






之前因为毕设要做MATLAB多输入多输出的东西,在网上找了半天也没有,有也是要付费的,最后自己弄出来了,给大家分享一下。
我分别做出了LSTM长短期记忆神经网络多输入多输出、径向基神经网络多输入多输出、BP神经网络多输入多输出和卷积神经网络多输入多输出。
首先说明一下数据集,我的数据都是通过ANSYS软件仿真得到的,输入是应变数据100*10,输出是位移数据100*10。最终目的是输入应变得到相对应的位移,所以我将数据reshape成1000*1构建模型之后再变回100*10,思路大概就是这样。我把数据集放在开头免费分享,可是发现它下载还是要VIP,想要数据集的可以私信我发给你,等人多了我再整个百度网盘。
一、从文件夹中读取数据
我的数据全部放在一个文件夹里面方便读取

上面是输出的位移数据,下面是输入的应变数据,一一对应。
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'C:\Users\14737\Desktop\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end相关代码的注释我都写上去了。
这里面要注意的是,我读取的数据Z_3,X_3是3维的,第一个维度代表是文件,二三维度代表行和列。
二、三维转二维
这一步实现了100*10到1000*1的转变。
%% 三维转二维(200:100:10变成200:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
三、划分数据集和测试集
这里我的数据量是100,所以我按照8:2的比例划分数据集和测试集。
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);四、归一化
这里要注意理解!
%% 归一化
[X_train_1,X_train_iutput]=mapminmax(X_train',-1,1); %训练输入归一化
X_test_1=mapminmax('apply',X_test',X_train_iutput); %测试输入归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train',-1,1); %训练输出归一化这里要注意归一化时,只能将训练集的输入与输出归一化,然后用训练集归一化的映射关系去归一化测试集,再将已经归一化完成的测试集放入已经用归一化好的训练集输出与输入训练出来的模型中得到输出,最后将得到的输出用训练集输出映射关系来反归一化。之所以这样做是因为在真实情况中很难得到输入输出的数据集,只有单个输入来放入已经训练好的模型中。是否用测试集本身归一化与反归一化还是用训练集的映射来归一化与反归一化对最后的结果影响比较大。
五、训练神经网络
1、BP神经网络
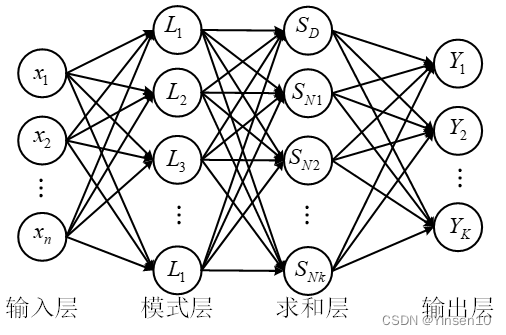
BP神经网络是最常规的,构建BP神经网络的时候首先要确定训练集与测试集的比例,根据一般经验将训练集与测试集的比例设置为8:2。然后设置训练次数,训练次数为200次,但是因为MATLAB中BP神经网络训练的时候如果损失函数的值在5次迭代之后都没有明显的改善的话就会停止迭代,所以要设置net1.divideFcn = ''才可以一直迭代下去。学习率设置的是0.01。隐藏层神经数设为一层。因为仿真的时候设置的是10条path,每一条path上面有100个感应点,所以每组不同力大小的应变和位移数据大小为10*100。所以输入层和输出层的神经元数目设置为1000个,隐藏层神经元数目设置为10个。隐藏层神经元的激活函数是'tansig'表示双曲正切 sigmoid 传递函数,输出层神经元的激活函数是'purelin'表示线性函数。训练方法为'trainrp'神经网络结构图。
%% 创建网络&设置训练参数&训练网络(训练方法trainrp)
net1 = newff(X_train_1,Z_train_1,10,{'tansig','purelin'},'trainrp');
net1.trainParam.goal = 1e-4;%优化目标 MSE
net1.trainParam.epochs = 200;%迭代次数
net1.trainParam.lr = 0.1;%学习率
net1.trainParam.min_grad = 1e-10;%最小梯度
net1.divideFcn = '';
[net1,w1] = train(net1,X_train_1,Z_train_1);
mse1 = w1.perf;
%% trainrp网络仿真
Y= sim( net1 , X_test_1) ;
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output'); 2、径向基神经网络
径向基函数是一种前馈神经网络,它的隐藏层的激活函数是径向基函数,这是它的特征。径向基函数是一种只和中心点距离有关的非负实值函数,具有径向对称性。隐藏层的维数通常较高,这使得它能够更好地逼近目标函数。径向基神经网络的非线性转换发生在输入层和隐含层之间,而隐含层和输出层之间是线性转换,并且两个层间的转换参数可以分别进行学习,与其他神经网络相比,其学习速度较快且可以避免局部极小问题。接下来将用广义回归神经网络和精确径向基神经网络来实现多输入多输出神经网络的搭建(因为MATLAB中只有这两种)。
(1)广义回归神经网络
广义回归神经网络(Generalized Regression Neural Network,GRNN)是一种四层前馈神经网络,它能够非线性地近似各种函数,是径向基神经网络的一种改进。与之不同的是,该网络无需训练过程,只需通过优化模式层的平滑因子来获得较好的输出结果。
GRNN有高效的非线性表征能力和极快的学习能力,比RBF更有优势,样本数据少时,预测效果更好,广义回归神经网络也可以用来处理不稳定数据。
GRNN只需要调节一个参数,spead是传播率(应该?)我设置的是0.02。
%% 设置grnn网络并且仿真
net = newgrnn(X_train_1,Z_train_1,0.02);%建立grnn 训练网络
Y = sim(net,X_test_1);
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output'); (2)精确径向基神经网络
精确径向基神经网络是径向基神经网络的特殊情况的一种,精确径向基神经网络的结构与径向基神经网络的结构完全一样,只是径向基神经网络的隐节点是固定个数(与样本个数相同),而精确径向基神经网络则会使用最小二乘法(Ordinary Least Square,OLS)算法逐个添加神经元,直到误差小于指定误差。即当精确径向基神经网络拥有与样本个数一样的神经元时,此时它就是径向基神经网络。
%% 设置rbe网络并且仿真
net = newrbe(X_train_1,Z_train_1);%建立grnn 训练网络
Y = sim(net,X_test_1);
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output'); 3、LSTM长短期记忆神经网络
LSTM网络是循环神经网络模型中的一种,它的结构很特殊。LSTM能有效地捕捉序列中的长期和短期模式,也能缓解RNN中的梯度消失或梯度爆炸问题,使梯度保持在合理的区间范围内,避免训练不稳定。LSTM可以加强模型的泛化能力和表达能力。总之,LSTM比RNN更进一步,可以处理更复杂和更长的序列数据。
%% 设置参数
inputSize = size(X_train_1',2);
