







Abstract
使用图像序列作为唯一的监督源,自监督学习在单目深度估计中显示出巨大的潜力。尽管人们尝试使用高分辨率图像进行深度估计,但预测的精度并没有明显提高。在这项工作中,我们发现其核心原因在于大梯度区域的深度估计不准确,使得双线性插值误差随着分辨率的增加而逐渐消失。为了在大梯度区域获得更准确的深度估计,需要获得具有空间和语义信息的高分辨率特征。因此,我们提出了一种改进的深度网络,HR-Depth,并采用两种有效的策略:(1)重新设计深度网络中的跳过连接以获得更好的高分辨率特征;(2)提出特征融合挤压激励(fSE)模块以更有效地融合特征。
使用Resnet-18作为编码器,HR-Depth在高分辨率和低分辨率下都以最小的参数超过了所有以前最先进的(SoTA)方法。此外,以前最先进的方法是基于相当复杂和深度的网络,具有大量的参数,这限制了它们的实际应用。因此,我们还构建了一个使用MobileNetV3作为编码器的轻量级网络。实验表明,轻量级网络可以在只有20%参数的高分辨率下与许多大型模型(如Monodepth2)相当。所有代码和模型将在https: //github.com/shawLyu/HR-Depth上提供。
Introduction
单幅图像的精确深度估计是帮助计算机重建和理解真实场景的一个活跃研究领域。它在自动驾驶汽车、机器人、增强现实等不同领域也有广泛的应用。虽然有监督的单目深度估计已经取得了成功,但它正受到获取地面真相的昂贵代价的困扰。自监督方法使用图像序列或立体图像的几何约束作为唯一的监督来源。
近期著作(Zhou et al . 2017;Godard等人(2017)在自监督深度估计中,由于模型内存需求大,仅限于低分辨率输入的训练。然而,随着计算和存储能力的提高,越来越多的计算机视觉任务使用高分辨率图像。在深度估计中,(Pillai et al . 2019)引入亚像素卷积层(Shi et al . 2016)来取代反卷积层和调整卷积层,以提高上采样的效果。并且(Godard et al . 2019)直接利用高分辨率图像进行深度估计。虽然上述工作探索了高分辨率深度估计,但在KITTI上性能并没有明显提高。受此启发,我们对现有方法进行了分析,发现其核心原因在于目标边界深度估计不准确。
在深度估计中,目标边界主要由语义信息和空间信息两部分确定。语义信息通过约束像素的类别来获得清晰的边界,空间信息通过几何约束来描述物体的轮廓。在之前的工作中,深度估计网络是基于U-Net(Ronneberger et al . 2015)架构,该架构主要使用跳脱连接来融合语义信息和空间信息。然而,编码器和解码器特征图之间的语义差距太大,导致空间信息和语义信息的整合很差。因此,以往的工作很难在目标边界处得到准确的深度估计。为了减少语义差距,我们重新设计了跳跃连接,以更好地融合特征映射。此外,我们还发现基本卷积不能整合空间信息和语义信息。因此我们建议用特征融合挤压和激励(fSE)块代替它。该分块不仅提高了特征融合效果,而且减少了参数个数。我们在KITTI基准上对我们的结果进行了评估,实验表明,我们设计的网络可以预测更锋利的边缘,并达到(SoTA)。
