






点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨图灵智库
来源丨 泡泡机器人SLAM
标题: HR-Depth:High Resolution Self-Supervised Monocular Depth Estimation
作者:Xiaoyang Lyu Liang Liu , Mengmeng Wang , Xin Kong
机构:Zhejiang University , Fuxi AI Lab, NetEase
来源:AAAI2021
编译:Cristin
审核: ZH
摘要

大家好,今天为大家带来的文章是 HR-Depth : High Resolution Self-Supervised Monocular Depth Estimation
利用图像序列作为唯一的监督源,自监督学习在单目深度估计方面显示出巨大的潜力。虽然人们尝试使用高分辨率图像进行深度估计,但预测的准确性并没有明显提高。在本文中,我们发现核心原因是在大梯度区域深度估计不准确,使得双线性插值error随着分辨率的增加逐渐消失。为了在大梯度区域获得更精确的深度估计,需要获取具有空间和语义信息的高分辨率特征。因此,我们提出了一种改进的DepthNet, HR-Depth,它具有两种有效的策略:(1)重新设计DepthNet中的跳过连接,以获得更好的高分辨率特征;(2)提出特征融合Squeeze-and-Excitation(fSE)(fSE)模块,以更有效地融合特征。使用Resnet-18作为编码器,HR深度在高分辨率和低分辨率下都以最少的参数超过了所有以前最先进的(SoTA)方法。此外,以往最先进的方法都是基于相当复杂和深度的网络,具有大量的参数,限制了它们的实际应用。因此,我们也构建了一个轻量级的网络,使用MobileNetV3作为编码器。实验表明,轻量级网络可以在只有20%参数的高分辨率下与Monodepth2等许多大型模型相媲美。code: https://github.com/shawLyu/HR-Depth.

主要工作与贡献

本工作的主要贡献如下:
•我们对高分辨率单目深度估计进行了深入分析,并证明预测更精确的边界可以提高性能。
•我们重新设计了跳跃连接,以获得高分辨率的语义特征图,可以帮助网络预测更清晰的边缘。
•提出了特征融合-压缩激励块,提高了特征融合的效率和效果。
•我们提出了一个简单而有效的轻量级设计策略——训练一个轻量级的深度估计网络,可以实现复杂网络的性能。

