







28篇图像填充/Inpainting相关论文
1 CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction ICCV2021
吐槽DeepFillv2 with CA layer,由于缺乏对缺失区域与已知区域之间对应关系的监督信号,可能无法找到合适的参考特征,这往往会导致结果中的伪影。
一种新的可学习的、辅助的上下文重建分支/损失(CR损失),以鼓励生成网络借用适当的已知区域作为填充缺失区域的参考。一种高效、鲁棒的无注意力的 Inpaint生成器,将传统的 Inpaint损害函数和辅助上下文重建损失联合训练,同时在推理时候速度高效。
大量的实验表明,CR损失的有效性和良好的性能比最先进的方法。

2 LAMA:Resolution-robust Large Mask Inpainting with Fourier Convolutions WACV2022
关键词:高感受野感知能力损失函数,快速傅里叶卷积,大掩模
Inpainting一直与复杂的几何结构和高分辨率的图像作斗争,我们发现,其中一个主要的原因缺乏一个有效的感受野。因此考虑使用具有大感受野的快速傅里叶卷积。它将有助于更好的感知loss和大掩模。采用分割网络进行权重初始化效果有提升。

当涉及到强烈的视角扭曲时,LaMa通常会苦苦挣扎(见补充材料)。 transformer 值得期待
3 ZITS:Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding CVPR2022
通过transfomer和草图来提升Inpainting,转换transfomer的作用点
由于卷积神经网络(CNNs)的接受域有限,一些特定的方法只处理规则的纹理,而失去了整体结构,基于注意力的模型可以学习结构恢复的长期依赖性,但它们受到大图像尺寸推断的大量计算的限制。为了解决这些问题,我们建议利用一个额外的结构恢复器来促进图像的逐渐绘制。
1 我们建议使用一个transfomer来学习一个归一化的灰度草图张量空间的内绘制任务。这种基于注意力的模型可以学习到更好的具有长期依赖性的整体结构
2 辅助信息可以在不需要再训练的情况下逐步合并到预先训练过的内Inpainting模型中。
3 提出了一种新的掩蔽位置编码方法,以改进不同掩蔽模型的泛化化。

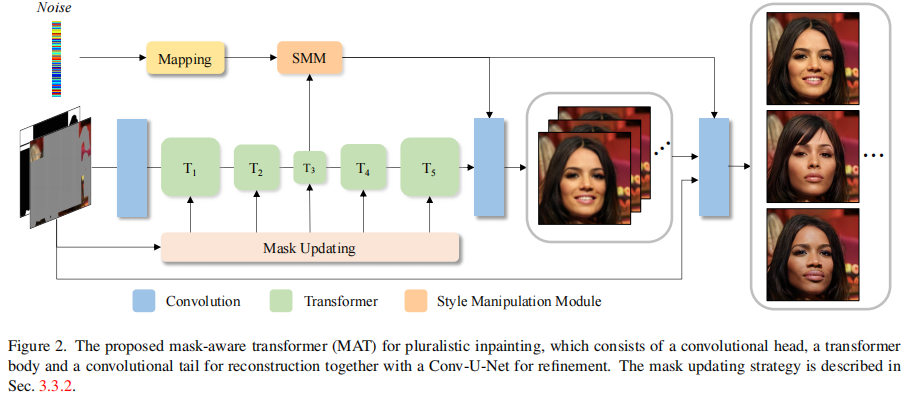
4 MAT: Mask-Aware Transformer for Large Hole Image Inpainting cvpr2022
关键字:Transformer 和 大掩模 + 高分辨率图像
最近的研究表明,在内部Inpainting问题中建模长期相互作用的重要性。为了实现这一目标,现有的方法可以利用独立的注意力技术或Transformer,但考虑到计算成本,通常分辨率较低。本文提出了一种新的基于Transformer的大孔 Inpainting模型,该模型结合了变压器和卷积的优点,可以有效地处理高分辨率图像。
1 我们开发了一种新的内Inpainting框架MAT。它是第一个能够直接处理高分辨率图像的基于Transformer的内部Inpainting系统。
2 我们精心设计了MAT的组件。所提出的多头上下文注意通过利用有效的令牌,有效地进行了随机依赖建模。我们还提出了一种改进的变压器块,使训练大掩模更稳定。此外,我们还设计了一个新的风格操作模块来提高多样性。
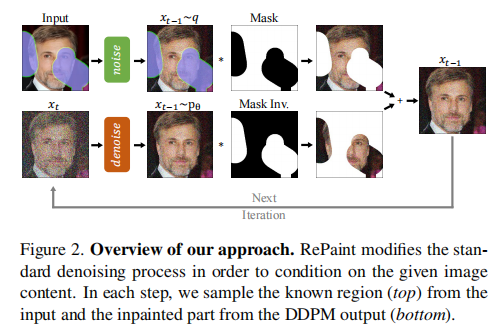
4 RePaint: Inpainting using Denoising Diffusion Probabilistic Models CVPR_2022 1.7k stars
关键词:原始DDPM
我们使用一个预训练的无条件DDPM作为生成先验,我们利用无条件DDPM和反向扩散过程本身的条件。它允许我们的方法毫不费力地推广到任何掩模形状的自由形式的绘画。此外,我们提出了一个反向过程的采样方案,这大大提高了图像质量
5 LDMS: High-Resolution Image Synthesis with Latent Diffusion Models
隐编码:VAE+扩散模型
为了能够在有限的计算资源上进行DM训练,同时保持其质量和灵活性,我们将其应用于强大的预训练自动编码器的潜在空间中。我们在多个任务(无条件图像合成、内绘制、随机超分辨率)和数据集上实现了具有竞争力的性能,同时显著降低了计算成本。与基于像素的扩散方法相比,我们也显著降低了推理成本。

