







 Transformer模型由Encoder和Decoder构成,Encoder通过多层Self-Attention处理输入序列,Decoder则结合Encoder的输出和MaskedSelf-Attention进行翻译预测。Self-Attention通过Q、K、V矩阵计算注意力权重,同时使用PositionalEncoding来保留序列顺序信息。
Transformer模型由Encoder和Decoder构成,Encoder通过多层Self-Attention处理输入序列,Decoder则结合Encoder的输出和MaskedSelf-Attention进行翻译预测。Self-Attention通过Q、K、V矩阵计算注意力权重,同时使用PositionalEncoding来保留序列顺序信息。
1.Transformer 整体结构
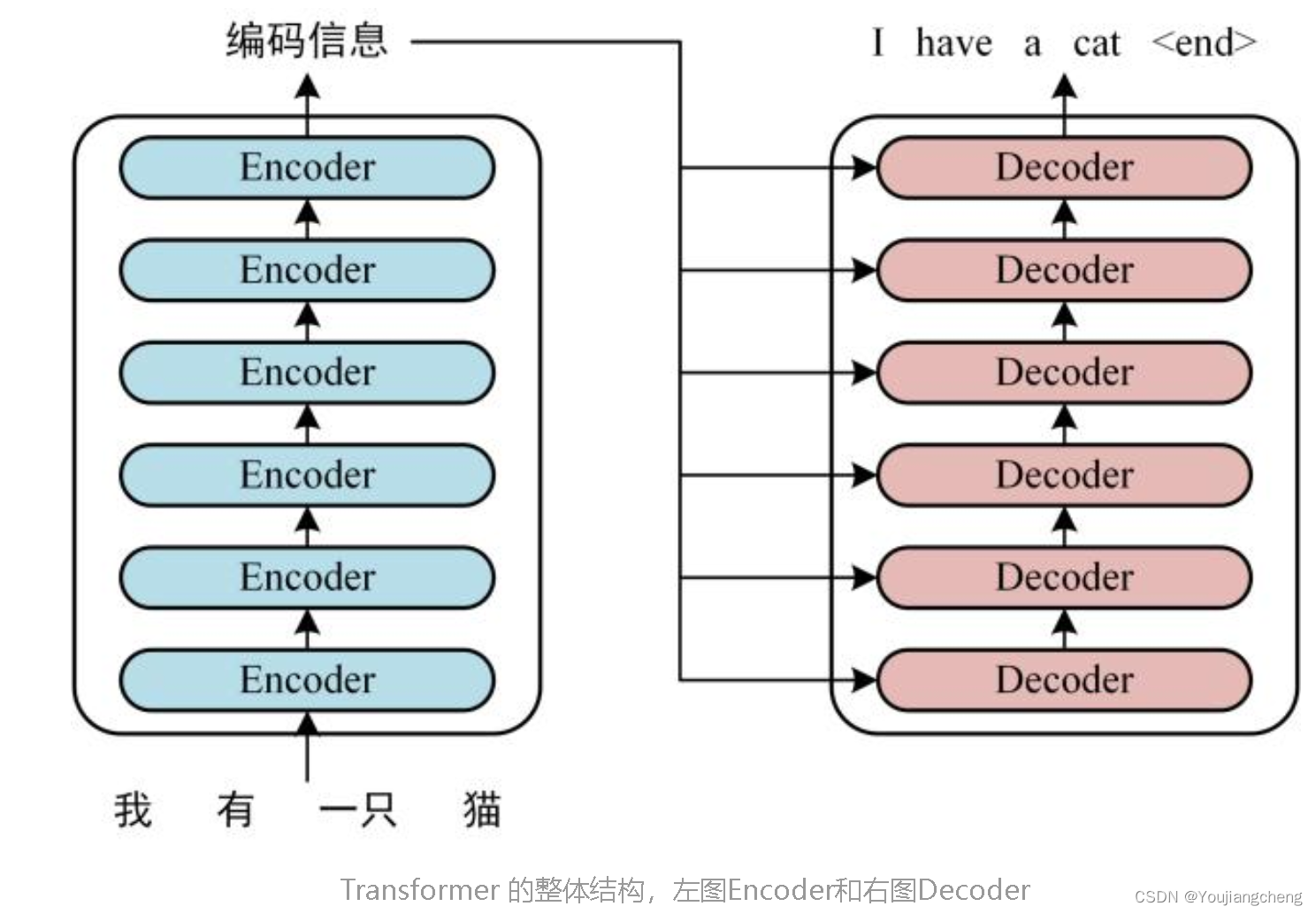
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
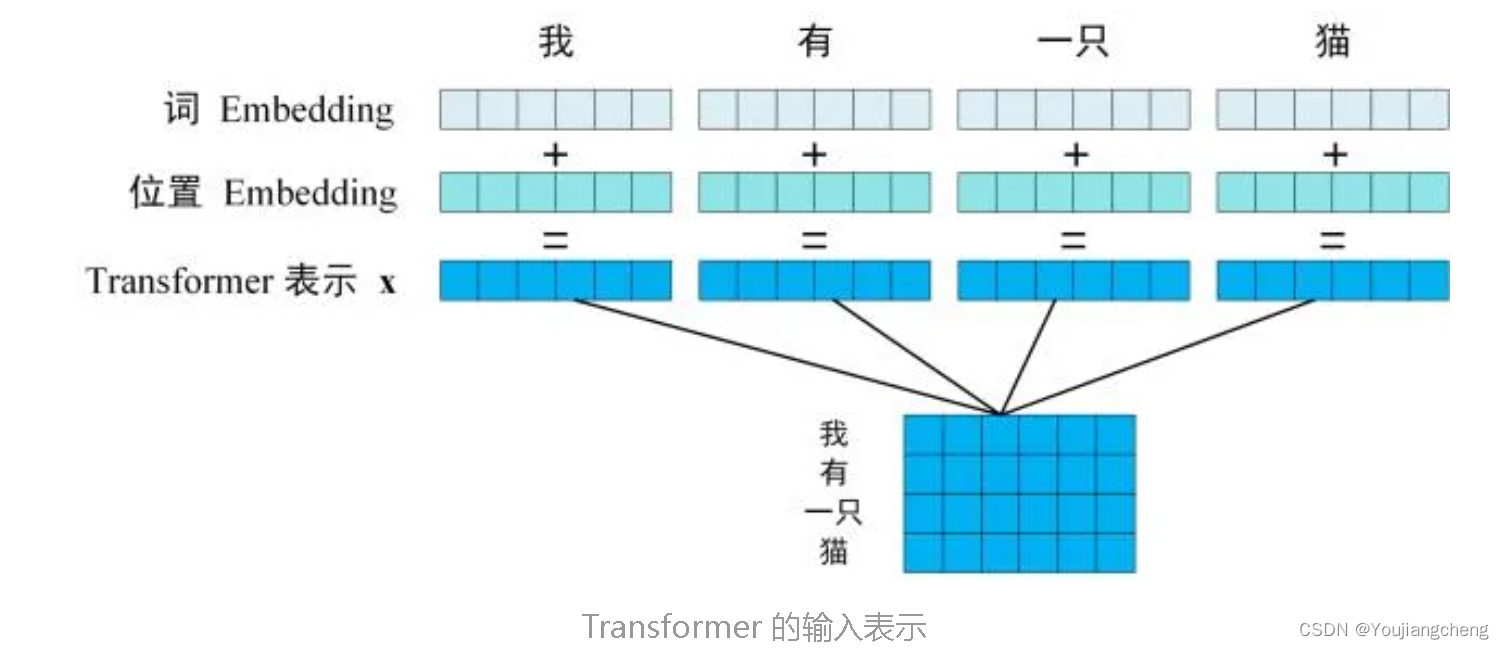
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
