









测试背景
本次测试背景为对某大型风电厂的机组采集数据进行处理,业务需求如下:
- 将采集到的设备的实时数据存入持久化存储
- 对数值超出上下限的测点进行实时告警
- 计算采集数据不同时间段内的均值,一并存入持久化存储
- 对持久存储中的数据提供类SQL查询
数据格式
- 实时数据为2小时的秒级机组实时数据(4000台机组,约200万点/秒)
- 历史数据为4000台机组两天的秒级机组历史数据(大约1TB),500测点/机组,数据以.csv文件格式提供,一台机组两天一个数据文件。需自行导入表TABLE_X中。
实时数据
接入数据的单台机组的数据格式如下:
| 字段号 | 字段名 | 字段含义 | 样例 |
|---|---|---|---|
| 1 | time | 时间戳 | 2017-04-26 12:25:00 |
| 2 | ID | 风机ID | 130 |
| 3至352 | K1至K350 | 开关量测量点 | 1 |
| 353至502 | TAG1至TAG150 | 模拟量测量点 | 123.4567 |
字段与字段间用“,”分隔,每台机组以“;”结尾,全部字段为字符串格式。实时数据存入表RT_RECORD中。
告警数据
当触发告警后将数据存入告警表中,告警表名称为TAG_EXCEPTION_RECORD,具体数据格式如下:
| 字段号 | 字段名 | 数据类型 | 字段含义 | 样例 |
|---|---|---|---|---|
| 1 | time | 时间戳 | 时间戳 | 2017-04-26 12:25:00 |
| 2 | ID | 整型 | 风机ID | 130 |
| 3至352 | K1至K350 | 浮点型 | 开关量测量点 | 1 |
| 353至502 | TAG1至TAG150 | 浮点型 | 模拟量测量点 | 123.4567 |
| 503 | Cal | 浮点型 | 计算量 | 167.5863 |
分钟均值
对每个TAG点计算每分钟的平均值,将计算结果存入分钟均值表:AVG_MIN_RECORD,具体格式如下:
| 字段号 | 字段名 | 数据类型 | 字段含义 | 样例 |
|---|---|---|---|---|
| 1 | time | 时间戳 | 时间戳 | 2017-04-26 12:25:00 |
| 2 | ID | 整型 | 风机ID | 130 |
| 3至152 | TAG1至TAG150 | 浮点型 | 模拟量测量点分钟平均值 | 123.4567 |
业务数据
业务数据表存放了风场与风机信息,表名为TABLE_R。
| 字段号 | 字段名 | 数据类型 | 字段含义 | 样例 |
|---|---|---|---|---|
| 1 | WFID | 整型 | 风场ID | 12322 |
| 2 | ID | 整型 | 风机ID | 182 |
硬件设施
- 服务器 5 台(1 路 8 核 CPU,32GB 内存,5*1TB SAS 硬盘)。
- 千兆交换机 1 台 24 口、网线若干、水晶头。
测试场景
测试1:流处理及实时报警能力测试
接收两个小时连续的实时数据(从 2017-04-30 12:00:00 至2017-04-30 13:59:59),200 万点/秒,接收后写入表RT_RECORD中。
1. 数据接入能力测试:
以实时数据发完2017-04-30 13:59:59的数据为开始,以所有列(所有TAG点)分钟平均值计算完成为结束。将分钟均值计算结果写入表AVG_MIN_RECORD中。
2. 实时告警能力测试
实时检测风机的各种模拟量,如果风机 TAG1 至 TAG150 列模拟量数据超过设定模拟量阈值,即为异常记录,并触发计算。将告警数据写入表TAG_EXCEPTION_RECORD中。
测试2:数据完整性及查询分析能力测试
此部分数据需要使用历史数据表TABLE_X和业务数据表TABLE_R中的数据。
2.1 数据完整性校验
通过查询验证数据入库的完整性,是否数据缺失或数据不准。使用SQL语句统计TABLE_X表的总条数。
2.2 风机数据查询
查询1:通过SQL或类SQL接口,基于全时间范围的全量风机数据多维度查询。
