






来源:深蓝具身智能
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

鸣谢!所有参与本次年度论文推荐的青年学者们

数据来源
2024年被认为是具身智能元年,这一年里,具身智能学术界发表了大量开创性的论文,引起了整个行业的关注。
同时,2025年虽然刚刚过去一个月,但也涌现出了不少佳作。
那么,哪些是具有「影响力」的高质量论文,值得我们反复研读的?
为此,我们采访调研了数十位优秀的具身智能领域一线研究者,推荐出他们心目中认为的年度最具影响力10篇论文。
(或许,每一位研究者心中都有自己的十佳论文,欢迎推荐补充)
希望这些通过合力推荐而来的论文,能成为大家探索具身智能及其相关领域的得力参考。

近一年里具身智能领域
最具影响力的10篇论文
(民榜,排名不分先后)
Universal Manipulation Interface:In-The-Wild Robot Teaching Without In-The-Wild Robots

机构:斯坦福大学、哥伦比亚大学、丰田研究所
奖项:RSS 2024的最佳系统论文奖
推荐理由:该项工作解决了机器人训练中“先有鸡还是先有蛋”的难题。
论文内容:作者提出了一种机械臂统一接口UMI,提供了一个创新的数据收集方法。它允许将野外人类演示的技能直接转移到可部署的机器人策略中(机器人的观察和行为表示)。
UMI的硬件和软件系统开源地址:https://umi-gripper.github.io
论文地址:https://arxiv.org/pdf/2402.10329
实验结果:以下是基于UMI采集的数据进行模型训练叠衣服的效果。
OpenVLA:An Open-Source Vision-Language-Action Model
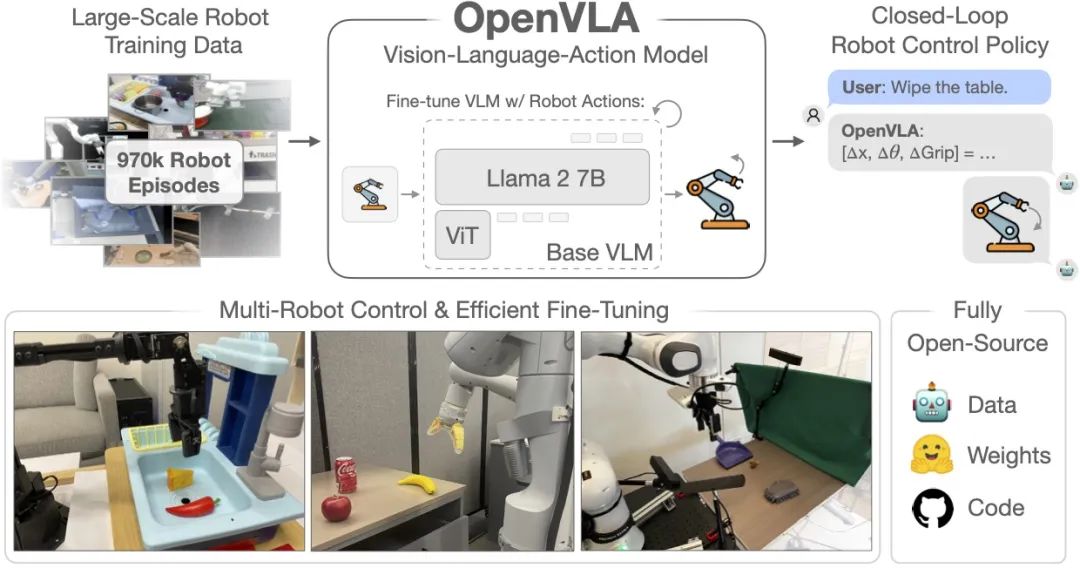
机构:斯坦福大学、加州大学伯克利分校、谷歌DeepMind等
奖项:CoRL 2024最佳论文提名奖
推荐理由:OpenVLA是首个大规模的开源VLA模型,它降低了研究者和开发者在机器人控制和具身智能领域工作的门槛。
论文内容:OpenVLA模型的关键创新在于基于97万个真实世界机器人演示数据进行训练,并建立在Llama 2语言模型和DINOv2、SigLIP预训练特征的视觉编码器之上,这使得OpenVLA在29个任务和多种机器人形态上展现出强大的性能,其绝对任务成功率比封闭模型RT-2-X高出16.5%,同时参数数量减少了7倍。此外,OpenVLA还具有出色的泛化能力、计算效率以及开源性,为视觉-语言-动作模型的研究和应用提供了新的思路和工具。
OpenVLA的开源链接:https://github.com/openvla/openvla
