








Hive数据库操作
- 查看数据库列表:
show databases;
hive (default)> show databases;
OK
database_name
default
- 选择数据库:
use 数据库名;
# 查询默认数据库default
hive (default)> use default;
OK
default数据库在HDFS上的目录为/user/hive/warehouse
- 创建数据库:
create database 数据库名;
hive (default)> create database mydb;
OK
- 删除数据库:
drop database 数据库名;
hive (default)> drop database mydb;
OK
【注意】default默认数据库无法删除;写命令的时候注意分号;
Hive表操作
- 创建表:
create table 表名(字段名1 字段类型1,字段名2 字段类型2...);
hive (default)> create table t2;
OK
- 查看表信息:
show tables;
hive (default)> show tables;
OK
tab_name
t1
- 查看表结构信息:
desc 表名;
hive (default)> desc t1;
OK
col_name data_type comment
id int
name string
- 查看表的创建信息:
show create table 表名;
hive (default)> show create table t1;
OK
createtab_stmt
CREATE TABLE `t1`(
`id` int,
`name` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://bigdata01:9000/user/hive/warehouse/t1'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1641880060')
- 修改表名:
alter table 表名 rename to 新的表名;
hive (default)> alter table t1 rename to t_1;
OK
load data local inpath ‘/data/soft/hivedata/t2.data.txt’ into table t2;
- 加载数据:
load data local inpath '数据文件路径' into table 表名;
hive (default)> load data local inpath '/data/soft/hivedata/t2.data.txt' into table t2;
Loading data to table default.t2
OK
Time taken: 1.041 seconds
hive (default)> select * from t2;
OK
t2.id
1
2
3
4
5
- 增加表字段:
alter table 表名 add columns(字段名 字段类型)
hive (default)> alter table t2 add columns(name string);
OK
- 表注释:修改
COLUMNS_V2、TABLE_PARAMS、PARTITION_PARAMS、PARTITION_KEYS表中的编码格式
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改分区表的字符编码格式