6 Imagen Editor and EditBench: Advancing and EvaluatingText-Guided Image Inpainting CVPR2023 Google Research
他们对预先训练过的T2I模型进行微调,使用随机掩模作为初始绘制掩模,使用图像标题作为文本提示。尽管有一些很好的结果,但这些模型经常出现文本错位,并且无法合成与文本提示对齐的对象,然而,这些模型倾向于假设在缺失的区域中总是有对象,从而失去了执行上下文感知的图像内画的能力。
贡献:EditBench,一个针对文本引导图像内绘制的手动策划的评估基准,它可以评估细粒度的细节,如对象属性组合,我们发现Imagen编辑器在人工评估和自动指标上都优于DALL-E 2和稳定扩散。

7 Smartbrush: Text and shape guided object inpainting with diffusion model. CVPR2023
关键词:文本和形状引导,优化背景保护、优化合成与文本提示对齐
文本提示可以用来描述具有更丰富属性的对象,掩模可以用来约束嵌入对象的形状,而不是只被认为是一个缺失的区域。我们提出了一种新的基于扩散的模型,名为Smartbrush,用于使用文本和形状指导来完成一个对象的缺失区域。
1 介绍了一种以不同精度的对象掩模为条件的文本和形状引导对象喷漆扩散模型,实现了一种新的对象inpainting控制水平.
2 为了使用粗输入掩模保留图像背景,训练模型在初始绘制过程中预测前景对象掩模,以保留合成对象周围的原始背景。(优化背景保护)
3 我们不是使用描述整个图像的随机掩码和文本标题来训练,而是使用实例分割掩码,并使用已绘制区域的局部文本描述来训练我们的模型。(优化合成与文本提示对齐)
4 我们提出了一种多任务训练策略,通过联合训练对象与文本到图像生成来利用更多的训练数据

这些模型倾向于假设在缺失的区域中总是有对象,从而失去了执行上下文感知的图像内画的能力。
8 Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model CVPR2023
多模态引导图像消除+ few-shot(不需要特定的数据集)+背景优化
文本到图像去噪扩散概率模型(DDPMs)已显示出令人印象深刻的图像生成能力,并成功应用于图像绘制。然而,在实践中,用户通常需要对内画过程进行更多的控制,而不是文本指导,特别是当他们想要使用定制的外观、颜色、形状和布局来组合对象时。不幸的是,现有的基于扩散的内部绘制方法仅限于单模态指导,需要特定任务的训练,阻碍了其跨模态的可伸缩性。为了解决这些限制,我们提出了Uni-paint,一个统一的多模态绘画框架,提供了各种指导模式,包括无条件的、文本驱动、笔画驱动、范例驱动的绘画,以及这些模式的组合。
我们的方法是基于预先训练的稳定扩散,不需要在特定的数据集上进行特定任务的训练,使定制图像的少镜头推广。我们在带有零条件反射的单个图像上引入了少镜头掩蔽微调,使失画可扩展到其他模式,并可推广到定制的图像输入。
我们引入了一种隐蔽的注意机制,以减轻潜在的泄漏到已知区域

