






 DRAW模型,一种基于RNN的深度生成模型,通过迭代过程生成图像,模仿人类视觉注意力机制,适用于复杂图像构造。本文深入解析DRAW的网络结构、计算拓扑、损失函数与读写操作,展示了其在MNIST、SVHN及CIFAR-10数据集上的卓越表现。
DRAW模型,一种基于RNN的深度生成模型,通过迭代过程生成图像,模仿人类视觉注意力机制,适用于复杂图像构造。本文深入解析DRAW的网络结构、计算拓扑、损失函数与读写操作,展示了其在MNIST、SVHN及CIFAR-10数据集上的卓越表现。
论文解读:《DRAW: A Recurrent Neural Network for Image Generation》
文章地址: http://arxiv.org/abs/1502.04623
github: https://github.com/vivanov879/draw
github(Theano): https://github.com/jbornschein/draw
github(Lasagne): https://github.com/skaae/lasagne-draw
youtube: https://www.youtube.com/watch?v=Zt-7MI9eKEo&hd=1
video: http://pan.baidu.com/s/1gd3W6Fh
1.文章概括:
提出了一种深层生成模型:深度递归注意力写入器(DRAW)(Deep Recurrent Attentive Writer),该模型具有通过重复部分生成而不是通过一次正向传播生成图像来生成单个图像的特性。模仿人眼空间注意力机制的带有视觉偏好性的,可变自动编码框架,其主要功能是用于复杂图像的迭代构造。
2.介绍:
DRAW体系结构近似草图被依次细化(画一个画,首先是把大致的轮廓勾勒出来,再逐步细化里面的物件,然后再逐渐美化),有些场景的部分是独立于其他场景和应用程序创建的(例如桌子上的水杯等物件,是独立存在的)。正如人们回忆场景和绘画一样,都是从一个物体开始,然后相关联性的进行回顾的,因为人的带宽有限,在观察物体的时候,通常每次只能观察一小部分,然后再整合到一起(观察一个屋子里有什么东西,首先映入眼帘的是一个物体,然后再去观察其他的物体,最后进行整合,不可能把所有东西一下子尽收眼底)。在潜在的视觉注意力机制引导下,通过对全图进行扫描,我们最终可以对原始场景进行回忆和重构。
通过一组RNN网络构成的变分自动编码器进行实现:一个编码器网络用来对真实图像进行压缩,同时一个解码器对压缩后图像进行恢复。二者的组合完全是一个端到端的SGD(Stochastic Gradient Descent随机梯度下降)过程,这里的损失函数是一个二进制交叉熵和KL散度。与众不同的是,模型生成的过程不是一次single pass(单程)的方式,而是一种迭代重建的方式,通过修改decoder(解码器)的预测结果来不断地对最终结果进行累计。
补充:
SGD 每次更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,SGD 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。
SGD简单的python实现:
参考:https://zhuanlan.zhihu.com/p/66528612
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
print(X_b)
n_epochs = 10000
t0, t1 = 5, 500 # 超参数
m = 100
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2, 1)
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2*xi.T.dot(xi.dot(theta)-yi)
learning_rate = learning_schedule(epoch*m + i)
theta = theta - learning_rate * gradients
print(theta)
运行结果如下:

3.DRAW网络模型
基本的DRAW模型结构是由一组编码器和解码器网络构成的。编码器是决定了潜在变量空间的分布用来捕捉显著的输入信息;解码器用来接受从编码分布中采样出出来的样本,并使用它们对图像上的自身分布进行条件化。
然而这里有三个关键的不同点:
- 编码器和解码器均为RNN
(1)编码器,解码器henc,hdec的输出沿时间序列方向传播
(2)编码器还在上一时间接收解码器的输出hdec - 生成分布P(x|z1:T)由每次解码器输出hdec总和形成
在VAE中,世代分布是由单个前向传播解码器的输出形成的。 - 注意机制(读,写模块)限制输入区域和生成区域
神经结构图如下所示:
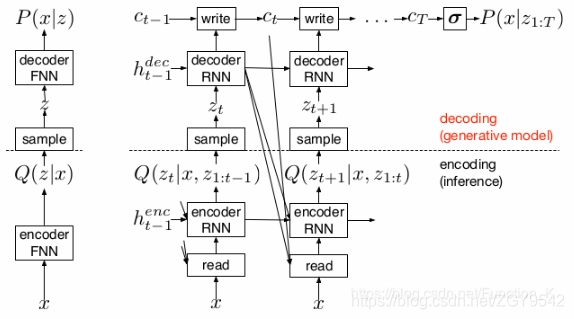
左边是传统的变分自动编码器(Variational Auto-Encoder)流程。输入x进入编码器,同时生成潜在的编码空间后进行Q采样过程得到Q(z|x),并将采样结果作为潜在编码空间z交给解码器,解码器再根据z的条件生成对应的分布P(x|z) 作为自动编码器的输出。
右边是本文提出的网络结构
基本组成部分:输入数据x,read操作,RNN编码器,Q采样,RNN解码器,write操作。
基本过程(以t时刻状态为准):
1.t状态一个batch的输入数据x;上一个t-1状态的编码器输出,以及t-1状态解码器的输出c(t-1);送入t时刻的read;
2.read后将结果送入RNN编码器,同时将t-1状态的编码器输出,上个状态的解码器输出;送入t时刻的RNN编码器;
3.t时刻的编码器输出进行Q采样,该输出为当前时刻的z潜在空间;
4.将隐藏空间的z送入解码器,同时将t-1状态的解码器输出送入解码器RNN;获得t时刻解码器输出;
5.将t时刻的解码输出,和t-1状态的临时结果c(t-1),送入t时刻的write操作,并产生临时结果c(t) 保存在画布矩阵中;
6.循环当前过程进入t+1时间状态,循环到t循环了整个过程,产生最终结果。
3.1网络结构和计算拓扑关系
RNNenct时间的输出是编码器隐藏矢量htenc;解码器RNNdec t的输出是隐藏矢量htdec。用记号b=W(A)来表示从向量a到向量b具有偏差的线性权重矩阵。
潜伏期分布为对角高斯N(Zt|µt,σt)
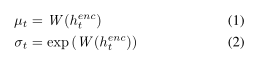
从人类的视觉观察角度考虑,假设人们观察一张图像存在T个状态,那么我们的过程应该循环遍历这T个状态,同时让网络在T个状态中不断获取数据,共享权重信息,来达成我们的预期期望。那么在1…T个时间状态中,共分为以下几个步骤:
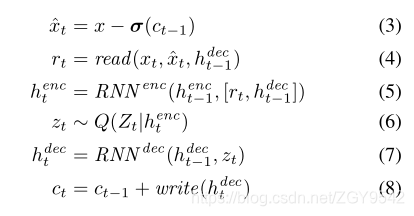
(1)第一步是计算误差图像,通过上一个状态的c(t-1),经过激活函数(这里使用的是sigmoid 函数【目的:Sigmoid函数是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的激活函数,将变量映射到0,1之间。】)后,用原始输入图像减去它,得到error image(带帽的xt);
(2)第二步,就是将当前t时刻状态的输入xt和error image 带帽的xt,以及上一个t-1状态的解码器输出送入read操作,得到的是read后,暂时的结果。
(3)henc的生成受到前一次迭代的henc,hdec和这一次的r的影响(方括号是concate操作)
(4)经过编码得到z,再经过解码得到本次recurrent的输出。
3.2损失函数
损失分为两部分,重构损失和隐层损失。