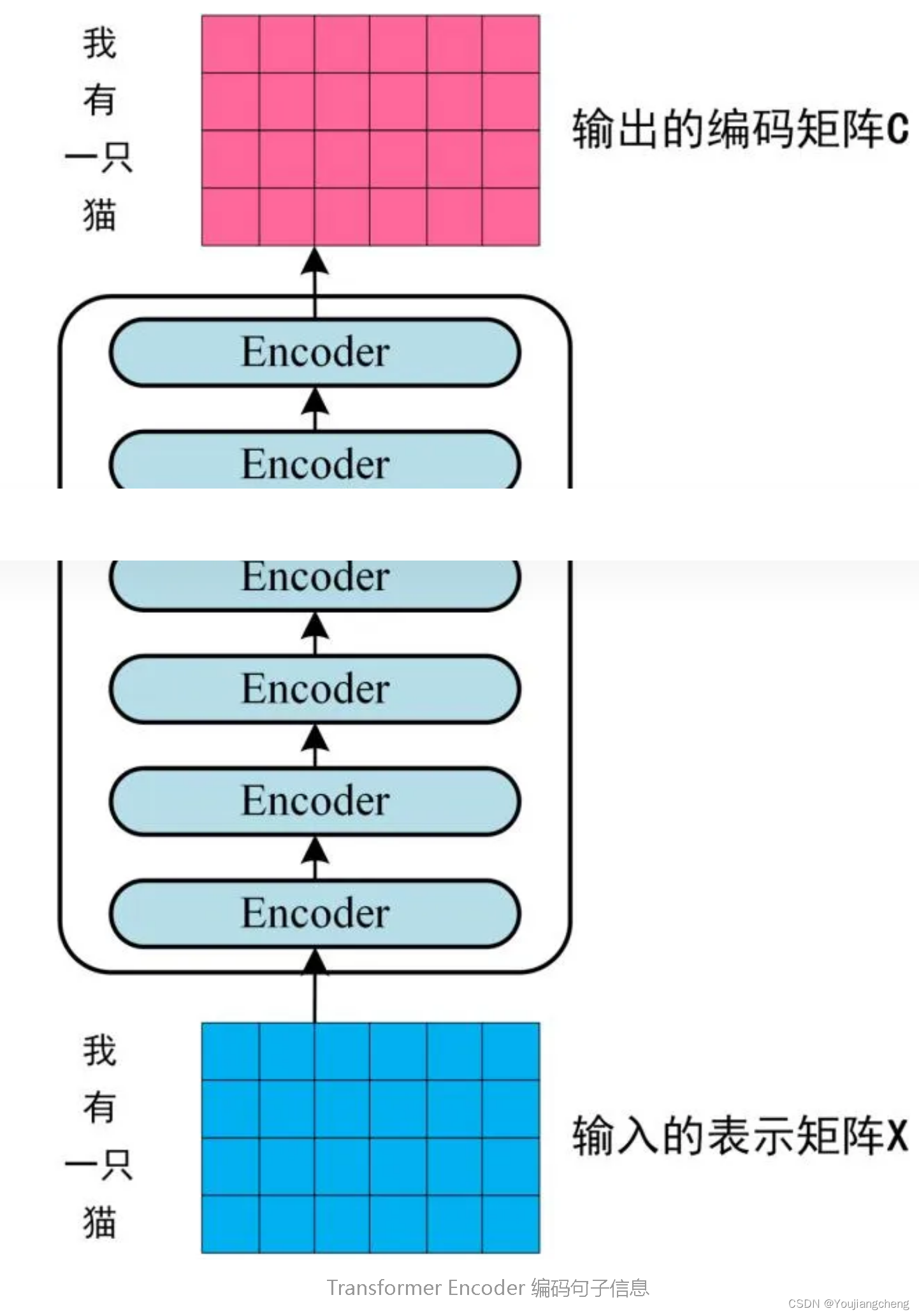
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 Xn×d表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
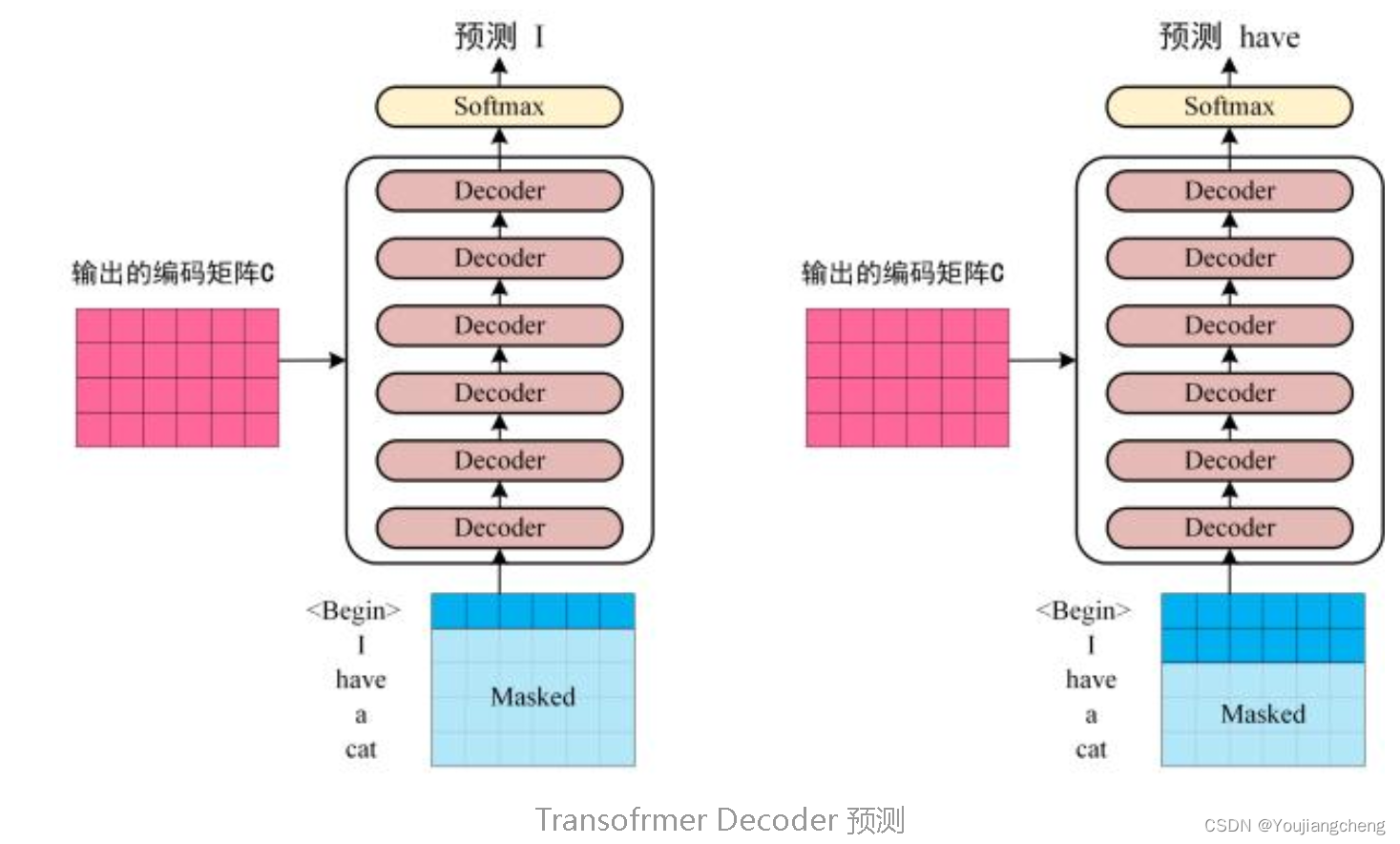
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "<Begin>",预测第一个单词 "I";然后输入翻译开始符 "<Begin>" 和单词 "I",预测单词 "have",以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
2. Transformer 的输入
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
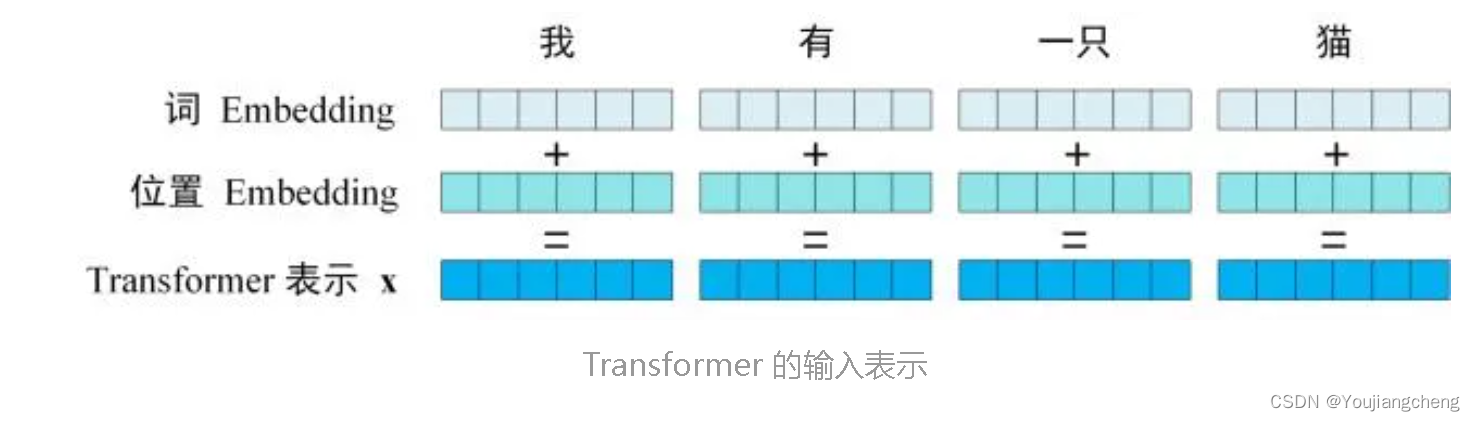
2.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