论文地址:https://arxiv.org/pdf/2406.09246
π0: A Vision-Language-Action Flow Model for General Robot Control
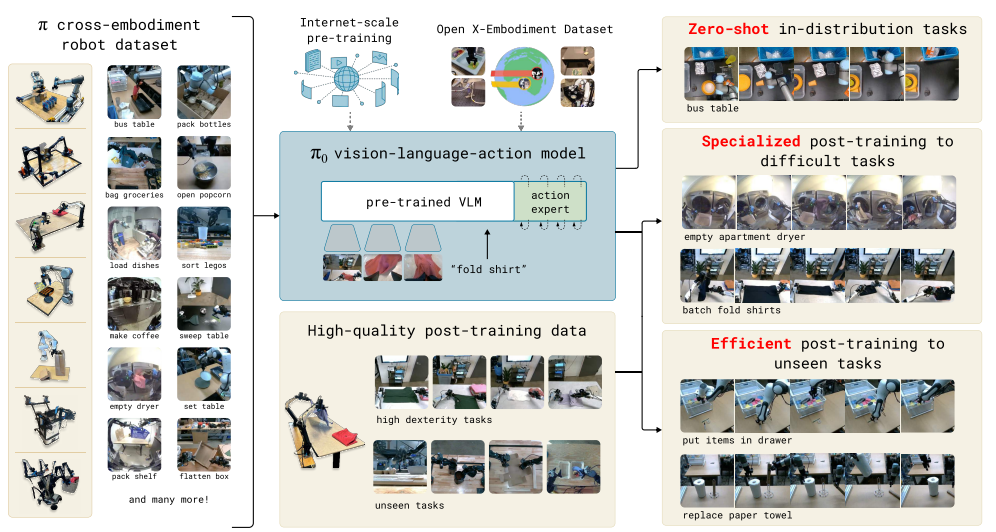
机构:Physical Intelligence(一家具身智能创业公司)
推荐理由:由被认为是全球具身智能领域“最强创始团队”的Physical Intelligence发布的机器人大模型,机器人泛化能力大幅提升。
论文内容:本文介绍了一种名为π0的模型,旨在解决机器人学习中的主要挑战,包括数据稀缺性、泛化能力和鲁棒性。π0模型基于预训练的视觉-语言模型(VLM),并结合了流匹配架构,能够理解和执行复杂的物理任务。该模型能够处理零样本学习,并在高质量数据上进行微调,以实现如叠衣服、清理桌子和组装盒子等多阶段任务。π0展示了在灵巧性、泛化能力和鲁棒性方面的显著进步,为实现更智能的机器人系统提供了新的可能性。
论文地址:https://arxiv.org/pdf/2410.24164
RDT-1B: A DIFFUSION FOUNDATION MODEL FOR BIMANUAL MANIPULATION
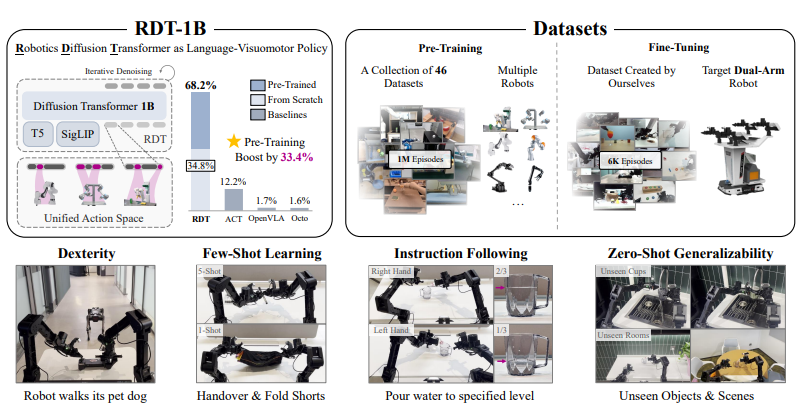
机构:清华大学AI研究院TSAIL团队
推荐理由:本文开创性地提出了一种针对双臂操作的扩散基础模型,是全球参数规模最大的针对双臂机器人操作任务的扩散基础模型。
论文内容:本文介绍了机器人扩散变换器(RDT-1B),这是一种针对双臂操作的开创性扩散基础模型,能够有效地表示多模态特性,捕捉机器人数据的非线性和高频特性,并解决数据稀缺问题。RDT-1B基于扩散模型,采用可扩展的Transformer架构来处理多模态输入的异质性。为了解决数据稀缺问题,引入了物理上可解释的统一动作空间,可以统一各种机器人的动作表示,同时保留原始动作的物理意义,促进学习可迁移的物理知识。RDT-1B在迄今为止最大的多机器人数据集上进行了预训练,并扩展到1.2B参数,这是最大的基于扩散的机器人操作基础模型。
论文地址:https://arxiv.org/pdf/2410.07864
ORION: Vision-based Manipulation from Single Human Video with Open-World Object Graphs
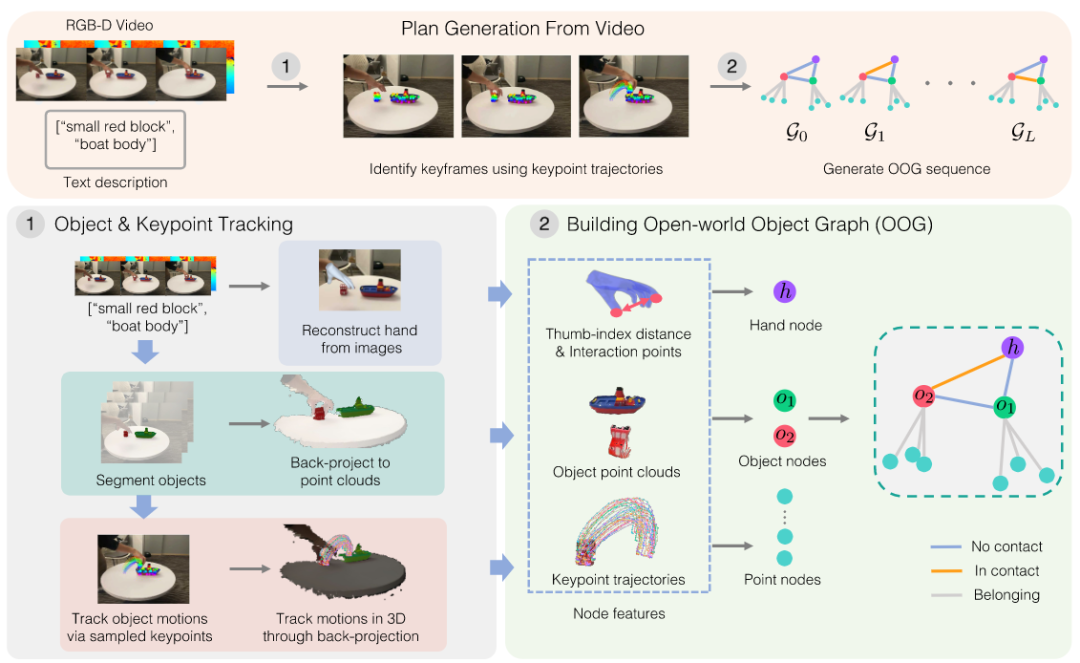
机构:UT Austin和Nvidia
推荐理由:该论文提出了一种从单个人类视频中学习视觉操作技能的方法,能够通过提取开放世界中的对象图谱来构建可泛化的操作策略,具有很强的创新性和实用性。