重构损失描述的是输入x和输出c之间的关系。最终的画布矩阵cT是被用于参数化输入数据的(c是canvas 矩阵,可以认为是一次绘制的结果)。如果输入是二进制的,那么D是伯努利分布(描述的是这次绘制导致x产生的概率),同时它的平均值是cT的sigmoid激活值。那么重构损失Lx是D(x|cT)的负对数概率:
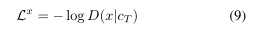
隐层损失描述的是encoding生成的概率Q(z|x)和P(z)之间的相似度,比较概率的相似程度的一个好办法自然是KL散度。将潜在分布序列Q(Zt|htenc)的潜在损失Lz定义为某一潜在先验P(Zt)与Q(Zt|htenc)的Kullback-Leibler散度之和:
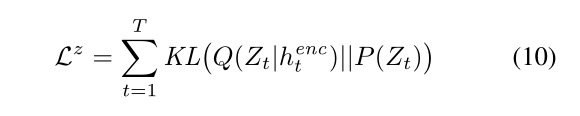
这种损失取决于从Q(Zt|htenc)中提取的潜在样本zt,而潜在样本zt又取决于输入x。如果潜在分布是具有µt的对角高斯分布,如公式1和2中定义的σt,则对于P(Zt)的简单选择是具有平均零和标准偏差一的标准高斯,在这种情况下等式10变成了下列等式(公式推导过程请参考:https://zhuanlan.zhihu.com/p/53271455)
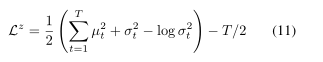
TensorFlow代码为:
latent_loss = 0.5 * tf.reduce_sum(
tf.square(hidden3_sigma) + tf.square(hidden3_mean)
- 1 - tf.log(eps + tf.square(hidden3_sigma)) - 1 - tf.log(eps + tf.square(hidden3_sigma))
)
网络的总网损L是重构网损和潜在网损之和的期望值:
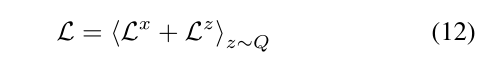
注:对于每个随机梯度下降步骤,使用单个z样本对其进行优化。
3.3随机数据生成
生成图片的过程不是用编码器,仅仅使用解码器(在生成图像的过程中,编码器是在全过程中都没有参与的),方法是每次以概率P(z)抽取一个噪声z,然后送入解码器来更新画布矩阵ct,当循环T次画布矩阵更新完成,那么生成的图像是D(X|_ct)。通过不断送入不同的z最终生成图像。
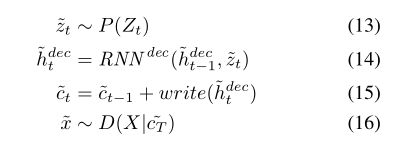
4.读写操作
前面的模型是不完整的,因为没有read和write。本文给出了两种方法:一种是有选择性地注意,另一种是不注意。
4.1不注意read和write
每次都把整个图像作为编码器的输入,同时对整个解码器输出的画布矩阵进行修改。那么这样的话读和写的操作就可以退化为:
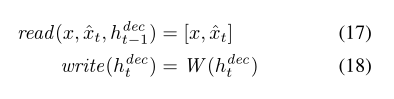
但是该方法不允许编码器在创建潜在分布时仅关注输入的一部分;也不允许解码器仅修改画布向量的一部分,所以称为“非注意力机制”。
4.2选择性注意模型
选择性注意力模型是通过一个2D高斯滤波来实现的,通过将滤波器使用到图像上,可以产生一个图像“补丁”的平滑变化的位置和缩放。
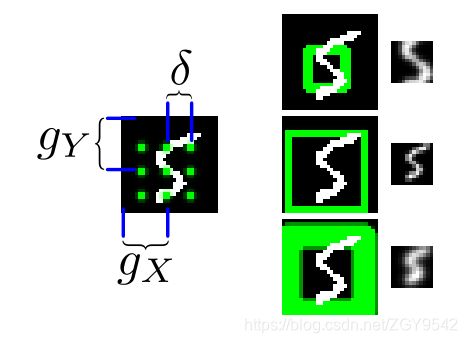
左图:叠加在图像上的3×3滤镜网格。显示了步幅(δ)和中心位置(Gx,Gy)。右图:从图像中提取3个N×N块(N=12)。左侧的绿色矩形表示面片的边界和精度(σ),而面片本身显示在右侧。顶部贴片的δ较小,σ较高,可提供放大但模糊的手指中心视图;中间贴片的δ较大,σ较低,可有效地对整个图像进行下采样;底部贴片的δ和σ较高。