numHiddenUnits = 100;
numResponses = size(Z_train_1',2);
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits,'OutputMode','sequence')
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...//训练网络的解决方法,自适应动量的随机优化方法
'MaxEpochs',1000, ...
'GradientThreshold',1e-5, ...
'InitialLearnRate',0.01, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropFactor',0.5, ...
'LearnRateDropPeriod',500, ...
'Plots', 'training-progress', ...
'Verbose',0);
%% 创建网络
[net,info2] = trainNetwork(X_train_1,Z_train_1,layers,options);
%% 仿真
Y= predict(net,X_test_1) ;
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_test_output); 4、卷积神经网络
CNN模型通常由四个部分组成,分别是卷积,池化,激活和全连接。卷积是提取特征的核心步骤。卷积的输出叫做特征图。为了不失去边缘的信息,我们需要用零值对输入进行填充,这样可以间接改变大小。另外,为了调节卷积的稀疏性,使用了步长。步长越大,稀疏性越高。卷积之后,特征图包含了大量容易造成过拟合问题的特征。所以,一般用池化的方法来消除冗余,防止过拟合的发生。
MATLAB中有自带的trainNetwork()函数,它可以练卷积神经网络用于深度学习分类和回归问题。net = trainNetwork(X,Y,layers,options)为图像分类或回归问题训练网络。数字数组X包含预测变量,Y数组包含分类标签或数字响应。其中X必须要转化为四维数组,每个维度分别代表输入矩阵长度,输入矩阵宽度,输入矩阵通道数和样本数目,用reshape将数组从二维变成四维。构造网络结构layers时,在卷积层设置了32个10*3的卷积核,还设置了Dropout层,丢弃了20%的数据,来防止过拟合。最后还要设置回归层,表示做的时回归任务。参数设置trainingOptions中,训练网络的解算器不能设置为sgdm(随机梯度下降法),要设置为adam(自适应学习率的梯度下降算法)。初始学习率为0.01。
%% 构造网络结构
layers = [
imageInputLayer([100, 10, 1]) % 输入层 输入数据规模[1000, 1, 1]
convolution2dLayer([10, 3], 32) % 卷积核大小 3*1 生成16张特征图
batchNormalizationLayer % 批归一化层
reluLayer % Relu激活层
% convolution2dLayer([20, 5], 32) % 卷积核大小 3*1 生成32张特征图
% batchNormalizationLayer % 批归一化层
% reluLayer % Relu激活层
dropoutLayer(0.2) % Dropout层,防止过拟合
fullyConnectedLayer(1000) % 全连接层
regressionLayer]; % 回归层
%% 参数设置
options = trainingOptions('adam', ... % adam 自适应
'MiniBatchSize', 40, ... % 批大小,每次训练样本个数30
'MaxEpochs', 100, ... % 最大训练次数 800
'InitialLearnRate', 0.005, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.5, ... % 学习率下降因子
'LearnRateDropPeriod', 500, ... % 经过400次训练后 学习率为 0.01 * 0.5
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Plots', 'training-progress', ... % 画出曲线
'Verbose', false);
%% 训练模型
net = trainNetwork(X_train_1, Z_train_1, layers, options);
%% 预测
Y_sim = predict(net,X_test_1);
六、得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_3(i,:,:) = reshape(Y_sim(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end七、计算评价指标
R = corrcoef(Z_test,Y_sim);
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim));%均方误差
RMSE = sqrt(MSE);%均方根误差八、画出得到的Z位移与实际Z位移3D图
D = 1;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('\fontname{宋体}\fontsize{20}实际一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('\fontname{宋体}\fontsize{20}训练一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
figure;
mesh(xi,yi,zi_real);
hold on;
mesh(xi,yi,zi_sim);
title('')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');九、完整代码
1、BP
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'E:\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(200:100:10变成200:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
%% 归一化
[X_train_1,X_train_iutput]=mapminmax(X_train',-1,1); %训练输入归一化
X_test_1=mapminmax('apply',X_test',X_train_iutput); %测试输入归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train',-1,1); %训练输出归一化
%% 创建网络&设置训练参数&训练网络(训练方法trainrp)
net1 = newff(X_train_1,Z_train_1,10,{'tansig','purelin'},'trainrp');
net1.trainParam.goal = 1e-4;%优化目标 MSE
net1.trainParam.epochs = 200;%迭代次数
net1.trainParam.lr = 0.1;%学习率
net1.trainParam.min_grad = 1e-10;%最小梯度