算法流程

1. 高分辨率性能分析
作为密集预测任务的共识,更高的分辨率本能地带来更准确的结果(Sun等人2019;周等,2019)。特别是在深度估计任务中,像素级视差更重要,因为它与深度误差的平方成反比(You et al. 2019)。然而,我们注意到之前的大部分工作都是使用低分辨率的输入,并将低分辨率的预测插值到高分辨率的预测中。低分辨率的实验本质上无法使这些结果从高分辨率的图像中受益。有些方法还进行高分辨率实验,用更大的图像训练模型(Godard等人2019;Pillai等人2019年)。然而,对小输入的性能改进非常有限,即(Pillai et al. 2019),他们的模型不能利用高分辨率。例如,我们使用更高的分辨率设置来评估最近的著名工作Monodepth2(Godardet al. 2019)。如表所示1、在高分辨率和低分辨率设置下,深度误差几乎相同。因此,我们认为他们的方法不能充分利用高输入分辨率的信息。
此外,我们还深入分析了现有方法不能提高高分辨率输入深度估计的实际原因。我们发现,从低分辨率预测到高分辨率预测的双线性插值过程中,最关键的一点是不可忽略的误差。具体来说,以Monodepth2(Godard et al.2019)为例,当输入较小的模型时,我们需要通过插值对输出进行上采样,以获得所需的高分辨率模型。从图2中可以看出,对于深度梯度较大的区域如实例边缘,局部的预测误差会严重影响全局精度,而对于深度梯度较小的区域,局部的预测误差会严重影响全局精度。有趣的是,当低分辨率输出的预测较差时,如图2右上部分,它会意外地补偿双线性插值的局部预测误差。结果表明,低分辨率图像的性能可以达到高分辨率图像的水平。换句话说,大多数方法不能从较大的输入中受益的实际原因是,这两种设置之间的差距被上述有趣的现象弥补了。因此,只有对深度梯度较大的区域进行更精确的预测,才能使高分辨率预测更加准确。我们还可以总结出,在大梯度区域和更尖锐的边缘预测更准确的深度,可以提高高分辨率的性能。
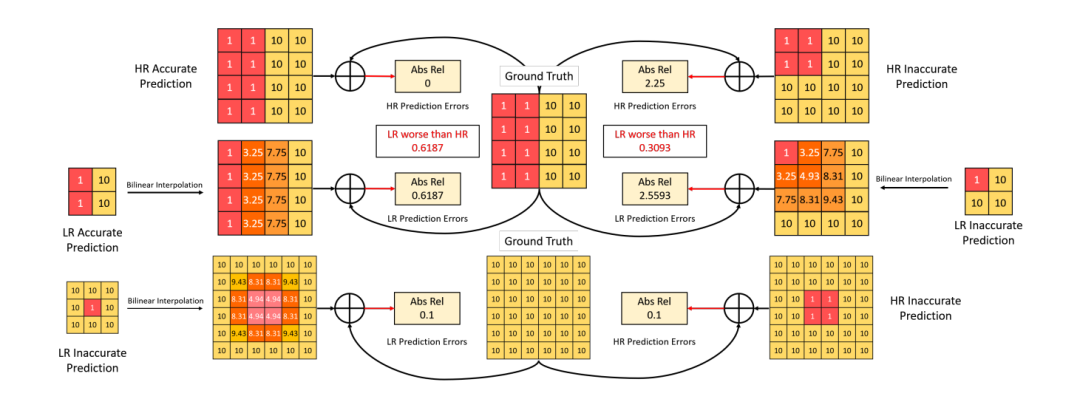
图2 高分辨率深度估计分析。Abs Rel是一种深度评价指标,越低越好。HR为高分辨率,LR为低分辨率。所有插值结果由OpenCV库计算。
2. Redesign Skip Connection
为了预测更准确的边界,我们尝试从空间和语义两个方面对边界进行增强,因为我们认为:(1)语义信息可以在不同类别之间产生边界,从而减少因误分类而导致的深度估计误差;(2)空间信息可以帮助网络知道边界的位置,从而更好地估计边界。在这里,我们将首先讨论深度网络和U-Net架构。