论文内容:本文提出了一种以物体为中心的方法,使机器人能够从人类视频中学习基于视觉的操作技能。研究了在开放世界环境下从单个人类视频中模仿机器人操作的问题,其中机器人必须从一个视频演示中学习操作新物体。引入了ORION算法,通过从单个RGB-D视频中提取物体为中心的操作计划并推导出一个依赖于提取计划的策略来解决这个问题。该方法使机器人能够从iPad等日常移动设备捕捉的视频中学习,并将策略推广到具有不同视觉背景、摄像机角度、空间布局和新物体实例的部署环境中。系统地评估了该方法在短期和长期任务中的表现,展示了ORION在从单个人类视频中学习开放世界操作方面的有效性。
论文地址:https://arxiv.org/pdf/2405.20321
HumanPlus: Humanoid Shadowing and Imitation from Humans

机构:斯坦福大学
奖项:Best Paper Award Finalist (top 6) at CoRL 2024
推荐理由:项目展示了一个全栈式系统,该系统使人形机器人能够从人类数据中学习运动和自主技能。
论文内容:这篇论文介绍了一个名为HumanPlus的全栈人形机器人系统,用于从人类数据中学习复杂的自主技能。该系统的核心包括:
一个实时影子系统,允许人类操作员使用单个RGB相机和Humanoid Shadowing Transformer(HST)来全身控制人形机器人,该HST是一种在模拟中训练的大量人类运动数据的low-level策略。
人形模仿Transformer(HIT),一种模仿学习算法,使用40个演示就能高效地学习双目感知和高自由度控制。通过影子系统和模仿学习算法的协同作用,HumanPlus允许直接在真实世界中学习全身操纵和运动技能,如穿鞋站立行走,仅使用最多40个演示就达到60-100%的成功率。
论文地址:https://arxiv.org/pdf/2406.10454
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
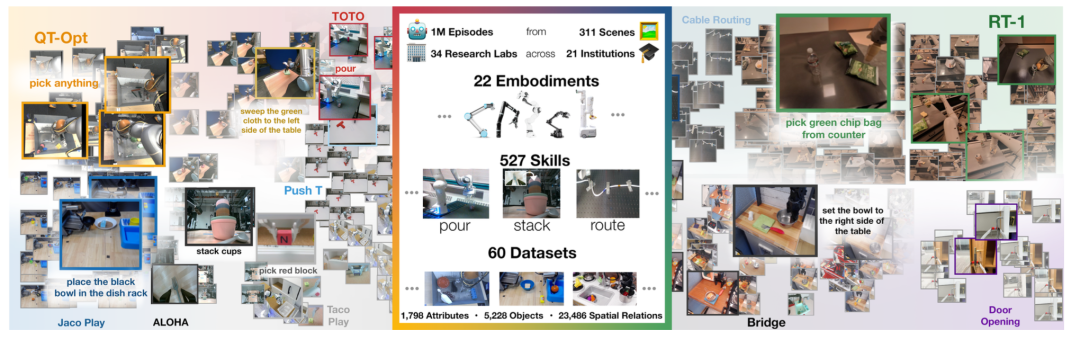
机构:谷歌 DeepMind 联手斯坦福大学等21个机构
奖项:2024年IEEE国际机器人与自动化会议(ICRA)的最佳论文奖
推荐理由:数据极大限制了具身智能的发展,本文贡献了迄今为止最大的开源真实机器人数据集。
论文内容:这篇论文本文介绍了Open X-Embodiment数据集,这是迄今为止最大的开源真实机器人数据集。该数据集包含超过100万条真实机器人轨迹,涵盖22个机器人实例,从单臂机器人到双手机器人和四足机器人。数据集由全球21个机构合作创建,汇集了60个现有机器人数据集,展示了527种技能(160,266个任务)。该数据集旨在推动通用机器人策略的学习,通过在多样化机器人平台和环境数据上训练模型,提高模型的泛化能力和跨平台学习能力。基于该数据集训练的RT-X模型表现出正迁移,能够通过利用其他平台的经验来提高多个机器人的能力。