[net1,w1] = train(net1,X_train_1,Z_train_1);
mse1 = w1.perf;
%% trainrp网络仿真
Y= sim( net1 , X_test_1) ;
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output');
%% 得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_sim_1 = Y_sim';
Y_3(i,:,:) = reshape(Y_sim_1(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end
%% 计算评价指标
R = corrcoef(Z_test,Y_sim');
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim'));%均方误差
RMSE = sqrt(MSE);%均方根误差
%% 显示评价指标
fprintf('R2=%f\nMSE=%f\nRMSE=%f\n',R2,MSE,RMSE);
%% 画出得到的Z位移与实际Z位移3D图
D = 1;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('\fontname{宋体}\fontsize{20}实际一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
% zlabel('Z方向位移(mm)','FontSize',20,'FontName','宋体');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('\fontname{宋体}\fontsize{20}训练一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
figure
mesh(xi,yi,zi_real);
hold on;
mesh(xi,yi,zi_sim);
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
% % mse
% figure;
% T = 0:1:200;
% plot(T,mse1,'LineWidth',1.5);
% axis([0,200,1e-8,1]);
% set(gca,'xticklabel',{'0','20','40','60','80','100','120','140','160','180','200'}) %设置X坐标轴刻度处显示的字符
% set(gca,'yticklabel',{'1e-8','1e-7','1e-6','1e-5','1e-4','1e-3','1e-2','1e-1','1'}) %设置Y坐标轴刻度处显示的字符
% set(gca,'ytick',[1e-8,1e-7,1e-6,1e-5,1e-4,1e-3,1e-2,1e-1,1]);%纵坐标设置
% set(gca,'yscale','log');%取对数实现纵坐标不均匀分布
% legend('trainrp');
% xlabel('Epochs');
% ylabel('MSE');clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'E:\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(200:100:10变成200:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
%% 归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train,-1,1); %训练输出归一化
[X_train_1,X_train_iutput]=mapminmax(X_train,-1,1); %训练输入归一化
[Z_test_1,Z_test_output]=mapminmax(Z_test,-1,1); %测试输出归一化
[X_test_1,X_test_input]=mapminmax(X_test,-1,1); %测试输入归一化
%% 创建网络&设置训练参数&训练网络(训练方法trainrp)
net1 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'trainrp');
net1.trainParam.goal = 1e-10;%优化目标 MSE
net1.trainParam.epochs = 200;%迭代次数
net1.trainParam.lr = 0.1;%学习率
net1.trainParam.min_grad = 1e-10;%最小梯度
net1.divideFcn = '';
[net1,w1] = train(net1,X_train_1',Z_train_1');
mse1 = w1.perf;
% 创建网络&设置训练参数&训练网络(训练方法traingdx)
net2 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traingdx');
net2.trainParam.goal = 1e-10;%优化目标 MSE
net2.trainParam.epochs = 200;%迭代次数
net2.trainParam.lr = 0.1;%学习率
net2.trainParam.min_grad = 1e-10;%最小梯度
net2.divideFcn = '';
[net2,w2] = train(net2,X_train_1',Z_train_1');
mse2 = w2.perf;
% 创建网络&设置训练参数&训练网络(训练方法traingd)
net3 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traingd');
net3.trainParam.goal = 1e-10;%优化目标 MSE
net3.trainParam.epochs = 200;%迭代次数
net3.trainParam.lr = 0.1;%学习率
net3.trainParam.min_grad = 1e-10;%最小梯度
net3.divideFcn = '';
[net3,w3] = train(net3,X_train_1',Z_train_1');
mse3 = w3.perf;
% 创建网络&设置训练参数&训练网络(训练方法traingdm)
net4 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traingdm');
net4.trainParam.goal = 1e-10;%优化目标 MSE
net4.trainParam.epochs = 200;%迭代次数
net4.trainParam.lr = 0.1;%学习率
net4.trainParam.min_grad = 1e-10;%最小梯度
net4.trainParam.max_grad = 10;%最小梯度
net4.divideFcn = '';
[net4,w4] = train(net4,X_train_1',Z_train_1');
mse4 = w4.perf;
% 创建网络&设置训练参数&训练网络(训练方法traingda)
net5 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traingda');
