







 本文提出了一种基于SimCLR的自监督学习方法,用于遥感图像的表示学习。与传统的Tile2Vec方法不同,该方法使用多个相邻图像的平滑表示来提高表示质量,减少了错误选择相邻图像的影响。在CDL、RESISC-45、UCMerced和EuroSAT数据集上的实验表明,所提方法在分类和微调任务上优于现有自监督学习技术,且在某些情况下与预训练的ImageNet模型相当。
本文提出了一种基于SimCLR的自监督学习方法,用于遥感图像的表示学习。与传统的Tile2Vec方法不同,该方法使用多个相邻图像的平滑表示来提高表示质量,减少了错误选择相邻图像的影响。在CDL、RESISC-45、UCMerced和EuroSAT数据集上的实验表明,所提方法在分类和微调任务上优于现有自监督学习技术,且在某些情况下与预训练的ImageNet模型相当。
在遥感中,随着时间的推移不断积累大量未标记的图像,很难对所有数据进行标注。因此,一种可以使用未标记数据提高识别率的自监督学习技术将对遥感有用。这封信介绍了 基于 SimCLR 框架的 遥感平滑表示的 对比自监督学习。在遥感的自监督学习中,通常使用 众所周知的特征,即 短距离内的图像 可能在语义上相似。本文的算法基于此知识,它同时 利用 多个相邻图像作为锚图像的正对,这与现有方法(例如 Tile2Vec)不同。此外,最先进的自监督学习方法之一的 MoCo 和 SimCLR 仅使用单输入图像的两个增强视图,但本文提出的方法 使用多输入图像 并 对它们的表示进行平均(例如,平滑表示)。因此,在农田数据层 (CDL)、RESISC-45、UCMerced 和 EuroSAT 数据集中,所提出的方法优于最先进的自监督学习方法,例如 Tile2Vec、MoCo 和 SimCLR。所提出的方法与 CDL 分类任务中的预训练 ImageNet 模型相当。
I. INTRODUCTION:
在遥感领域,基于深度学习的计算机视觉技术,如 语义分割[1]-[3]、目标检测[4]-[6]、图像分类[7]、[8]、[9]、[ 10],应用广泛。特别是,图像分类 是 遥感图像分析的基本要素,它将遥感图像分类为有意义的类别。在最近的相关研究中,已经尝试使用没有标签的大规模数据来提高基于深度学习的视觉识别的准确性。自监督学习是使用未标记数据学习有意义表征的代表性研究领域。现代自监督学习技术,如 MoCo [11] 和 SimCLR [12],已经发展得很好。
代表性的 遥感自监督学习方法是 Tile2Vec [13] 和 上下文编码器 [14]。上下文编码器用于语义分割任务,Tile2Vec 方法针对分类任务。 Tile2Vec 技术利用 三元组损失 来最小化 锚点 和 相邻patches的表示 之间的距离,并最大化 锚点 和 远处patches 的表示之间的距离。
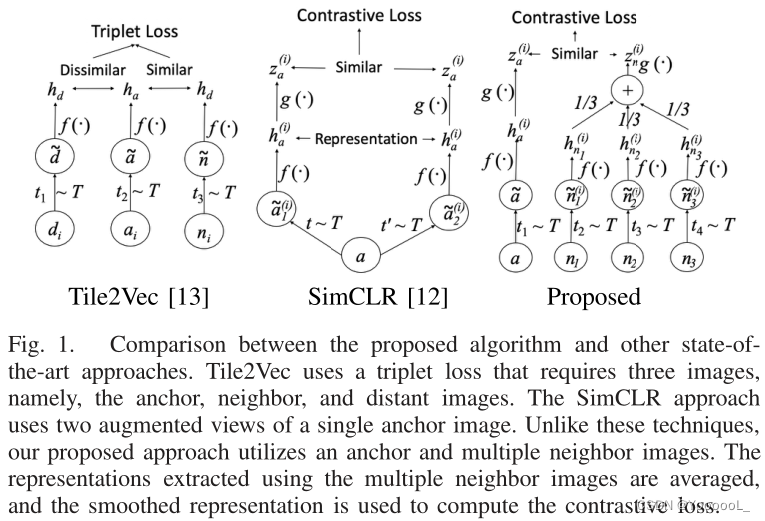
本文提出了一种 使用平滑表示的 自监督学习方法,如图 1 所示。不同于现有的最先进方法,如 SimCLR [12]、MoCo [11] 和 Tile2Vec [13] ,本文 使用多个正样本 和 负样本来学习表示。被选为正样本的 K 个相邻图像被平均 以创建平滑表示,这对于减少噪声表示 很有用。本文的方法仅使用从 xView 数据集中收集的 325 600 个卫星图像块进行训练。所提出的方法表现出的性能可与在农田数据层 (CDL) 分类中使用来自 ImageNet 的 120 万张图像进行训练所获得的性能相媲美。
