






一、Transformer 输入
Transformer 中单词的输入表示x由单词Embedding和位置 Embedding(Positional Encoding)相加得到,通常定义为TransformerEmbedding 层,其代码实现如下所示:
1.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
1.2 位置 Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE 表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
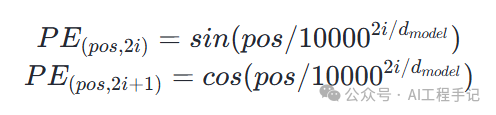
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。
1.1 TransformerEmbedding 层实现



二、Transformer 整体结构
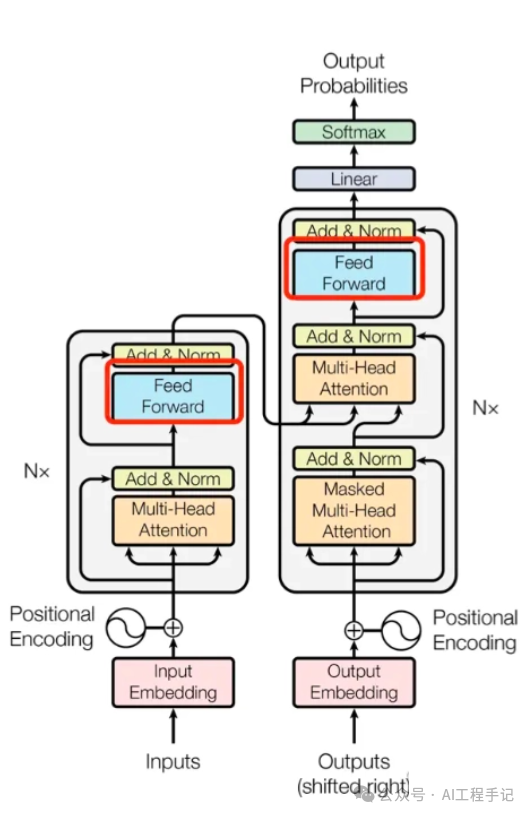
论文中给出用于中英文翻译任务的 Transformer 整体架构如下图所示:
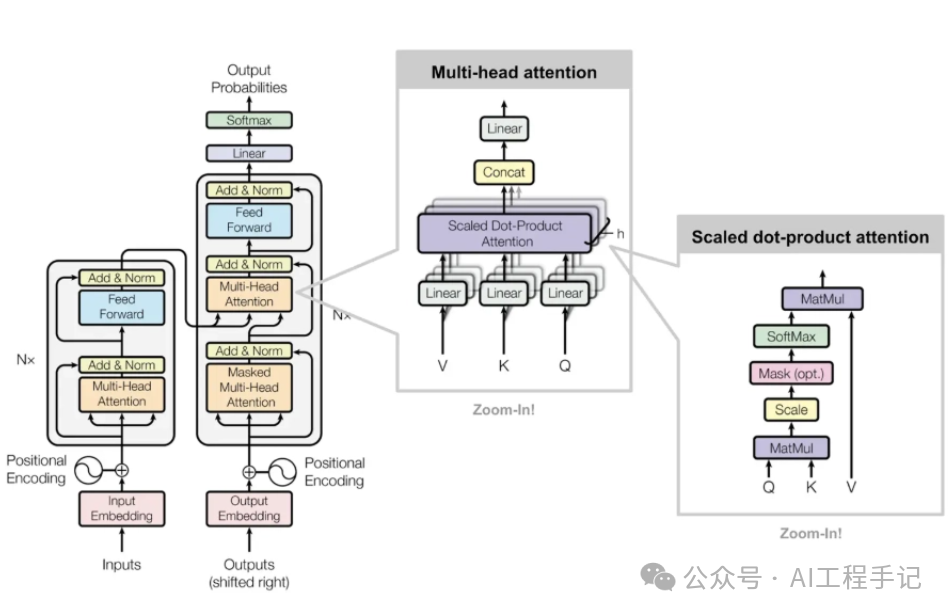