作为副作用,更高的分辨率输入带来额外的计算成本。因此,轻量化是高分辨率模型设计的关键原则之一。然而,之前的SoTA有大量的参数,如Packnet-SfM有127M的参数,轻量级网络的性能不适合实际应用,如(Poggi et al 2018)。因此,为了保持轻量级网络的高性能,本文引入了一种简单而有效的设计策略。我们在此策略的基础上成功训练了一个轻量级网络,仅用3.1M个参数就能达到Monodepth2的精度。
总而言之,本工作的主要贡献如下:
-
•我们对高分辨率单目深度估计进行了深入分析,并证明预测更准确的边界可以提高性能。
-
•我们重新设计了跳跃连接,以获得高分辨率的语义特征图,这可以帮助网络预测更锋利的边缘。
-
•为了提高特征融合的效率和效果,我们提出了特征融合挤压和激励块。
-
•我们提出了一种简单而有效的轻量级设计策略来训练轻量级深度估计网络,该网络可以达到复杂网络的性能。
Related Work
Supervised Monocular Depth Estimation
单个图像的深度估计是一个不适定问题,因为相同的输入图像可以被投影到多个合理的深度。因此,许多工作都是从监督学习开始的。(Eigen et al . 2015)首次提出了基于RGBD数据集训练的基于学习的深度估计结构。他们的工作将深度估计视为一个回归问题,使用粗到精的网络来获得逐像素的深度值。随着全卷积神经网络的兴起,(Laina et al . 2016)使用卷积层代替全连接层,并使用预训练的编码器进行特征提取。这项工作使深度估计任务能够使用更深的网络进行训练,并且具有与深度传感器相当的精度。为了预测清晰准确的遮挡边界,(Ramamonjisoa et al . 2020)引入了细化网络预测加性残差深度图,以细化第一次估计结果。然而,监督方法由于泛化性能差和难以获得地面真值深度值而陷入瓶颈。于是人们开始探索自监督单目深度估计。
Self-Supervised Monocular Depth Estimation
利用立体图像训练深度网络是一种直观的自我监督方法。(Garg et al . 2016)提出了使用立体对进行自监督深度估计的最早工作之一,(Godard et al . 2017)通过引入左右深度一致性损失产生了优于当代监督方法的结果。为了减少立体摄像机的局限性,(Zhou et al . 2017)首次提出使用possecnn来估计相邻帧之间的相对姿态。这项工作使网络能够完全依赖于单眼图像序列进行训练。(Godard et al . 2019)引入了自动掩蔽和最小重投影损失来解决运动物体和遮挡问题,使Monodepth2成为使用最广泛的基线。为了进一步提高网络性能,(Guizilini et al . 2020b)引入了预训练的语义分割网络和像素自适应卷积来指导深度网络进一步利用语义信息。但是Guizilini等人有两个缺点
