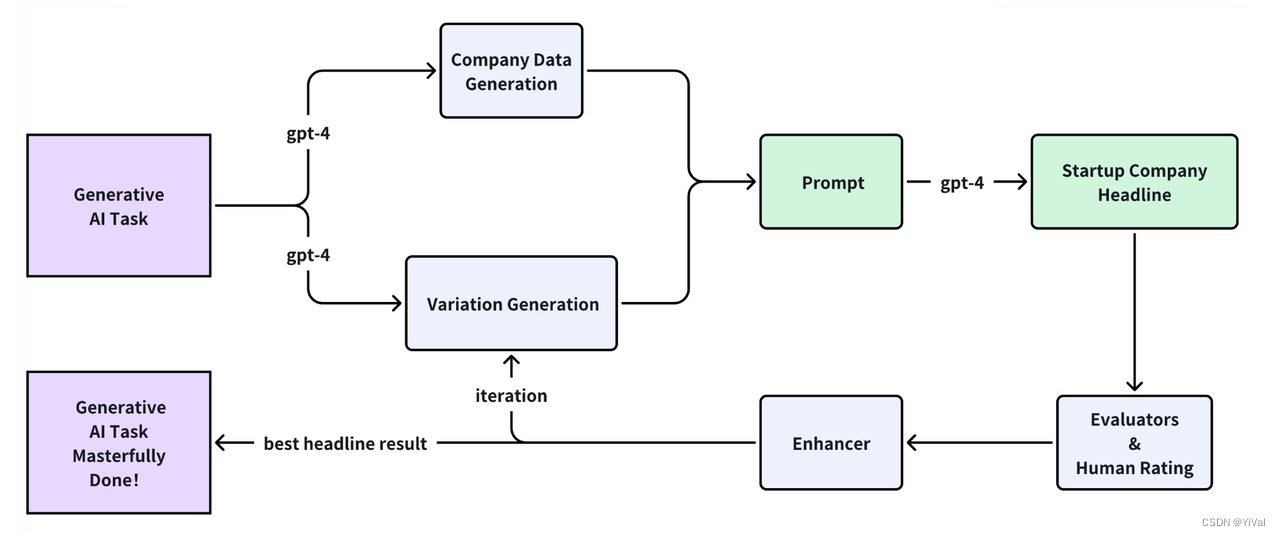
生成测试数据
YiVal支持通过简单的配置过程生成各种各样的测试数据!在这里,我们使用'openai_prompt_based_generator'来创建十组基本公司信息。这些数据随后将作为AIGC应用程序的输入,该应用程序将生成相应的登录页标题,以供进一步评估。除了使用大语言模型生成测试数据之外,YiVal还促进了从本地文件导入数据、访问Hugging Face数据集以及与各种其他数据源。

Prompt生成
YiVal支持使用GPT-4自动生成各种prompt,然后在此过程中进一步评估和优化prompt。只需要最基本的配置,YiVal就可以支持大规模的prompt生成。

结果评估
在2023年ACL的文章 Can Large Language Models Be an Alternative to Human Evaluation中,GPT-4达到了接近人类专家的评估水平,充分验证了LLM用于评估的潜力。
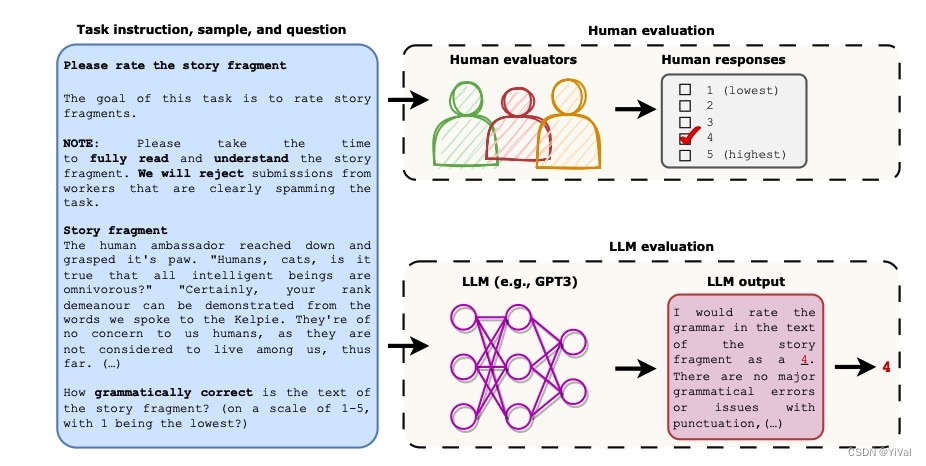
此外,在2023年8月北京大学和腾讯联合发表的文章《大语言模型不是公正的评估器》中,作者发现位置偏差会影响LLM作为评估器的评估结果。
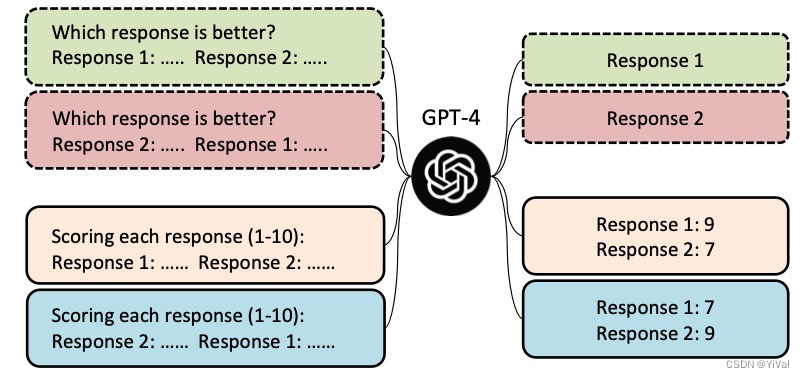
YiVal内置的“openai_prompt_based_evaluator”综合了几篇与提示相关的前沿论文,并且非常可靠。只需进行一些简单的配置,您就可以使用Yival经过精心打磨的高质量prompt,获得接近人类专家水平的评估结果!
为了评估生成的登录页标题的质量,我们从三个角度来对prompt进行评估:清晰度、相关度和吸引度。此外,YiVal将延迟和token_usage记录也作为评估指标之一。