Contributions:
1)本文将 SimCLR 技术(一种用于通用图像识别任务的最先进算法)应用于具有平滑表示的遥感应用。
2) 据本文所知,本文是第一个 证明 自监督学习算法 可以 在遥感应用中 提供与 ImageNet 预训练模型相当的性能的方法。
3) 本文使用 RESISC45、UCMerced 和 EuroSAT 数据集建立了实验协议,以评估遥感应用中的自监督学习算法。
II. MOTIVATION AND PROBLEM STATEMENT
Tile2Vec 方法使用 三元组损失,这会导致两个问题。
第一个问题是 Tile2Vec 方法明确需要 锚点和远距离图像 的一对负样本。换句话说,每个锚对应于单个远距离图像。最近提出的基于对比学习的自监督学习技术 不需要 明确的负样本对 [12 SimCLR]。相反,未配对的锚图像 和 相邻图像 用作负样本。本文采用这种方法来提高性能。
第二个问题是 可能会 错误地选择相邻图像。 Tile2Vec 方法仅选择一个正例来计算三元组损失。当相邻图像选择不正确时,可能会出现性能下降。为了解决这个问题,本文使用多个相邻图像。但是,目前(2021)没有使用多个输入的自监督学习技术。本文专注于解决本研究中的两个问题。
III. CONTRASTIVE SELF-SUPERVISED LEARNING FOR REMOTE SENSING
本文认为,第二部分提到的两个问题可以用两种方法来解决。
第一个是使用只需要正样本对的对比学习。
第二种是使用平滑的表示来允许对比学习中的多个输入。
本节中解释这两种方法。本文技术的总体架构如图 2 所示。本文的算法使用从高分辨率卫星图像中提取的多个相邻图像。随机选择锚图像和相邻图像,并将这些图像用作编码器的输入。最后,本文使用带有编码器和投影头提取输入的特征,并通过 最小化基于特征的对比损失 来训练网络。
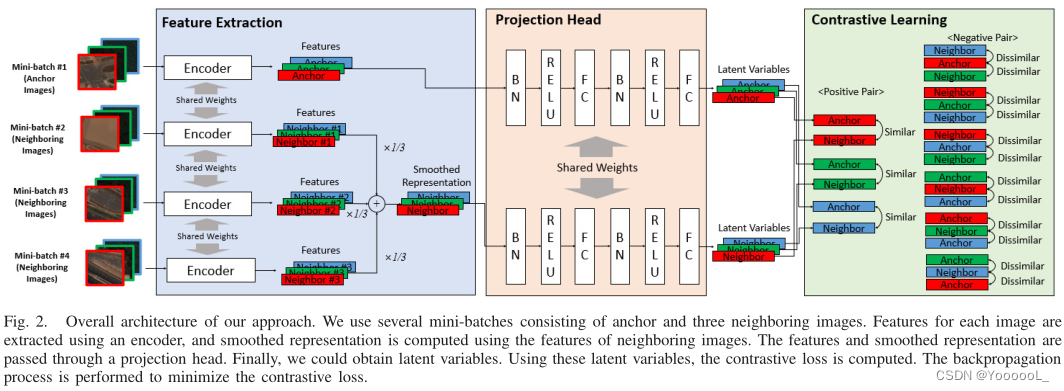
A. Contrastive Learning With Neighbor Images
受 SimCLR 算法 [12] 的启发,本文使用 隐空间中的对比损失 来最大化数据点的不同增强视图之间的相似性。 SimCLR 算法使用从同一图像裁剪的图像。这些裁剪图像应该在空间上重叠,因为裁剪图像的内容包含相同的对象。但是,本文使用 不重叠或轻微重叠的 锚点和相邻图像。本文算法的数学解释如下。为了方便起见,假设本文选择了一个相邻的patch。将 锚点 和 相邻图像 的小批量分别表示为 ![]() 和
和 ![]() 。 N 是 mini-batch 的图像数量。
。 N 是 mini-batch 的图像数量。
