







最近在读《基于R语言的自动数据收集》,在连续看了几天之后,手痒开始进行实践,这本书总体来说不错,推荐入坑。
但是对于一个没有HTML/XML等网页基础的数据狗来说,理解这个原理有点复杂,好在书中和网上信息丰富,得以管中窥豹。、
个人理解,初级的网络内容爬取,主要的原理和步骤很简单:
1. 理解网页的编写逻辑
2. 找到批量提取的机械路径
3. 根据提取目的编写提取函数
先说第一点,这一点我觉得是非常重要的,每个网页编写的逻辑不同,比如CSDN和虎嗅的首页逻辑肯定有差别,更不用说网易新闻、腾讯新闻等这种单网页多模块,其中还包括JS的复杂网页了,顺便说一句,博客类网站(包括知乎)主要以文字为主,而且根据前端的表现,也没有各种网页交互,广告满天飞、需要各种点击等,逻辑相对简单;反过来说,尝试理解京东的首页逻辑,感觉就复杂的多。本文也以这类博客类网站为主。
我们需要知道,网页编写是有逻辑的,这也是自动化的基础,那么有一定的逻辑编写,也有一定的逻辑提取;就好比网页后台是2.5*2,前台展示5,我们知道后台的逻辑就是前台展示除2的话,我们就可以通过前台的数据去转到后台提取。
基础知识储备:xpath,xml、正则表达式
先说xml,我们在网页上看到的无论表格、博客的摘要、标题等一系列都有一个标准的,称为w3c标准;其中通过审查元素可以看到网页的XML元素,如我在我的首页进行查看(浏览器点审查元素,或查看源代码),有这个东西:
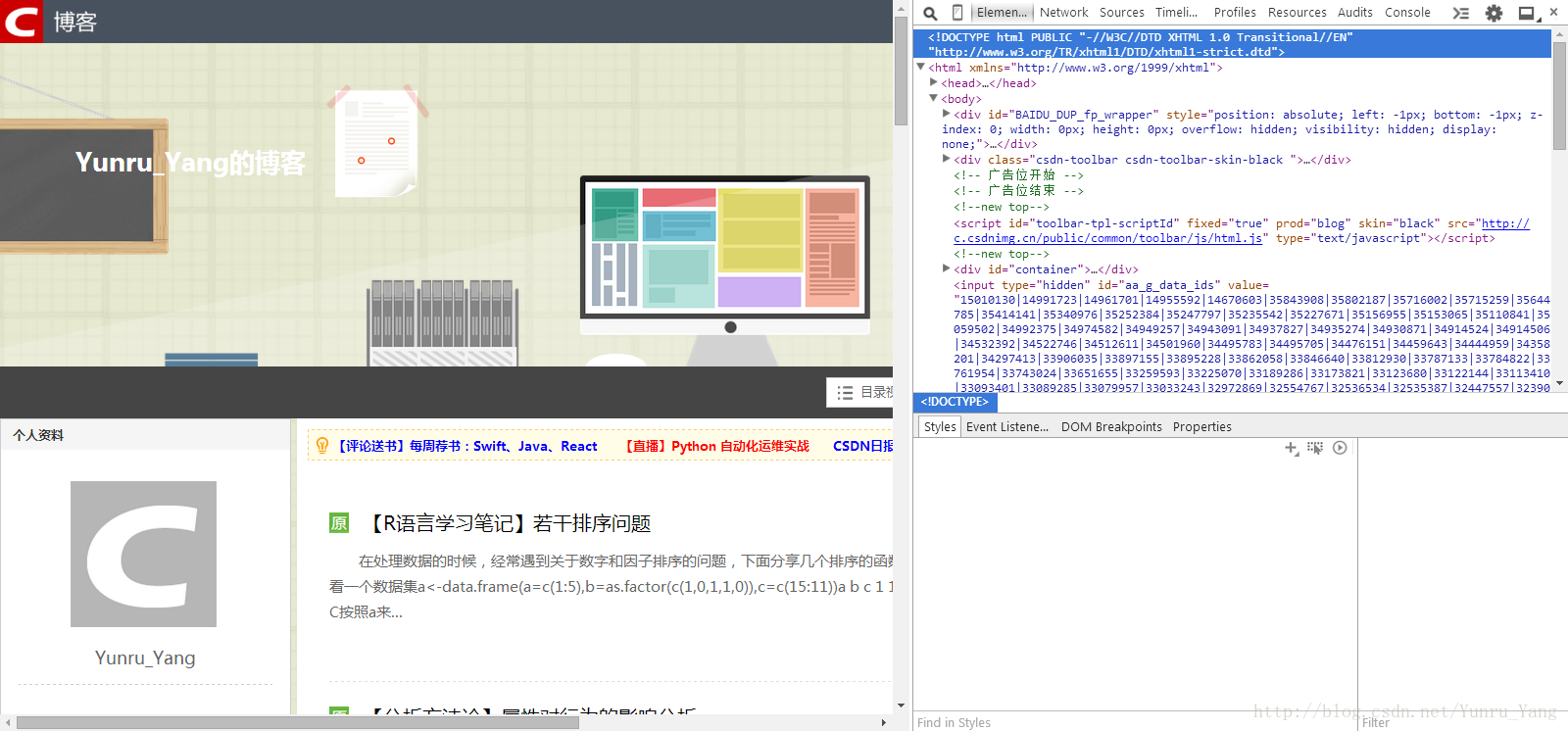
右面密密麻麻的代码就是XML规则编写的代码,这边仔细看是有规律的(具体的规律后面会详述),我们理解的代码就是这套代码