和所展示的一样,NxN的高斯滤波器被放置在图像的具体坐标处,并且使用步长距离来控制滤波器的采样间隔点和缩放距离。这意味着,大的步长会导致图像中更多部分被观测到,但是图像中的有效分辨率则会降低。网格中心坐标(gx, gy)和步长决定了滤波器的平均位置。
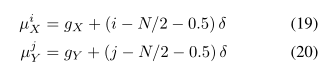
还有两个额外的参数在注意力网络中被需要使用。一个是高斯滤波器带有各向异性的方差参数,一个是标量的强度值gamma用来和滤波器的响应函数相乘。输入图像如果是一个AxB的图像,那么所有五个注意力参数都会被在每个时间步骤处动态决定。这个决定的方式是一种对于解码器输出henc的线性变换。
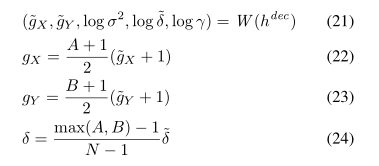
方差、步幅和强度在对数标度中发射以确保正性。选择GX、GY和δ的缩放比例是为了确保初始补丁(具有随机初始化的网络)大致覆盖整个输入图像。
水平和垂直滤波器组矩阵FX和FY(维度分别为N×A和N×B)定义如下:
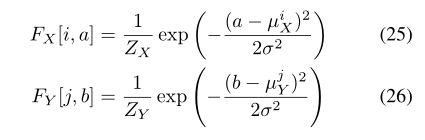
其中i和j参数都是注意力块的一个点,Zx和Zy是规范化常数用来控制总和为1。
4.3读的操作
输入—— Fx,Fy,强度gamma,和一个输入图像及对应的error image。
输出—— 一个拼接图[x, error image]
(详情见代码)
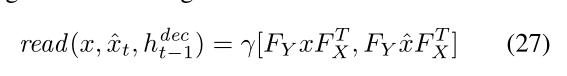
read代码如下:
def filterbank(gx, gy, sigma2,delta, N):
grid_i = tf.reshape(tf.cast(tf.range(N), tf.float32), [1, -1])
mu_x = gx + (grid_i - N / 2 - 0.5) * delta # eq 19
mu_y = gy + (grid_i - N / 2 - 0.5) * delta # eq 20
a = tf.reshape(tf.cast(tf.range(A), tf.float32), [1, 1, -1])
b = tf.reshape(tf.cast(tf.range(B), tf.float32), [1, 1, -1])
mu_x = tf.reshape(mu_x, [-1, N, 1])
mu_y = tf.reshape(mu_y, [-1, N, 1])
sigma2 = tf.reshape(sigma2, [-1, 1, 1])
Fx = tf.exp(-tf.square(a - mu_x) / (2*sigma2))
Fy = tf.exp(-tf.square(b - mu_y) / (2*sigma2)) # batch x N x B
# normalize, sum over A and B dims
Fx=Fx/tf.maximum(tf.reduce_sum(Fx,2,keep_dims=True),eps)
Fy=Fy/tf.maximum(tf.reduce_sum(Fy,2,keep_dims=True),eps)
return Fx,Fy
def attn_window(scope,h_dec,N):
with tf.variable_scope(scope,reuse=DO_SHARE):
params=linear(h_dec,5)
# gx_,gy_,log_sigma2,log_delta,log_gamma=tf.split(1,5,params)
gx_,gy_,log_sigma2,log_delta,log_gamma=tf.split(params,5,1)
gx=(A+1)/2*(gx_+1)