卫星图像通常是大约 100 万像素或更大的大尺寸图像。两个裁剪图像用于计算来自卷积神经网络 f 的输入的小批量 x 的表示 hx = f (x)。因此,我们可以分别用 f(a) 和 f(n) 得到 ha 和 hn。与原始的 SimCLR 类似,本文使用投影头 ![]() ,其中 b(·) 是一个批量归一化函数 [15] 和 σ ( ·) 是一个整流线性单元(ReLU)函数。 W1 和 W2 分别表示 g(·) 的第一层和第二层全连接层的权重参数。 x 的隐变量是 zx = g(hx)。与原始的 SimCLR 算法不同,本文采用了批量归一化。
,其中 b(·) 是一个批量归一化函数 [15] 和 σ ( ·) 是一个整流线性单元(ReLU)函数。 W1 和 W2 分别表示 g(·) 的第一层和第二层全连接层的权重参数。 x 的隐变量是 zx = g(hx)。与原始的 SimCLR 算法不同,本文采用了批量归一化。
对于损失函数,本文使用 归一化温度标度交叉熵 (NT-Xent) 损失 来学习 具有相邻补丁的表示。原始损失函数与原始 SimCLR 算法中使用的损失函数相同 [12]
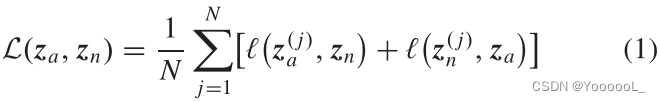
其中 ![]() 和
和 ![]() 是锚图像和相邻图像的两个批量batches中的第 j 个隐变量,za 和 zn 分别是锚图像和相邻图像的隐变量的小批量mini-batches。每个mini-batches中的图像数量用 N 表示。每个项 l(·) 的损失值定义如下:
是锚图像和相邻图像的两个批量batches中的第 j 个隐变量,za 和 zn 分别是锚图像和相邻图像的隐变量的小批量mini-batches。每个mini-batches中的图像数量用 N 表示。每个项 l(·) 的损失值定义如下:
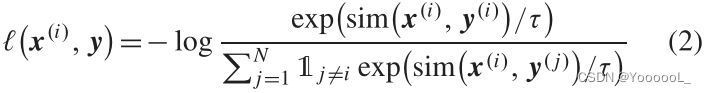
其中![]() ,τ 是温度参数。在本文的实验中将 τ 的值设置为 0.5。
,τ 是温度参数。在本文的实验中将 τ 的值设置为 0.5。 ![]() 用于正样本。本文最大化 正样本(即锚点和相邻样本)的表示之间的相似性。
用于正样本。本文最大化 正样本(即锚点和相邻样本)的表示之间的相似性。![]() 用于负样本。同一个mini-batch中存在的其他 与当前索引的anchor图像 不对应的图像 被认为是 负样本。我们最大化该项以使其不同。
用于负样本。同一个mini-batch中存在的其他 与当前索引的anchor图像 不对应的图像 被认为是 负样本。我们最大化该项以使其不同。
B. Smoothed Representation 平滑的表示
最大化锚点和一个相邻图像的表示之间的相似性可能会产生负面影响。原因是可以选择 具有与锚图像不同的结构或对象的图像 作为相邻图像。我们相信,如果我们选择多个相邻补丁,我们可以减轻负面影响。因此,我们选择了多个相邻补丁并提出了一种基于多个相邻补丁创建平滑的表示的方法,该方法可以减轻由错误选择正样本引起的负面影响(见图 3)。
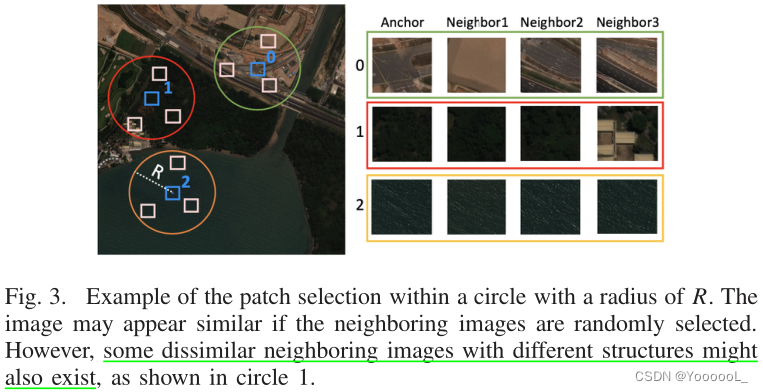
在图中,anchor 和 Group 0 中的三个相邻图像看起来很相似,这是一个幸运的案例。在Group 1 中,其中一个相邻图像与锚图像不同。锚图像没有建筑物,但一些建筑物显示在三个相邻图像之一中。因此,本文聚合了基于多个相邻图像的多个表示,以缓解问题
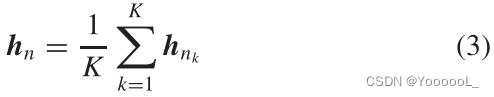