论文地址:https://arxiv.org/pdf/2310.08864
RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
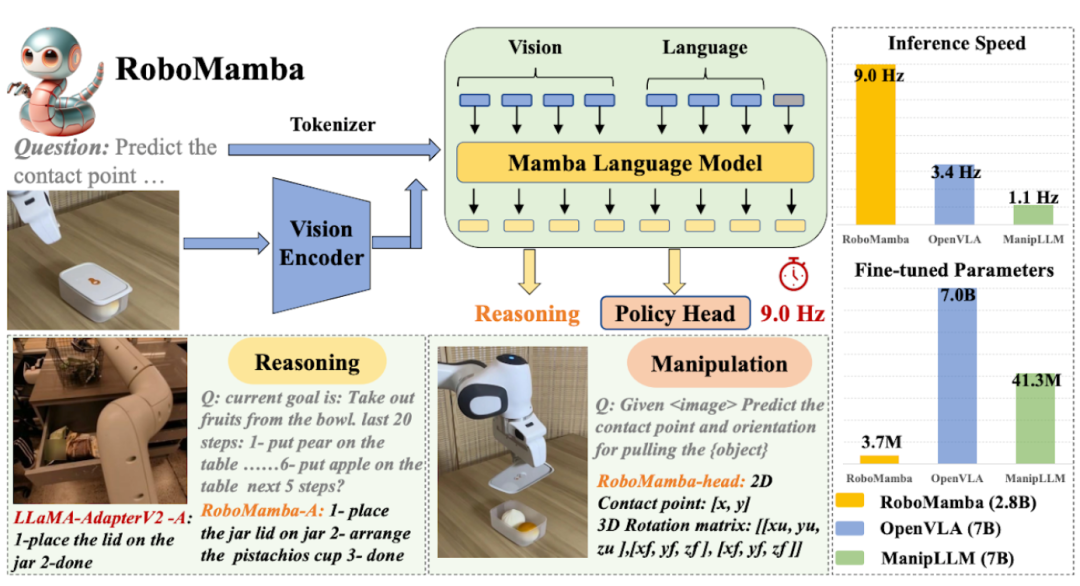
机构:北京大学、北京智源人工智能研究院(BAAI)
推荐理由:本文创新性地将视觉编码器与高效的 Mamba 语言模型集成,构建了全新的端到端机器人多模态大模型。
论文内容:这篇论文介绍了一个名为RoboMamba的多模态状态空间模型,旨在提高机器人的推理和操作能力,同时保持高效的微调和推理。RoboMamba通过以下方式实现这一目标:
视觉编码器与Mamba模型的集成:首先将视觉编码器与Mamba模型集成,通过协同训练将视觉数据与语言嵌入对齐,使模型具备视觉常识和机器人相关推理能力。
高效的微调策略:为了进一步使RoboMamba具备动作姿势预测能力,探索了一种具有简单策略头的高效微调策略。一旦RoboMamba具备足够的推理能力,它就可以用最少的微调参数(模型的0.1%)和时间(20分钟)获得操作技能。
出色的推理和姿态预测能力:在实验中,RoboMamba在通用和机器人评估基准上展示了出色的推理能力。同时,模型在模拟和真实世界实验中展示了令人印象深刻的姿态预测结果,推理速度比现有的机器人多模态大语言模型(MLLM)快7倍。
论文地址:https://arxiv.org/pdf/2406.04339
EgoMimic: Scaling lmitation Learning via Egocentric Video
机构:Georgia Tech和斯坦福大学
推荐理由:EgoMimic超越了最先进的模仿学习方法,并能够推广到全新的场景。
论文内容:本文介绍了一个名为EgoMimic的全栈框架,通过人类具身数据(特别是与3D手部跟踪配对的以自我为中心的人类视频)扩展操作。EgoMimic通过以下方式实现这一目标:(1)使用符合人体工程学的Project Aria眼镜捕获人类具身数据的系统,(2)一种低成本的双手操纵器,可最大限度地缩小与人类数据的运动学差距,(3)跨域数据对齐技术,(4)一种在人类和机器人数据上共同训练的模仿学习架构。与仅从人类视频中提取高级意图的先前研究相比,该方法将人类和机器人数据平等地视为具身演示数据,并从两个数据源中学习统一的策略。EgoMimic在一系列多样化的长视界、单臂和双手操作任务上取得了显著的改进,并能够泛化到全新的场景。最后,展示EgoMimic的良好规模化趋势,其中添加1小时的额外手部数据比添加1小时的额外机器人数据更有价值。