为了减少语义和分辨率差距,我们受到(Zhou et al. 2018)的启发,提出了密集跳跃连接。如图3所示,除了原有的编码器和解码器中的节点外,我们还添加了大量的中间节点来聚合特性。
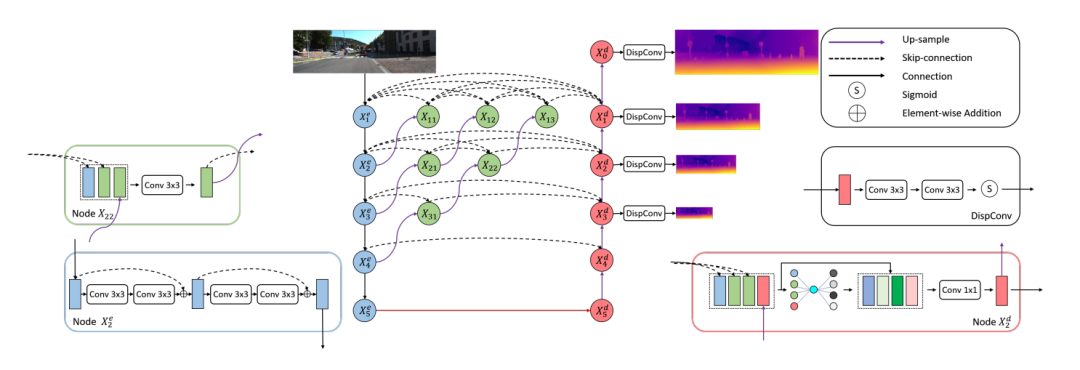
图3 网络框架说明。该网络主要由三种不同类型的节点组成。X i e为特征提取节点,主要由残差块组成。xi,j表示一个特征融合节点,该节点只有3 × 3的卷积运算。X i d是特征融合节点,主要由我们提出的fSE模块组成。视差由disconv块进行解码,该块包含3 × 3卷积和sigmoid激活函数。
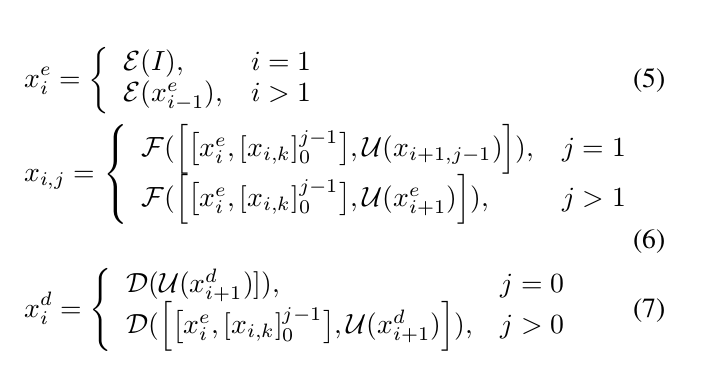
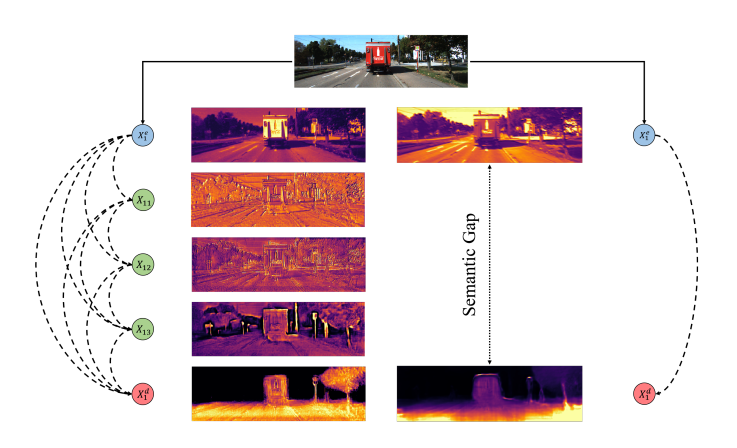
图4 Lite-Network在KITTI数据集上对距离达80m的量化性能。计算矩阵和方法与表2相同。在督导栏中,T是指使用教师网络引导lite网络进行训练。
3.Feature Fusion SE Block
基于U-Net的DepthNet采用3 × 3的卷积将上采样的特征图与编码器提供的原始特征图进行融合,卷积的参数计算为
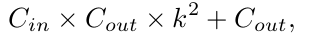
就像(Huang et al. 2017),密集的跳跃连接使得解码器节点大量增加了输入特征图,因此这种操作将不可避免地降低网络的效率。受(Huet al. 2019)的启发,我们提出了一个轻量级模块,特征融合挤压激励(fSE),以提高特征融合的精度和效率。fSE模块通过全局平均池来压缩特征图来表示通道信息,并使用两个全连接层(FC)和一个sigmoid函数来衡量每个特征的重要性,同时对它们进行重新加权。然后利用1×1卷积对信道进行融合,得到高质量的特征图。
4.Lite-HR-Depth
我们的Lite-HR-Depth采用了MobileNetV3作为编码器,并缩小了只有3.1M参数的特征融合和解码器节点,其中2.82M参数来自编码器。此外,我们通过知识蒸馏进一步提高Lite-HR-Depth的准确性(Hinton等人,2015年)。对于自监督学习,由于缺乏基本事实,我们不得不使用视图综合作为监督信号,这增加了小型网络训练的难度。因此,我们建议从所学的大模型中寻找一种直接的监督形式。通过以自我监督的方式训练一个大型网络,我们得到高性能网络实例T。然后训练轻量级模型的第二个实例,即S,使其最小化
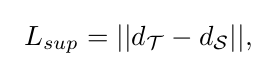