其中 hnk 是用相邻图像 nk 提取的表示, k ∈ {1, . . . K },K 是相邻图像的数量。本文将此值设置为 3。本文的算法在算法 1 中给出。算法中的 tm 表示锚点和相邻图像的数据增强函数,其中 m ∈ {1, . . . K + 1}。

IV . EXPERIMENTS
A. 数据集
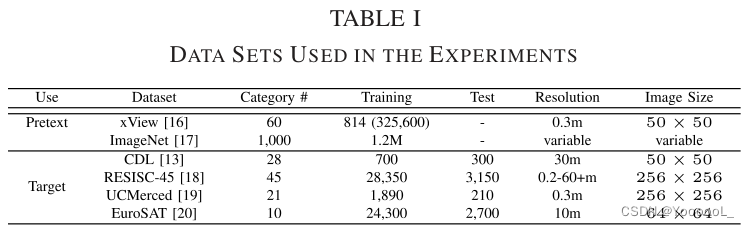
本文将两个数据集(即 xView [16] 和 ImageNet [17])用于前置任务,如表 I 所示。首先,ImageNet 数据集用于评估带标签的监督迁移学习设置。该数据集包含大约 120 万张训练图像。对于遥感数据,本文使用了 xView 数据集,该数据集最初是为评估卫星图像中的目标检测算法而设计的。为了评估自监督学习算法,本文处理了 xView 数据集,该数据集由 846 张图像组成,从 WorldView-3 卫星以 0.3 m 的分辨率拍摄。对于本文的实验,从 814 张图像中随机选择锚图像。其余图像的像素值较小;因此,本文没有使用这些图像。本文从 814 张图像中裁剪出 100 张锚图像,总共获得 81400 张图像。本文还 裁剪了距离锚块 100 像素以内的三个相邻块。最后,获得了 325600 个patches 。patches 大小为 50 × 50。远处的图像从圆圈外裁剪,仅用于评估 Tile2Vec 算法。
本文为目标任务使用了四个数据集(即 CDL、RESISC-45、UCMerced 和 EuroSAT)。这些数据集的目的是分类。表 I 显示了类别数。 CDL 和 EuroSAT 数据集分别具有 50×50 和 64×64 的低分辨率图像。相比之下,RESISC-45 和 UCMerced 数据集拥有 256×256 的高分辨率图像。CDL 和 UCMerced 数据集的图像数量明显少于其他数据集;因此,本文希望他们能够 通过自监督学习 证明迁移学习的显著有效性。
B. 实施
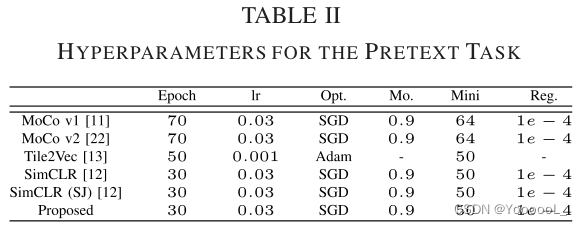
本文采用 TorchVision 库中的 ResNet-50 架构 [21] 进行所有实验。表 II 列出了每种方法的超参数。 lr、Opt.、Mo.、Mini 和 Reg。分别代表学习率、优化器、动量、小批量大小和权重衰减正则化。对于 MoCo v1 和 v2,初始学习率通过每 30 个 epoch 乘以 0.1 来衰减。对于其他算法,本文没有使用学习率衰减。此外,在Tile2V ec的原始源代码中,初始学习率为0.001,没有学习率衰减。相反,使用了 Adam 优化器。对于基于 SimCLR 的方法中的投影头,本文使用了两个带有 ReLU 和 1000 个节点的全连接层。
对于 CDL 分类测试,本文使用了与 scikit-learn 库 [23] 中提供的默认值相同的超参数。 EuroSAT、RESISC45 和 UCMerced 的超参数设置如下。我们使用了 60 个 epoch 和 64 个 mini-batch size。初始学习率为 0.1,学习率每 20 个 epoch 乘以 0.1 衰减。权重衰减参数为 0.0005。对于优化器,我们使用动量为 0.9 的随机梯度下降 (SGD)。