net5.trainParam.goal = 1e-10;%优化目标 MSE
net5.trainParam.epochs = 200;%迭代次数
net5.trainParam.lr = 0.1;%学习率
net5.trainParam.min_grad = 1e-10;%最小梯度
net5.divideFcn = '';
[net5,w5] = train(net5,X_train_1',Z_train_1');
mse5 = w5.perf;
% 创建网络&设置训练参数&训练网络(训练方法traincgf)
net6 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traincgf');
net6.trainParam.goal = 1e-10;%优化目标 MSE
net6.trainParam.epochs = 200;%迭代次数
net6.trainParam.lr = 0.1;%学习率
net6.trainParam.minstep = 1e-10;
net6.divideFcn = '';
[net6,w6] = train(net6,X_train_1',Z_train_1');
mse6 = zeros(1,201);
mse6_ = w6.perf;
L6 = length(mse6_);
for i = 1:201
if i<=L6
mse6(i) = mse6_(i);
else
mse6(i) = mse6_(L6);
end
end
% 创建网络&设置训练参数&训练网络(训练方法traincgp)
net7 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traincgp');
net7.trainParam.goal = 1e-10;%优化目标 MSE
net7.trainParam.epochs = 200;%迭代次数
net7.trainParam.lr = 0.1;%学习率
net7.divideFcn = '';
[net7,w7] = train(net7,X_train_1',Z_train_1');
mse7 = zeros(1,201);
mse7_ = w7.perf;
L7 = length(mse7_);
for i = 1:201
if i<=L7
mse7(i) = mse7_(i);
else
mse7(i) = mse7_(L7);
end
end
% 创建网络&设置训练参数&训练网络(训练方法traincgb)
net8 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'traincgb');
net8.trainParam.minstep = 1.00e-10;
net8.trainParam.goal = 1e-10;%优化目标 MSE
net8.trainParam.epochs = 200;%迭代次数
net8.trainParam.lr = 0.1;%学习率
net8.divideFcn = '';
[net8,w8] = train(net8,X_train_1',Z_train_1');
mse8 = zeros(1,201);
mse8_ = w8.perf;
L8 = length(mse8_);
for i = 1:201
if i<=L8
mse8(i) = mse8_(i);
else
mse8(i) = mse8_(L8);
end
end
% 创建网络&设置训练参数&训练网络(训练方法trainscg)
net9 = newff(X_train_1',Z_train_1',5,{'tansig','purelin'},'trainscg');
net9.trainParam.goal = 1e-10;%优化目标 MSE
net9.trainParam.epochs = 200;%迭代次数
net9.trainParam.lr = 0.1;%学习率
net9.divideFcn = '';
[net9,w9] = train(net9,X_train_1',Z_train_1');
mse9 = w9.perf;
%% 训练算法的选取对 MSE 的影响的可视化
figure;
T = 0:1:200;
hold on;
plot(T,mse1,'r-',T,mse2,'g-',T,mse3,'y-',T,mse4,'m-',T,mse4,'c-',T,mse5,'k-',T,mse6,'b-','LineWidth',1.5);
plot(T,mse7,'Color',[0.3 0.8 0.9],'LineWidth',1.5);%,T,mse8,'Color',[0.3 0.5 0.5],T,mse9,'Color',[0.8 0.8 0.8],
plot(T,mse8,'Color',[0.5 0.8 0.7],'LineWidth',1.5);
plot(T,mse9,'Color',[0.3 0.2 0.1],'LineWidth',1.5);
axis([0,200,1e-8,1e-1]);
set(gca,'xticklabel',{'0','20','40','60','80','100','120','140','160','180','200'}) %设置X坐标轴刻度处显示的字符
set(gca,'yticklabel',{'1e-8','1e-7','1e-6','1e-5','1e-4','1e-3','1e-2','1e-1'}) %设置Y坐标轴刻度处显示的字符
set(gca,'ytick',[1e-8,1e-7,1e-6,1e-5,1e-4,1e-3,1e-2,1e-1]);%纵坐标设置
set(gca,'yscale','log');%取对数实现纵坐标不均匀分布
legend('trainrp','traingdx','traingd','traingdm','traingda','traincgf','traincgp','traincgb','trainscg','Fontsize',28,'fontname','Times New Roman');
xlabel('Epochs','Fontsize',28,'fontname','Times New Roman');
ylabel('MSE','Fontsize',28,'fontname','Times New Roman');
% %% 基于 trainrp 算法的隐层节点数目对 MSE 影响
% %隐藏层的神经元个数
% s=4:18;
% mes=1:15;
% MSE = zeros(6,15);
% for j=1:6
% for i=1:15
% net=newff(X_train_1',Z_train_1',s(i),{'tansig','purelin'},'trainrp');
%
% net.trainParam.goal = 1e-10;%优化目标 MSE
% net.trainParam.epochs = 200;%迭代次数
% net.trainParam.lr = 0.1;%学习率
% net.trainParam.min_grad = 1e-15;%最小梯度
% net.divideFcn = '';
% [net,w] = train(net,X_train_1',Z_train_1');
% mse_ = w.perf;
% mse(i) = mse_(201);
% end
% MSE(j,:) = mse;
% end
% %% 画出基于 trainrp 算法的隐层节点数目对 MSE 影响