mysql>alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
mysql>alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
#注释正常显示
hive (default)> desc t2;
OK
col_name data_type comment
age int 年龄
- 指定列和行分隔符的指定
create table t3_new(
id int comment 'ID',
stu_name string comment 'name',
stu_birthday date comment 'birthday',
online boolean comment 'is online'
)row format delimited
fields terminated by '\t'
lines terminated by '\n';
【注意】lines terminated by '\n';行分隔符可以忽略不写,但是如果要写的话,只能写到最后面!只能写在最后
【注意】针对无法识别的数据显示为NULL
Hive数据类型
基本数据类型
数据类型 开始支持版本 数据类型 开始支持版本
TINYINT ~ TIMESTAMP 0.8.0
SMALLINT ~ DATE 0.12.0
INT/INTEGER ~ STRING ~
BIGINT ~ VARCHAR 0.12.0
FLOAT ~ CHAR 0.13.0
DOUBLE ~ BOOLEAN ~
DECIMAL 0.11.0
复合数据类型
常见复合数据类型:
数据类型 开始支持版本 格式
ARRAY 0.14.0 ARRAY<data_type>
MAP 0.14.0 MAP<primitive_type, data_type>
STRUCT ~ STRUCT<col_name : data_type, ...>
- ARRAY:表示一个数组结构
#测试数据如下:
1 zhangsan swing,sing,coding
2 lisi music,football
#建表格式
hive (default)> create table stu(
> id int,
> name string,
> favors array<string>
> )row format delimited
> fields terminated by '\t'
> collection items terminated by ','
> lines terminated by '\n';
OK
# 向表中加载数据
hive (default)> load data local inpath '/data/soft/hivedata/stu.data' into table stu;
Loading data to table default.stu
OK
Time taken: 1.478 seconds
#查数组中的某一个元素,使用arrayName[index]
hive (default)> select id,name,favors[1] from stu;
OK
id name _c2
1 zhangsan sing
2 lisi football
Time taken: 0.631 seconds, Fetched: 2 row(s)
- MAP:里面存储的是键值对,每一个键值对属于Map集合的一个item
建表语句如下:
1. 指定scores字段类型为map格式