2.2 位置 Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
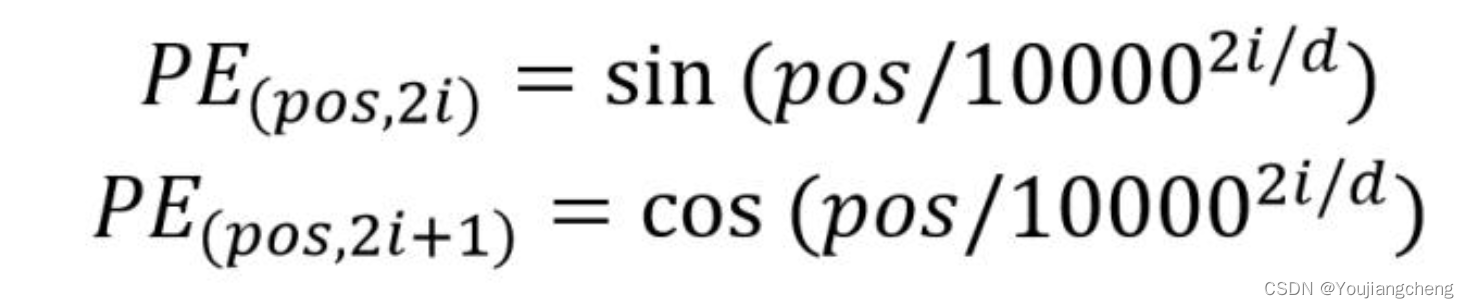
解释一下上面的公式:
pos表示单词在句子中的绝对位置,pos=0,1,2…,例如:Jerry在"Tom chase Jerry"中的pos=2;dmodel表示词向量的维度,在这里dmodel=512;2i和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









