






论文研读来源A Survey of Transformers (arxiv.org)
摘要
文章行文顺序:
首先,简短的介绍最基本的transformer,然后提出X-formers的新的分类方法
之后,从三个方面介绍X-formers:模型变化、预训练、应用
最后,提出一些未来的研究方向
1 引言
Transformer 最初是作为机器翻译的序列到序列模型提出的。后来的工作表明,基于 Transformer 的预训练模型可以在各种任务上实现最先进的性能。Transformer 已成为 NLP 中的首选架构,尤其是对于 PTM。(Transformer-based pre-trained models)
这些 X-formers 从不同的角度改进了原版 Transformer。
- Model Efficiency.长序列计算注意力导致很高的计算代价,改进方法包括轻量级注意力(sparse attention variants),分治方法(recurrent and hierarchical mechanism)。【个人认为FFN的阶段,参数规模不亚于计算注意力的时候】
- Model Generalization.由于输入数据的结构偏差,很难在小规模的数据集上进行训练。改进方法主要包括引入结构偏差,或者正则化、在大规模无标签的数据上进行预训练
- Model Adaptation.在下游任务中应用Transformer
上述分类方法比较含糊,可能出现一个改进的模型出现在多个类别。因此提出全新的分类方法:architecture modification, pre-training, applications
2 背景
2.1 原始Transformer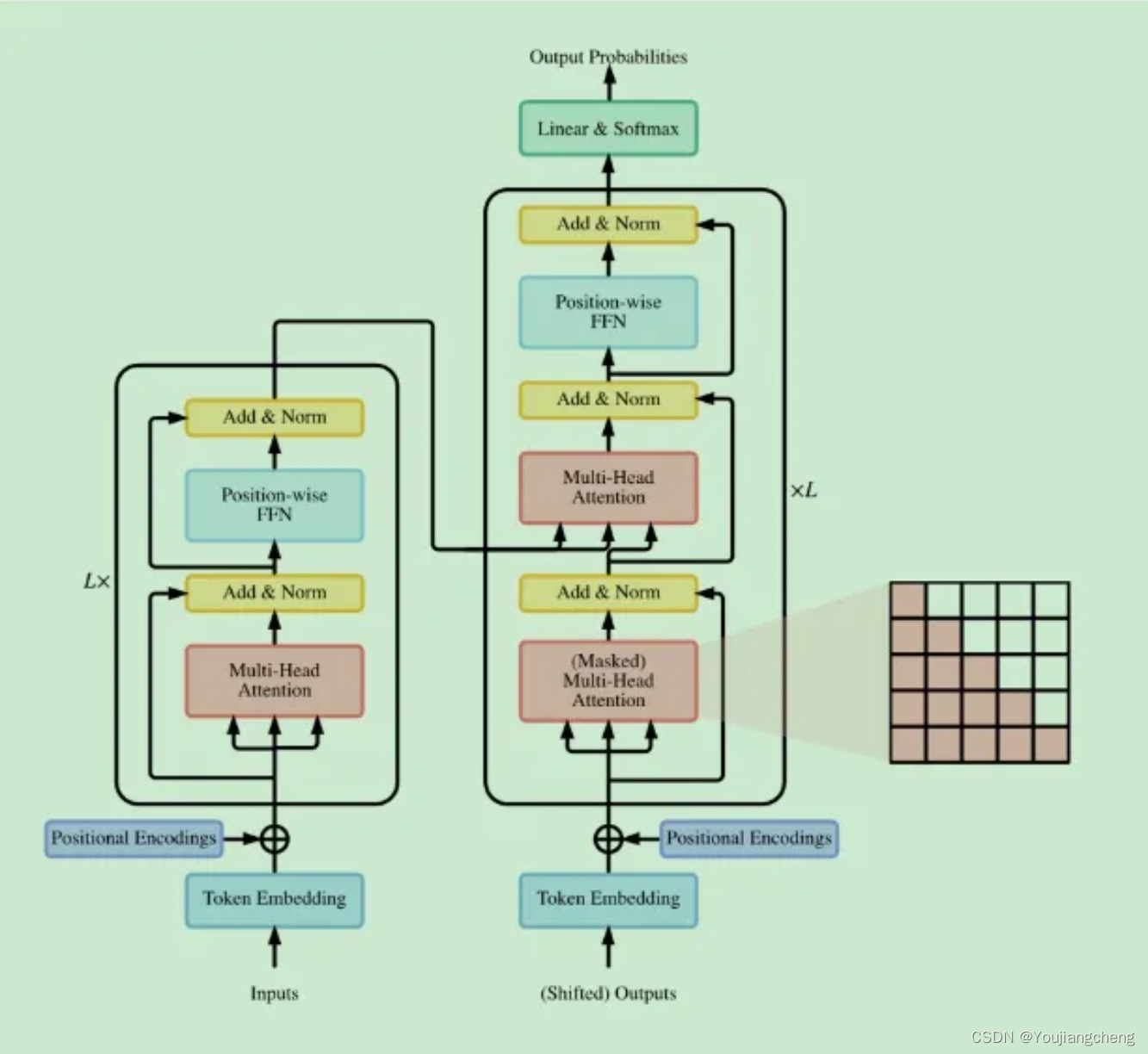
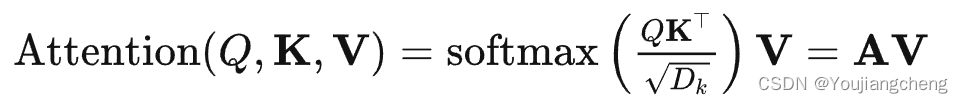
A:注意力权重矩阵
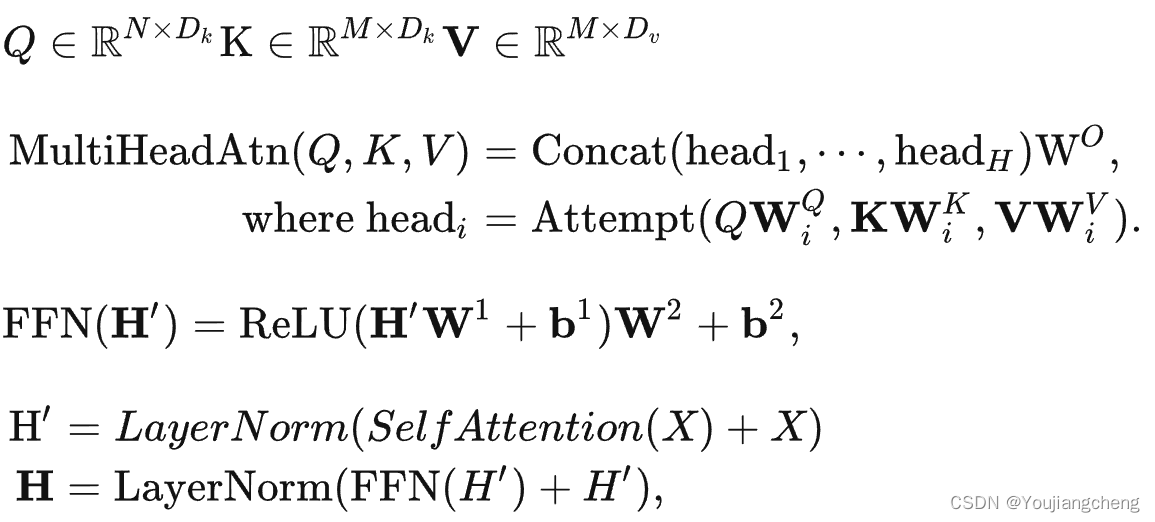
2.2 模型使用
- Encoder-Decoder
- Encoder only.这通常用于分类或序列标记问题
- Decoder only.通常用于序列生成,例如语言建模。
2.3 模型分析
当输入序列很短时,Transformer的瓶颈在于FFN。然而,随着输入序列变长,self-attention成为Transformer的瓶颈。并且自注意力还需要 × 的存储空间。
2.4 将 Transformer 与其他网络类型进行比较
2.4.1 Self-Attention分析
它可以理解为一个全连接层,其中权重是根据输入的成对关系动态生成的。
2.4.2 在归纳偏差方面