2. 通过collection items terminated by ','指定了map中元素之间的分隔符
3. 通过map keys terminated by ':'指定了key和value之间的分隔符
===================================================================
create table stu2(
id int,
name string,
scores map<string,int>
)row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
#查询格式
hive (default)> select * from stu2;
OK
stu2.id stu2.name stu2.scores
1 zhangsan {" chinese":80,"math":90,"english":100}
2 lisi {" chinese":89,"english":70,"math":88}
hive (default)> select id,name,scores['math'],scores['english'] from stu2;
OK
id name _c2 _c3
1 zhangsan 90 100
2 lisi 88 70
【注意】取数据是根据元素中的key获取的,和map结构中元素的位置没有关系
- Struct:复合类型,类似java中的对象
测试数据如下:
1 zhangsan bj,sh
2 lisi gz,sz
# 建表语句
create table stu3(
id int,
name string,
address struct<home_addr:string,office_addr:string>
)row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
#查询格式
hive (default)> select * from stu3;
OK
stu3.id stu3.name stu3.address
1 zhangsan {"home_addr":"bj","office_addr":"sh"}
2 lisi {"home_addr":"gz","office_addr":"sz"}
Time taken: 0.189 seconds, Fetched: 2 row(s)
hive (default)> select id,name,address.home_addr from stu3;
OK
id name home_addr
1 zhangsan bj
2 lisi gz
Time taken: 0.201 seconds, Fetched: 2 row(s)
Struct与Map的区别
- 个数区别:
- map中可以随意增加
k-v对的个数 - struct中的
k-v个数是固定的
- 类型区别:
- map在建表语句中需要指定
k-v的类型 - struct在建表语句中需要指定
所有的属性名称和类型
- 取值区别:
- map中通过
[]取值 - struct中通过
.取值,类似java中的对象属性引用
- 源数据区别:
- map的源数据中需要带有
k-v - struct的源数据中只需要有
v即可
总体而言还是Map比较灵活,但是会额外占用磁盘空间,因为它比Struct多存储了数据的Key
Struct只需要存储Value,比较节省空间,但是灵活性有限,后期无法动态增加K-V
- 复合数据类型
测试数据如下:
1 zhangsan english,sing,swing chinese:80,math:90,english:100 bj,sh