可以看出 Transformer 架构由 Encoder 和 Decoder 两个部分组成:其中 Encoder 和 Decoder 都是由 N=6 个相同的层堆叠而成。Multi-Head Attention 结构是 Transformer 架构的核心结构,其由多个 Self-Attention 组成的。
Transformer 架构更详细的可视化图如下所示:
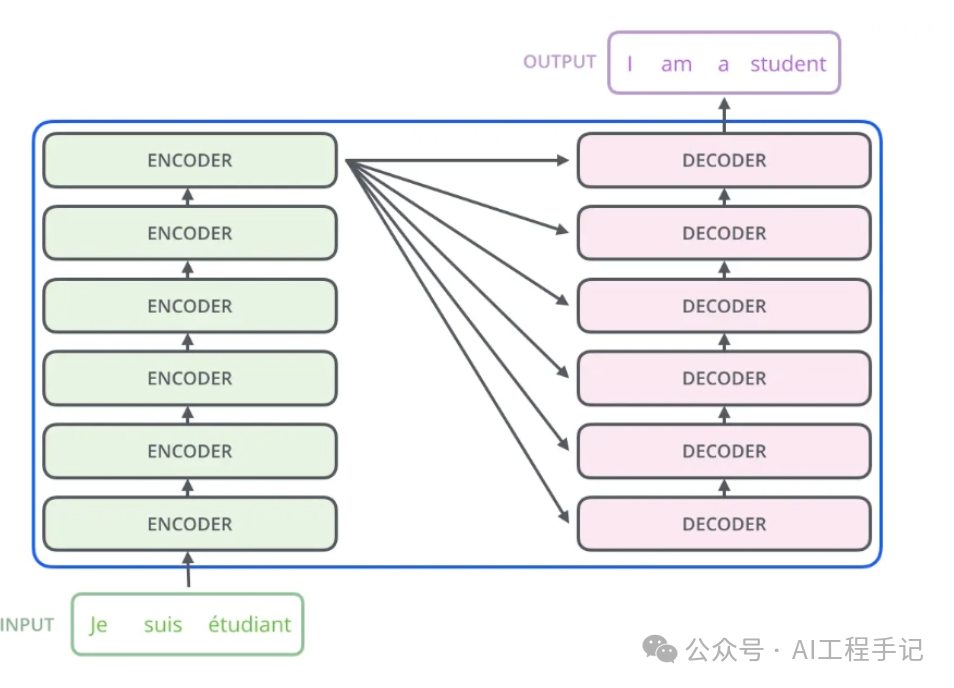
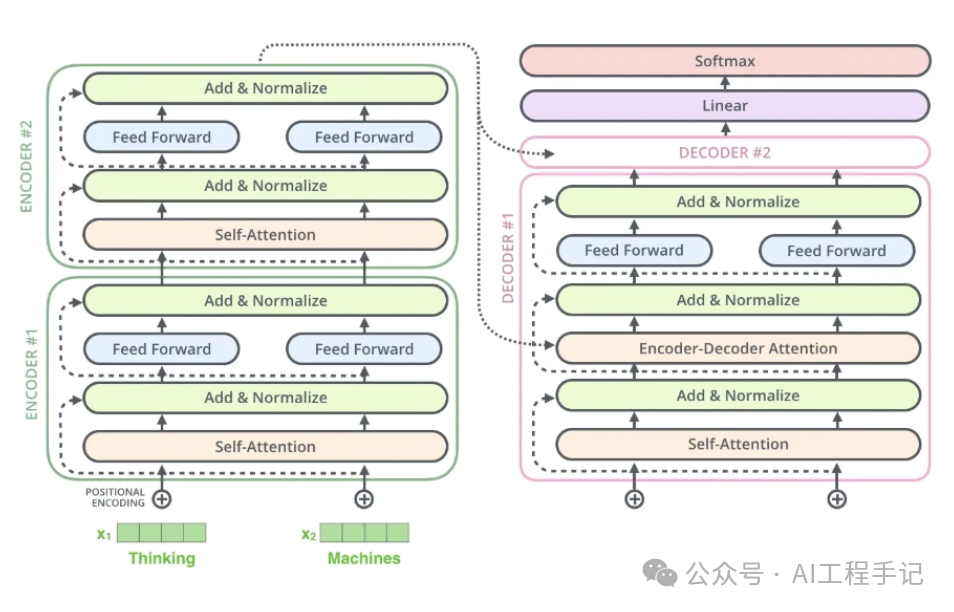
2.1 Transformer 发展史
以下是 Transformer 模型(简短)历史中的一些关键节点:
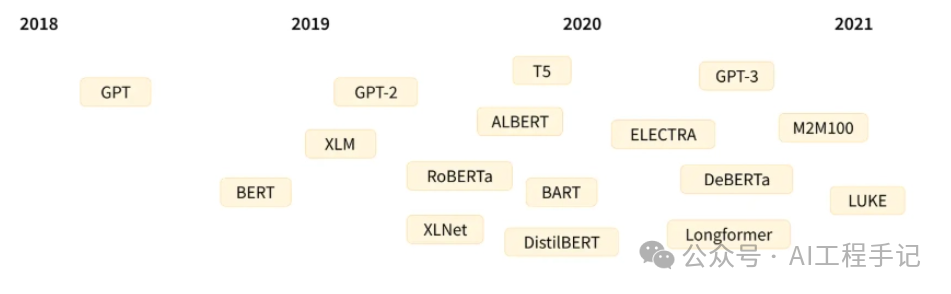
Transformer 架构 于 2017 年 6 月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括
-
-
2018 年 6 月
- GPT, 第一个预训练的 Transformer 模型,用于各种 NLP 任务并获得极好的结果
-
-
2018 年 10 月
- BERT, 另一个大型预训练模型,该模型旨在生成更好的句子摘要(下一章将详细介绍!)
