









 本文概述了复旦大学邱锡鹏团队Transformer的变体(X-formers),探讨了其在模型效率提升、结构改进、预训练策略和广泛应用上的进展,为理解与实践Transformer提供系统指南。
本文概述了复旦大学邱锡鹏团队Transformer的变体(X-formers),探讨了其在模型效率提升、结构改进、预训练策略和广泛应用上的进展,为理解与实践Transformer提供系统指南。
这篇文章翻译自复旦大学邱锡鹏团队的 Transformers 综述。
文章链接:A Survey of Transformers
Abstract
Transformers在许多领域都取得了取得的成功,如:NLP、CV和语音处理,自然吸引了学术界和工业界的很大兴趣。到目前为止,已经有许多Transformers的变体(也就是 X-formers)被提出来,然而仍然缺乏对这些变体的系统的、全面的文献解读。这篇综述中,我们提出对X-formers 全面的评述。我们首先介绍了Vanilla Transformer,然后对X-formers 进行划分,接下来从结构、预训练和应用三个方面介绍了不同的X-formers,最后描绘了未来发展方向。
Introduction
X-formers从三个方面丰富了Vanilla Transformer:
- 模型效率:应用Transformer的一个关键挑战是在self-Attention时计算和内存的限制,导致的处理长文本时的低效率。一些改进方法包括:lightweight attention (e.g. sparse attention variants) and Divide-and-conquer methods ((e.g., recurrent and hierarchical mechanism)
- 模型泛化:因为Transformer结构比较灵活,针对输入数据的固有偏差上几乎没有假设,因此在处理小规模数据时比较困难。改进的方法包括:引入结构化偏置、正则化、在大规模数据上预训练。
- 模型应用:工作的主线旨在将Transformer应用在下游任务上。
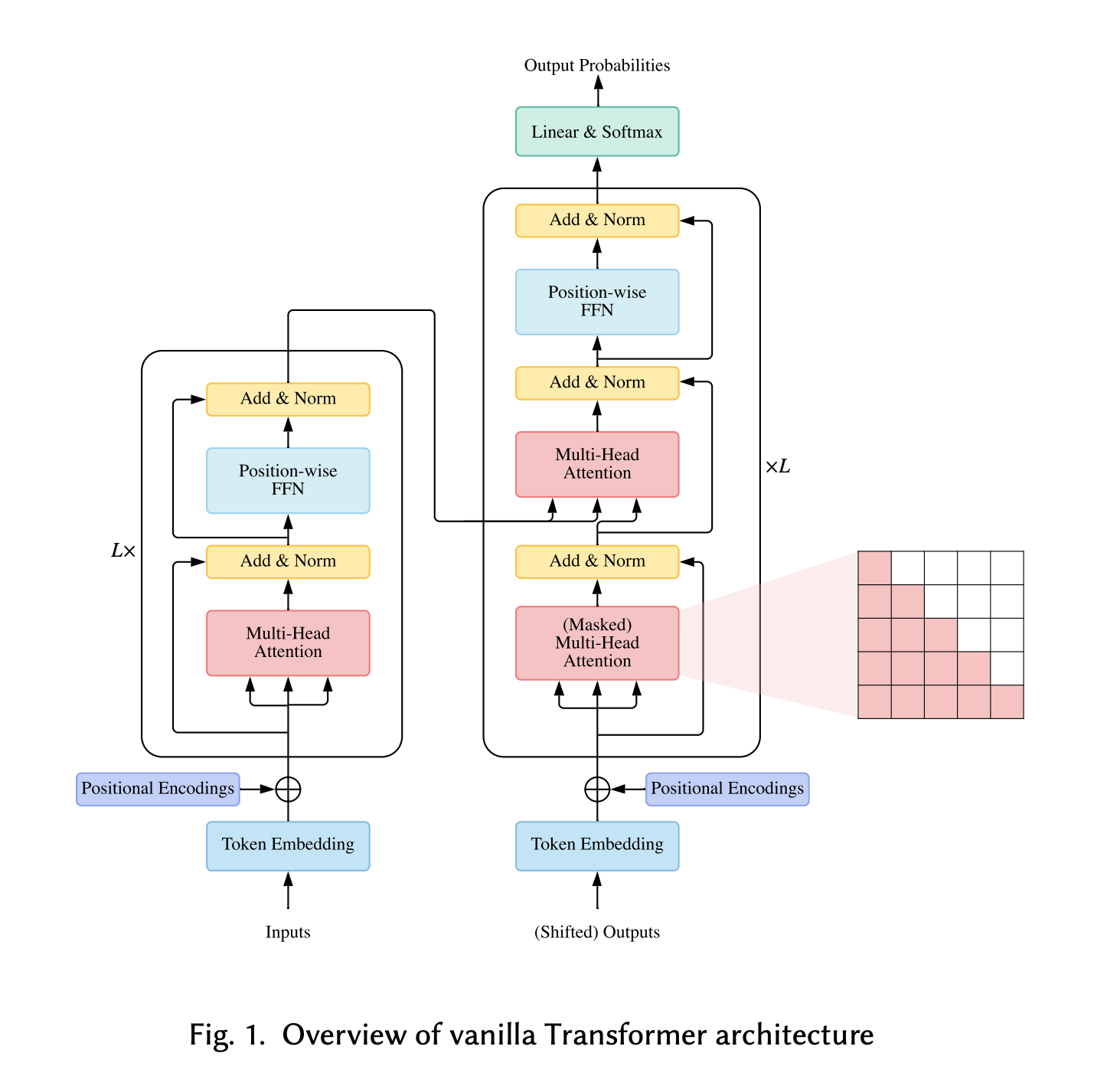
BackGround
Vanilla Transformer



















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