2020 b)。首先,我们希望通过自我监督来缓解像素级标注的压力,但在这项工作中我们需要昂贵的语义标签。其次,语义分割和深度估计网络应同时运行。这将增加深度估计的成本。此外,(Guizilini et al . 2020a)利用装箱和解装箱块来保留图像中的空间信息和低层特征。他们认为标准的卷积和池化操作不能保留足够的细节,因此他们提出了3D装箱和拆包块来取代标准的下采样和上采样操作。装箱和拆包块是可逆的,因此它们可以恢复重要的空间信息用于深度估计。但这两个块依赖于三维卷积,因此网络参数的数量大大增加,难以部署到移动设备上。但这两项工作表明,丰富的语义和空间信息可以获得更清晰的边缘,从而提高深度估计的精度。
在我们的工作中,我们表明,通过简单地融合编码器提取的信息,我们可以获得具有空间和语义信息的理想特征。通过我们富有洞察力的设计,无需引入更多参数,这些功能显着提高了整体性能,获得更锐利的边缘。
Lightweight Network for Depth Estimation
从单幅图像中进行深度估计也是一项非常有吸引力的技术,在机器人自主导航中具有许多意义。因此,有必要利用深度预测网络在CPU上快速推断出准确的深度图。(Wofk et al . 2019)提出了一种轻量级的监督深度估计网络,该网络采用编码器-解码器架构,经过修剪后包含1.34M个参数。在无监督的领域,(Poggi et al . 2018;Aleotti et al . 2020)提出了带有190万个参数的PyDNet。虽然上述两种作品参数较少,但其性能也下降了很多。在本文中,我们提出了一种新颖而简单的网络设计策略,可以使轻量级网络的性能与复杂网络相当甚至超越。
HR-Depth Network
Problem Formulation
在自监督单目深度估计任务中,目标是使用深度网络fD从RGB图像I中学习深度信息D。由于缺乏地真深度值,我们需要额外的网络fP来预测源图像s和目标图像It之间的相对姿态p = [R|t]。通常情况下,目标图像为It,源图像集由相邻图像It−1,It+1组成。通过最小化光度重投影误差来优化深度网络:
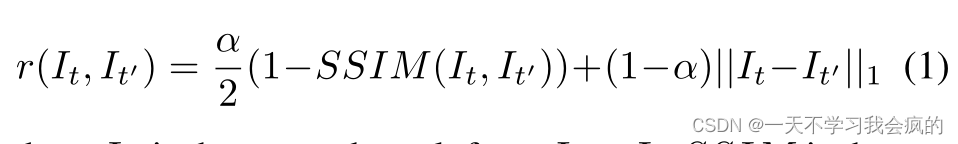
其中It’为Is到It的变换结果,SSIM为结构相似度算子,用于测量patch的相似度。我们遵循(Godard et al . 2019)中每像素最小损失的形式来处理遮挡。光度损失记为:
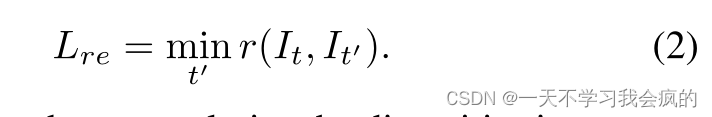
此外,为了正则化无纹理低图像梯度区域的差异,使用边缘感知平滑正则化项:
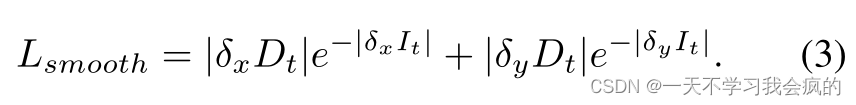
其中δx和δy符号用于深度和RGB图像的部分微分,矩阵的指数运算是一个元素操作。所以最终的损失函数是在多尺度图像上的重投影损失和平滑损失之和:
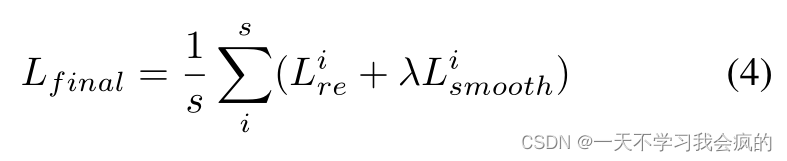
其中s为尺度数,λ为光滑项的权值。
Analysis on High Resolution Performance