gy=(B+1)/2*(gy_+1)
sigma2=tf.exp(log_sigma2)
delta=(max(A,B)-1)/(N-1)*tf.exp(log_delta) # batch x N
return filterbank(gx,gy,sigma2,delta,N)+(tf.exp(log_gamma),)
## READ ##
def read_no_attn(x,x_hat,h_dec_prev):
return tf.concat([x,x_hat], 1)
def read_attn(x,x_hat,h_dec_prev):
Fx,Fy,gamma=attn_window("read",h_dec_prev,read_n)
def filter_img(img,Fx,Fy,gamma,N):
Fxt=tf.transpose(Fx,perm=[0,2,1])
img=tf.reshape(img,[-1,B,A])
glimpse=tf.matmul(Fy,tf.matmul(img,Fxt))
glimpse=tf.reshape(glimpse,[-1,N*N])
return glimpse*tf.reshape(gamma,[-1,1])
x=filter_img(x,Fx,Fy,gamma,read_n) # batch x (read_n*read_n)
x_hat=filter_img(x_hat,Fx,Fy,gamma,read_n)
return tf.concat([x,x_hat], 1) # 沿特征轴连接
read = read_attn if FLAGS.read_attn else read_no_attn
4.4写的操作
Attention机制的参数是根据 ht dec计算的,并且处理过程与Read模块的顺序相反。wt是生成的图像补丁。ht dec它是从计算得出的,用于生成的图像补丁从解码器输出的一组参数gamma‘,Fx’和Fy’被获取到,并以与Read模块相反的顺序进行处理。
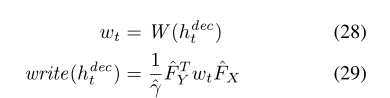
wt是NxN的图像块,从ht时刻的解码器中获取。对于彩色图像来说,每个输入和输出,同时还有read和write的patch都是一个三通道的结果。
write的代码如下:
## WRITER ##
def write_no_attn(h_dec):
with tf.variable_scope("write",reuse=DO_SHARE):
return linear(h_dec,img_size)
def write_attn(h_dec):
with tf.variable_scope("writeW",reuse=DO_SHARE):
w=linear(h_dec,write_size) # batch x (write_n*write_n)
N=write_n
w=tf.reshape(w,[batch_size,N,N])
Fx,Fy,gamma=attn_window("write",h_dec,write_n)
Fyt=tf.transpose(Fy,perm=[0,2,1])
wr=tf.matmul(Fyt,tf.matmul(w,Fx))
wr=tf.reshape(wr,[batch_size,B*A])
#gamma=tf.tile(gamma,[1,B*A])
return wr*tf.reshape(1.0/gamma,[-1,1])
write=write_attn if FLAGS.write_attn else write_no_attn

