






2024深度学习发论文&模型涨点之——频域+知识蒸馏
即将2025,频域+知识蒸馏还能做吗?!当然,知识蒸馏仍然是一个活跃的研究领域,并且随着深度学习技术的不断进步,知识蒸馏的研究思路也在不断革新。将频域和知识蒸馏结合起来,可以用于提高生成模型(如生成对抗网络GAN)的效率和性能。例如,小波知识蒸馏(Wavelet Knowledge Distillation)是一种方法,它通过离散小波变换将图像分解为不同的频带,然后只对高频成分进行蒸馏。
这种方法可以帮助学生模型更加关注高频信息的学习,从而提高生成图像的质量。在一些研究中,频域知识蒸馏被用来提高图像到图像翻译任务的效率,通过压缩和加速模型,同时保持性能。
小编整理了一些频域+知识蒸馏论文合集,论文原文+开源代码需要的同学关注“AI科研论文”公号,那边回复“频域+注意力机制”获取。
论文1:
A self‐distillation object segmentation method via frequency domain knowledge augmentation
通过频域知识增强的自蒸馏目标分割方法
方法
模型构建:构建了一个高效整合多级特征的目标分割网络,以提高分割性能。
虚拟教师生成模型:提出了一个像素级虚拟教师生成模型,通过自蒸馏学习将像素级知识传递给目标分割网络,增强其泛化能力。
频域知识适应生成方法:提出了一种频域知识适应扩展方法,利用可微分量化操作符动态调整可学习的像素级量化表,以增强数据。
实验验证:在五个目标分割数据集上进行实验,验证了所提方法能有效提升目标分割网络的性能。
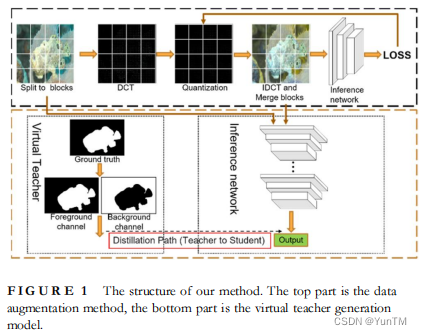
创新点
频域知识蒸馏:首次提出在频域中通过自蒸馏增强知识的方法,揭示了卷积神经网络在学习过程中更倾向于学习低频信息。
性能提升:所提方法在无需复杂辅助教师结构和大量训练样本的情况下,通过频域知识增强,有效提高了目标分割的性能。
自蒸馏学习方法:通过像素级虚拟教师和数据增强方法,实现了自蒸馏学习,提高了模型的分割结果,与典型特征精炼自蒸馏方法相比,平均Fβ和mIoU分别提高了约1.5%和3.6%。
论文2:
DDK: Distilling Domain Knowledge for Efficient Large Language ModelsDDK:蒸馏领域知识以提升高效的大型语言模型
方法
领域性能差异调整:提出了一个新的大型语言模型(LLM)蒸馏框架DDK,根据教师和学生模型在不同领域的性能差异动态调整蒸馏数据集的组成。
领域知识引导采样:基于教师和学生模型之间的性能差距,采用领域知识引导的采样策略,以不同的概率从不同领域采样数据。
因子平滑更新机制:引入了因子平滑更新机制,以增强DDK方法的稳定性和鲁棒性。
优化算法:通过最小化教师和学生模型输出逻辑之间的差异来进行监督损失的优化。
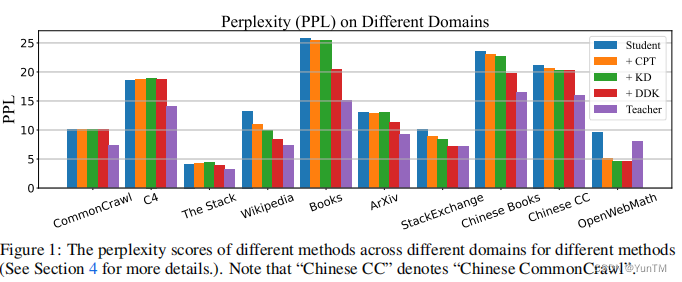
创新点
领域特定数据混合研究:首次研究了领域特定数据混合对LLMs蒸馏的影响,并有效地转移教师网络的领域知识。