2 lisi games,coding chinese:89,english:70,math:88 gz,sz
# 建表语句:
create table student (
id int comment 'id',
name string comment 'name',
favors array<string> ,
scores map<string, int>,
address struct<home_addr:string,office_addr:string>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
#加载数据
load data local inpath '/data/soft/hivedata/student.data.txt' into table student;
# 查询数据
hive (default)> select * from student;
OK
student.id student.name student.favors student.scores student.address
1 zhangsan ["english","sing","swing"] {"chinese":80,"math":90,"english":100} {"home_addr":"bj","office_addr":"sh"}
2 lisi ["games","coding"] {"chinese":89,"english":70,"math":88} {"home_addr":"gz","office_addr":"sz"}
Hive表类型
内部表
内部表也可以称为受控表,是Hive中的默认表类型,表数据默认存储在 warehouse目录中。
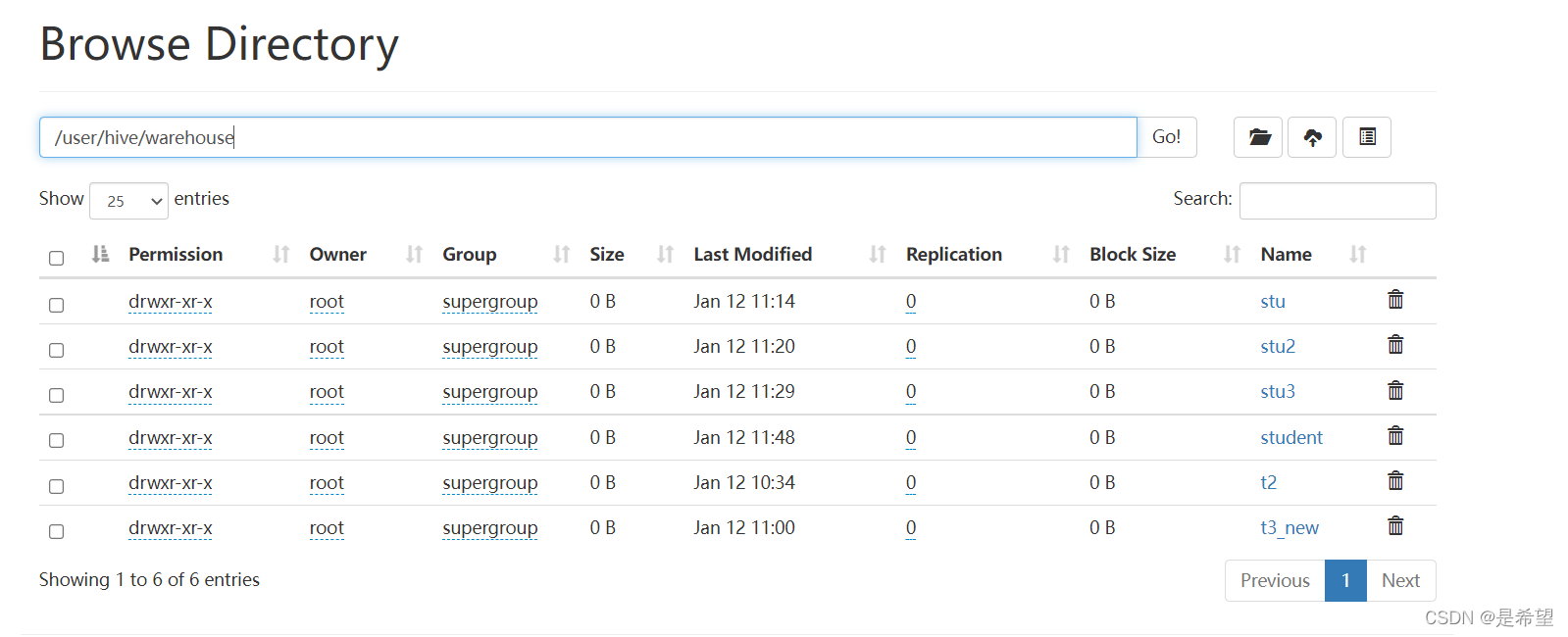
内部表的特性:
创建一张表,其对应就在MetaStore中存储表的元数据信息,当我们一旦从Hive中删除一张表之后,表中的数据会被删除,在MetaStore中存储的元数据信息也会被删除。
外部表
建表语句中包含 External的表叫外部表,外部表在加载数据的时候,实际数据并不会移动到warehouse目录中,只是与外部数据建立一个链接(映射关系)。表的定义和数据的生命周期互相不约束,数据只是表对hdfs上的某一个目录的引用而已,当删除表定义的时候,数据依然是存在的。仅删除表和数据之间引用关系,所以这种表是比较安全的。
#创建一个external_table 外部表
create external table external_table (
key string
) location '/data/external';
【注意】location 是HDFS上的路径
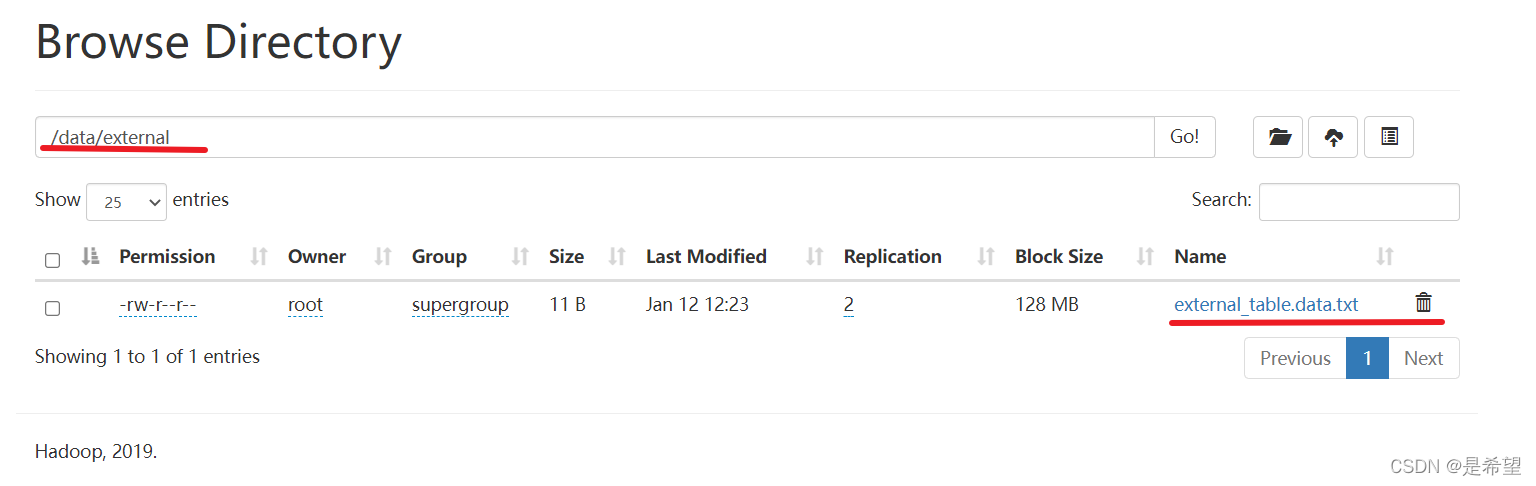
#删除external_table 外部表
hive (default)> drop table external_table;
OK
Time taken: 0.462 seconds
# 查看表列表
hive (default)> show tables;
OK
tab_name
stu
stu2
stu3
student
t2
t3_new
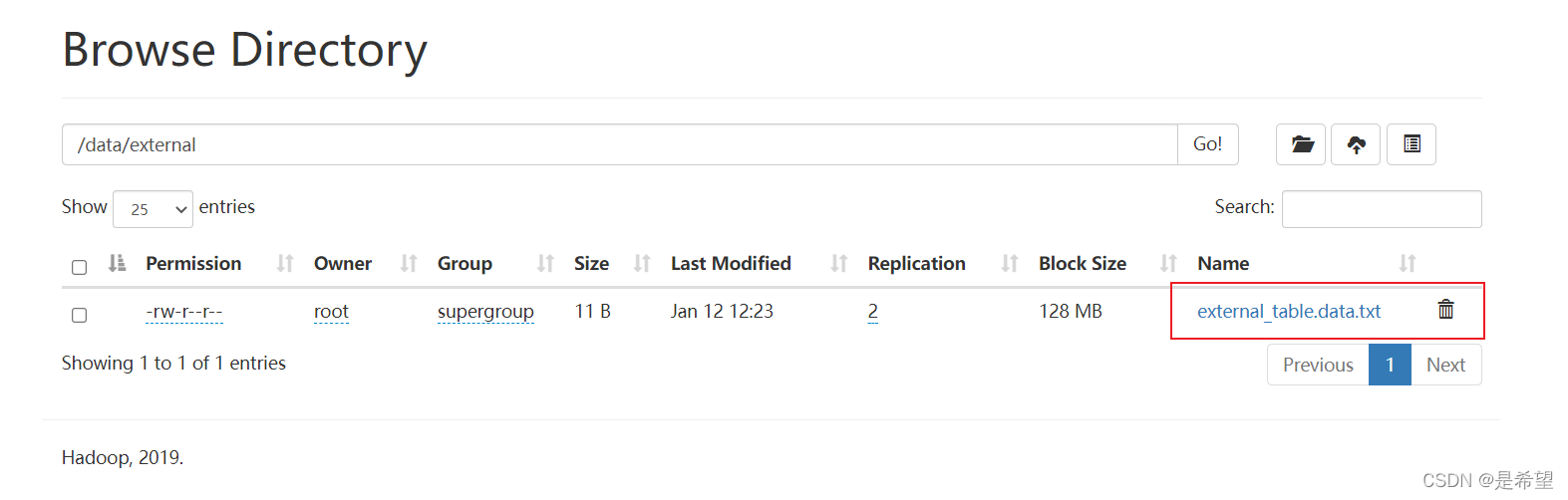
但在HDFS上文件依然存在,这个其实就是外部表的特性,外部表被删除时,只会删除表的元数据,表中的数据不会被删除。
【注意】实际上内外部表是可以互相转化的,需要我们做一下简单的设置即可,里面的EXTERNAL参数必须是大写才能生效。