论文地址:https://arxiv.org/pdf/2410.24221
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation
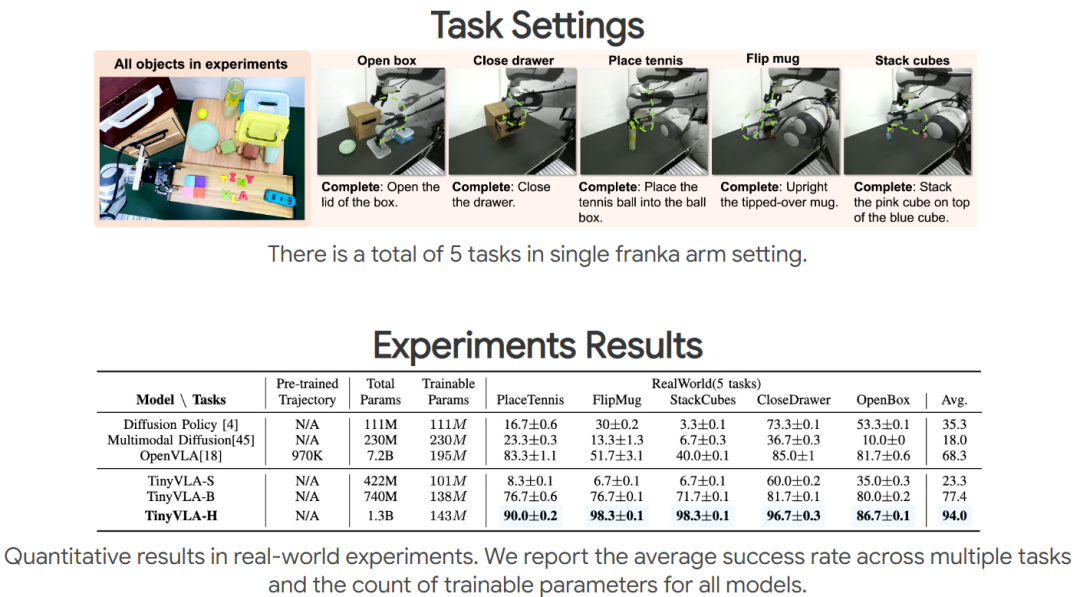
机构:华东师范大学、上海大学、Syracuse大学、北京人形机器人创新中心、美的集团
推荐理由:TinyVLA显著优于现有的VLA模型OpenVLA,在速度和数据效率上表现更佳,同时泛化性更强。
论文内容:本文介绍了一个新的紧凑型视觉-语言-动作(VLA)模型系列,称为TinyVLA,旨在解决现有VLA模型在推理速度慢和需要大量机器人数据进行预训练方面的挑战。TinyVLA具有两个关键优势:(1)更快的推理速度,(2)更高的数据效率,无需预训练阶段。框架包括两个基本组件:(1)使用强大的高速多模态模型初始化策略主干,(2)在微调过程中集成扩散策略解码器,以实现精确的机器人动作。在模拟和真实机器人上的广泛评估表明,TinyVLA在速度和数据效率方面显著优于现有的VLA模型OpenVLA,同时提供相当或更优异的性能。此外,TinyVLA在各个维度上都表现出强大的泛化能力,包括语言指令、新物体、未见过的位置、物体外观的变化、背景变化和环境变化,通常可以匹敌或超过OpenVLA的性能。
论文地址:https://arxiv.org/pdf/2409.12514
除了以上推荐的2024年的10篇论文外,还有23年、25年的代表性论文,值得研读,例如:
Cosmos World Foundation Model Platform for Physical Al
机构:NVIDIA
奖项:CES 2025上获得了Best AI和Best Overall两项大奖。
推荐理由:该论文提出了一个强大的世界基础模型平台,帮助开发者为物理AI系统构建定制化的世界模型。它通过预训练的模型、高效的视频分词器和数据处理管道,解决了物理AI训练数据获取难的问题,推动了物理AI的发展。此外,平台开源且提供模型权重,降低了开发门槛。
论文内容:本文介绍了Cosmos World Foundation Model Platform,这是一个用于加速物理AI开发的平台。该平台推出了一系列世界基础模型(WFMs),这些模型可以预测和生成虚拟环境未来状态的物理感知视频,以帮助开发者构建新一代机器人和自动驾驶汽车(AV)。这些模型使用包括文本、图像、视频和运动在内的输入数据来生成和仿真虚拟世界,以准确模拟场景中物体的空间关系及其物理交互。