Prompt Autotune
YiVal使用谷歌DeepMind论文“作为优化器的大模型”中的“opro增强器”,输入一个元提示词(meta-prompt),大模型就可以为YiVal中的用户自定义函数生成新的解决方案。Meta-prompt包含在优化过程中生成的“解决方案-评分”对(solution-score pairs),以及任务的自然语言描述,在优化提示时,还包含了任务示例的选择。
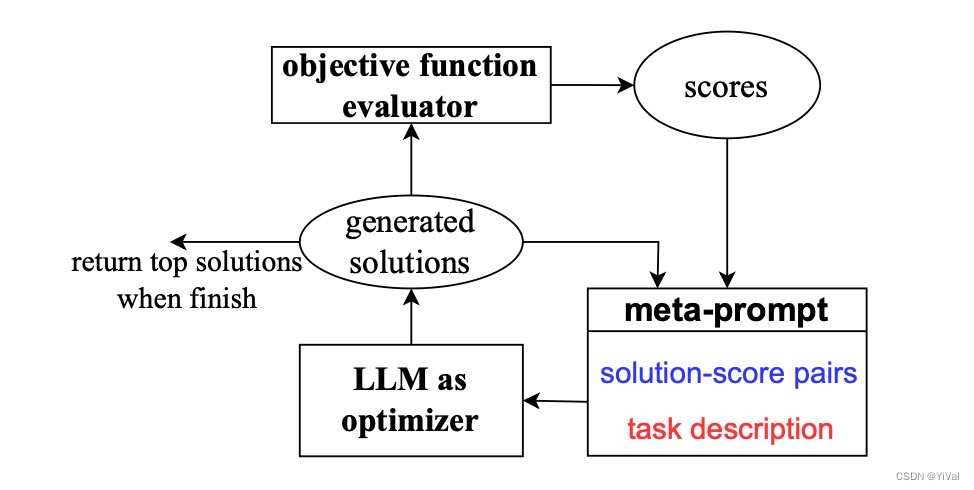
有了opro增强器和meta-prompt之后,我们会发现prompt的评估分数越来越高✈️

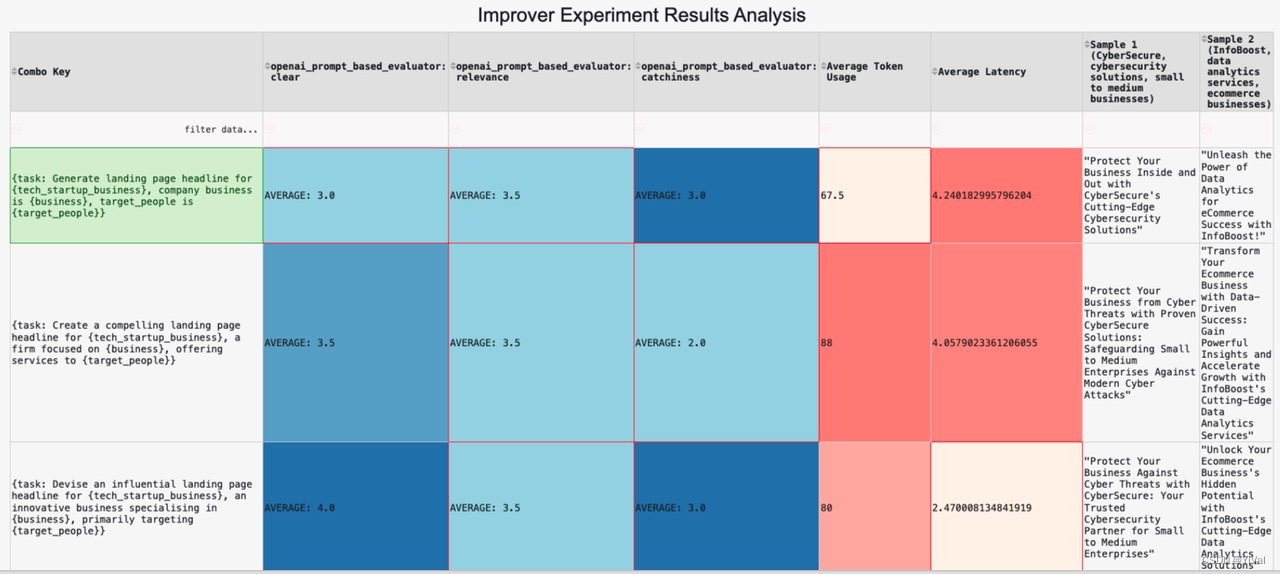
结论
Prompt Engineer通常通过有效的手动收集和评估案例来获得实时的、可靠的prompt迭代反馈。YiVal提供了一套全面的工具,可以自动生成测试数据,允许系统地评估和微调prompt。















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