与其他方法 [即 MoCo v1、MoCo v2 和 SimCLR (SJ)] 不同,本文提出的方法 没有使用数据增强的尺度抖动。本文实验中使用的所有算法包括用于数据增强的随机灰度、颜色抖动和随机水平翻转。除 ImageNet 实验外,前置任务的图像大小为 50 × 50,因为前置数据集中的裁剪块大小为 50 × 50。本文使用 224 × 224 图像进行 ImageNet 实验。对于目标任务,本文使用了 64 × 64 的图像尺寸,这是目标数据集中最小的尺寸,以在我们有限的资源下节省时间。
C. CDL 分类测试
首先,本文使用前置任务数据集(例如 xView 和 ImageNet)训练了一个模型。我们使用编码器从 CDL 数据集中提取特征。这些特征用作三个机器学习分类器的输入,即随机森林 (RF)、多层感知器 (MLP) 和逻辑回归 (LR)。我们测量了目标任务测试集的分类率。我们随机选取CDL数据集图片总数(1000张)的70%(700张)作为训练数据,其余的作为测试数据。该评估过程重复 100 次,并使用测试数据对分类率进行平均。
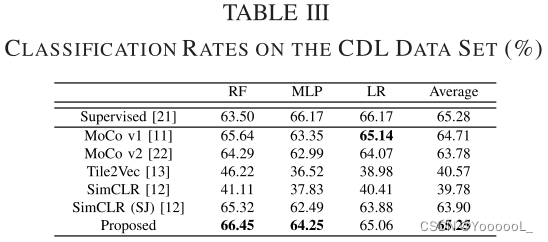
实验结果列于表三。 “Supervised” 意味着在目标任务数据集上使用 ImageNet 预训练模型进行学习。本文的算法在最先进的算法中显示出最好的结果。表中的 SimCLR (SJ) 表示具有 尺度抖动 数据增强的 SimCLR。本文算法的结果与使用 ImageNet 的预训练模型的结果相当。使用RF分类器,分类率为66.45%,是三种分类器中最好的。结果优于使用 ImageNet 数据集获得的结果(例如,使用 LR 的结果为 66.17%)。此外,本文的算法不需要任何人工注释成本。本文观察到 ImageNet 预训练模型与基于自监督学习的预训练模型 [例如,MoCo v1、MoCo v2 和 SimCLR (SJ)] 之间的差距并不大;因此,本文得出结论,域内迁移学习可能对 CDL 数据集有帮助。
D.微调测试
对于微调测试,本文针对目标任务使用了三个数据集,即 RESISC-45、UCMerced 和 EuroSAT 数据集。本文使用所有这些数据集中图像总数的 90% 进行训练,其余用作测试数据。与CDL分类测试类似,我们也包含了 与ImageNet预训练模型的对比,从头开始训练提取的结果也包含在内。使用每种方法预训练的权重参数用作目标任务的初始权重,最后一个线性分类层除外。
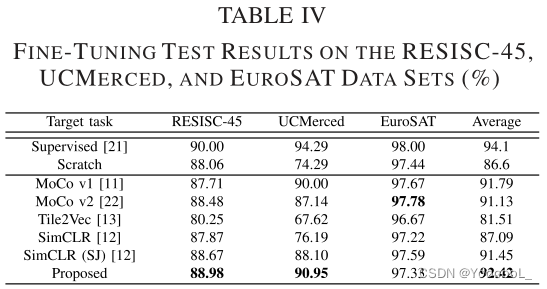
结果列于表IV。 “Scratch”意味着 仅使用目标任务数据集 从头开始学习。本文的方法平均显示出最好的结果。特别是,本文的算法对 RESISC-45 和 UCMerced 数据集有效。其他自监督学习算法中准确率最高的为 91.79%,而我们的方法达到了 92.42%。此外,ImageNet 预训练模型显示出 94.1% 的准确率。 ImageNet 预训练模型的准确度与我们的方法之间存在大约 1.7% 的差距。