NVIDIA在CES大会上推出第一批Cosmos世界基础模型,用于基于物理的仿真和合成数据生成,配备先进的tokenizer、护栏、加速数据处理和管理工作流,以及模型定制和优化框架。无论公司规模大小,研究人员和开发者都可以根据NVIDIA允许商业使用的开放模型许可下,自由使用Cosmos模型。构建AI智能体的企业还可以使用在CES上推出的新开源NVIDIA Llama Nemotron和Cosmos Nemotron模型。开发者可以直接使用Cosmos模型生成基于物理学的合成数据,或利用NVIDIA NeMo框架,根据自己的视频对模型进行微调,以实现特定物理AI设置。
论文地址:https://arxiv.org/pdf/2501.03575
EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
机构:智元机器人、上海交通大学、上海人工智能实验室
推荐理由:EnerVerse通过创新的稀疏记忆机制和自由锚定视角,生成具身未来空间,显著提升机器人长程任务规划的逻辑性和连续性。
论文内容:这篇论文介绍了一个名为EnerVerse的综合框架,专为机器人操作任务设计,用于生成具身未来空间。EnerVerse通过自回归扩散模型,在生成未来具身空间的同时引导机器人完成复杂任务。其核心创新包括:
稀疏记忆机制:结合逐块单向生成范式,以促进无限长序列的生成,解决视频数据中的冗余问题。
自由锚定视角:提供灵活的视角,增强观察和分析能力,减轻运动建模的模糊性,消除密闭环境中的物理限制,显著提高机器人在各种任务和设置中的泛化和适应性。
高效动作规划:通过在生成网络下游集成Diffusion策略头,打通未来空间生成与机器人动作规划的全链条,确保动作预测的实时性。
数据引擎流水线:结合生成模型与4D Gaussian Splatting,利用生成模型的泛化能力和4DGS的空间约束,实现数据质量和多样性的迭代增强,有效缩小仿真到真实的差距。
实验结果表明,EnerVerse在视频生成、动作规划、消融与训练策略分析及注意力可视化方面都表现出卓越的性能。在LIBERO基准测试中,EnerVerse在机器人动作规划任务中取得了显著优势,特别是在长程任务中表现优异。
论文地址:https://arxiv.org/pdf/2501.01895
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
机构:Google DeepMind
推荐理由:RT-2将大规模预训练的视觉-语言模型直接应用于机器人控制,显著提升了泛化能力和语义推理能力。
论文内容:RT-2(Robotic Transformer 2)是一个视觉-语言-动作(VLA)模型,旨在将预训练的视觉语言模型(VLM)与机器人数据相结合,以提高机器人的泛化能力和推理能力。RT-2的核心贡献和特点如下:
多模态输入:RT-2的输入包括一帧或多帧图像和自然语言指令。这些输入通过预训练的视觉语言模型(如PaLM-E和PaLI-X)进行token化,生成文本序列,最终输出为机器人动作的标记序列。
动作表示:RT-2将机器人的动作表示为标记(类似于语言标记),这些标记可以由标准自然语言标记生成器处理。具体来说,动作空间包括机器人末端执行器的6个自由度(位置和旋转位移)、机器人夹持器的伸展程度,以及一个特殊的离散命令(用于终止该回合)。
协同微调:RT-2通过在大规模互联网数据和机器人特定数据的混合上进行共同微调,使模型能够输出机器人运动指令向量。这种协同微调方法不仅提高了模型的泛化能力,还使其能够执行训练数据中未明确包含的任务。
实时推理:RT-2开发了一种协议,允许在云服务中部署模型,并通过网络查询此服务以在机器人上运行它们。使用这个解决方案,可以实现合适的控制频率,同时还可以使用同一云服务为多个机器人提供服务。
实验结果:RT-2在超过6000次的机器人评估试验中展示了其强大的泛化能力和推理能力。例如,在任务“把草莓放进正确的碗里”中,RT-2需要理解草莓和碗的表征,并在场景上下文中进行推理,以确定草莓应该与相似的水果放在一起。
限制:尽管RT-2展示了可以实时运行大型VLA模型的能力,但这些模型的计算成本很高,而且由于这些方法应用于需要高频控制的设置,实时推理可能会成为一个主要瓶颈。未来研究的一个方向是探索量化和蒸馏技术,使这些模型能够以更高的速率或在更低成本的硬件上运行。
论文地址:https://robotics-transformer2.github.io/assets/rt2.pdf

结语
本次盘点旨在梳理具身智能领域的年度关键成果,通过访谈一线研究者,筛选出具有代表性的论文。这些论文涵盖了该领域的核心议题与前沿进展,可作为不同阶段研究者的参考资源,助力大家在科研与学术探索中取得新突破。
具身智能这一火热领域,自去年开始逐渐进入大众视野,目前正处在初步兴起的阶段。其未来的发展路径以及大规模商业化落地的时间,目前还难以精准预估,或许只能暂时打上一个?号。
这里给大家推荐一门我们最新的课程《国内首个面向具身智能方向的理论与实战课程》:






课程亮点
本课程从学术研究和实际应用两方面,带你从零入门具身智能的原理学习、论文阅读、代码梳理等内容。
课程由具身智能领域的资深专家主讲,他们先后担任研究所、国企、大厂具身智能负责人,拥有丰富的理论知识和实践经验。
课程答疑
本课程答疑主要在本课程对应的鹅圈子中答疑,学员学习过程中,有任何问题,可以随时在鹅圈子中提问。



















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