众所周知,卷积网络通过共享局部核函数来施加平移不变性和局部性的归纳偏差。同样,循环网络通过其马尔可夫结构携带时间不变性和局部性的归纳偏差。Transformer 架构对数据的结构信息几乎没有做任何假设。这使得 Transformer 成为一个通用且灵活的架构。然而,结构偏差的缺乏使得 Transformer 容易对小规模数据过度拟合。
另一种密切相关的网络类型是具有消息传递的图神经网络(GNN)。 Transformer 可以看作是在一个完整的有向图(带有自循环)上定义的 GNN,其中每个输入都是图中的一个节点。 Transformer 和 GNN 之间的主要区别在于,Transformer 不引入关于输入数据结构的先验知识——Transformer 中的消息传递过程完全取决于内容的相似性度量。
3 Transformer分类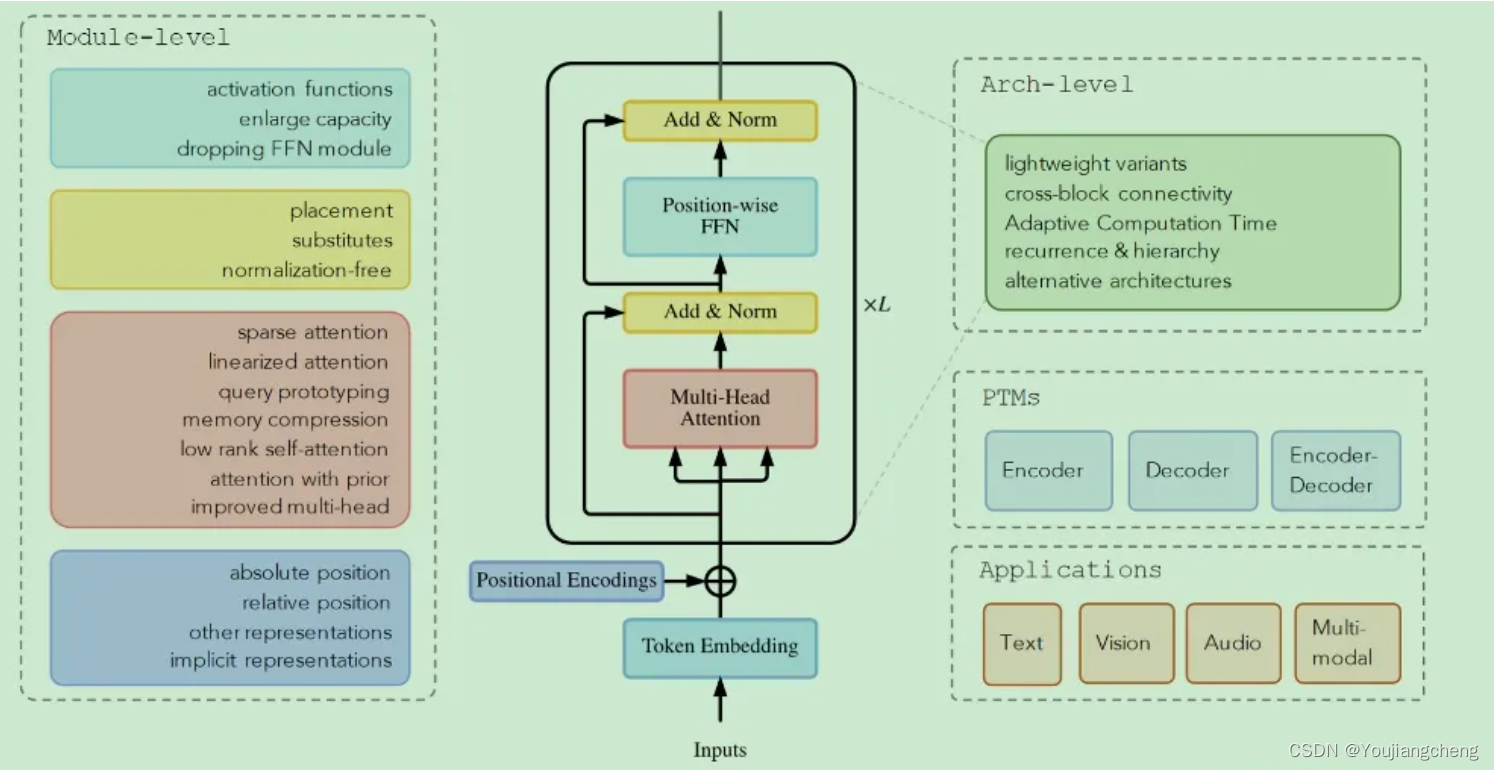
改进的分类
4 ATTENTION
Self-attention在Transformer中起着重要作用,但在实际应用中存在两个挑战。
- 复杂。作为第二节的讨论。 2.3、self-attention的复杂度为O(T^2 · D)。因此,注意力模块在处理长序列时成为瓶颈。
- 结构先验。 Self-attention 不会对输入假设任何结构性偏差。甚至订单信息也需要从训练数据中学习。因此,Transformer(没有预训练)通常很容易在小型或中等规模的数据上过度拟合。
对注意力的改进可分为以下几个分类:
- 稀疏的注意力。这一系列工作将稀疏偏差引入注意力机制,从而降低了复杂性。
- 线性化注意力。这一行工作将注意力矩阵与内核特征映射分开。然后以相反的顺序计算注意力以实现线性复杂度
- 原型和内存压缩。这类方法减少了查询或键值内存对的数量,以减少注意力矩阵的大小。
- 低阶自注意力。这项工作捕捉到了自注意力的低阶属性。
- 使用先验的注意力。研究方向探索用先前的注意力分布来补充或替代标准注意力。
- 改进的多头机制。研究系列探索了不同的替代多头机制。
4.1 稀疏注意力
可以通过结合结构偏差来限制每个查询涉及的查询-键对的数量来降低计算复杂度。我们只是根据预定义的模式计算查询-密钥对的相似度分数
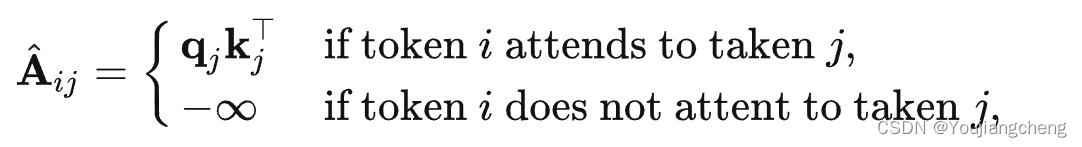
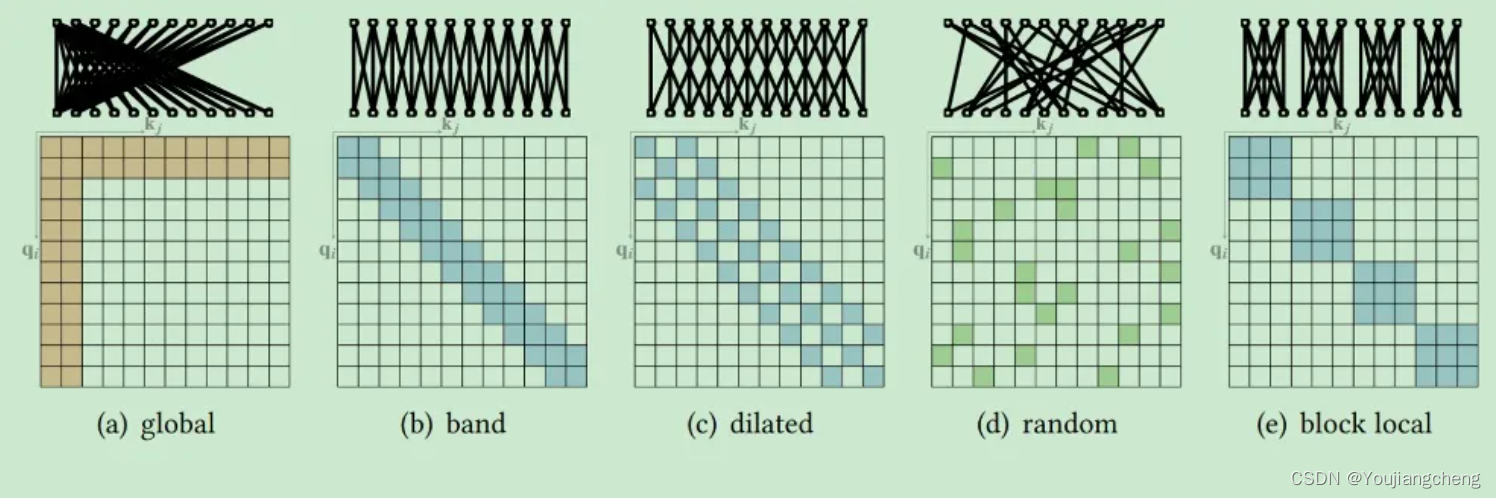
基于确定稀疏连接的指标,我们将这些方法分为两类:基于位置和基于内容的稀疏注意力。
4.1.1 Position-based Sparse Attention.
在基于位置的稀疏注意力中,注意力矩阵根据一些预定义的模式受到限制。尽管这些稀疏模式的形式各不相同,但我们发现其中一些可以分解为一些原子稀疏模式。
4.1.1.1 原子稀疏注意力
- Global Attention 全局注意力。为了减轻在稀疏注意力中对远程依赖建模能力的下降,可以添加一些全局节点作为节点之间信息传播的中心。这些全局节点可以参与序列中的所有节点,整个序列都参与这些全局节点,
- Band Attention(又名滑动窗口注意力或局部注意力)。Since most data come with a strong property of locality, it is natural to restrict each query to attend to its neighbor nodes. A widely adopted class of such sparse pattern is band attention
- Dilated Attention.分散注意力。这可以很容易地扩展到 strided attention,其中窗口大小不受限制,但 dilation wd 设置为较大的值。
- Random Attention 随机注意力。为了增加非本地交互的能力,为每个查询随机采样一些边缘。【想法来源见(e.g., Erdős–Rényi random graph)】