内部表转外部表
alter table tblName set tblproperties ('EXTERNAL'='true');
外部表转内部表
alter table tblName set tblproperties ('EXTERNAL'='false');
在实际工作中,我们在hive中创建的表95%以上的都是外部表。
大致工作流程如下图所示:
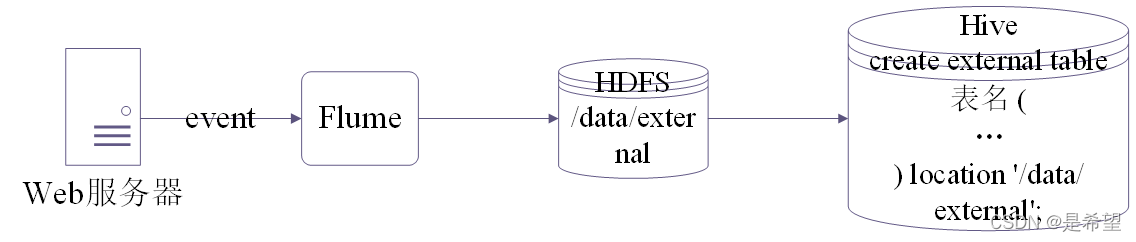
我们先通过Flume采集数据,把数据上传到HDFS中,然后在Hive中创建外部表和HDFS上的数据绑定关系,就可以使用SQL查询数据了,所以连load数据那一步都可以省略了,因为是先有数据,才创建的表。
分区表
分区可以理解为分类,通过分区把不同类型的数据放到不同目录中。
分区表的意义在于优化查询,查询时尽量利用分区字段,如果不使用分区字段,就会全表扫描,最典型的一个场景就是把天作为分区字段,查询的时候指定天。
使用partitioned by指定区分字段
内部分区表
将分区表存放在默认目录下的表属于内部分区表。
# 测试数据
1 zhangsan
2 lisi
3 wangwu
========================
create table partition (
id int,
name string
) partitioned by (year int, school string)
row format delimited
fields terminated by '\t';
#加载数据
hive (default)> load data local inpath '/data/soft/hivedata/partition.data' into table partition_2 partition (year=2020,school='xk');
Loading data to table default.partition_2 partition (year=2020, school=xk)
OK
Time taken: 1.095 seconds
hive (default)> load data local inpath '/data/soft/hivedata/partition.data' into table partition_2 partition (year=2020,school='english');
Loading data to table default.partition_2 partition (year=2020, school=english)
OK
Time taken: 0.599 seconds
hive (default)> load data local inpath '/data/soft/hivedata/partition.data' into table partition_2 partition (year=2019,school='xk');
Loading data to table default.partition_2 partition (year=2019, school=xk)
OK
Time taken: 0.814 seconds
hive (default)> load data local inpath '/data/soft/hivedata/partition.data' into table partition_2 partition (year=2019,school='english');
