







文章目录
0 前言
根据我的实践经验来看,对于有编程基础(如C语言)的人来说,python入门应该很简单,而且加上官方文档做得非常好,所以个人建议python的学习主要去参考官网。本博客主要是记录那些容易忽略的关键点以及对个人对python中一些内容的理解。时时更新!
Python中文官网——多查,熟能生巧:https://docs.python.org/zh-cn/3/index.html
学习一门编程语言,首先要理清编程语言的语法基本架构以及数据结构。
1 python关键字
初学python时,我当时总会有一种感觉,那就是 “python啥都写,但似乎又啥都不能写”。“啥都能写”体现在python是一门动态语言,不需要像C语言那样声明定义变量,语法非常自由;而“啥都不能写”又表现为python虽然自由,但也有它的语法,只要违背,一样会报错。
而关键字我认为就是学习python的第一步。通过关键字了解python的语法,从而体会其设计理念。
找到一个python关键词相关的教程,比较完整,此处就不再赘述。链接
2 内置函数, 内置库, 第三方包
除关键字外,使用python时还需要区分内置函数,内置库以及第三方包。一些常用的库和包可以看看这个链接。
2.1 内置函数
所谓内置函数,就是指即使不导入任何包,也能直接使用的函数,比如print。至于python当中有哪些内置函数,可以直接查看官网链接。
以3.10.8版本的python为例,其所有的内置函数如下图所示。

虽然,使用python给人一种感觉就是只要会“调包”即可,但其实很多功能都能不调包,直接通过内置函数来实现。这里简单总结几个个人觉得在某些情况下特别有用的内置函数:
-
dir
dir函数可以查看某个对象的函数,即可以用.点出来的函数。(虽然其本质是返回__dir__函数的内容)

还可以查看内置函数和内置变量
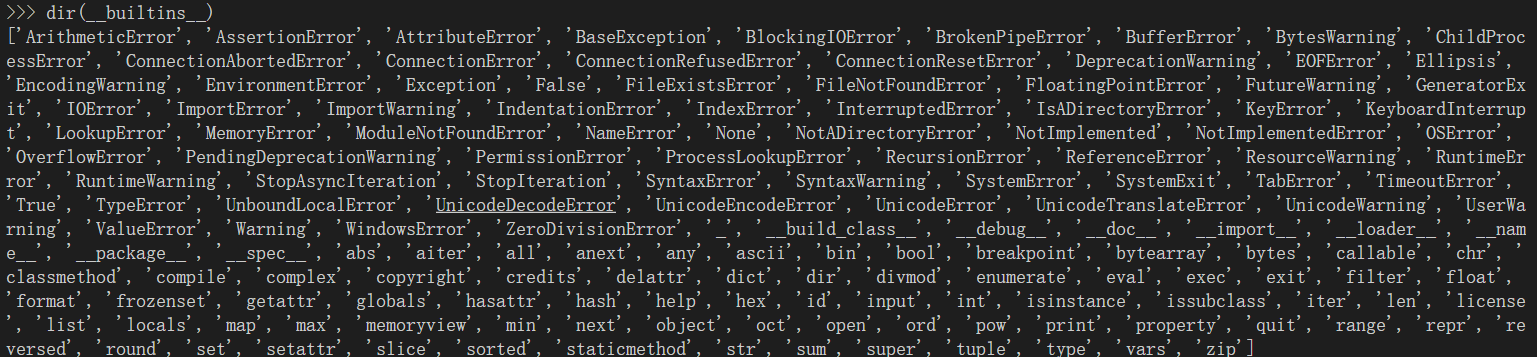
-
enumerate /ɪˈnuməˌreɪt/

除列表外,其实字典也是可以使用enumerate函数的,返回的是序号和key,如果要取其value,还需要加个中括号。如下图所示。

2.2 内置库
所谓内置库,也叫标准库,是指在安装python安装包时就直接给安装到电脑上的一些模块,因此在使用时可以直接import,而不需要使用pip install命令安装。在Windows上会直接安装所有的标准库,而在其他系统可能需要自己选择。具体有哪些标准库及其使用方法建议参考官方文档:
- python标准库官方文档——建议使用网页查找功能
2.3 第三方包
除了内置函数与内置库以外,剩下的都是第三方包了,也就是需要使用pip install安装的库。由于第三方包非常多,因此python官网还提供了一个查询索引网站,里面有对第三方包的介绍及其官网链接。注意区分名字。
以pandas为例:

3 python中的数据结构
python中常用的数据结构就是list(列表),tuple(元组),dict(字典),set(集合),str(字符串)等这些,很多第三方的包新构建的数据结构都是基于这些数据结构设计的,不过在功能上可能更丰富。
这些数据结构使用较为简单,这里不再赘述,熟能生巧。
使用过程中的一些问题总结
-
如何对字典进行排序?利用内置函数
sorted,可以根据函数的参数提示来进行设定参数。 参考链接 -
list数据结构支不支持reshape操作?不支持,只能转换为numpy格式才能使用reshape函数
-
字符串前面加b,u,r的含义?参考链接
b"":表示后续字符串为byte类型u"":表示后续字符串编码格式为utf-8r"":表示非转义字符串
-
判断字符串是否只含空白字符:
isspace()注意区分“空字符串”和“只包含空白字符的字符串”

-
如何print带引号的字符串?
在C语言当中,一般输出一个带引号的字符串需要加上转义字符,但是在python当中有一种更加简单的方式,那就是引号嵌套。【因为在python当中字符串单引号和双引号是等价的】

可以看出,这里用双引号输出了一个带单引号的字符串,这是可以正常输出的。当然,如果要输出两种引号,那就得加上转义字符了。
掌握基本编程框架之后,接下来就是学习别人写的代码,同时要学会使用编程工具(主要是代码提示),这也就要求能看懂代码,或者理解代码的底层设计机制。
4 python函数参数中的*,/
在使用vscode写python程序时,经常会发现在参数列表中莫名多了一个*或者/,如下图所示。
这个符号的作用其实是用来区分位置参数和关键字参数。关于这个在官网其实有很好的解释,如下图所示。

图片来自官网链接
5 python中的解包
对解包最直观的理解就是如果需要传入的参数个数不确定时,可以使用*来表示传入的参数是一个列表。或者在其他的情形下也可以使用解包的语法来实现快速操作。
还可以看看官网对解包的解释: 参考链接