支持无条件输入
9 HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models 25 Dec 2023
关键字:解决文本和图像匹配问题(text-alignment),高分辨率问题
文本引导图像内绘制的最近进展,导致了异常现实和视觉上可信的结果。然而,在当前的文本到图像的绘制模型中仍然有显著的改进潜力,特别是在更好地将绘制区域与用户提示对齐和执行高分辨率的绘制方面。
1 我们引入了提示感知引入注意(PAIntA)层,以缓解文本引导图像绘制中背景和附近物体干扰问题,倾向文本;
2 为了进一步改进生成的文本对齐,我们提出了重加权注意评分指导(RASG)策略,该策略能够在执行事后引导抽样时防止分布外转移

10 Inst-Inpaint: Instructing to Remove Objects with Diffusion Models 2023年8月9日
舍弃了MASK输入,只输入文字,构建了一个文本-图像对数据集GQA dataset
以LDM为基础架构来训练我们的模型,它在潜在空间中应用扩散步骤,而不是像素空间本身。然而,在复杂的数据集中,如GQA-Inpaint,一些具有复杂模式的场景,特别是文本,根据给定的指令成功地找到并删除了目标对象,但是重建效果很差。
基于Detectron2 and Detic、CascadePSP获取mask
基于CRFill 获取 inpaint结果,由于其计算效率和高质量的结果


11 Blended Latent Diffusion 30 Apr 2023
基于LLM优化扩散模型速度
扩散模型的一个主要缺点是其推断时间相对较慢。在本文中,我们提出了一个加速解决方案的任务的本地文本驱动编辑的通用图像,其中所需的编辑仅限于一个用户提供的掩码。我们的解决方案利用了一个文本到图像的潜在扩散模型(LDM),它通过在一个低维的潜在空间中操作来加速扩散,并消除了在每个扩散步骤中对资源密集型的CLIP梯度计算的需要。我们首先使LDM通过混合每个步骤的延迟来执行局部图像编辑,类似于混合扩散。