- Block Local Attention 块注意力。这类注意力将输入序列分割成几个不重叠的查询块,每个查询块都与一个本地内存块相关联。
4.1.1.2 Compound Sparse Attention
现有的稀疏注意力通常由不止一种上述原子模式组成。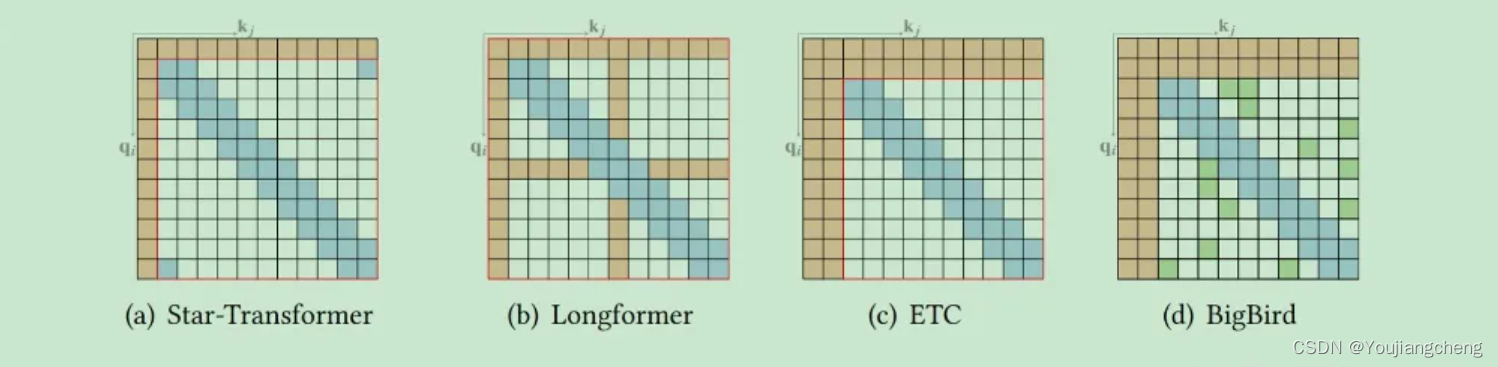
他们的理论分析还表明,稀疏编码器和稀疏解码器的使用可以模拟任何图灵机,这解释了那些稀疏注意力模型的成功。
4.1.1.3 扩展稀疏注意力
7 预训练的TRANSFORMERS
作为与固有地包含局部归纳偏差的卷积网络和循环网络的一个关键区别,Transformer 不对数据的结构进行任何假设。
这些模型使用各种自我监督目标进行预训练,在给定上下文的情况下预测掩码词。
- Encoder only.一系列工作使用 Transformer 编码器作为其骨干架构。 BERT 是典型的 PTM,通常用于自然语言理解任务。它利用掩码语言建模 (MLM) 和下一句预测 (NSP) 作为自我监督的训练目标。 RoBERTa 进一步调整了 BERT 的训练并删除了 NSP 目标,因为它被发现会损害下游任务的性能。
- Decoder only.一些研究侧重于在语言建模上预训练 Transformer 解码器。例如,Generative Pre-trained Transformer (GPT) 系列(即 GPT 、GPT-2 和 GPT-3 )致力于扩展预训练的 Transformer 解码器,并且最近说明了大规模 PTM 可以通过将任务和示例作为构建提示提供给模型来实现高性能
- Encoder-Decoder. BAR 将 BERT 的去噪目标扩展到编码器-解码器架构。使用编码器-解码器架构的好处是归纳模型具备执行自然语言理解和生成的能力。 T5 采用类似的架构,是最早在下游任务中使用任务特定文本前缀的研究之一。
8 Transformer的应用
- Natural Language Processing.Transformer 及其变体已在 NLP 任务中得到广泛探索和应用,例如机器翻译、语言建模 和命名实体识别 .大量的努力致力于在大规模文本语料库上预训练 Transformer 模型,我们认为这是 Transformer 在 NLP 中广泛应用的主要原因之一。