实验结果

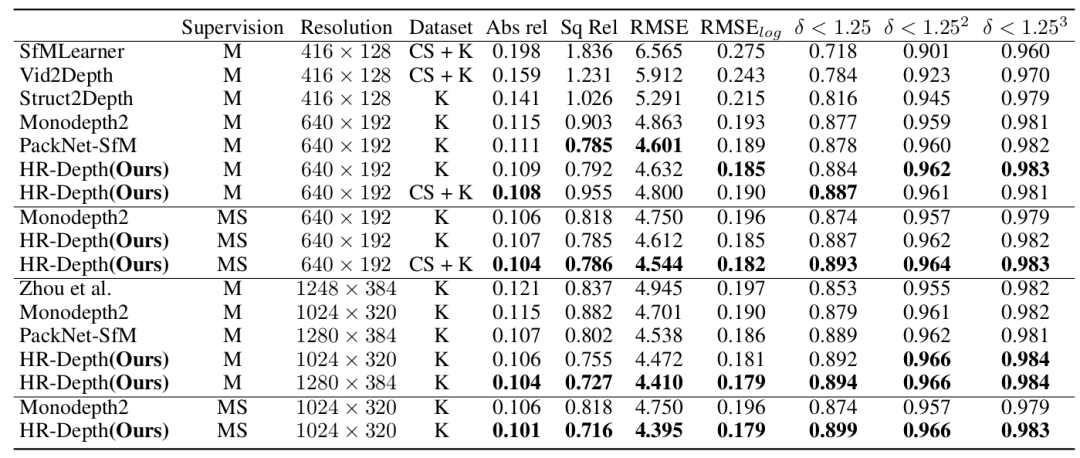
表1 在KITTI数据集上对距离达80m的深度估计的定量结果。误差评价指标Abs Rel、Sq Rel、RMSE和RMSE l og越低越好,精度评价指标δ < 1.25、δ < 1.25 2、δ < 1.25 3越高越好。在数据集列中,CS + K表示在cityscape (CS)上进行预训练和在KITTI(K)上进行微调。M是由单目(M)图像序列监督的DepthNet, MS是由单目和立体(MS)图像监督的DepthNet。在测试时间,我们缩放DepthNet的输出与中值的地面真实激光雷达信息。
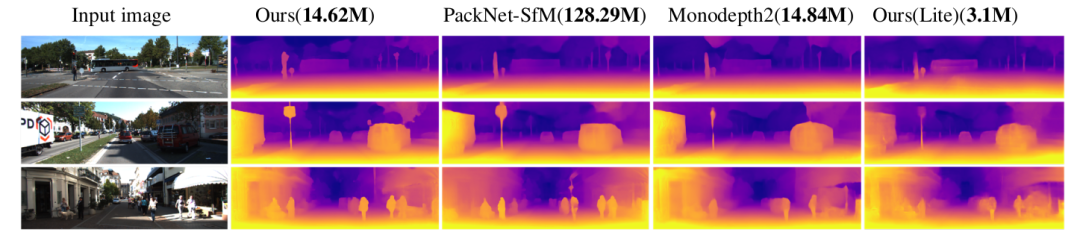
图5 定性单目深度估计性能比较HR-Depth和Lite-HR-Depth与以前的SOTA。来自KITTI数据集的帧。与Monodepth2相比,我们的网络能够预测更尖锐的边缘(Godard等人,2019年),其性能可与PackNet-SfM相比,但参数要少得多。
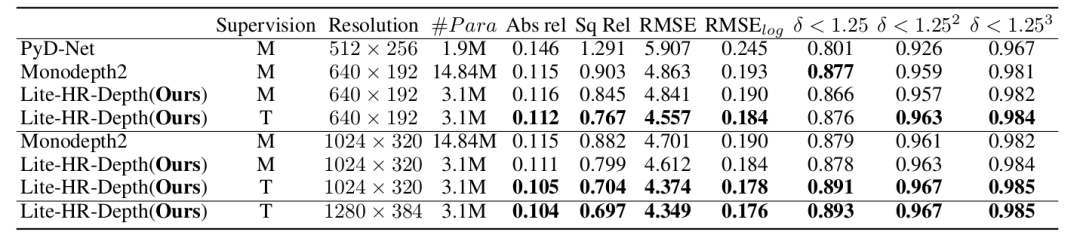
表2 Lite-Network在KITTI数据集上对距离达80m的量化性能。计算矩阵和方法与表2相同。在监督栏中,T是指使用教师网络引导lite网络进行训练。
点击阅读原文, 即可获取本文下载链接。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~















 8657
8657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