OK,假设我们对代码了如指掌,下一步就是进行信息抽取了,这个工具或者语法就是xpath,xpath可以认为反过来针对编写好的xml规则进行提取,比如针对网页头的xml代码是
<head>我是个开头</head>根据<head>这个属性可以对中间那段话进行提取
最后就是利用万能的R进行数据提取了,我们提取的内容有很多种,比如提取url,如果有下载链接的话,批量下载csv、pdf、xls等,或者我们只提取日期、作者然后做下一步的统计等等,用途也不同,可能有的单纯为了观测和资料搜集(可以放到csv中),或者直接后续用R进行聚类,等等等等;接下来我们就用第一种对我的博客进行资料提取的例子,最后扩展成一个封装的R函数,可以提取更多人的博客标题和对应的url,输出一个列表,方便我们查看。下面开始:
我们从最简单的入手,我们网络提取的目标为看我这个博客中所有的文章、摘要和url,最后形成一个列表,方便查看;基于这个目的和前面说的步骤,需要理解下xml的代码。
先观察代码和整个页面逻辑,CSDN博客首页的文章应该按照统一的逻辑生成,包含标题、摘要、时间、阅读数、评论数等,如图:
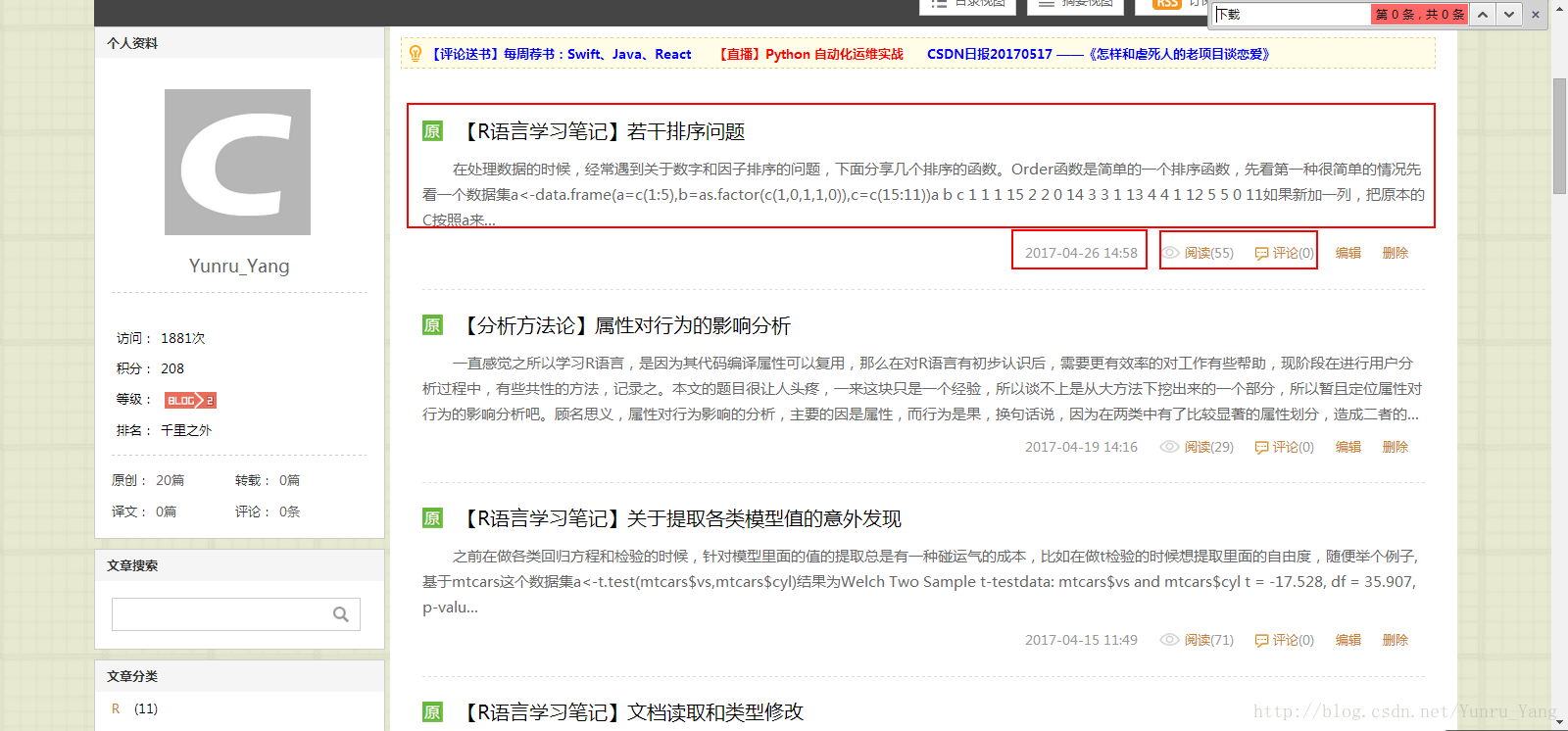
每个文章显示的部分都是一致的,这也是未来我们可以提取的可能;个人有个技巧,可以在源码界面搜索标题,比如‘若干排序问题’,就可以看到对应的XML代码,如图:
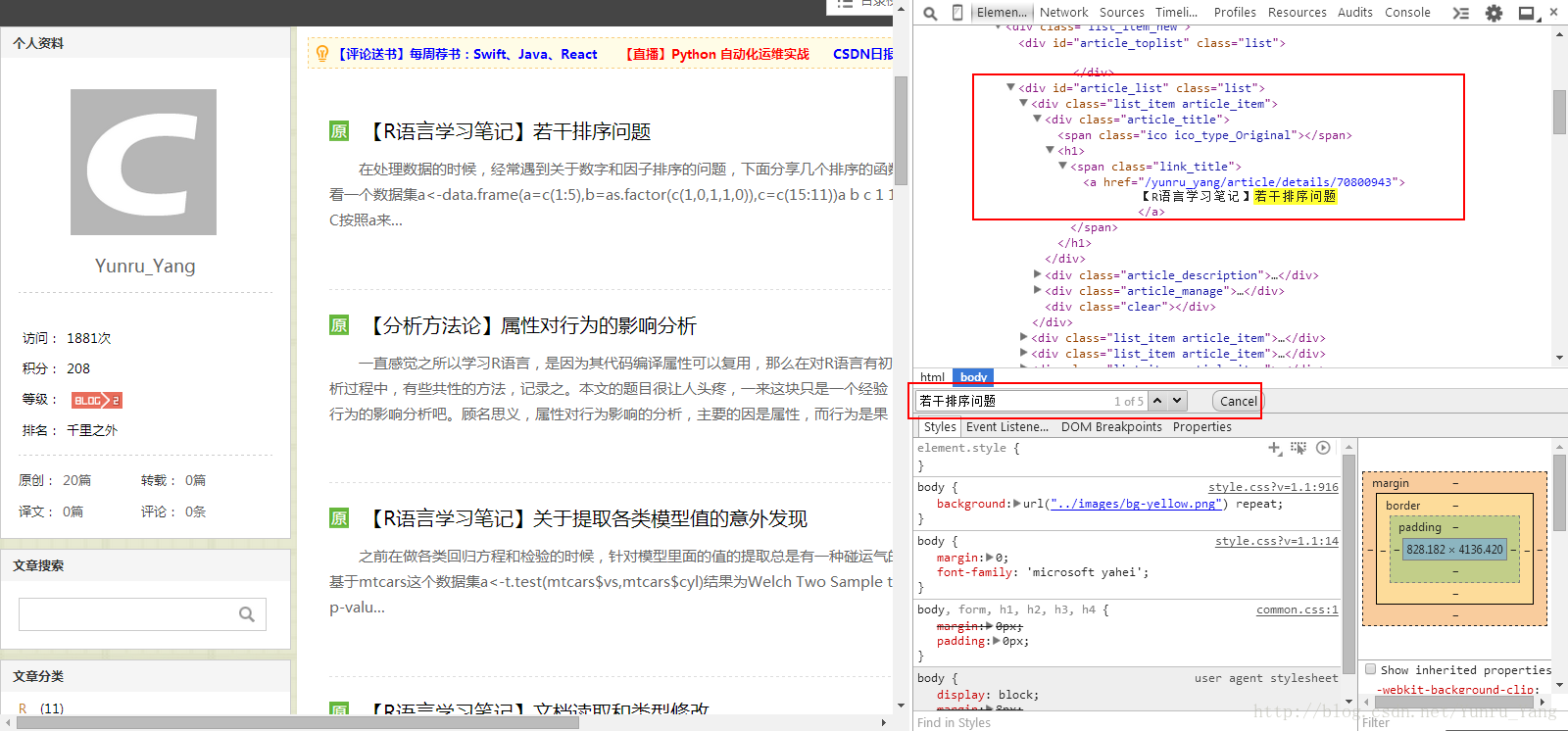
OK,看到我们的路径:比较多
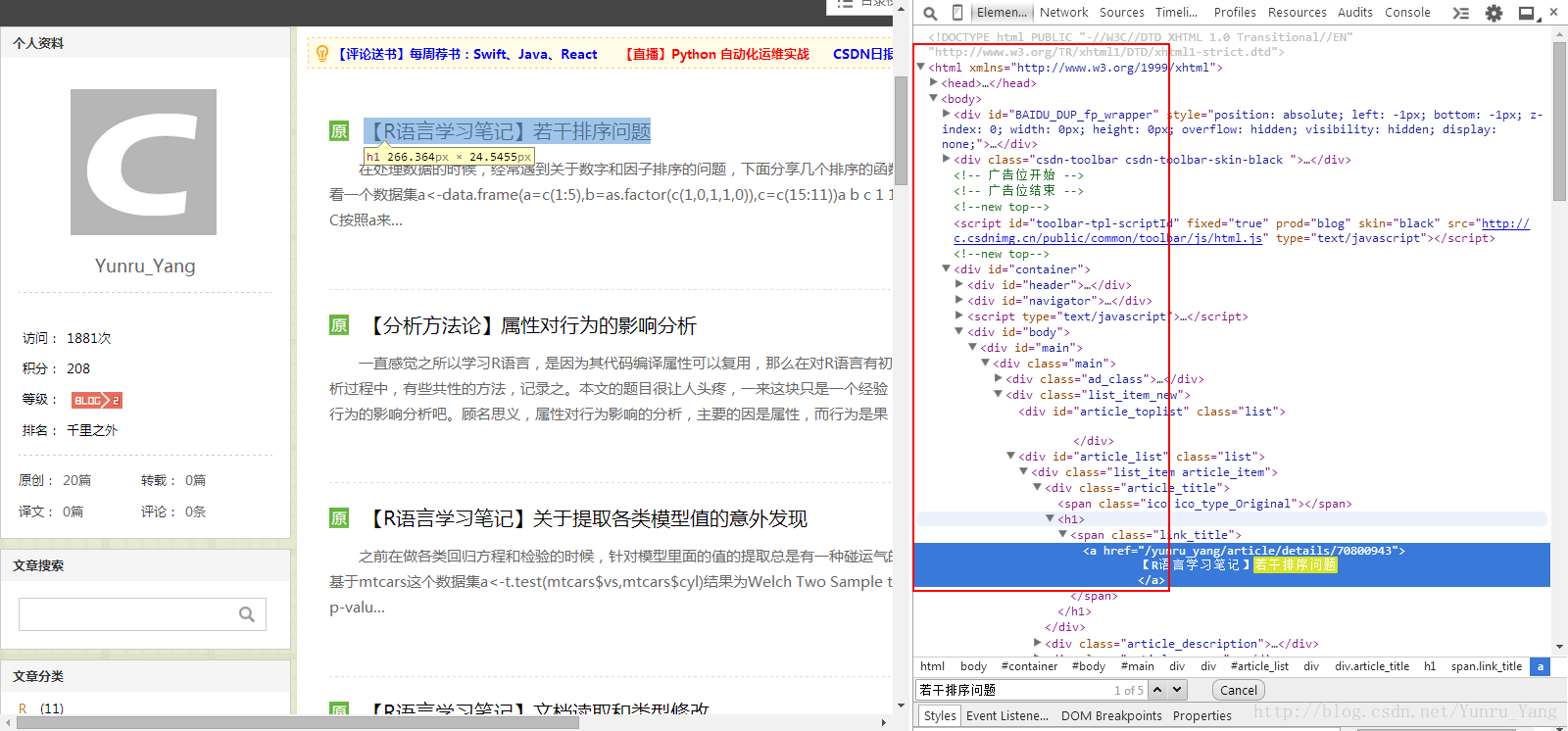
现在我们理解了网页,并往下看,其实原理都一样;整个网页的博客名称显示逻辑是:
<div>的class属性为list_item article_item的段落,下面的内容具体点开看,这个< div>中有三段:
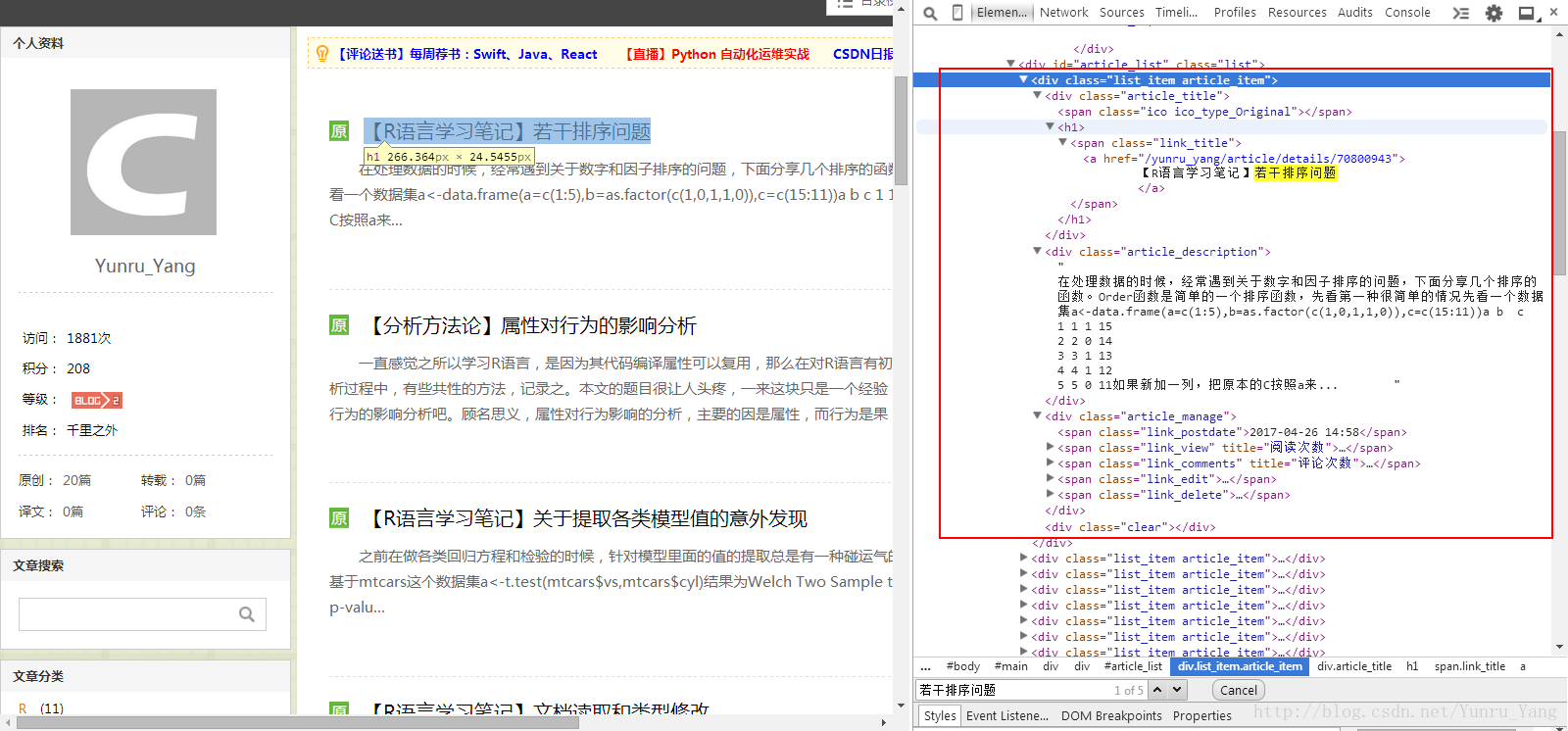
第一段是article_title,对应标题
第二段是article_description,对应摘要
第三段是article_manage,对应其他的阅读数、评论数之类的
下面用xpath进行提取路径,整个需要载入两个包:
library(XML)
library(stringr)然后尝试去提取url:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4736
4736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