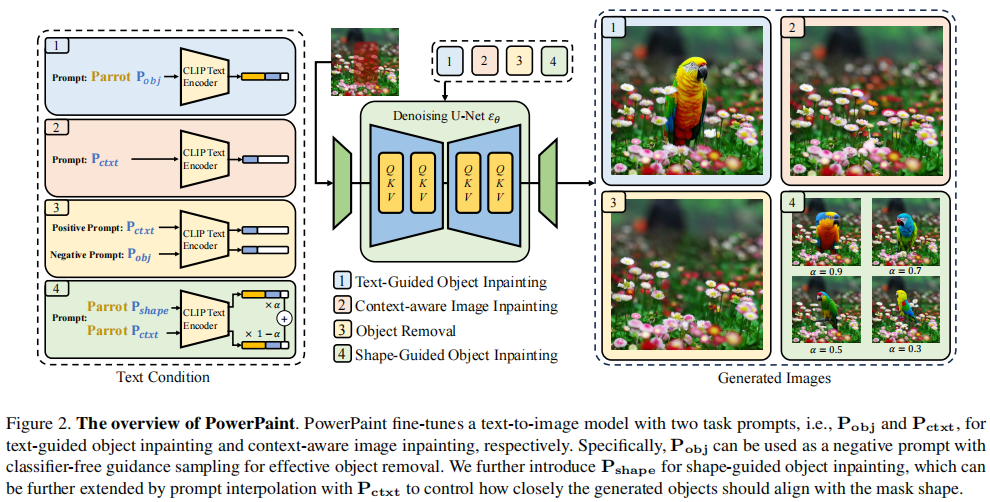
12 PowerPaint :A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
清华&上海AI人工智能实验室
主要解决的问题:如何准确地进行条件控制&填充内容是参考上下文内容还是参考基于条件生成的内容?
实现高质量的通用图像修复,其中用户指定的区域根据用户意图填充合理的内容,提出了一个重大的挑战。现有的方法面临的困难,同时解决上下文感知图像修复和文本引导的对象修复由于不同的最佳训练策略所需的。为了克服这一挑战,我们推出了PowerPaint,这是第一个高质量和多功能的修复模型,在这两项任务中都表现出色。首先,我们引入了可学习的任务提示以及量身定制的微调策略,以明确地引导模型专注于不同的修复目标。这使PowerPaint能够通过使用不同的任务提示来完成各种修复任务,从而实现最先进的性能。其次,我们展示了PowerPaint中的任务提示的多功能性,通过展示其作为对象删除的负提示的有效性。此外,我们利用提示插值技术,使可控的形状引导对象修复。最后,我们在各种修复基准上对PowerPaint进行了广泛的评估,以证明其在多功能图像修复方面的卓越性能。
之前的方法仍然容易产生与图像上下文缺乏一致性的随机伪影,为了解决上述限制,我们提出了PowerPaint,这是第一个高质量的通用图像绘制模型,既支持文本引导的对象图像绘制,也支持上下文感知的图像绘制。在单个模型中实现不同的绘制目标的关键在于利用不同的可学习任务提示和定制的微调策略。
通过这样的训练,Pobj能够提示PowerPaint基于文本描述合成新的对象,而使用Pctxt可以根据图像上下文填充连贯的结果,而没有任何额外的文本提示。通过利用这种采样策略,将Pctxt指定为正提示,将Pobj指定为负提示,PowerPaint可以有效防止该区域内对象的生成,显著提高对象去除[25]的成功率。
之前的模型能够用与图像上下文相一致的内容来填充该区域。然而,这些方法不能从图像上下文中推断出新的对象,也不能合成新的内容。
SD 尽管有一些很好的结果,但这些模型经常出现文本错位,并且无法合成与文本提示对齐的对象。智能刷和图像编辑器提出通过使用配对的对象描述数据来训练[31,32]来解决这个问题。然而,这些模型倾向于假设在缺失的区域中总是有对象,从而失去了执行上下文感知的图像内画的能力。.Smartbrush and Imagen Editor不进行消除,而是在指定的mask区域生成目标,且失去了执行上下文感知图像内绘制的能力。
通过学习对不同任务的不同任务提示,context-aware image inpainting and text-guided object inpainting.
Adapting Text-to-Image Models:适配文生图模型
我们建议使用特定于任务的提示来指导各种任务的文本到图像模型,而不是特定于对象的提示。通过对文本嵌入和模型参数进行微调,我们在任务提示和期望的输出之间建立了一个健壮的对齐。
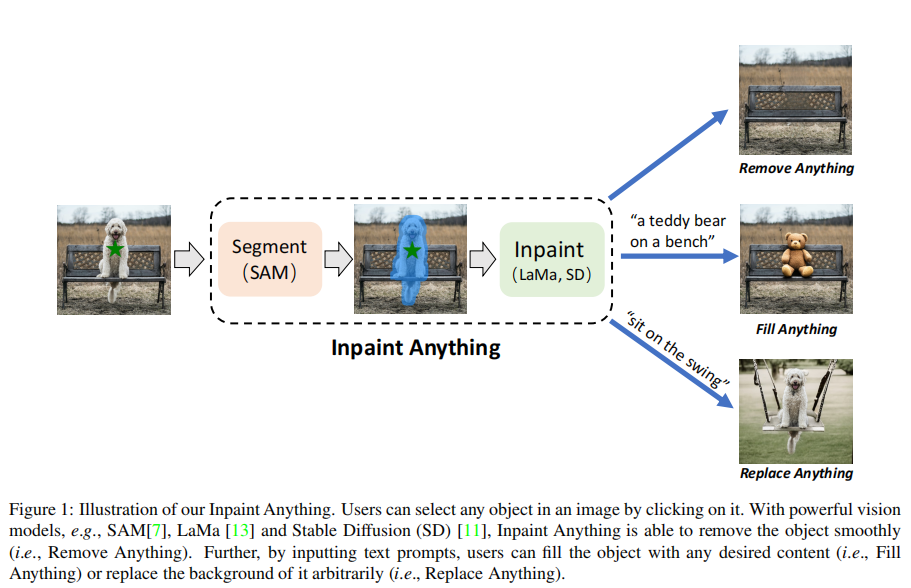
12 Inpaint Anything: Segment Anything Meets Image Inpainting
工程文章,将分割和图像填充相结合
SAM+LaMa/MAT/ZITS
13 DreamBooth: Fine Tuning Text-to-Image Diffusion Models
for Subject-Driven Generation
基于文本图像编辑