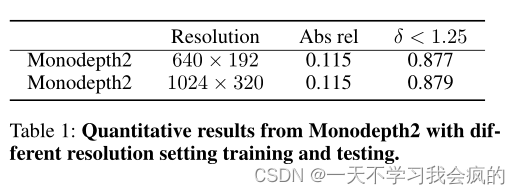
作为密集预测任务的共识,更高的分辨率本能地带来更准确的结果(Sun et al . 2019;Zhou et al . 2019)。特别是在深度估计任务中,像素级视差更重要,因为它与深度误差的平方成反比(Y ou et al 2019)。然而,我们注意到,之前的大多数工作使用低分辨率输入,并将低分辨率预测插值到高分辨率预测。低分辨率的实验设置本质上使得这些作品无法受益于高分辨率的图像。一些方法还进行高分辨率实验,用更大的图像训练模型(Godard等人2019;Pillai et al, 2019)。然而,在小输入上的性能改进非常有限,即(Pillai等人2019),他们的模型无法利用高分辨率。例如,我们用更高的分辨率设置评估了最近名为Monodepth2的知名作品(Godard et al 2019)。如表1所示,在高分辨率和低分辨率设置下,深度误差几乎相同。因此,我们认为他们的方法不能充分利用高分辨率输入的信息。
表1 Monodepth2在不同分辨率设置下训练和测试的定量结果。
深入分析了现有方法无法改善高分辨率输入深度估计的实际原因。我们发现双线性插值过程对低分辨率预测上采样到高分辨率预测最关键的是不可忽略的误差。详细地说,以monodepth (Godard等)为例2019)作为一个例子,当输入小的模型时,我们需要对输出进行上采样以获得所需的高分辨率的插值。由图2可以看出,在实例边缘等深度梯度较大的区域,局部预测误差会严重影响全局精度,而在深度梯度较小的区域,局部预测误差会严重影响全局精度。有趣的是,当低分辨率输出的预测较差时,如图2右上部分,它会意外地补偿双线性插值的局部预测误差。结果表明,在低分辨率下可以达到与高分辨率相当的性能。换句话说,大多数方法不能从更大的输入中获益的实际原因是,这两种设置之间的差距被上述有趣的现象弥补了。因此,只有对深度梯度较大的区域进行更精确的预测,才能使高分辨率预测更加准确。我们还可以总结出,通过在大梯度区域和更清晰的边缘预测更准确的深度,可以提高高分辨率的性能。
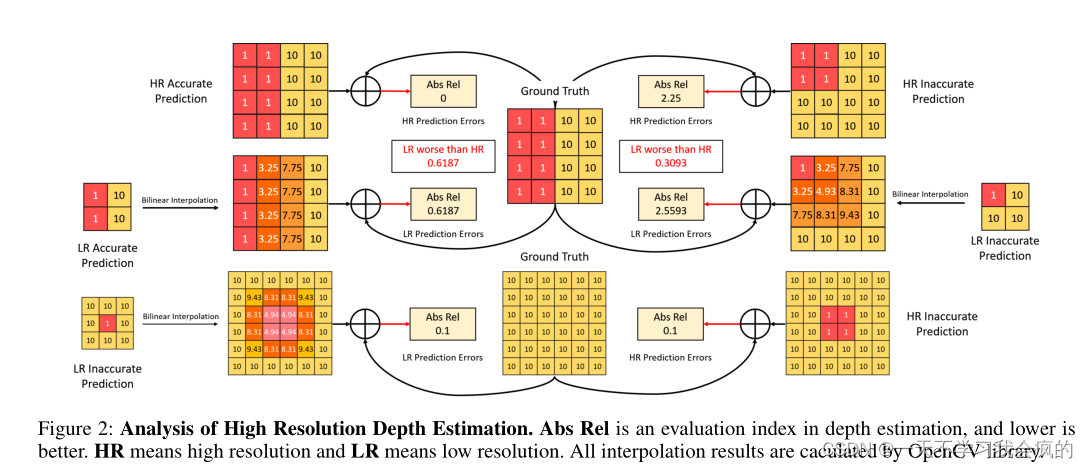
图2 高分辨率深度估计分析。Abs Rel是深度估计中的一个评价指标,越低越好。HR表示高分辨率,LR表示低分辨率。所有插值结果均由OpenCV库计算。
Redesign Skip Connection
基于以上分析,为了预测更准确的边界,我们尝试从空间和语义两个方面对其进行增强,因为我们认为(1)语义信息可以产生不同类别之间的边界,从而减少误分类造成的深度估计误差;(2)空间信息可以帮助网络知道边界的位置,从而更好地估计边界。在这里,我们将首先讨论具有U-Net架构的深度网。
跳接是U-Net的核心组成部分之一,其目的是恢复下采样过程中丢失的信息。然而,我们认为直接组合来自不同层的特征可能不太有效,因为它们之间在语义水平和空间分辨率上存在差距。正如之前的研究(Zhang et al . 2018)所表明的,随着层数的加深,深度神经网络代表了更多的语义特征。因此,如果底层特征可以包含更多的语义信息,比如相对清晰的语义边界,那么融合就会变得更容易,我们可以通过解码这些特征来获得更清晰的深度估计。