Loading data to table default.partition_2 partition (year=2019, school=english)
OK
Time taken: 0.687 seconds
【注意】数据文件中只需要有id和name这两个字段的值就可以了,具体year和school这两个分区字段是在加载分区的时候指定的。
查询数据
select * from partition; 【全表扫描,没有用到分区的特性】
select * from partition where year = 2019;【用到了一个分区字段进行过滤】
select * from partition where year = 2019 and school = 'xk';【用到了两个分区字段进行过滤】
外部分区表
与内部分区表相对的是外部分区表,其基本操作如下:
#创建一个外部分区表
create external table ex_par(
id int,
name string
)partitioned by(dt string)
row format delimited
fields terminated by '\t'
location '/data/ex_par';
#加载数据
hive (default)> load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partition (dt='2020-01-01');
Loading data to table default.ex_par partition (dt=2020-01-01)
OK
Time taken: 0.791 seconds
#展示分区
hive (default)> show partitions ex_par;
OK
partition
dt=2020-01-01
Time taken: 0.415 seconds, Fetched: 1 row(s)
#删除分区
hive (default)> alter table ex_par drop partition(dt='2020-01-01');
Dropped the partition dt=2020-01-01
OK
Time taken: 0.608 seconds
hive (default)> show partitions ex_par;
OK
partition
Time taken: 0.229 seconds
针对分区表,通过hdfs的put命令把数据上传上去了,但是却查不到数据,就是因为没有在表中添加分区信息,这时需要绑定关系
hive (default)> alter table ex_par add partition(dt='2020-01-01') location '/data/ex_par/dt=2020-01-01';
OK
Time taken: 0.326 seconds
桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。物理上,每个桶就是表(或分区)里的一个文件。
桶表的应用场景:
举个例子,针对中国的人口,主要集中河南、江苏、山东、广东、四川,其他省份就少的多了,你像西藏就三四百万,海南也挺少的,如果使用分区表,我们把省份作为分区字段,数据会集中在某几个分区,其他分区数据就不会很多,那这样对数据存储以及查询不太友好,在计算的时候会出现数据倾斜的问题,计算效率也不高,我们应该相对均匀的存放数据,从源头上解决,这个时候我们就可以采用分桶的概念,也就是使用桶表
桶表示例:
create table bucket_tb(