13 Deep Learning-based Image and Video Inpainting: A Survey 7 Jan 2024
对于图像中缺失区域的恢复,结果有时并不是唯一的,特别是对于较大的缺失区域。因此,在文献中主要存在两条研究方向:(1)确定性图像绘制和(2)随机图像绘制。给定一个损坏的图像,确定性图像绘制方法只输出一个绘制结果,而随机图像绘制方法可以通过随机采样过程输出多个可信的结果。受多模态学习的启发,一些研究人员最近专注于文本引导的图像输入绘画,通过提供文本提示的额外信息。
根据推理阶段的结果是否唯一可以分为 Deterministic Image Inpainting和Deterministic Image Inpainting
2.1Deterministic Image Inpainting:
从网络结构的角度来看,现有的确定性图像Inpainting通常采用三种框架:单镜头、双阶段和渐进
Single-shot framework:存在着多个研究方向:掩模感知设计、注意机制、多尺度聚合、转换域、编解码器连接和深度先验指导。
目标函数:像素重建损失,感知损失、风格损失、对抗损失、结构损失等
Two-stage framework:Coarse-to-fine methods,tructure-then-texture methods
Progressive frameworks:渐进式方法从边界到孔中心迭代填充孔,缺失面积逐渐变小,直到消
2.2 Stochastic Image Inpainting:
VAE-based methods、GAN-based methods、Flow-based methods、MLM-based methods.Diffusion model-based methods,其中扩散模型主要问题 Sampling strategy design. Computational cost reduction.
2.3 Text-guided Image Inpainting
如何确保图文匹配、如果确保条件生成的内容和图像上下文内容合理填充
14 A Survey on Various Image Inpainting Techniques November 2021
15 A Review of Image Inpainting Methods Based on Deep Learning Received: 29 August 2023
16 NUWA-LIP: Language-guided Image Inpainting with Defect-free VQGAN
关键词:保护非mask区域不受影响+DF-VQGAN
语言引导图像插入画的目的是在文本引导下填充图像的缺陷区域,同时保持非缺陷区域不变。然而,在直接编码缺陷图像的过程中,容易对非缺陷区域产生不利影响,导致非缺陷部分的结构扭曲。为了更好地将文本指导适应于交互任务本文提出了N¨UWA-LIP,其中包括无缺陷VQGAN(DFVQGAN)和多视角序列-序列模块(MP-S2S),该方法引入相对估计来控制接受扩散和对称连接来保留非缺陷区域的信息

17 MI-GAN: A Simple Baseline for Image Inpainting on Mobile Devices
蒸馏、重参数化
我们提出了一个简单的图像绘制基线,移动绘制GAN(MI-GAN),它在计算上比现有的最先进的绘制模型便宜和大约一个数量级,并且可以有效地部署在移动设备上。过度的定量和定性评价表明,MI-GAN的性能比最近最先进的方法相当,或者在某些情况下更好
我们开发了一种适合于我们的模型和问题的定制的知识蒸馏方法,并实现了一种模型再参数化策略,以提高结果的质量。

