






0 前言
该笔记基于《CUDA C 编程指南》以及CUDA官方文档,多记录程序代码以及函数使用,其余知识点详见书中。
1 基于CUDA的异构并行计算
该章就是写了一个关于helloworld的小demo:
hello.cu
#include <stdio.h>
__global__ void helloFromGPU(){
// 可以通过threadIdx.x得到对应的线程ID
printf("Hello world from GPU%d\n", threadIdx.x);
}
int main(){
printf("Hello world from CPU\n");
helloFromGPU<<<1, 10>>>();
cudaDeviceReset();
return 0;
}
可以看到,该源文件的后缀为.cu,然后使用nvcc来对其进行编译:
nvcc -arch sm_52 ex_1_3.cu -o hello
然后运行hello这个可执行文件,输出:
Hello world from CPU
Hello world from GPU0
Hello world from GPU1
Hello world from GPU2
Hello world from GPU3
Hello world from GPU4
Hello world from GPU5
Hello world from GPU6
Hello world from GPU7
Hello world from GPU8
Hello world from GPU9
可能会有一些疑问,为什么源代码后缀名为.cu,首先这是nvcc所支持编译的源文件后缀,另外,以该后缀结尾的源代码表示这是一个CUDA源文件,包含了主机代码(host code)以及设备函数(device functions)。nvcc所支持编译的源文件后缀有如下:
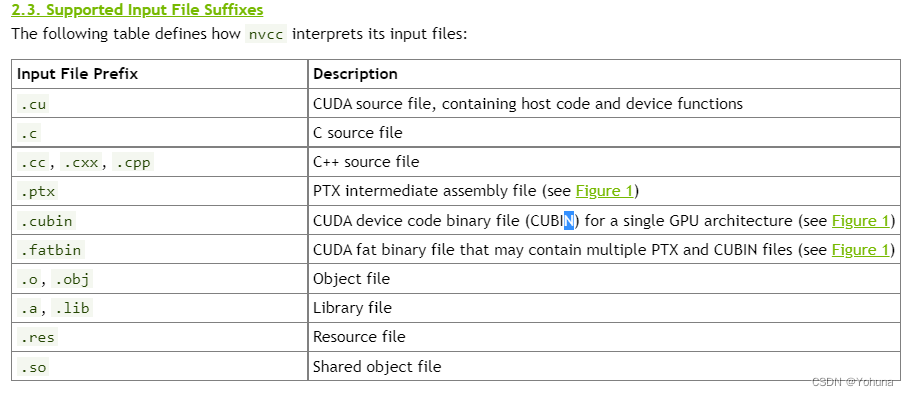
现在来解释以下源代码和编译指令:
-
首先源代码方面:
- 我们将应用于GPU上的函数称为核函数,该函数需要
__global__来对其进行修饰; - 在运行核函数的时候,我们需要添加一个
<<<x, y>>>来进行调用,这里x指的是调用该函数所使用的线程块个数,y代表的是每个线程块中线程的个数。我们定义的是<<<1, 10>>>,那么最后就会有10个线程被调用。 - 在GPU调用完核函数之后,需要调用
cudaDeviceReset(),该函数作用是显式地释放和清空当前进程中与当前设备有关的所有资源。
- 我们将应用于GPU上的函数称为核函数,该函数需要
-
编译指令方面:
-
可以看到在编译时有一个开关语句
-arch sm_52,这是什么意思呢?就是说让编译期使用sm_52这个架构来生成设备代码。注意,不同的nvidia显卡对应了不同的sm_xx架构,由于我的显卡为GTX Titan X,所以对应的架构为sm_2,具体的对应表见这里 -
那什么是sm呢?SM的结构图如下:
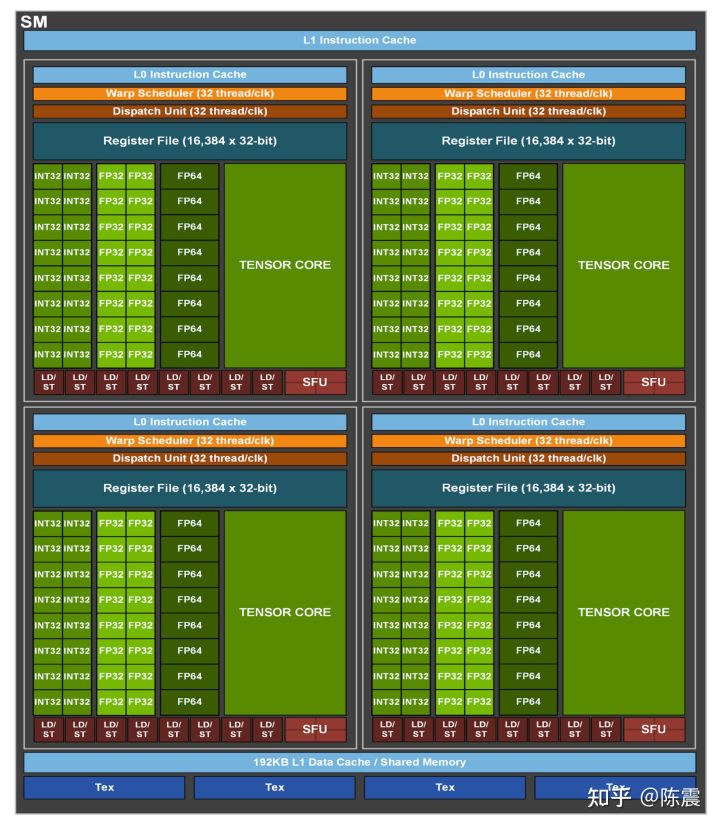
SM可以看成是GPU计算调度的一个基本单位,只有对其架构和硬件规格有一定认识,才能更高效地利用GPU的硬件能力。SM中自上而下分别有:
-
L1 Shared Memory,在SM层面提供192KB的共享缓存
-
接下来是四个PB(Process Block),每个PB内部分别有
-
- L0缓存
- Warp Scheduler用于计算任务调度
- Dispatch Unit用于计算任务发射
- Register File寄存器
- 16个专用于INT32计算的核心
- 16个专用于FP32计算的核心
- 8个专用于FP64计算的核心
- 4个Tensor Core,这是受Google TPU的影响,专门设计用于执行A*B+C这类矩阵计算的硬件单元,甚至还支持稀疏矩阵计算,Tensor Core对深度学习的加速非常明显
- 8个用于LOAD/STORE数据的硬件单元
- 4个SFU(Special Function Unit)用于执行超越函数、插值等特殊计算
因此一个SM内就有64个用于计算的核心,Nvidia称之为CUDA Core(但是我没搞明白64是怎么算出来的)。而一整块A100 GPU则密密麻麻地放置了108个SM,总计6912个CUDA Core,可以简单理解成这是一个拥有6912个核心的巨型CPU!
-
-
参考文章:















 6067
6067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