-
-
2019 年 2 月
- GPT-2, GPT 的改进(并且更大)版本,由于道德问题没有立即公开发布
-
-
2019 年 10 月
- DistilBERT, BERT 的提炼版本,速度提高 60%,内存减轻 40%,但仍保留 BERT 97% 的性能
-
-
2019 年 10 月
- BART 和 T5, 两个使用与原始 Transformer 模型相同架构的大型预训练模型(第一个这样做)
-
-
2020 年 5 月
- GPT-3, GPT-2 的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习)
这个列表并不全面,只是为了突出一些不同类型的 Transformer 模型。大体上,它们可以分为三类:
- GPT-like (也被称作自回归 Transformer 模型)
- BERT-like (也被称作自动编码 Transformer 模型)
- BART/T5-like (也被称作序列到序列的 Transformer 模型)
Transformer 是大模型,除了一些特例(如 DistilBERT)外,实现更好性能的一般策略是增加模型的大小以及预训练的数据量。其中,GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。
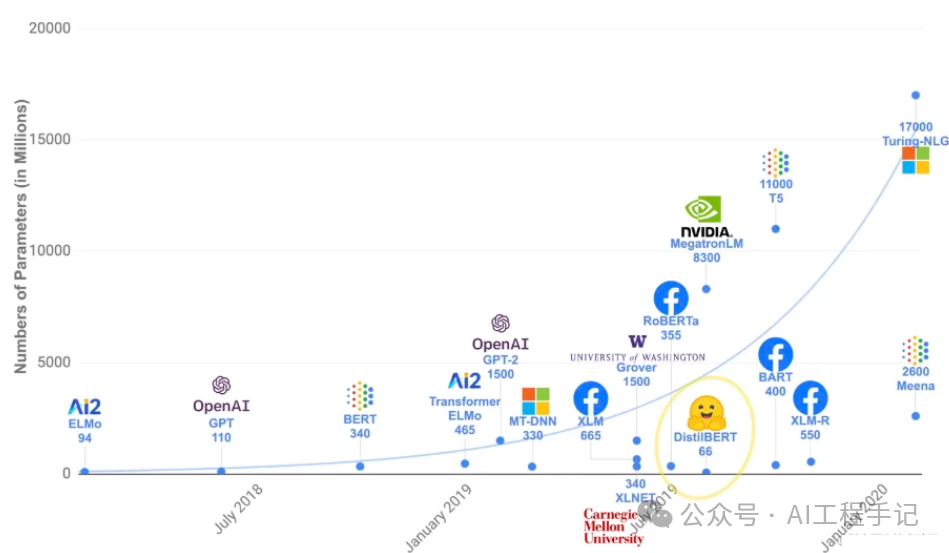
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
三、Multi-Head Attention 结构
Encoder 和 Decoder 结构中公共的 layer 之一是 Multi-Head Attention,其是由多个 Self-Attention 并行组成的。Encoder block 只包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
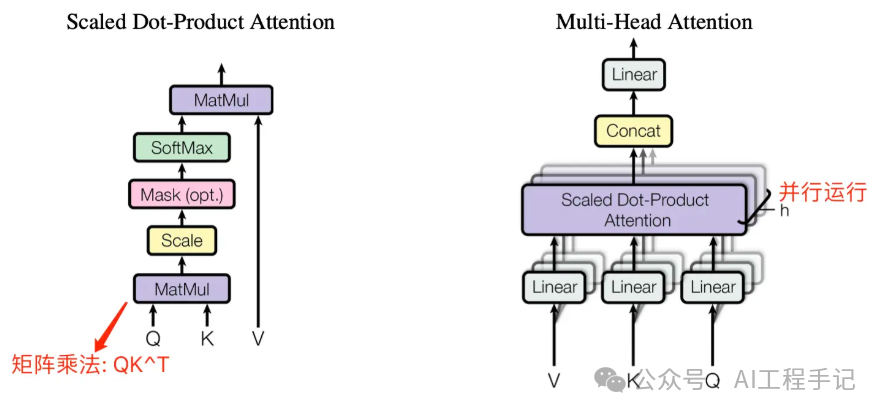
3.1 Self-Attention 结构
Self-Attention 中文翻译为自注意力机制,论文中叫作 Scale Dot Product Attention,它是 Transformer 架构的核心,其结构如下图所示:

那么重点来了,第一个问题:Self-Attention 结构的最初输入 Q(查询), K(键值), V(值) 这三个矩阵怎么理解呢?其代表什么,通过什么计算而来?