18 Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning 23 Mar 2023
本文提出了一种新的对抗性图像嵌入训练框架,包括分割混淆对抗性训练(SCAT)和对比性学习。SCAT在嵌入生成器和分割网络之间进行对抗游戏,提供像素级局部训练信号,能够适应具有自由形式孔的图像。通过将SCAT与标准的全局对抗训练相结合,新的对抗训练框架同时表现出以下三个优点: (1)修复后图像的全局一致性,(2)修复后图像的局部精细纹理细节,(3)处理具有自由形式孔的图像的灵活性。此外,我们提出了纹理和语义对比学习损失,通过利用鉴别器的特征表示空间来稳定和改进我们的绘制模型的训练,其中绘制图像被拉离地面真实图像,但被推离损坏的图像。所提出的对比损失可以更好地引导修复后的图像从损坏的图像数据点移动到特征表示中的真实图像数据点

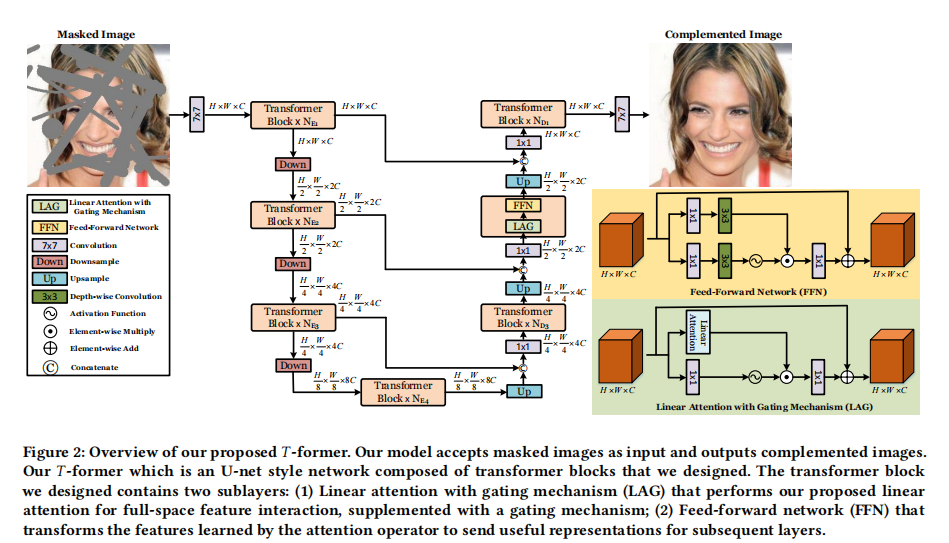
19 T-former: An Efficient Transformer for Image Inpainting 19 May 2023 MM 2022
在本文中,我们设计了一种新的线性相关的注意力。基于这种注意力机制,一个名为𝑇-frost的网络被设计用于图像输入绘画
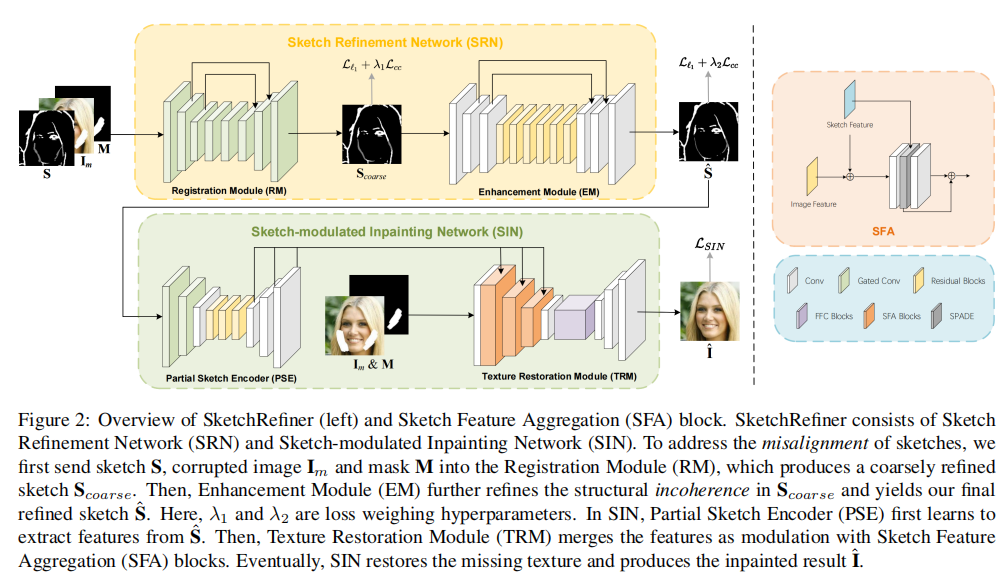
20 Towards Interactive Image Inpainting via Robust Sketch Refinement
2023年6月19日
考虑增加额外输入条件:草图,但是草图容易带来混淆,要解决
