







一.softmax和分类模型:
1.1 离散值与神经网络与softmax
1.1.1 离散值
由于线性回归 都是预测连续性的值,当需要进行离散值.
进行分类:
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为y1,y2,y3。 我们通常使用离散的数值来表示类别,例如y1=1,y2=2,y3=3
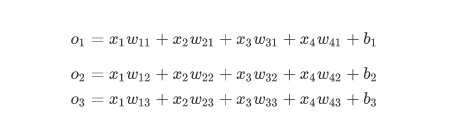
1.1.2 神经网络:
图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出o1,o2,o3的计算都要依赖于所有的输入x1,x2,x3,x4,softmax回归的输出层也是一个全连接层。
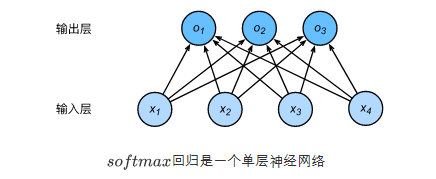
例如,如果o1,o2,o3分别为0.1,10,0.1,由于o2最大,那么预测类别为2,则其代表猫。
1.1.3 softmax
一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果o1=o3=103,那么输出值10却又表示图像类别为猫的概率很低。
另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
于是引入softmax

1.2 损失函数
之前线性回归引入的平方差函数:
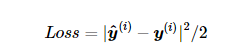
然而,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率。例如,在图像分类的例子里,如果y(i)=3,那么我们只需要y3(i) 比其他两个预测值 y1(i)和y2(i) 大就行了。即使 y3(i) 值为0.6,不管其他两个预测值为多少,类别预测均正确。而平方损失则过于严格,例如y1(i)=y2(i)=0.2比y1(i)=0,y2(i)=0.4的损失要小很多,虽然两者都有同样正确的分类预测结果。故引入交叉熵函数
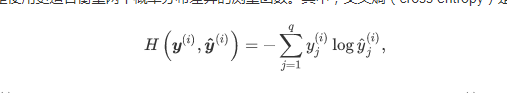
1.3 实践
1.读取数据集
def data_iter(batch_size, features,labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0,num_examples,batch_size):
j = indices[i,min(i+batch_size,num_examples)]
yield features.index_select(0,j),labels.index_select(0,j)
2.初始化参数
def init(input_channels,output_channels):
w = torch.tensor(np.random.normal(0,0.01,size = (num_inputs,output_channels)),dtype = torch.float32)
b= torch.zeros(output_channels,dtype = torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
3.softma
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True)
return X_exp / partition
4.定义线性模型
def Linear(X,w,b):
return torch.mm(X,w)+b
5.神经网络模型
def net(X,w,b):
return softmax(Linear(X,w.b))
6.定义损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
5.定义优化方法
def SGD(params,lr,batch_size)
for param in params:
param.data -= lr*params.grad()/batch_size
6.开始训练
def train_ch3(net, features, labels, loss, num_epochs, batch_size,
params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in data_iter(features,labels):
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]















 2335
2335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









