






小样本学习(Few-shot learning, FSL),在少数资料中也被称为low-shot learning(LSL)。小样本学习是一种训练数据集包含有限信息的机器学习问题。
对于机器学习应用来说,通常的做法是提供尽可能多的数据。这是因为在大多数机器学习应用中,输入更多的数据训练能使模型的预测效果更好。然而,小样本学习的目标是
使用数量较少的训练集来构建准确的机器学习模型。由于输入数据的维度是一个决定资源消耗成本(如,时间成本,计算成本等)的因素,公司可以通过使用小样本学习来降低数据分析/机器学习消耗成本。
随着深度学习技术的不断进步,小样本学习正成为人工智能研究的热点之一。未来的研究可能会聚焦于如何结合深度学习与小样本学习,提高模型的泛化能力和适应性,以及如何通过无监督或半监督学习方法缓解标注数据缺乏的问题。
为帮助同学们获取论文,小编整理了一些小样本学习论文合集,小编整理了一些持续学习论文合集,以下放出部分,论文原文+开源代码需要的同学关注“AI科研灵感”公号,那边回复“小样本学习”获取。
论文1:
Adaptive Subspaces for Few-Shot Learning
用于少样本学习的自适应子空间
方法
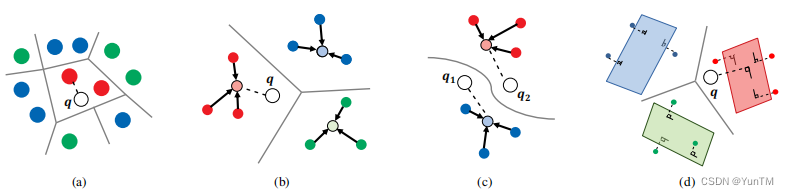
动态分类器框架:提出了一个基于少量样本构建的动态分类器框架,核心是利用子空间方法作为动态分类器的主要组成部分。
子空间建模:通过子空间方法对视觉数据进行建模,与以往通过池化(例如平均池化)实现的对称函数不同,本研究提出了使用子空间构建对称函数的新方法。
判别式形式:开发了一种判别式形式,通过在训练过程中鼓励子空间之间的最大区分度来进一步提升准确性。
半监督学习适应性:展示了该方法可以利用未标记数据,从而适用于半监督少样本学习和归纳设置,并通过实验验证了该变体的鲁棒性。
创新点
子空间方法的提出:首次提出使用子空间方法来构建少样本学习中的分类器,与原型网络相比,在CUB数据集上展示了更好的性能。
鲁棒性增强:通过子空间建模,该方法在对抗扰动(例如异常值)方面显示出了更好的鲁棒性,并且在监督和半监督少样本分类任务中取得了有竞争力的结果。
判别式训练的提升:通过引入判别式训练,进一步增强了模型的性能,使得子空间之间的区分度最大化,提高了分类的准确性。
代码开源:提供了实现该方法的代码,方便其他研究者进行验证和进一步的研究。
论文2:
FEW-SHOT LEARNING WITH GRAPH NEURAL NETWORKS使用图神经网络的少样本学习
方法
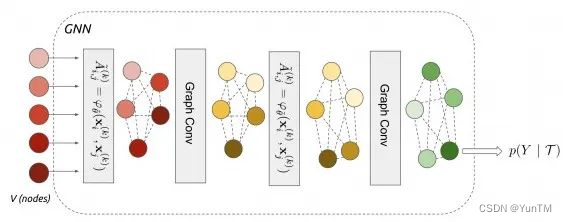
图神经网络架构:提出了一个图神经网络架构,该架构将少样本学习问题视为在部分观察到的图形模型上的推断问题,该图形模型由一系列输入图像构成,其标签可以被观察到或不被观察到。
消息传递算法:通过将通用的消息传递推断算法与神经网络对应物相融合,定义了一个图神经网络架构,该架构概括了最近提出的几种少样本学习模型。
半监督和主动学习扩展:框架易于扩展到少样本学习的变体,如半监督或主动学习,展示了基于图的模型在“关系”任务上的良好性能。
创新点