为了减少语义和分辨率差距,我们提出了受(Zhou et al . 2018)启发的密集跳跃连接。如图3所示,除了原始编码器和解码器中的节点外,我们还添加了许多中间节点来聚合特征。设xei表示编码器节点Xei的输出,xdi表示节点Xdi的输出,xi,j表示节点Xi,j的输出,其中i表示沿编码器的下采样层,j表示沿跳过连接的聚合层。考虑通过DepthNet传递的单个图像I。特征映射的堆栈计算为
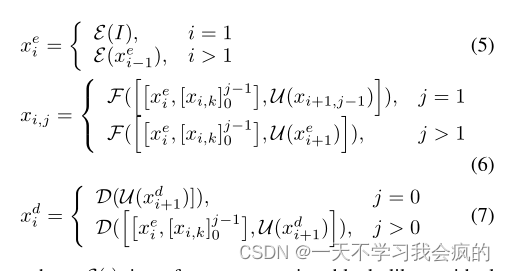
式中,E(·)是残差块一样的特征提取块,F(·)是由卷积运算和激活函数组成的特征融合块,D(·)是由特征融合块组成的特征融合运算,U(·)是由卷积和双线性插值运算组成的上采样块,[·]表示拼接层。密集跳跃连接和每个节点的详细信息如图3所示。
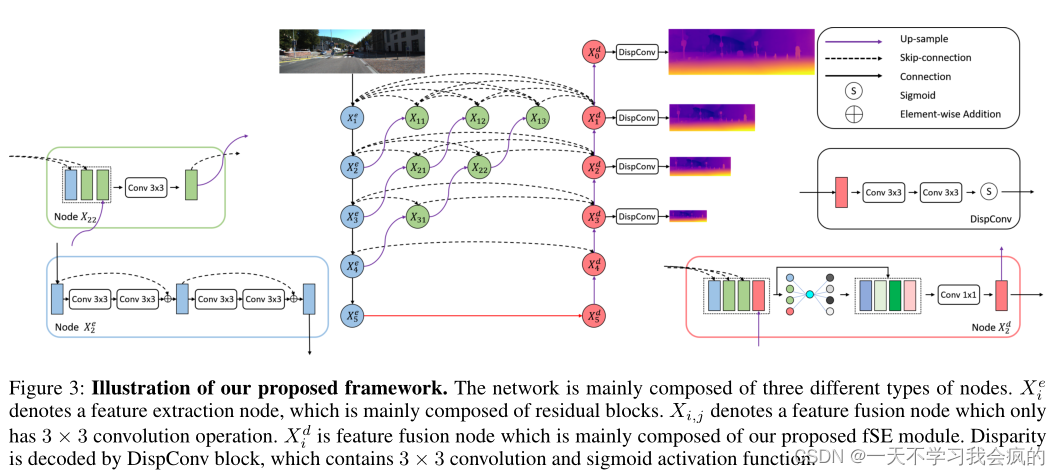
图3 我们提出的框架的说明。该网络主要由三种不同类型的节点组成。xei标识一个特征提取节点,该节点主要由残差块组成。Xi,j是特征融合节点,主要由本文提出的fSE模块组成。视差解码由包含3 × 3卷积和sigmoid激活函数的disconv块实现。
通过密集的跳跃连接,解码器中的每个节点都呈现出最终聚合特征图、中间聚合特征图和来自编码器的原始特征图。然后,解码器可以使用具有更丰富语义信息的高分辨率特征来预测更清晰的深度图。
Feature Fusion SE Block
基于U-Net的深度网络采用3 × 3卷积将上采样特征图与编码器原始特征图融合,卷积参数计算为
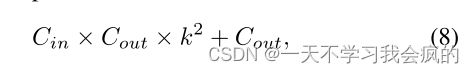
式中,Cin为输入通道数,Cout为输出通道数,k为卷积核大小。就像(Huang et al . 2017)一样,密集的跳跃连接使得解码器节点的输入特征映射急剧增加,因此这种操作必然会降低网络的效率。受(Hu et al . 2019)的启发,我们提出了一种轻量级模块,特征融合挤压激励(fSE),以提高特征融合的精度和效率。fSE模块通过全局平均池化压缩特征映射来表示信道信息,并使用两个完全连接(FC)层和一个s型函数来衡量每个特征的重要性,同时重新加权它们。然后利用1×1卷积对通道进行融合,得到高质量的特征图。该模块的参数号为
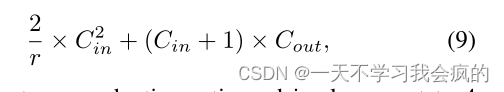
式中,r为还原比,本文所有实验均取4。当使用Resnet-18作为编码器时,fSE模块可以将HRDepth的参数从16.06M降低到14.62M,甚至低于Monodepth2的14.84M参数。同时,由于fSE模块将更加注重特征融合,网络性能也将得到提升。
Lite-HR-Depth