% figure;
% plot(s,MSE(1,:),'r-',s,MSE(2,:),'g-',s,MSE(3,:),'k-',s,MSE(4,:),'m-',s,MSE(5,:),'c-',s,MSE(6,:),'b-','LineWidth',1.5);
% set(gca,'xtick',s,'xticklabel',s(1:1:end));
% legend('第一次训练','第二次训练','第三次训练','第四次训练','第五次训练','第六次训练');
% xlabel('隐藏层点数');
% ylabel('MSE');
% %% trainrp网络仿真
% Y= sim( net1 , X_test_1' ) ;
%
% %% 测试结果反归一化
% Y_sim=mapminmax('reverse',Y',Z_test_output);
%
% %% 得到数据二维转三维
% Y_3 = zeros(20,100,10);
% for i = 1:20
% Y_3(i,:,:) = reshape(Y_sim(i,:),100,10);
% end
% Z_test_3 = zeros(20,100,10);
% for i = 1:20
% Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
% end
% %% 画出得到的Z位移与实际Z位移3D图
% D = 6;
% x = 460/101*2:460/101:460;
% y = (-180:40:180);
% z_sim = reshape(Y_3(D,:,:),100,10)';
% z_real = reshape(Z_test_3(D,:,:),100,10)';
%
% xi = x;
% yi = (-180:360/99:180)';
% zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
% zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
%
% figure;
% subplot(2,2,1)
% mesh(x,y,z_real);
% title('实际一端受力Z方向位移')
% xlabel('X');
% ylabel('Y轴');
% zlabel('Z方向位移');
% subplot(2,2,2)
% mesh(xi,yi,zi_real);
% title('实际一端受力Z方向位移(插值后)')
% xlabel('X');
% ylabel('Y轴');
% zlabel('Z方向位移');
% subplot(2,2,3)
% mesh(x,y,z_sim);
% title('训练出的一端受力Z方向位移')
% xlabel('X');
% ylabel('Y轴');
% zlabel('Z方向位移');
% subplot(2,2,4)
% mesh(xi,yi,zi_sim);
% title('训练出的一端受力Z方向位移(插值后)')
% xlabel('X');
% ylabel('Y轴');
% zlabel('Z方向位移');
% grid on2、LSTM
warning off % 关闭报警信息
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'E:\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(100:100:10变成100:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
%% 归一化
[X_train_1,X_train_iutput]=mapminmax(X_train',-1,1); %训练输入归一化
X_test_1=mapminmax('apply',X_test',X_train_iutput); %测试输入归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train',-1,1); %训练输出归一化
%% 设置参数
inputSize = size(X_train_1',2);
numHiddenUnits = 100;
numResponses = size(Z_train_1',2);
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits,'OutputMode','sequence')
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',1000, ...
'GradientThreshold',1e-5, ...
'InitialLearnRate',0.01, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropFactor',0.5, ...
'LearnRateDropPeriod',500, ...
'Verbose',0);
%% 设置LSTM网络并且仿真
[net,info1] = trainNetwork(X_train_1,Z_train_1,layers,options);
Y= predict( net ,X_test_1);
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output');
%% 得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_sim_1 = Y_sim';
Y_3(i,:,:) = reshape(Y_sim_1(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end
%% 画出得到的Z位移与实际Z位移3D图
D = 3;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('\fontname{宋体}\fontsize{20}实际一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('\fontname{宋体}\fontsize{20}训练一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
figure;
mesh(xi,yi,zi_real);
hold on;
mesh(xi,yi,zi_sim);
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
%% 计算评价指标
R = corrcoef(Z_test,Y_sim_1);
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim_1));%均方误差
RMSE = sqrt(MSE);%均方根误差
error = Relative_error_of_two_dimensional_array(Z_test,Y_sim_1);
%% 显示评价指标
fprintf('R2=%f\nMSE=%f\nRMSE=%f\nerror=%f\n',R2,MSE,RMSE,error);
%% 画图
figure;
subplot(1,2,1)
T = 1:1:1000;
plot(T,info1.TrainingRMSE,'Color',[0.3 0.8 0.9],'LineWidth',1.5);