- Computer Vision.Transformer 也适用于各种视觉任务,例如图像分类 [14、33、88]、目标检测 、图像生成 和视频处理 等。
- Audio Applications.Transformer 还可以扩展用于音频相关应用,例如语音识别、语音合成 、语音增强 和音乐生成。
- Multimodal Applications(多模态).由于其灵活的架构,Transformer 也被应用于各种多模态场景,例如视觉问答,视觉常识推理,字幕生成,语音到文本的翻译和文本到图像的生成。
9 结论和未来方向
在本次调查中,我们对 X-formers 进行了全面概述,并提出了一个新的分类法。尽管 X-formers 已经证明了他们在各种任务中的能力,但挑战仍然存在。除了目前关注的问题(例如效率和泛化),Transformer 的进一步改进可能在于以下几个方向:
- 理论分析。当 Transformer 在足够的数据上进行训练时,它通常具有比 CNN 或 RNN 更好的性能。一个直观的解释是,Transformer 在数据结构上几乎没有 假设,因此比 CNN 和 RNN 更灵活。然而,理论原因尚不清楚,我们需要对 Transformer 能力进行一些理论分析。
- 更好的全局交互机制,超越注意力。Transformer 的一个主要优点是使用注意力机制来模拟输入数据中节点之间的全局依赖关系。然而,许多研究表明,对于大多数节点来说,全连接是不必要的。因此,在高效建模全局交互方面仍有很大的改进空间。一方面,self-attention模块可以看作是一个具有动态连接权重的全连接神经网络,它通过动态路由聚合非局部信息。因此,其他动态路由机制是值得探索的替代方法。另一方面,全局交互也可以通过其他类型的神经网络建模,例如记忆增强模型。
- 多模态数据的统一框架。在许多应用场景中,集成多模态数据对于提高任务性能是有用且必要的。此外,通用人工智能还需要能够捕捉不同模态之间的语义关系。由于 Transformer 在文本、图像、视频和音频方面取得了巨大成功,我们有机会构建一个统一的框架,更好地捕捉多模态数据之间的内在联系。然而,模态内和跨模态注意力的设计仍有待改进。















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