以往的大多数SoTA自监督单目深度估计算法都是基于相当复杂的深度神经网络和大量的参数,这限制了它们在嵌入式设备等实际平台上的应用。然而,对于现有的轻量级网络,如PyDNet(Poggi et al 2018),当它们减少参数数量时,准确性大大降低。为了使深度估计网络摆脱GPU的限制,同时保持其良好的性能,我们提出了一个简单而有效的轻量级网络,命名为Lite-HR-Depth。
我们的Lite-HR-Depth采用MobileNetV3作为编码器,缩小了特征融合和解码器节点,只有3.1M参数,其中2.82M参数来自编码器。此外,我们通过知识蒸馏进一步提高了Lite-HR-Depth的准确性(Hinton et al 2015)。对于自监督学习,由于缺乏ground truth,我们不得不使用view syntheses作为监督信号,这增加了训练小网络的难度。因此,我们建议从学习到的大模型中寻找一种直接的监督形式。通过以自监督的方式训练一个大型网络,我们得到了一个高性能的网络实例T。然后我们训练第二个轻量模型的实例,即S,使其最小化
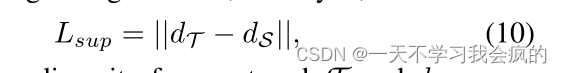
其中dT表示与网络T的差异,dS表示与网络S的差异。通过这种策略,我们得到了一个比T更精确的网络S。值得注意的是,Lite-HR-Depth的参数只有Monodepth2的20%,但在高分辨率下甚至可以比Monodepth2表现得更好。我们将在实验中展示对该生命网络的更多分析。
Experiments
在本节中,我们验证了(1)我们重新设计的skipconnection可以改善结果,特别是预测更锋利的边缘;(2)fSE模块可以显着减少参数并提高精度;(3)我们提出的设计方法可以轻松获得高精度的轻量级网络。我们在KITTI数据集(Geiger et al 2012)上评估了我们的模型,以便与之前发表的单目方法进行比较。
数据集
KITTI。KITTI基准(Geiger et al . 2012)是深度评估中应用最广泛的方法。我们采用(Eigen et al . 2015)的数据分割,并删除静态帧,随后采用(Zhou et al . 2017)。最终,我们使用39810张图像进行训练,4424张用于验证,697张用于评估。此外,我们对所有图像使用相同的内禀,将相机的主点设置为图像中心,将焦距设置为KITTI中所有焦距的平均值。对于立体训练,我们将两个立体帧之间的变换设置为固定长度的纯水平平移。
CityScapes。CityScape (Cordts et al . 2016)是另一个大型自动驾驶数据集。所以我们也在CityScape上进行预训练我们的结构的实验,然后我们在KITTI数据集上进行微调和评估。leftImg8bit序列被认为是cityscape数据集的训练分割,使用与KITTI相同的训练参数进行20次epoch。
Implementation Details
我们在PyTorch(Paszke et al 2017)上实现我们的模型,并在一个Telsa V100 GPU上训练它们。我们使用Adam Optimizer(Kingma et al . 2014), β1 = 0.9, β2 = 0.999。