xlabel('Epochs','FontSize',20,'FontName','Times New Roman');
ylabel('RMSE','FontSize',20,'FontName','Times New Roman');
title('\fontname{Times New Roman}\fontsize{20}RMSE\fontname{宋体}\fontsize{20}随迭代次数增加的变化');
subplot(1,2,2)
plot(T,info1.TrainingLoss,'Color',[0.3 0.8 0.9],'LineWidth',1.5);
xlabel('Epochs','FontSize',20,'FontName','Times New Roman');
ylabel('Loss','FontSize',20,'FontName','Times New Roman');
title('\fontname{Times New Roman}\fontsize{20}Loss\fontname{宋体}\fontsize{20}随迭代次数增加的变化');3、RBF
warning off % 关闭报警信息
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'C:\Users\14737\Desktop\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(200:100:10变成200:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
%% 归一化
[X_train_1,X_train_iutput]=mapminmax(X_train',-1,1); %训练输入归一化
X_test_1=mapminmax('apply',X_test',X_train_iutput); %测试输入归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train',-1,1); %训练输出归一化
%% 设置grnn网络并且仿真
net = newgrnn(X_train_1,Z_train_1,0.02);%建立grnn 训练网络
Y = sim(net,X_test_1);
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output');
%% 得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_sim_1 = Y_sim';
Y_3(i,:,:) = reshape(Y_sim_1(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end
%% 画出得到的Z位移与实际Z位移3D图
D = 3;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
%% 计算评价指标
R = corrcoef(Z_test,Y_sim_1);
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim_1));%均方误差
RMSE = sqrt(MSE);%均方根误差
%% 显示评价指标
fprintf('R2=%f\nMSE=%f\nRMSE=%f\n',R2,MSE,RMSE);
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('\fontname{宋体}\fontsize{20}实际一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('\fontname{宋体}\fontsize{20}训练一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
figure;
mesh(xi,yi,zi_real);
hold on;
mesh(xi,yi,zi_sim);
title('')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');warning off % 关闭报警信息
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'C:\Users\14737\Desktop\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(100:100:10变成100:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
%% 归一化
[X_train_1,X_train_iutput]=mapminmax(X_train',-1,1); %训练输入归一化
X_test_1=mapminmax('apply',X_test',X_train_iutput); %测试输入归一化
[Z_train_1,Z_train_output]=mapminmax(Z_train',-1,1); %训练输出归一化
%% 设置rbe网络并且仿真
net = newrbe(X_train_1,Z_train_1);%建立grnn 训练网络
Y = sim(net,X_test_1);
%% 测试结果反归一化
Y_sim=mapminmax('reverse',Y,Z_train_output');
%% 得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_sim_1 = Y_sim';
Y_3(i,:,:) = reshape(Y_sim_1(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end
%% 画出得到的Z位移与实际Z位移3D图
D = 1;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
% figure;
%
% subplot(1,2,2)
% mesh(xi,yi,zi_real);
% title('实际一端受力Z方向位移')
% xlabel('X轴');
% ylabel('Y轴');
% zlabel('Z方向位移(mm)');
% subplot(1,2,1)
% mesh(xi,yi,zi_sim);
% title('训练出的一端受力Z方向位移')
% xlabel('X轴');
% ylabel('Y轴');
% zlabel('Z方向位移(mm)');
% grid on
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('\fontname{宋体}\fontsize{20}实际一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('\fontname{宋体}\fontsize{20}训练一端受力\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
grid on
figure;
mesh(xi,yi,zi_real);
hold on;
mesh(xi,yi,zi_sim);
title('')
xlabel('\fontname{Times New Roman}\fontsize{20}X\fontname{宋体}\fontsize{20}轴');
ylabel('\fontname{Times New Roman}\fontsize{20}Y\fontname{宋体}\fontsize{20}轴');