在 RESISC-45 数据集上,从头开始学习的结果(表 IV 中的“Scratch”)显示出比 MoCo v1、Tile2Vec、SimCLR 和 SimCLR (SJ) 更好的分类率。这是因为 RESISC-45 数据集的训练数据很大。同样,在 EuroSAT 数据集上,从头开始学习也取得了不错的效果。因此,我们推测当目标训练数据的数量较少时,自监督学习算法是有效的。
E. 线性分类测试
在线性分类测试中,本文使用编码器作为特征提取器。添加了线性分类层。我们只更新了线性层,编码器的权重参数被冻结。该测试程序测量了每种算法学习到的表示的质量。选择训练数据和测试数据的方法与微调测试相同。线性分类任务的结果如表 V 所示。本文实现了 47.34% 的平均分类率。本文的算法在 EuroSA T 数据集上的表现大大优于其他方法。然而,在 UCMerced 数据集上,本文的算法比 MoCo v1 和 SimCLR (SJ) 方法差。
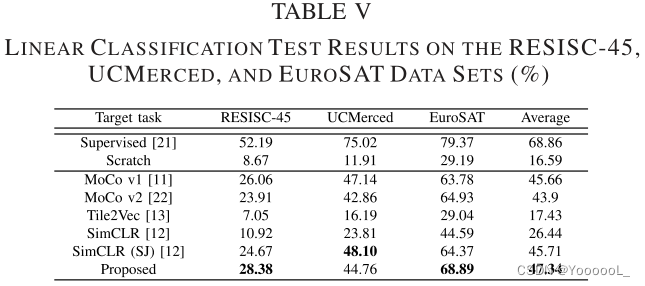
ImageNet 预训练模型显示出比自监督学习方法更好的结果(平均 68.86%)。然而,使用自监督学习算法获得的结果明显优于从头开始学习的结果 (16.59%)。这证明了未标记数据的有效性。此外,结果表明,scale jittering 尺度抖动有效地提高了原始 SimCLR 的性能;然而,在本文的方法中使用相邻图像(不包括几何数据增强技术)与其他方法相当或更有效。
F . Discussion
在本节中,介绍了本文方法的优点和局限性。
优点:
首先,多项实验表明,尺度抖动可有效提高原始 SimCLR 的性能;然而,在本文的方法中使用 不包括几何数据增强技术的相邻图像 具有可比性或更有效。此外,根据本文的实验结果,可以得出结论,当在目标任务中提供少量训练数据时,自监督学习提供与 ImageNet 预训练模型相似或更好的准确性。卫星图像和 ImageNet 之间的域差距可能需要在目标域中有足够数量的训练数据。
局限性:
尽管有这些优点,但也有一些局限性。在微调测试中,所提出的算法在 RESISC-45 和 EuroSAT 数据集上没有表现出比“Scratch”显着的性能改进。具体来说,在 EuroSAT 数据集上,所提出方法的准确性低于“Scratch”。 RESISC-45 和 EuroSAT 数据集包含的数据比 UCMerced 数据集多得多。因此,当下游任务中的训练数据量足够时,所提出的方法无效。这是尚待解决的问题。
V. CONCLUSION
本文提出了一种对比自监督学习方法,具有遥感平滑的表示。本文的技术使用基于 SimCLR 框架的对比损失来最大化从锚图像和相邻图像中提取的特征之间的相似性。此外,它降低了从锚图像中提取的特征与小批量中其他图像的相似性。与其他算法相比,本文技术的改进是因为使用多个相邻图像来增加训练数据的多样性。为了整合从相邻图像中提取的特征,本文使用了平滑表示技术,可以减轻错误选择相邻图像的负面影响。与其他最先进的自监督学习方法相比,所提出的技术在 CDL 数据集的分类、微调和线性分类测试中表现出最佳性能。此外,在 CDL 分类测试中,本文们的方法在使用 RF 分类器时优于 ImageNet 预训练模型。


















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