id int
) clustered by (id) into 4 buckets;
给桶表加载数据的写法:insert into table … select … from …;
【注意】在插入数据之前需要先设置开启桶操作,不然数据无法分到不同的桶里面
分桶就是设置Reduce任务的数量,因为你分了多少个桶,最终结果就会产生多少个文件,最终结果中文件的数量就和Reduce任务的数量是挂钩的
设置set hive.enforce.bucketing = true可以自动控制Reduce的数量从而适配桶的个数
hive (default)> set hive.enforce.bucketing=true;
# 向桶中加载数据
hive (default)> insert into table bucket_tb select id from b_source where id is not null;
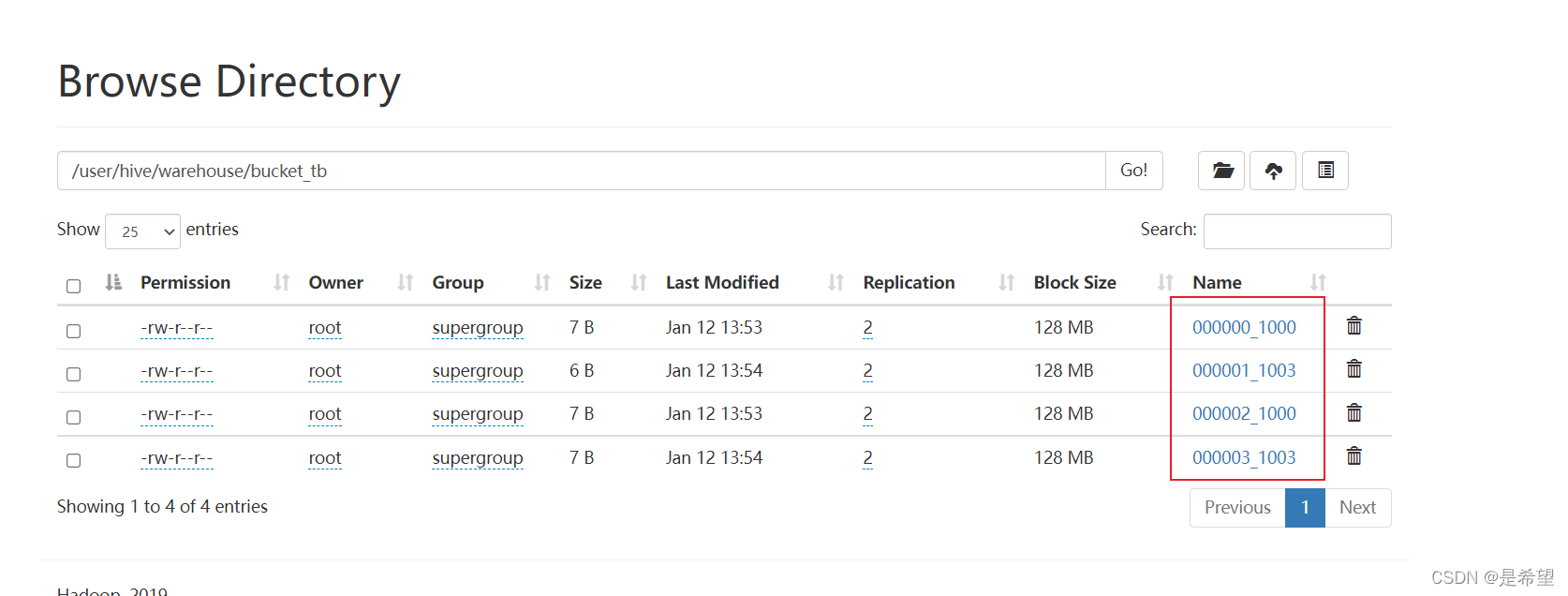
到HDFS上查看桶表中的文件内容,可以看出是通过对Buckets 取模确定的
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /user/hive/warehouse/bucket_tb/000000_1000
12
8
4
桶表的作用:
- 数据抽样
select * from bucket_tb tablesample(bucket 1 out of 4 on id);
语法解析:
TABLESAMPLE(BUCKET x OUT OF y ON column)
y尽可能是桶表的bucket数的倍数或者因子,而且y必须要大于等于x
y表示是把桶表中的数据随机分为多少桶
x表示取出第几桶的数据
例如:
bucket 1 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第1桶的数据
bucket 2 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第2桶的数据
bucket 3 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第3桶的数据
bucket 4 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第4桶的数据
【注意】tablesample抽样可以针对所有表,但是针对桶表抽样效率会更高。
- 提高某些查询效率
桶表在使用分桶字段在join的时候,因为桶表join时计算的数据量比普通表小,所以可以进一步提升效率
视图
- 创建视图:
create view 视图名 as select 表名.字段名1,表名.字段名2 from 表名
hive (default)> create view v1 as select t3_new.id,t3_new.stu_name from t3_new;
OK
id stu_name
Time taken: 0.3 seconds
- 查看视图:
select 字段名 from 视图名
hive (default)> select * from v1;
OK
v1.id v1.stu_name
1 张三
2 李四
3 王五
参考文献
慕课网 https://www.imooc.com/wiki/BigData















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