zlabel('\fontname{Times New Roman}\fontsize{20}Z\fontname{宋体}\fontsize{20}方向位移\fontname{Times New Roman}\fontsize{20}(mm)');
%% 计算评价指标
R = corrcoef(Z_test,Y_sim_1);
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim_1));%均方误差
RMSE = sqrt(MSE);%均方根误差
%% 显示评价指标
fprintf('R2=%f\nMSE=%f\nRMSE=%f\n',R2,MSE,RMSE);4、CNN
warning off % 关闭报警信息
clc %清空命令行
clear %清空变量
close all %关闭开启的图窗
%% 导入并读取数据
path = 'C:\Users\14737\Desktop\基于人工神经网络的应变重构研究\自测数据(一端固定,100个点)\'; %此处文件地址改为需要的文件夹路径
Filesname = dir(strcat(path,'*.xlsx')); %找到当前路径文件夹下的以.xlsx为后缀的文件名,strcat是横向连接字符的函数
Length = length(Filesname ); %计算文件夹里xls文档的个数
Z_3=zeros(Length/2,100,10);
X_3=zeros(Length/2,100,10);
for i = 1:Length %批量读取文件的内容并保存
xls_data = readmatrix(strcat(path,Filesname (i).name));%读取这个循环中的这组数据
data = xls_data(3:end,2:end);
if i<=100
Z_3(i,:,:)=data;
else
j=i-100;
X_3(j,:,:)=data;
end
end
%% 三维转二维(100:100:10变成100:1000)
Z_2 = zeros(100,1000);
X_2 = zeros(100,1000);
for i = 1:100
Z_2(i,:) = reshape(Z_3(i,:,:),1000,1);
X_2(i,:) = reshape(X_3(i,:,:),1000,1);
end
%% 划分训练集和测试集
temp = randperm(100); %生成100的乱序数组,temp = 1:1:100;打乱顺序
Z_train = Z_2(temp(1:80),:);
X_train = X_2(temp(1:80),:);
M = size(X_train,1);
Z_test = Z_2(temp(81:end),:);
X_test = X_2(temp(81:end),:);
N = size(X_test,1);
%% 按照CNN的要求reshape数据4维[输入矩阵长度 输入矩阵宽度 输入矩阵通道数 样本数目]
X_train=X_train';
X_test=X_test';
Z_train=Z_train';
X_train_1 = double(reshape(X_train, 1000, 1, 1, M));
X_test_1 = double(reshape(X_test , 1000, 1, 1, N));
Z_train_1 = double(Z_train);
Z_test_1 = double(Z_test);
%% 构造网络结构
layers = [
imageInputLayer([1000, 1, 1]) % 输入层 输入数据规模[1000, 1, 1]
convolution2dLayer([300, 1], 16) % 卷积核大小 3*1 生成16张特征图
batchNormalizationLayer % 批归一化层
reluLayer % Relu激活层
% convolution2dLayer([300, 1], 32) % 卷积核大小 3*1 生成32张特征图
% batchNormalizationLayer % 批归一化层
% reluLayer % Relu激活层
dropoutLayer(0.2) % Dropout层,防止过拟合
fullyConnectedLayer(1000) % 全连接层
% fullyConnectedLayer(80)
regressionLayer]; % 回归层
%% 参数设置
options = trainingOptions('sgdm', ... % SGDM 梯度下降算法
'MiniBatchSize', 30, ... % 批大小,每次训练样本个数30
'MaxEpochs', 100, ... % 最大训练次数 800
'InitialLearnRate', 1e-2, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.5, ... % 学习率下降因子
'LearnRateDropPeriod', 400, ... % 经过400次训练后 学习率为 0.01 * 0.5
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Plots', 'training-progress', ... % 画出曲线
'Verbose', false);
%% 训练模型
net = trainNetwork(X_train_1, Z_train_1, layers, options);
%% 预测
Y_sim = predict(net,X_test_1 );
%% 得到数据二维转三维
Y_3 = zeros(20,100,10);
for i = 1:20
Y_3(i,:,:) = reshape(Y_sim(i,:),100,10);
end
Z_test_3 = zeros(20,100,10);
for i = 1:20
Z_test_3(i,:,:) = reshape(Z_test(i,:),100,10);
end
%% 画出得到的Z位移与实际Z位移3D图
D = 3;
x = 460/101*2:460/101:460;
y = (-180:40:180);
z_sim = reshape(Y_3(D,:,:),100,10)';
z_real = reshape(Z_test_3(D,:,:),100,10)';
xi = x;
yi = (-180:360/99:180)';
zi_real = interp2(x,y,z_real,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
zi_sim = interp2(x,y,z_sim,xi,yi,'spline');%'linear' :双线性插值算法(缺省算法);'nearest' :最临近插值;'spline' :三次样条插值;'cubic' :双三次插值。
figure;
subplot(1,2,2)
mesh(xi,yi,zi_real);
title('实际一端受力Z方向位移')
xlabel('X轴');
ylabel('Y轴');
zlabel('Z方向位移');
subplot(1,2,1)
mesh(xi,yi,zi_sim);
title('训练出的一端受力Z方向位移')
xlabel('X轴');
ylabel('Y轴');
zlabel('Z方向位移');
grid on
%% 计算评价指标
R = corrcoef(Z_test,Y_sim);