SELECT TAGx FROM TABLE_X WHERE TAGn>e and ID>m and ID<(m+100)
ORDER BY TAGxx,n,e,m 随机给出。
查询2:通过SQL或类SQL接口,基于全时间范围的全量风机数据多维度聚合查询。
SELECT SUM(Kx),AVG(TAGa),AVG(TAGa+3),AVG(TAGa+5)
FROM TABLE_X
WHERE TAGn>e and ID IN (SELECT ID FROM TABLE_R WHERE WFID=m)
Group by IDx,a,e,m,n 随机给出。
查询3:风机数据和业务数据联合查询
通过 SQL或类SQL接口,基于风机数据表(TABLE_X)和业务
数据(TABLE_R)进行全量查询。
SELECT SUM(TAGx),ID, WFID
FROM TABLE_X
JOIN TABLE_R
ON TABLE_X.ID=TABLE_R.ID
WHERE TAGx>110 and TAGy>77 and TAGz>162 and TAGu<67 and
TAGv<125
GROUP BY ID;u,v,x,y,z 随机给出。
技术选型思路
明确了测试需求以后,需要对业务场景中各个环节进行技术选型。在不同方向的技术选型过程中,有些方向依据以往的经验可以很容易的选出,而另一些则需要经过一些测试,根据测试结果来选择。
由于公司内部的测试环境达不到测试需求中所述硬件的标准,所以按照实际硬件情况对所处理的数据量进行了近似比例的缩小。在持久化存储和SQL查询两节会详细给出的测试所使用的物理资源和数据量。
消息队列
由于实际项目情况下可能存在多个数据源,所以需要使用消息队列对设备采集数据进行汇总。除了进行数据汇总之外,消息队列还可以起到流量削峰的功能,防止一段时间内异常的流量过大导致下游处理程序崩溃。目前常用的消息队列有RabbitMQ、ZeroMQ、ActiveMQ、Kafka等。综合各种考虑,最后选用了Kafka作为数据传输的消息队列,原因如下:
- Kafka是分布式消息队列,最初就是被设计用来大量数据的传输,吞吐率十分优秀
- Kafka中的消息是存储在硬盘上的,不会出现down机数据丢失的情况
- Kafka的读写机制经过特殊优化,读写速度非常快
- Kafka与其他大数据框架结合的API比较成熟
数据处理框架
数据处理框架主要用来对海量数据进行处理。目前的处理框架从处理的数据源不同可以分为两种:批处理框架和流处理框架。批处理框架主要用来对已经存在的海量数据进行离线处理,特点是能处理海量的数据,但是延迟较高,代表为Apache Hadoop。流处理框架主要对系统中新接入的数据进行处理,特点是能处理的数据量没有批处理框架那么大,但是延迟较低,可以实现近实时处理。代表为Apache Storm和Apache Samza。除了纯粹的批处理和流处理框架,还有融合了批处理和流处理功能的混合框架,代表为Apache Spark和Apache Flink。
在本次测试项目中,由于同时要进行流处理(实时告警、分钟级均值)和批处理(小时、日、月均值),所以优先使用混合框架。在两款混合框架中,选定了在企业应用中较为成熟、社区更加活跃的Spark。
持久化存储
不同于消息队列和数据处理框架,持久化存储的选择则存在一些困难。持久化存储的选择的主要考量标准是单位时间内可以接入数据量的大小。由于物理资源的不足,所以对从流处理框架写入到持久化存储这一过程的数据量按照CPU数量进行了近似比例缩小。如下所示:
| 场景 | CPU数量 | 处理设备数量 |
|---|---|---|
| 测试要求 | 40 | 4000 |
| 实际情况 | 6 (1 driver,5 executor) | 500 |
也就是说当数据落入速度达到大概500设备/秒即完成要求。
在对每个持久化存储方案进行了多次测试后,得到了如下的测试结果
| 持久化存储方案 | 每秒写入设备数 |
|---|---|
| HBase | 350 |
| Hive+HDFS | 2600 |
| OpenTSDB | 300 |
| Cassandra | 300 |