在 Self-Attention 中,Q、K、V 是在同一个输入(比如序列中的一个单词)上计算得到的三个向量。具体来说,我们可以通过对原始输入词的 embedding 进行线性变换(比如使用一个全连接层),来得到 Q、K、V。这三个向量的维度通常都是一样的,取决于模型设计时的决策。
第二个问题:Self-Attention 结构怎么理解,Q、K、V的作用是什么?这三个矩阵又怎么计算得到最后的输出?
在计算 Self-Attention 时,Q、K、V 被用来计算注意力分数,即用于表示当前位置和其他位置之间的关系。注意力分数可以通过 Q 和 K 的点积来计算,然后将分数除以 8,再经过一个 softmax 归一化处理,得到每个位置的权重。然后用这些权重来加权计算 V 的加权和,即得到当前位置的输出。
将分数除以 8 的操作,对应图中的
Scale层,这个参数 8 是 K 向量维度 64 的平方根结果。
3.2 Self-Attention 实现
文章的 Self-Attention 层和论文中的 ScaleDotProductAttention 层意义是一样的。
输入序列单词的 Embedding Vector 经过线性变换(Linear 层)得到 Q、K、V 三个向量,并将它们作为 Self-Attention 层的输入。假设输入序列的长度为 seq_len,则 Q、K 和 V 的形状为(seq_len,d_k),其中,dk\text{d}_{\text{k}}dk 表示每个词或向量的维度,也是 QQQ、KKK 矩阵的列数。在论文中,输入给 Self-Attention 层的 Q、K、V 的向量维度是 64, Embedding Vector 和 Encoder-Decoder 模块输入输出的维度都是 512。
Embedding Vector 的大小是我们可以设置的超参数—基本上它就是我们训练数据集中最长句子的长度。
Self-Attention 层的计算过程用数学公式可表达为:
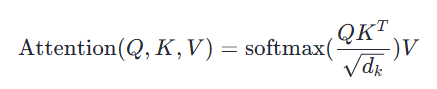
以下是一个示例代码,它创建了一个 ScaleDotProductAttention 层,并将 Q、K、V 三个张量传递给它进行计算:

3.3 Multi-Head Attention