deepnet和PoseNet训练了20个epoch,批处理大小为12。两种网络的初始学习率均为1 × 10−3,经过15次迭代后学习率衰减为10倍。训练序列由三个连续的图像组成。我们设置SSIM权重为α = 0.85,平滑损失权重为λ = 1 × 10−3。
DepthNet。我们使用ResNet-18(He et al . 2016)作为编码器实现HR-Depth,并使用MobileNetV3(Howard et al . 2019)作为lite - hrdepth的编码器。我们提出的架构的细节将在补充材料中描述。这四种视差图都用于训练时的损失计算。为了评估,我们只使用最大输出规模,之后使用双线性插值调整到真实深度分辨率。
PoseNet。PoseNet的架构由(Godard et al . 2019)提出。PoseNet建立在Resnet-18上,第一级卷积通道从3改为6,这允许相邻的帧馈送到网络中。PoseNet的输出是用6自由度矢量参数化的相对位姿。前三个维度表示平移向量,后三个维度表示欧拉角。
Depth Estimation Performance
我们使用(Eigen et al . 2015)中描述的指标评估KITTI的深度预测。评估结果总结在表2中,然后在图4中定性地说明了它们的性能。我们表明,我们提出的体系结构优于所有现有的SoTA自监督方法。我们也优于最近的模型(Guizilini等)2020a),参数120M。此外,我们还引入了一个额外的未标记视频来源,cityscape数据集(CS+K),我们可以进一步提高DepthNet的性能。我们还表明,在更高的分辨率下,模型的性能显着提高。在以最小的参数处理高分辨率的输入图像时,我们获得了最好的结果。
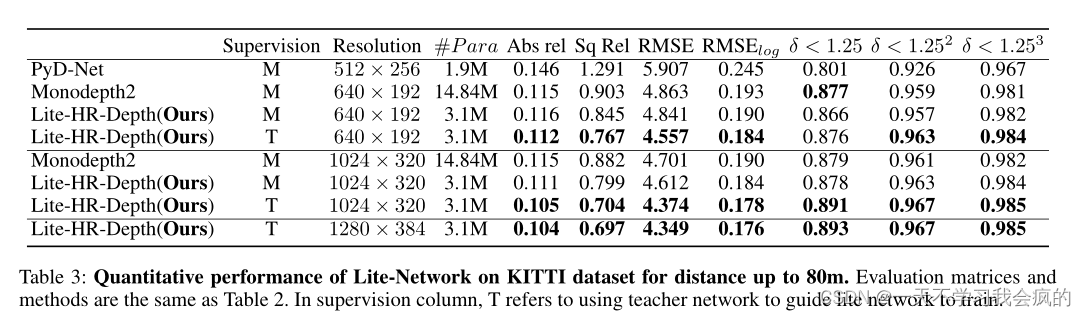
如表3所示,当使用低分辨率图像进行训练时,在教师(T)网络监督下,Lite-HR-Depth的表现优于Monodepth2。然而,当使用高分辨率图像进行训练时,在没有额外监督信号(M)的情况下,Lite-HR-Depth可以比Monodepth2表现得更好。
表2 在KITTI数据集上深度估计的定量结果,距离可达80m。误差评价指标Abs Rel、Sq Rel、RMSE和RMSElog越低越好,准确度评价指标δ < 1.25、δ < 1.252、δ < 1.253越高越好。在数据集列中,CS + K是指在cityscape (CS)上进行预训练,在KITTI(K)上进行微调。M表示由单眼(M)图像序列监督的深度网络,MS表示由单眼和立体(MS)图像监督的深度网络。在测试时,我们使用中值地面真值激光雷达信息来缩放深度网络的输出
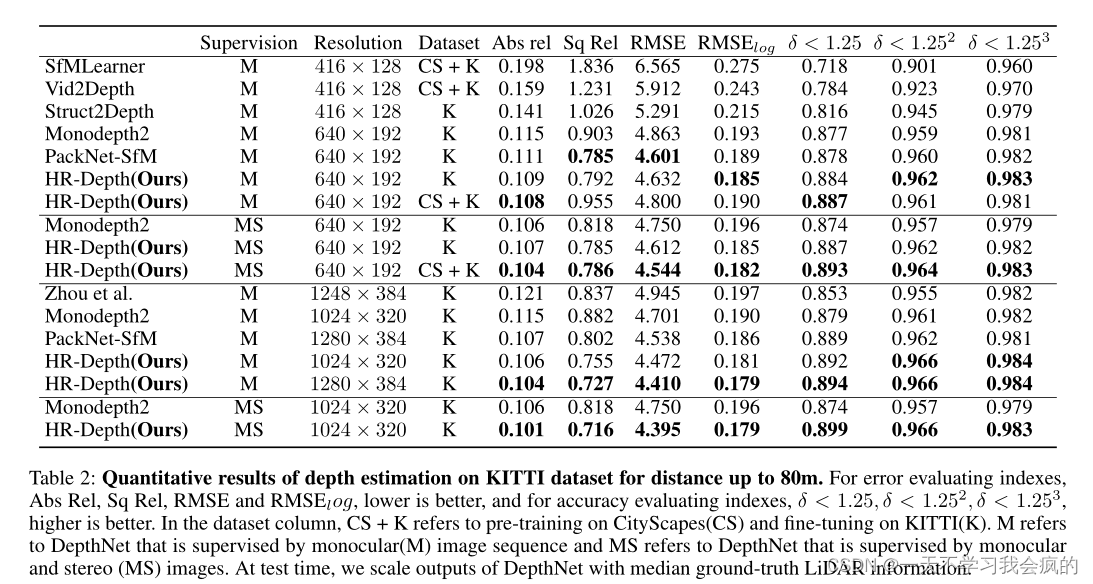
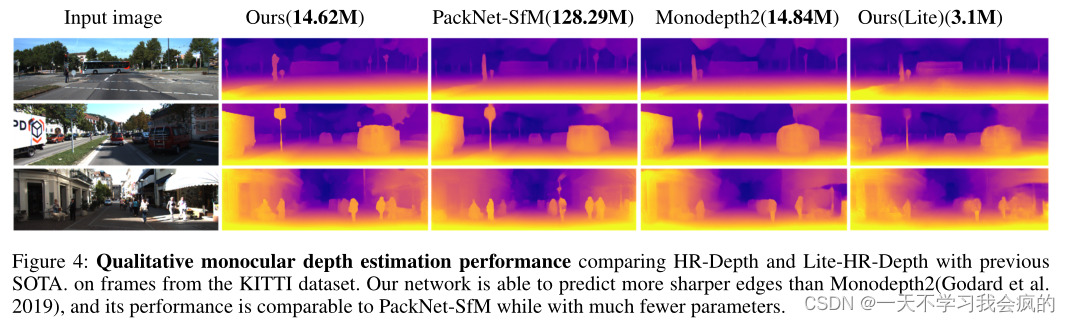