图神经网络的应用:首次将图神经网络应用于少样本学习任务,通过构建基于图的结构化数据模型,提供了一种新的学习范式。
性能提升:在Omniglot和Mini-Imagenet任务上匹配了最先进的性能,同时使用了更少的参数。
学习任务的统一框架:通过图神经网络框架,统一了多种学习任务(少样本、主动、半监督)的训练设置,为构建能够在不同模式下同时操作的单一学习者提供了可能。
论文3:
Generalizing from a Few Examples: A Survey on Few-Shot Learning
从少量样本泛化:少样本学习综述
方法
问题定义:提供了少样本学习(FSL)的正式定义,并从数据、模型和算法三个角度对FSL方法进行了分类。
相关学习问题区分:讨论了FSL与弱监督学习、不平衡学习、迁移学习和元学习等相关学习问题的关联性和差异。
核心问题指出:指出FSL监督学习问题的核心是经验风险最小化器不可靠,并基于此对FSL方法进行了系统性的分析和分类。

创新点
系统性分类:首次对FSL方法进行了系统性的分类,帮助研究者更好地理解FSL方法的优缺点,并为未来的研究提供了清晰的方向。
未来研究方向提出:基于FSL当前发展的弱点,提出了在问题设置、技术、应用和理论方面的有前景的未来研究方向,为FSL的进一步发展提供了指导。
综述贡献总结:总结了FSL的相关工作,并提出了新的研究目标,有助于推动FSL领域的发展。
论文4:
Learning from Few Examples: A Summary of Approaches to Few-Shot Learning
从少量样本学习:少样本学习方法概述
方法
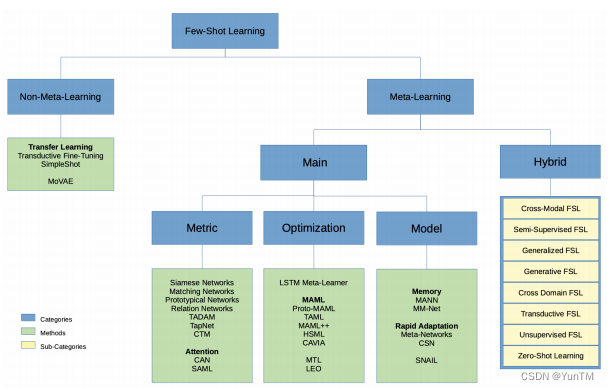
元学习基础:介绍了元学习(Meta-Learning)的背景知识,包括问题定义和元学习在少样本学习中的应用。
分类方法:将少样本学习方法分为基于元学习的少样本学习和非基于元学习的少样本学习两大类,并对每种方法进行了详细的讨论。
数据增强:探讨了如何通过数据增强技术来解决少样本学习问题,包括从Dtrain中变换样本、从弱标注或未标注数据集中变换样本以及从相似数据集中变换样本。
模型约束:讨论了如何通过先验知识来约束模型的假设空间,使得在有限的样本下也能有效地学习。
算法调整:分析了如何利用先验知识来改变搜索最佳假设的算法策略,包括提供一个好的初始化参数或直接学习优化器来输出搜索步骤。
创新点
多模态信息融合:提出了在设计少样本学习方法时考虑多模态信息的可能性,这可能为少样本学习提供更丰富的先验知识。
自动化机器学习(AutoML)的应用:提出了将AutoML技术扩展到少样本学习中的潜在方向,这可能实现更经济、高效和有效的算法设计。
实际应用领域的扩展:强调了少样本学习在计算机视觉、自然语言处理、机器人技术等多个领域的应用潜力,并鼓励探索这些领域的新应用。
理论分析的深入:提出了对少样本学习的理论分析,包括样本复杂度、领域适应和算法收敛性的理论问题,这有助于更深入地理解少样本学习的原理和性能限制。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