Multi-Head Attention (MHA) 是基于 Self-Attention (SA) 的一种变体。MHA 在 SA 的基础上引入了“多头”机制,将输入拆分为多个子空间,每个子空间分别执行 SA,最后将多个子空间的输出拼接在一起并进行线性变换,从而得到最终的输出。
对于 MHA,之所以需要对 Q、K、V 进行多头(head)划分,其目的是为了增强模型对不同信息的关注。具体来说,多组 Q、K、V 分别计算 Self-Attention,每个头自然就会有独立的 Q、K、V 参数,从而让模型同时关注多个不同的信息,这有些类似 CNN 架构模型的多通道机制。
下图是论文中 Multi-Head Attention 的结构图。

从图中可以看出, MHA 结构的计算过程可总结为下述步骤:
- 将输入 Q、K、V 张量进行线性变换(
Linear层),输出张量尺寸为 [batch_size, seq_len, d_model]; - 将前面步骤输出的张量,按照头的数量(
n_head)拆分为n_head子张量,其尺寸为 [batch_size, n_head, seq_len, d_model//n_head]; - 每个子张量并行计算注意力分数,即执行 dot-product attention 层,输出张量尺寸为 [batch_size, n_head, seq_len, d_model//n_head];
- 将这些子张量进行拼接
concat,并经过线性变换得到最终的输出张量,尺寸为 [batch_size, seq_len, d_model]。
总结:因为 GPU 的并行计算特性,步骤2中的张量拆分和步骤4中的张量拼接,其实都是通过 review 算子来实现的。同时,也能发现SA 和 MHA 模块的输入输出矩阵维度都是一样的。
3.4 Multi-Head Attention 实现
Multi-Head Attention 层的输入同样也是三个张量:查询(Query)、键(Key)和值(Value),其计算过程用数学公式可表达为:
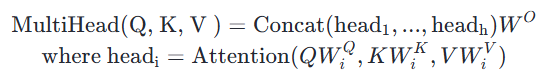
一般用 d_model 表示输入嵌入向量的维度, n_head 表示分割成多少个头,因此,d_model//n_head 自然表示每个头的输入和输出维度,在论文中 d_model = 512,n_head = 8,d_model//n_head = 64。值得注意的是,由于每个头的维数减少,总计算成本与具有全维的单头注意力是相似的。
Multi-Head Attention 层的 Pytorch 实现代码如下所示:


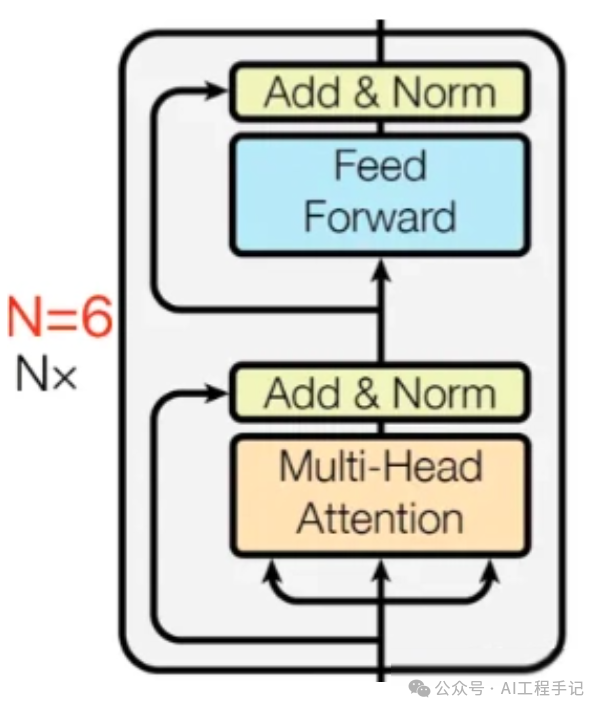
四、Encoder 结构
Encoder 结构由 N=6\text{N} = 6N=6 个相同的 encoder block 堆叠而成,每一层( layer)主要有两个子层(sub-layers): 第一个子层是多头注意力机制(Multi-Head Attention),第二个是简单的位置全连接前馈网络(Positionwise Feed Forward)。
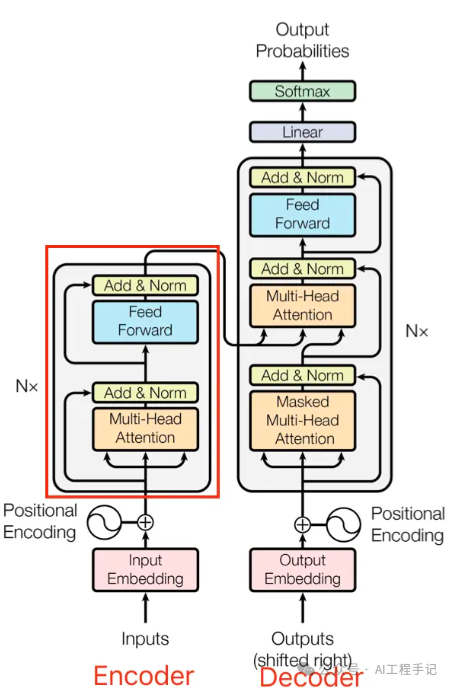
上图红色框框出的部分是 Encoder block,很明显其是 Multi-Head Attention、Add&Norm、Feed Forward、Add & Norm 层组成的。另外在论文中 Encoder 组件由 N=6\text{N} = 6N=6 个相同的 encoder block 堆叠而成,且 encoder block 输入矩阵和输出矩阵维度是一样的。
4.1 Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成。这里的 Add 指 X + MultiHeadAttention(X),是一种残差连接。Norm 是 Layer Normalization。Add & Norm 层计算过程用数学公式可表达为:
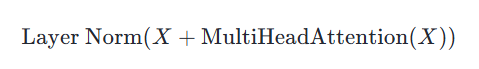
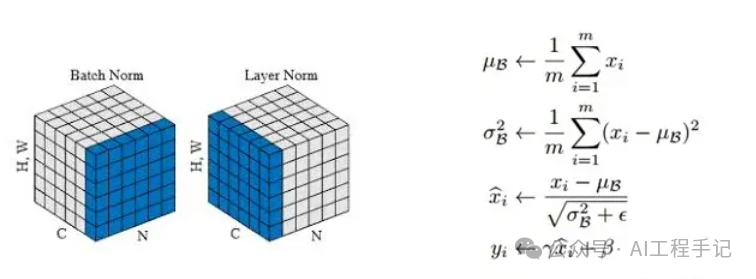
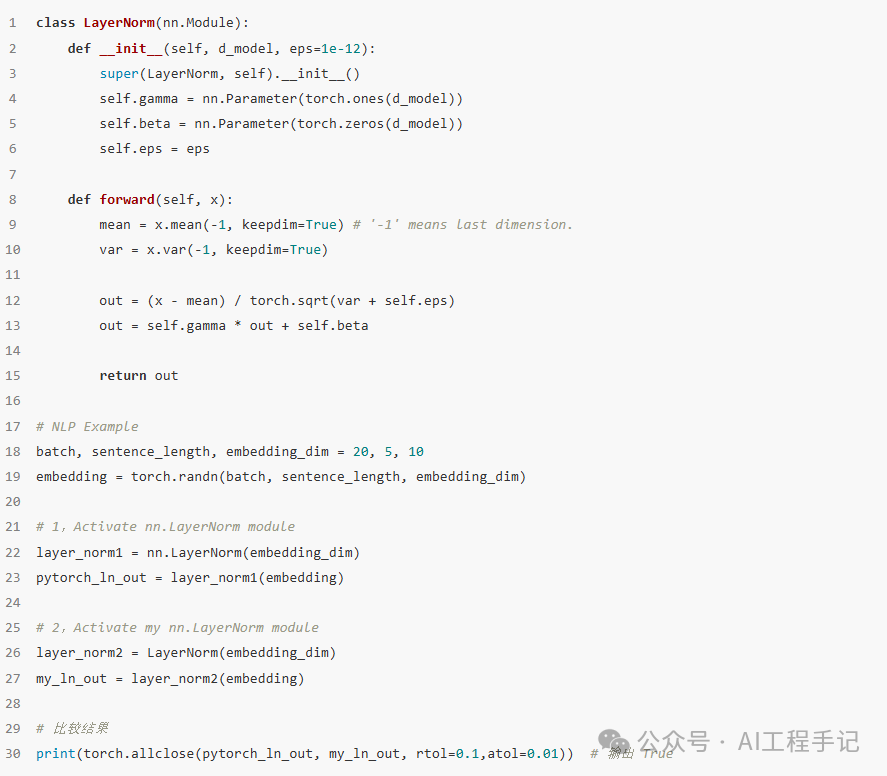
Add 比较简单,这里重点讲下 Layer Norm 层。Layer Norm 是一种常用的神经网络归一化技术,可以使得模型训练更加稳定,收敛更快。它的主要作用是对每个样本在特征维度上进行归一化,减少了不同特征之间的依赖关系,提高了模型的泛化能力。Layer Norm 层的计算可视化如下图所示:
Layer Norm 层的 Pytorch 实现代码如下所示:
4.2 Feed Forward
Feed Forward 层全称是 Position-wise Feed-Forward Networks,其本质是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,计算过程用数学公式可表达为:
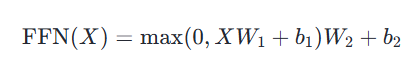
除了使用两个全连接层来完成线性变换,另外一种方式是使用 kernal_size = 1 的两个 1×11\times 11×1 卷积层,输入输出维度不变,都是 512,中间维度是 2048。
PositionwiseFeedForward 层的 Pytorch 实现代码如下所示:

4.3 Encoder 结构的实现
基于前面 Multi-Head Attention, Feed Forward, Add & Norm 的内容我们可以完整的实现 Encoder 结构。
Encoder 组件的 Pytorch 实现代码如下所示:

五、Decoder 结构
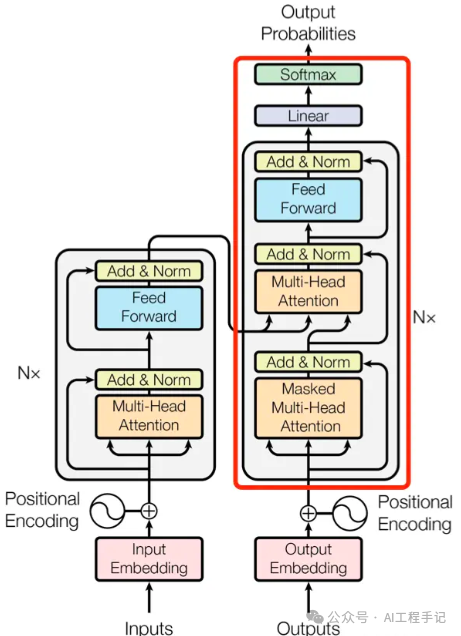
上图右边红框框出来的是 Decoder block,Decoder 组件也是由 N=6\text{N} = 6N=6 个相同的 Decoder block 堆叠而成。Decoder block 与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Q 使用上一个 Decoder block 的输出计算。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)
注意,解码器块中的第一个注意力层关联到解码器的所有(过去的)输入,但是第二注意力层使用编码器的输出。因此,它可以访问整个输入句子,以最好地预测当前单词。这是非常有用的,因为不同的语言可以有语法规则将单词按不同的顺序排列,或者句子后面提供的一些上下文可能有助于确定给定单词的最佳翻译。
另外,Decoder 组件后面还会接一个全连接层和 Softmax 层计算下一个翻译单词的概率。
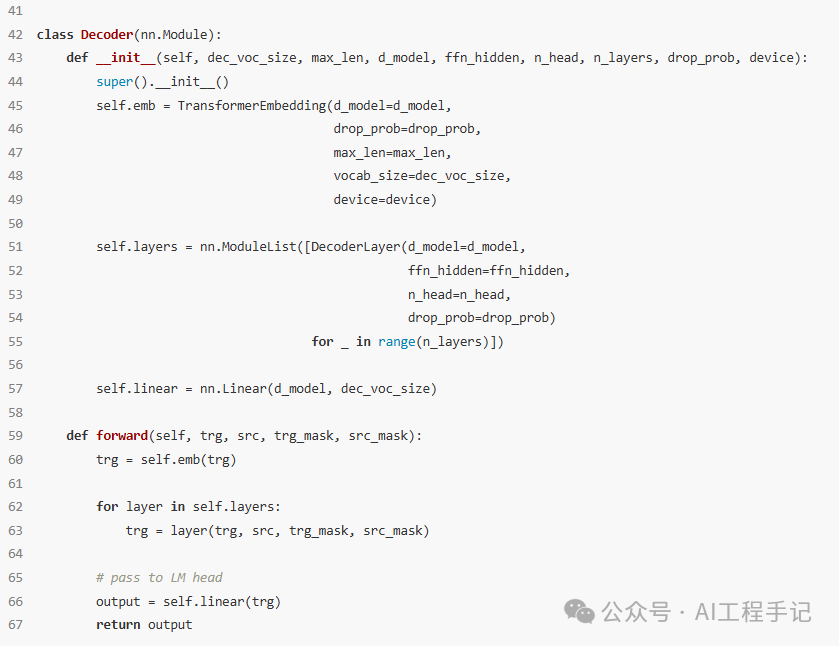
Decoder 组件的代码实现如下所示:

六、Transformer 总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
6.1 Transformer 完整代码实现
基于前面实现的 Encoder 和 Decoder 组件,我们可以实现 Transformer 模型的完整代码,如下所示:


最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