图4 定性单眼深度估计性能比较HR-Depth和Lite-HR-Depth与以前的SOTA。从KITTI数据集的帧。我们的网络能够预测比Monodepth2(Godard等人)更锐利的边缘2019),其性能与PackNet-SfM相当,但参数少得多。
表3 距离达80m的KITTI数据集上Lite-Network的定量性能。评价矩阵和方法如表2所示。在督导栏中,T是指利用教师网络引导lite网络进行培训。
Ablation Studies
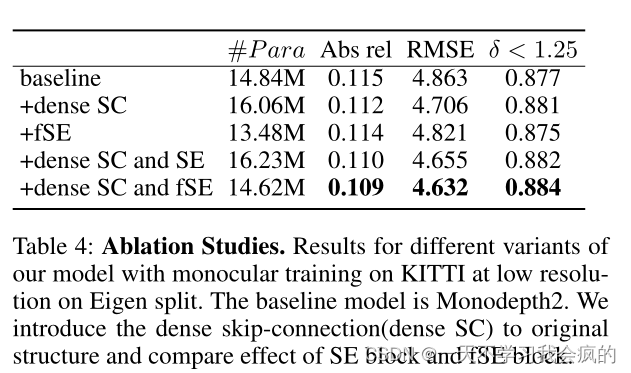
为了进一步探索我们的网络提供的性能改进,我们执行了一个烧蚀分析,引入了不同的体系结构组件。我们选择Monodepth2作为我们的基线模型,我们可以看到我们所有的贡献都可以带来显著的改进。
密集跳接的好处。如图5所示,跳跃连接中的语义差距太大,无法很好地融合,但密集的跳跃连接可以利用中间特征,有效地减少编码器和解码器之间的语义差距。因此,我们可以获得具有更多语义信息的高分辨率特征图,从而显著提高性能。
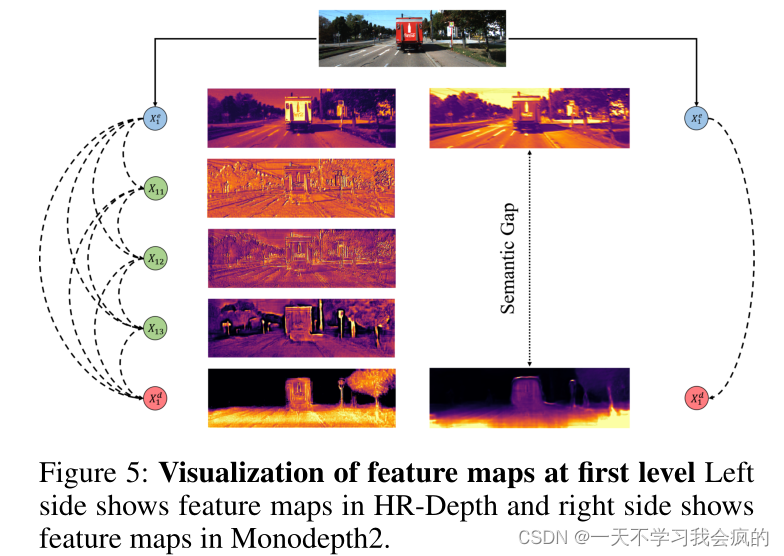
图5 左侧为HR-Depth的特征图,右侧为Monodepth2的特征图。
fSE块。为了提高特征融合和计算效率,设计了fSE块。为了验证fSE,我们还将SE(Hu et al . 2019)应用于密集跳跃连接,并将其与提议的fSE块进行比较。如表4所示,SE块会引入额外的参数,但我们的fSE块可以大大减少密集跳接引入的参数,进一步提高网络的性能,甚至优于SE块。
表4 烧蚀的研究。我们的模型在低分辨率的KITTI上进行单眼训练的不同变体的结果。基线模型是Monodepth2。在原结构中引入密集跳接(dense SC),并比较了SE块体和fSE块体的效果。
Feature map visualization
如前所述,重新设计跳连的目的是为了减少语义和空间差距,从而获得具有丰富语义信息的高分辨率特征图。因此,为了说明特征融合的效果,我们可视化了中间特征映射,并绘制了fSE的输出,以探索中间特征映射特征融合的影响。图4显示,像Xe1这样的底层节点经过轻微的转换,得到的是简单的空间信息,而像Xd2这样的解码器节点的输出得到的是丰富的语义信息。因此,Xe1和Xd2的表示能力之间存在很大的差距。密集的跳跃连接可以逐渐向中间特征添加语义信息,从而减少节点Xe1和Xd2之间的间隙。
Conclusion
在本文中,我们展示了如何提高高分辨率估计性能的理论和经验证据。在此基础上,我们提出了一种新的卷积网络架构,称为HR-Depth,用于高分辨率自监督单目深度估计。它利用新颖的密集跳跃连接和fSE块来减少分辨率和语义之间的差距。尽管该方法仅在图像序列上进行训练,但其性能优于其他现有的自监督和半监督方法,甚至可以与监督方法相媲美。此外,我们还提出了一种简单而有效的轻量级网络设计策略。实验表明,Lite-HR-Depth可以在较少参数的情况下达到与大型模型相当的效果。















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