因子平滑更新策略:提出了因子平滑更新策略,以战略性地增强蒸馏过程中对目标领域的关注,有效稳定了领域知识引导的采样过程。
广泛实验验证:在多个基准数据集上进行了广泛的实验,证明了DDK的有效性和泛化能力。
论文3:
Impact analysis of applying knowledge distillation in neural networks on domain shift
应用知识蒸馏在神经网络领域偏移影响分析
方法
WIFI-CSI数据应用:探讨了无线通信技术在多种应用中的使用,特别是WIFI-CSI数据在机器学习中的分类和估计任务。
深度学习模型:使用了深度学习模型,特别是EfficientNet家族模型,来处理复杂的分类任务,如计算机视觉和高维数据。
知识蒸馏技术:应用了基本的知识蒸馏技术和多种教师方法,包括平均教师逻辑和随机选择教师模型的方法。
实验设计:设计了多个实验来评估知识蒸馏技术在存在领域偏移的数据上的表现,包括基线实验、基本蒸馏实验和多教师实验。
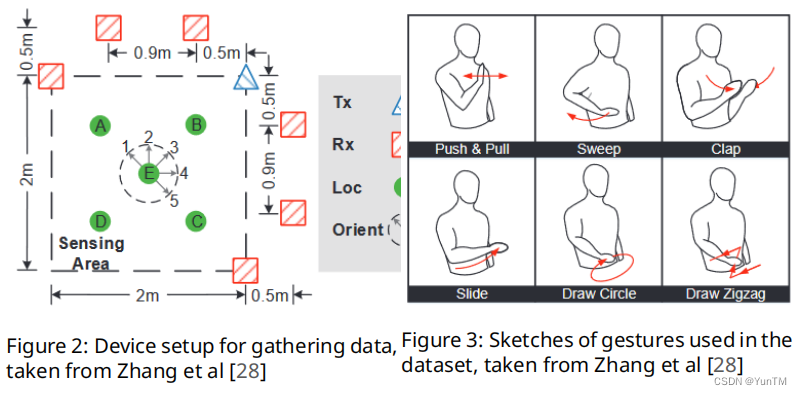
创新点
领域偏移适应性:研究了知识蒸馏技术在处理训练和测试数据之间存在领域偏移时的有效性,提供了模型性能和模型大小之间的平衡。
多教师蒸馏策略:探索了不同的多教师知识蒸馏策略,包括平均逻辑和随机选择教师模型的方法,以提高模型在领域偏移下的鲁棒性。
实验结果分析:通过实验结果,分析了知识蒸馏技术在减少模型大小的同时,如何保持或提高模型性能,特别是在存在领域偏移的情况下。
论文4:
Teach Harder, Learn Poorer: Rethinking Hard Sample Distillation for GNN-to-MLP Knowledge Distillation
《教更难,学更差:重新思考GNN到MLP知识蒸馏中的难样本蒸馏》
方法
难样本识别:从难度的角度重新审视教师GNN中的知识样本,识别出难样本蒸馏可能是现有图知识蒸馏算法的性能瓶颈。
硬度感知蒸馏框架(HGMD):提出了一个简单而有效的硬度感知GNN到MLP蒸馏框架,该框架解耦了学生无关的知识硬度和学生依赖的蒸馏硬度,并使用非参数方法估计它们。
硬度感知蒸馏方案:提出了两种硬度感知的蒸馏方案(HGMD-weight和HGMD-mixup),用于从教师GNN中蒸馏出硬度感知的知识到学生MLP的对应节点。
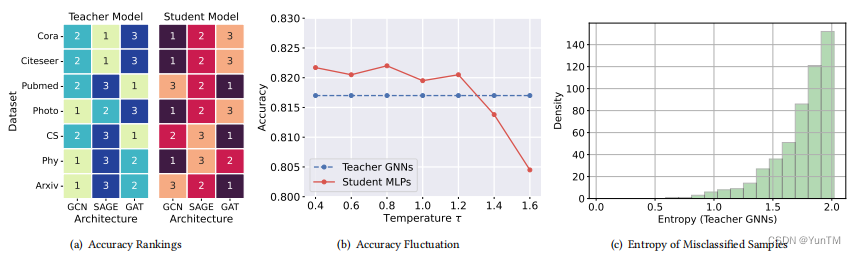
创新点
难样本蒸馏的重要性:首次识别出难样本蒸馏是限制现有GNN到MLP知识蒸馏算法性能的主要瓶颈,并详细描述了它的含义、影响以及如何处理。
知识硬度与蒸馏硬度的解耦:提出了一种非参数方法来估计这两种不同的硬度,而不是将它们混为一谈。
非参数蒸馏方案:提出了两种基于解耦硬度的蒸馏方案,尽管没有引入额外的可学习参数,但性能仍可与大多数最新竞争对手相媲美。
实验验证:HGMD-mixup在七个真实世界数据集上的平均性能超过了普通MLPs 12.95%,并且超过了教师GNNs 2.48%,证明了该方法的有效性。

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