R2 = R(1,2)^2;%R2(决定系数)是一种用于衡量回归模型拟合优度的统计量。R2的值介于0和1之间,越接近1表示模型对数据的拟合越好。R2的计算公式为:R2 = 1 - SSresid/SStotal,其中SSresid是残差平方和,SStotal是总平方和1
MSE = immse(Z_test,double(Y_sim));%均方误差
RMSE = sqrt(MSE);%均方根误差
%% 显示评价指标
fprintf('R2=%f\nMSE=%f\nRMSE=%f\n',R2,MSE,RMSE);数据集已经上传。
十、总结
BP神经网络调参优化
在搭建BP网络过程中,还没有一种确定的方法去确定隐层节点数目,只能根据总结的经验来调整,此外,BP的寻优算法的选取也同样会对最终结果产生很大影响,所以要对BP寻优算法的选取和隐层节点的确定开展研究。
使损失函数最小化实际上就是参数修正的目的, MATLAB BP神经网络训练时默认的损失函数为均方误差MSE。MATLAB工具箱集成了多种训练算法,因为有许多不同的寻优算法。本节研究目的是MATLAB工具箱集成的多种训练算法中选出适合多输入多输出应变场和位移场重构的最优算法,因此不在此详细讨论算法原理。训练的时候为了控制变量设置隐层节点为10个,讨论训练算法的选取对损失函数(均方误差)的影响。
| 训练函数 | 含义 |
| traingd | 梯度下降法 |
| traingdm | 附加动量的梯度下降法 |
| traingda | 自适应时间步长梯度下算法 |
| traingdx | 附加动量自适应时间步长梯度下降 |
| trainlm | Levenberg-Marquardt算法 |
| trainbr | 贝叶斯法 |
| trainrp | 弹性 BP 算法 |
| traincgf | Fletcher-Reeves 算法 |
| traincgp | Polak-Ribiers 算法 |
| traincgb | Powell-Beale 算法 |
| trainscg | 成比例的共轭梯度算法 |
| trainbfg | 拟牛顿法 |
| trainoss | 一步割线算法 |
| 训练参数 | 含义 | 设置值 |
| net.trainParam.goal | 优化目标:MSE | 1e-4 |
| net.trainParam.epochs | 迭代次数 | 200 |
| net.trainParam.lr | 学习速率 | 0.01 |
| net.trainParam.min_grad | 最小梯度 | 1e-20 |

Trainoss,trainlm,trainbr,trainbfg这四个训练算法由于输入输出神经元太多,加之电脑性能有限并不能训练出来。从训练结果可以看出,trainrp的损失函数的值最低,所以最终选取的是trainrp作为训练函数。选择完训练函数之后要开始选择隐藏层层数和隐藏层神经元个数。
| 隐藏层的层数 | 神经网络的功能 |
| 0 | 线性可分决策或函数 |
| 1 | 拟合任何从一个有限空间到另一个有限空间的连续映射的非线性函数。 |
| 2 | 表示任意精度的任意决策边界,而且可以拟合任何精度的任何平滑映射 |
| 其他 | 可以学习复杂的描述 |
至于隐藏层的神经元数量,目前没有科学的方法去确定,一般都是按照别人的经验总结出来的公式来确定,有如下的经验公式可用来参考:

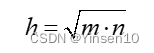
n为输出层节点数,m为输入层节点数, h为隐层节点数, 为1~10之间的调节常数。按照这些公式来算的话,因为输入输出神经元个数都为1000,所以m和n的值都是1000,h分别为45~55,10,1000,神经元个数为50,10,1000的MSE随迭代次数的变化图像如图
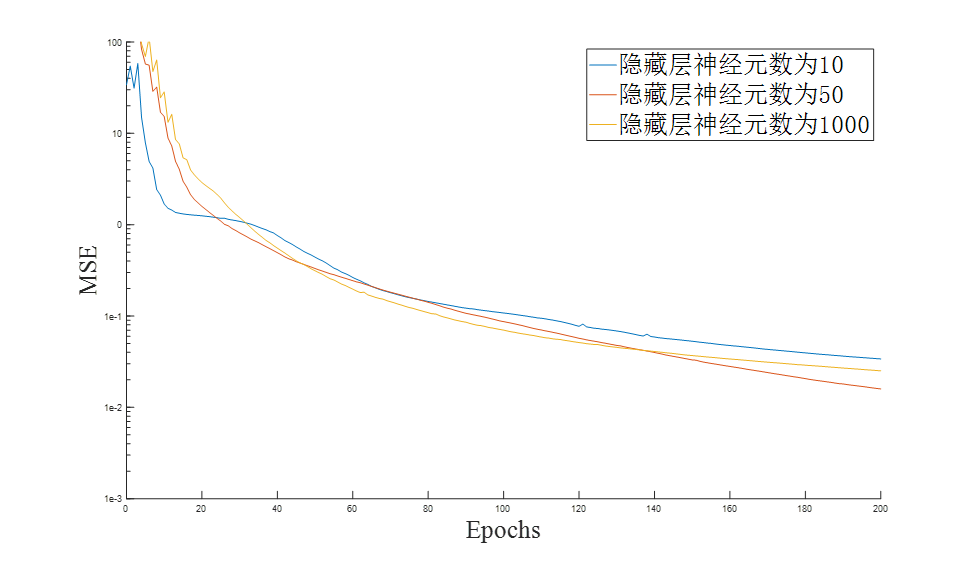
从图中发现发现神经元为1000时MSE降到最小,但是不能确定隐藏层神经元数定为1000。因为可能出现过拟合的现象导致网络的泛化性能很差,所以还是要用测试集验证训练出来网络的泛化性能。
| 神经元个数 | 相关系数 | 均方误差 | 均方根误差 | 用时(s) |
| 50 | 0.9634 | 1.93 | 1.389 | 1 |
| 10 | 0.9999 | 0.004517 | 0.06721 | 1 |
| 1000 | 0.8718 | 6.722 | 2.59 | 28 |
神经网络效果对比
为了在上面所有实现多输入多输出应变场和位移场重构的神经网络中选择一种效果最好的神经网络,本节将比较这些神经网络的测试集相关参数来得出神经网络最重要的泛化性能的好坏,同时比较训练时长。
在比较之前首先将各个神经网络的参数配置表出:
(1)BP神经网络中优化目标是10-4 ,迭代次数是200次,学习率是0.01,最小梯度为 。
(2)LSTM神经网络采用adam(自适应学习率的梯度下降算法),迭代1000次,初始学习率为0.01,500次后学习率变为0.005防止过拟合。
(3)CNN神经网络输入数据规模[100, 10, 1],卷积核大小10*3并且生成32张特征图,一个卷积层,一个池化层,一个ReLU激活层还有一个Dropout层,防止过拟合。也采用adam优化算法,每次训练样本个数30,最大训练次数 800,初始学习率为0.01,迭代次数过半后学习率变为0.005防止过拟合。
| 训练网络 | 相关系数 | 均方误差 | 相对误差 | 用时(s) |
| LSTM | 0.999350 | 0.028081 | 0.030701 | 80 |
| CNN | 0.859153 | 6.067563 | 0.548362 | 26 |
| GRNN(RBF) | 0.999952 | 0.002037 | 0.006359 | 1 |
| RBE(RBF) | 0.999983 | 0.000546 | 0.004611 | 1 |
| trainrp(BP) | 0.999862 | 0.006007 | 0.009643 | 1 |
| traingdx(BP) | 0.775561 | 10.55572 | 0.435756 | 1 |
| traingd(BP) | 0.755932 | 11.680123 | 0.425965 | 1 |
| traingdm(BP) | 0.755358 | 11.253721 | 0.411279 | 1 |
| traingda(BP) | 0.746234 | 11.727012 | 0.419758 | 1 |
| traincgf(BP) | 0.735900 | 12.479201 | 0.415925 | 2 |
| traincgp(BP) | 0.997560 | 0.1049245 | 0.038630 | 2 |
| traincgb(BP) | 0.997623 | 0.1032016 | 0.017861 | 2 |
| trainscg(BP) | 0.970268 | 1.27786 | 0.058504 | 1 |
对BP神经网络中的寻优算法的选取与隐层节点的数目开展研究,确定了在所有优化算法中trainrp的效果最好,同时隐藏层节点数为10的时候泛化性能最好。对于所有的神经网络也进行了对比,发现多输入多输出应变场和位移场重构神经网络中,径向基神经网络中的广义回归神经网络与精确径向基神经网络还有BP神经网络中使用trainrp优化算法时的泛化性能与用时少,总的来说这三种是最优的选择。















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