缩放。左上角:原始100x75图像。中上:用144个二维高斯滤波器提取的12×12个面片。右上角:在面片上应用转置滤镜时重建的图像。底部:仅显示两个二维高斯过滤器。第一个用于生成左上角的面片特征。最后一个过滤器用于生成右下角的面片特征。通过使用不同的过滤器权重,可以将注意力移到不同的位置。
5.实验结果
数据集:MNIST、街景门牌号和CIFAR-10
特别说明:对于MNIST实验,公式9的重建损失是通常的二元交叉熵项。对于SVHN和CIFAR-10实验,红色、绿色和蓝色像素强度被表示为0到1之间的数字,然后这些数字被解释为独立的颜色发射概率。
表3列出了所有实验的网络超参数

MNIST和SVHN的生成序列示例见:https://www.
youtube.com/watch?v=Zt-7MI9eKEo
5.1杂乱的MNIST分类
在杂乱的MNIST中,每幅图像都包含许多视觉杂波的数字状片段,网络必须将其与待分类的真实数字区分开来。如图5所示,具有迭代注意力模型允许网络逐步放大图像的相关区域,而忽略其外部的杂乱。

与原始RAM网络相比,测试误差有了显著改善。

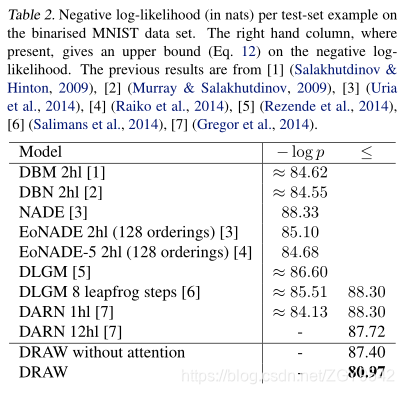
5.2MNIST生成
表2示出了没有选择性注意的绘制与诸如DUN、NADE和DBMS的其它近期生成模型的性能相当,并且注意绘制大大改善了现有技术的状态。
一旦训练了DRAW网络,就可以通过迭代地选择潜在样本并运行解码器以更新画布矩阵来生成图像。在这里,我们可以看到经过训练的DRAW网络生成MNIST数字时图像如何演化:
(红色矩形限定了网络在每个时间步长所关注的区域,焦点精度由矩形边框的宽度表示)

最终生成的数字与原始数字几乎没有区别。

先生成非常模糊的图像,然后再进行细化:
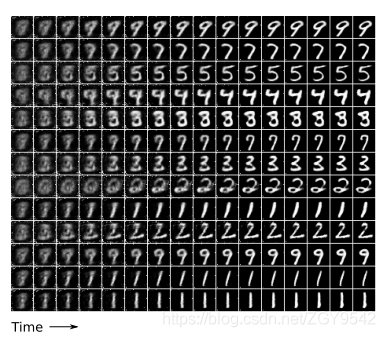
5.3两位数的MNIST生成
训练DRAW生成带有两个随机选择的28×28 MNIST图像的图像,并将其放置在60×60黑色背景中的随机位置。在两个数字重叠的情况下,在每个点将像素强度相加在一起,并将其裁剪为不大于1。生成数据的示例如图8所示。网络通常生成一个数字,然后生成另一个数字,这表明有能力从简单的片断重建合成场景。
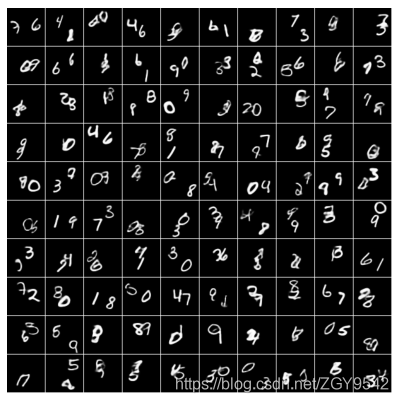
5.4街景门牌编号生成
使用与(GoodFloor等人,2013年)相同的预处理,为每个训练示例产生64x64门牌图像。然后使用从预处理图像中随机位置提取的54×54块来训练网络。
最右边的一列显示了与它们旁边的生成图像最接近的训练图像,这两列在视觉上相似,但数字通常不同。

红色矩形表示注意补丁。网络如何一次绘制一个数字,以及如何移动和缩放书写补丁以生成具有不同斜率和大小的数字。

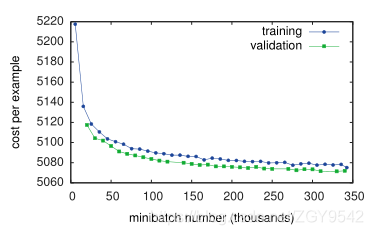
验证成本始终较低,因为验证集补丁是从图像中心提取的(而不是像在训练集中那样从随机位置提取的)。
5.5生成CIFAR图像
绘制能够捕捉到真实照片的大部分形状、颜色和构图(最右侧的列显示了与其旁边的列最近的训练示例)。

6.结论
在本文中,我们提出了一种称为DRAW的方法,该方法通过迭代处理生成图像。
由于DRAW方法的新颖性和实用性,
(1)将RNN用于编码器和解码器以实现迭代图像生成;
(2)通过使用不同的注意力机制,可以生成部分图像;
此外,我们已经证明,通过MNIST和SVHM中的验证实验,DRAW可以比现有方法生成更逼真的图像。
自我总结
read和write掌握的不是很到位,还需要仔细研究代码才能搞懂。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