图像内画的一个难题是修复被破坏区域的复杂结构。它激发交互式图像绘制,利用额外的提示,例如,草图,以帮助绘制过程。草图对最终用户来说是简单和直观的,但同时也有很多随机性的自由形式。这种随机性可能会混淆内画模型,并在已完成的图像中产生严重的伪影。为了解决这个问题,我们提出了一种两阶段的图像内绘制方法,称为素描精炼器。
21 Asymmetric_VQGAN:Designing a Better Asymmetric VQGAN for StableDiffusion
7 Jun 2023
1 优化扩散模型导致的信息丢失,背景保护
2 显示参考图(先验信息、上下文信息)
统计扩散是一种革命性的文本到图像生成器,它正在图像生成和编辑的世界中引起轰动。与传统的在像素空间中学习扩散模型的方法不同,统计扩散通过VQGAN学习在潜在空间中的扩散模型,保证了效率和质量。它不仅支持图像生成任务,而且还支持对真实图像进行图像编辑,如图像内画和本地编辑。然而,我们观察到,在统计扩散中使用的普通VQGAN会导致显著的信息丢失,即使在未编辑的图像区域也会导致失真伪影。为此,我们提出了一种新的具有两种简单设计的非对称VQGAN。
据我们所知,我们是第一个明确指出和研究基于统计扩散的编辑方法中的失真问题的人。
我们设计了一种新的非对称VQGAN来解决上述失真与两个简单而有效的设计问题。与典型的对称VQGAN设计相比,该新设计可以更好地保留非编辑区域和恢复细节,同时保持较低的训练和推理成本。
我们的非对称VQGAN在两个具有代表性的任务上实现了最先进的性能:在Place数据集[44]上的内嵌绘制任务和在COCOEE数据上的本地编辑任务(即通过示例[40]绘制)
asymmetric VQGAN