最初测试了HBase,但写入速度一直不理想,只能达到350设备/秒左右。于是放弃了数据库存储,转而使用底层存储机制为分布式文件系统的Hive,写入速度得到大幅提升,达到2600设备/秒。后来又测试了OpenTSDB和Cassandra两款数据库,写入速度也都只能达到300设备/秒左右。所以最终持久化存储选定了Hive。
SQL查询
在测试2中需要使用SQL或类SQL对已经存在的历史数据进行查询,而且查询条件比较复杂,所以需要提供可使用SQL进行即席查询的OLAP引擎。我们选定了目前比较流行的三种MPP(Massive Parallel Processing,即海量并行处理)架构的OLAP引擎进行了测试,分别是Apache Hive,Spark SQL,Presto。同样由于物理资源
不足,我们对可处理的数据量进行了近似比例缩小:
| 场景 | CPU数量 | 处理设备数量 |
|---|---|---|
| 测试要求 | 40 | 4000 |
| 实际情况 | 10 | 1000 |
下面是它们的测试结果。
测试2.1,数据完整性校验。分别使用三种引擎对全部数据进行count操作:
SELECT COUNT(*) FROM TABLE_X;下面给出三种引擎的执行时间:
| Hive | Spark SQL | Presto |
|---|---|---|
| 48.5分钟 | 48分钟 | 23秒 |
可以看到Presto在查询速度上的巨大优势。于是放弃了对Hive和Spark SQL的后续测试,用Presto进行后续(测试2)全部测试。
查询1:全量数据多维度查询
SQL语句如下:
SELECT TAG380 FROM TABLE_X WHERE TAG451>999.9994 AND ID > 23 and ID < (23+100) ORDER BY TAG380;测试三次(结果集大小为9):
8秒
6秒
3.98秒
查询2:全量数据多维度聚合查询
SQL语句如下:
SELECT SUM(K200),AVG(TAG400),AVG(t400+3),AVG(t400+5) FROM TABLE_X WHERE TAG451>999.88 AND ID IN (SELECT ID FROM TABLE_R WHERE WFID = ‘3’) GROUP BY ID(11风机):
2分27秒
查询3:风机数据和业务数据联合查询
SELECT SUM(TAG489), TABLE_X.ID FROM TABLE_X JOIN TABLE_R ON TABLE_X.ID=TABLE_R.ID WHERE TAG489>110 AND TAG442>77 AND TAG378>162 AND TAG410<67 AND TAG351<125 GROUP BY TABLE_X.ID测试两次(1000个结果):
3分33秒
3分52秒
可以看到,Presto与Hive和Spark SQL相比,性能有明显优势,并且所有查询结果都可以近实时(一般小于 10分钟可以称为近实时)返回结果。
解决方案
根据以上测试结果,我们提出了使用Apache Kafka、Apache Spark等技术的解决方案,如图所示:
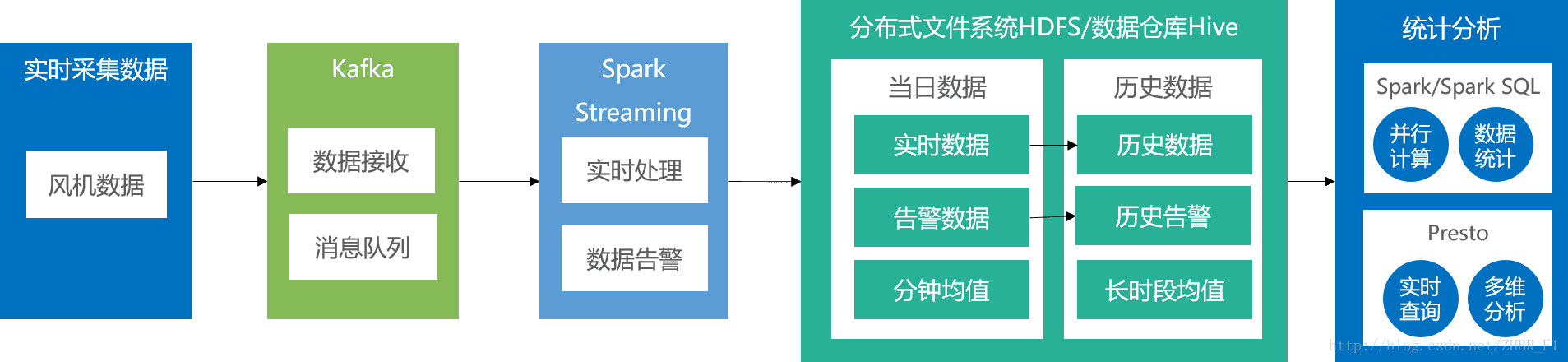
- 数据传输
使用Apache Kafka将实时数据接入到系统中。Kafka将数据写入硬盘,作为后续的计算和存储的数据源 - 实时计算
使用Apache Spark的库Spark Streaming进行实时计算,包括实时告警、分钟级均值和实时数据落地。 - 持久化存储
将实时数据和经过实时计算的告警数据、分钟级均值数据存入Hive表中。落地的Hive表采用无分区+csv格式来提高写入速度。然后定时将无分区+csv格式的Hive表转为按设备分区+parquet格式的Hive表提升查询速度。 - 离线计算
使用Spark Core及Spark SQL对已经存在于Hive表中的数据进行离线计算,包括小时、日、月均值的计算。 - 即席查询
使用Presto为即席查询提供类SQL语义。















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