22 Blended Diffusion for Text-driven Editing of Natural Images CVPR2022
扩散模型+边缘融合优化
一种基于自然语言描述的局部(基于区域的)编辑的第一个解决方案,以及一个ROI掩码。我们通过利用和结合预先训练的语言图像模型(CLIP)来实现我们的目标,将编辑引导到用户提供的文本提示符,并使用去噪扩散概率模型(DDPM)来生成自然外观的结果。
为了无缝地将编辑区域与图像的不变部分相融合,我们在空间上将输入图像的噪声版本与噪声水平下潜在的局部文本引导扩散进行混合。

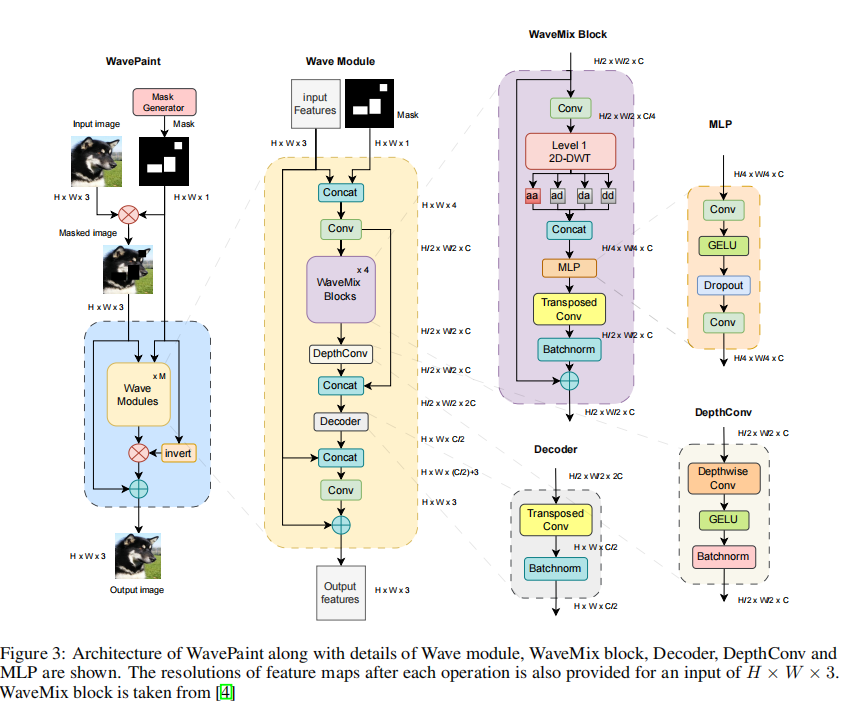
23 WAVEPAINT: RESOURCE-EFFICIENT TOKEN-MIXER FOR SELF-SUPERVISED INPAINTING 1 Jul 2023
基于DWT优化transfomer计算量
目前最先进的图像内画模型在计算上很重,因为它们是基于变压器或CNN骨干,在对抗或扩散设置中进行训练。本文通过使用一种计算效率高的基于波混合的全卷积结构-波图来区分视觉变压器。它使用了一个二维离散小波变换(DWT)来进行空间和多分辨率的标记混合以及卷积层。
24 GEOMETRY OF THE VISUAL CORTEX WITH APPLICATIONS TO IMAGE INPAINTING AND ENHANCEMENT
本研究的目的是介绍一种基于视觉皮层亚黎曼模型的轻量级、有效的鲁棒性、图像内画和图像增强算法。
玄学,看不懂

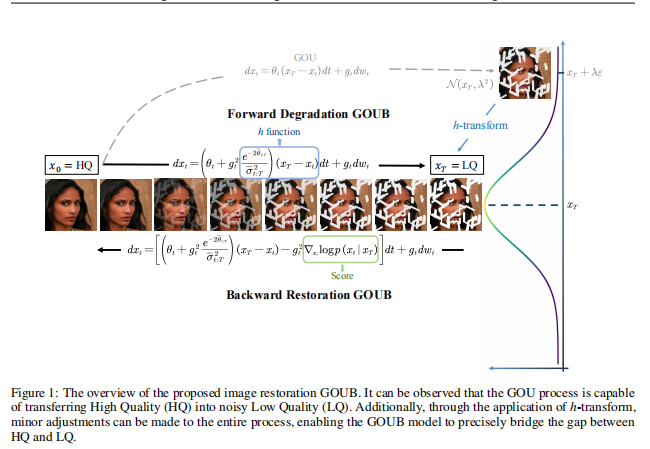
25 IMAGE RESTORATION THROUGH GENERALIZED ORNSTEIN-UHLENBECK BRIDGE
玄学,看不懂
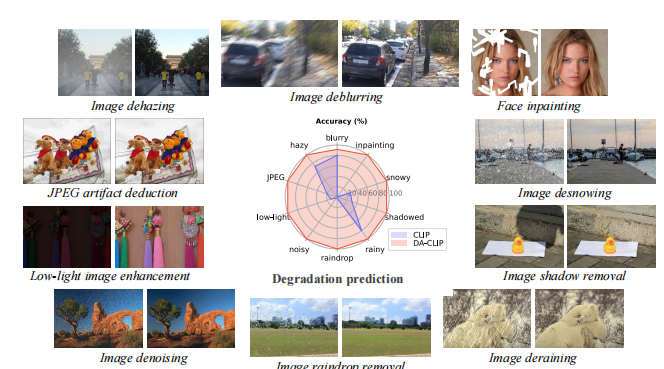
26 CONTROLLING VISION-LANGUAGE MODELS FOR UNIVERSAL IMAGE RESTORATION
把语言模型整到图像修复里面
在本文中,我们提出了一种退化感知的视觉语言模型(DA-CLIP),以更好地将预先训练好的视觉语言模型转移到低级视觉任务中,作为图像恢复的通用框架。更具体地说,DA-CLIP训练了一个额外的控制器,它可以调整固定的CLIP图像编码器来预测高质量的特征嵌入。
27 Free-Form Image Inpainting with Gated Convolution 2019年10月22日
28 Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting CVPR2022
在1080上实时处理2K图像















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