python本质是一门面向对象的语言,每一个变量都是一个对象,因此学会使用类至关重要。
6 类的使用
关于类的使用,其实我本人之前的编程习惯是不喜欢的,感觉要比函数用起来更麻烦,不够“优雅”。因此,能够通过函数解决的问题我基本不会考虑使用类来实现(面向过程编程的思想根深蒂固)。这也导致我一直对类还不够熟悉,趁着这次机会把官方文档好好看了一遍,梳理一下思路。
标准类的代码结构:
class subclass(baseclass): #用括号代表继承,如果有多个继承,用逗号分隔
def __init__(self) -> None: # 构造函数,用于类的初始化
super().__init__() # 父类初始化,也可以直接用父类名字
self.val = 'hello' # 对象的属性
val2 = 'world' # 类的属性
def func1(self): # 类的方法
pass
@staticmethod
def func2(): # 声明静态方法,不用加self函数
pass
item = subclass() # 实例化一个对象
x = subclass.func2() # 静态方法可以直接调用,不用实例化
这个代码有一些注意事项:
- 在类名后用括号代表继承,如果有多个继承,用逗号分隔
- 一般类要加一个构造函数:
__init__(),其中需要传入self参数和其他初始化类时需要指定的属性:def __init__(self, arg1, arg2) super()函数表示该类的父类,主要有两种使用方式,一种是不传参数,直接写super().__init__(),主要适用于单继承的情况;另一种是传递一个参数super(classname, self).__init__(),其中classname参数可以是类本身,则super代表继承的第一个类,如果classname为继承的第一个类,则super代表继承的第二个类,以此类推。
继承的父类初始化时,除使用super函数外,其实也可以直接使用类名来初始化,但要记得在init函数中传入self参数。其实这个问题是本质是 python中调用实例的方法,既可以是
实例名.方法(参数)也可以是类名.方法(实例名, 参数)
class A():
def __init__():
print('A')
class B(A):
def __init__():
super().__init__()
A.__init__(self) #两种方式任选一种
- 一般来说,写在所有函数(方法)外的变量(属性),不需要加
self.,它代表的是类的属性(静态方法),且类中的所有函数都可以直接使用该变量。如果是声明实例化对象的属性,一般是在函数里面,首选__init__()函数,则需要加上self.。但是在函数中不加self.的变量则属于是该函数的局部变量,不是类的属性。 - 关于类的属性和对象的属性怎么区分,我找到一个更好的类比例子,那就是“类中的静态函数和普通函数”。对于类的属性,可以直接调用,不用实例化一个对象。而对象的属性则需要。
编程语言理论知识的学习非常重要,但实战必不可少,只有不断实践,积累代码量,编程能力才能快速提高。
7 优秀的代码格式
根据自己微薄的代码实践经验,总结一下个人认为比较好的代码格式。
- 变量和函数命名要有意义,如果是简写,最好在代码最上面写明简写含义;
- 函数定义时,参数要加类型注解,要注明返回值类型;
- 函数定义时,要在函数名下增加字符串解释,方便调用时查看;
- 模块化程序,尽量合成函数。
所以一般一个程序结构如下所示
# -*- coding: utf-8 -*- 支持文件中出现中文字符
#########################################################################
"""
Created on 2022.11.10
@author: Zoey
@简写说明
+ feat: feature
+ calc: calculate
+ Vec: Vector
+ chd: child
+
+
+
"""
#########################################################################
import numpy as np
import ...
#########################################################################
def func1(s:list|np.ndarray, flag:bool) -> np.ndarray: #记得加类型注解
''' @func: ...(函数功能)
@para s:...(参数列表)
flag: ...
@return: ...(返回值)
'''
...
return xxx
def func2(s:tuple)-> list:
''' @func: ...
@para s: ...
@return: ...
'''
pass
# 主函数
def main():
...
if __name__ == "__main__":
main()
8 pip工具的使用
pip是python第三包的管理工具,在Windows上安装python时会自动安装,它能够在安装包时自动解决依赖问题,功能和Ubuntu上的apt、CentOS上的yum一样,因此其实pip也是可以更换软件源,换成国内的软件源,这样安装包的速度会大大提升。而且操作也很简单(更新清华源):
# 临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple <some-package>
# 永久配置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
清理缓存
在使用pip下载第三方包的过程中,会积累很多缓存,为了减少磁盘压力,建议还是定期清理一下:
pip cache purge
或者是直接手动删除路径$env:LOCALAPPDATA/pip下的cache文件夹
这些缓存如果不清理,有可能会导致卸载重装某个软件包时发生错误,具体表现为安装包并没有具体的文件夹,只有后缀为dist-info的文件夹,而且在执行命令时会提示using cache....,如果安装出错,建议删掉缓存重新安装试试。
9 内置函数和内置库的使用
随着python版本的不断更新,其自带的内置函数和内置库(主要是后者)也逐渐完善,功能越来越多,这里总结一些常用的基本操作。
9.1 python读写文本文件
在python中,一般读写文本文件有两种方式,一个是使用python的内置函数open,一个是使用第三方库,常用的有numpy。
open
## test.txt内容(含有字符串和数字)
# 1LSU 20190101/0015 34.1
# 1LSU 20190101/0045 34.2
# 1LSU 20190101/0115 34.5
# 1LSU 20190101/0145 33.8
# 1LSU 20190101/0215 31.9
# 1LSU 20190101/0245 31.4
with open("test.txt") as file:
A = file.read().split() #这里重点是split函数,默认以空格作为分隔符
import numpy as np
b = np.array(A).reshape(-1,3) #只有numpy类型的数据才能reshape
numpy.loadtxt
其语法格式如下所示。
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#',
delimiter=None, converters=None, skiprows=0, usecols=None,
unpack=False, ndmin=0, encoding='bytes', max_rows=None, *,
quotechar=None, like=None)
其中各个参数的含义如下所示
| 参数名 | 含义 |
|---|---|
fname | 文件名字符串 |
dtype | 读取到的数组中数据的格式 |
comments | 注释的起始符,即该符号后面的本行内容不再读取,继续读取下一行 |
delimiter | 数据的分隔符,可以设置为空格,逗号等 |
converters | 转换函数(不常用) |
skiprows | 跳过前面几行不读 |
usecols | 选择要读取的列 |
unpack | (不常用) |
ndmin | 返回数组的最小维度 |
encoding | 编码格式 |
max_rows | 最多可以读取多少行 |
quotechar | 引用字符,其中的内容不读取 |
like | (不常用) |
9.2 python读写excel表
python读写excel表有很多种方式,其区别只在于使用的库不同。这里总结常用的几种方式。
xlrd&xlwt&xlutils.copy
pandas
import pandas as pd
df=pd.read_excel('my.xlsx',engine='openpyxl',sheet_name='中国疫情')
print(df.shape) #获取文件的行数与列数
9.3 python当前路径和导包问题
上面这个链接总结了一些常用的获取当前文件路径的方式,其中最为简单的用法还是直接使用__file__的宏定义,可以直接用{}加到字符串中。
9.4 数据类型转换总结
| 函数 | 描述说明 |
|---|---|
int(x[,base]) | 将x转为整数 |
float(x) | 将x转为浮点数 |
complex(real[,imag]) | 创建一个复数,real为实部,imag为虚部 |
str(x) | 将对象x转为字符串 |
repr(x) | 将对象x转为表达式字符串 |
eval(str) | 用来计算在字符串中的有效Python表达式,并返回表达式的值 |
tuple(s) | 将序列s转为一个元组,s可为元组、列表、字典等 |
list(s) | 将序列s转为一个列表 |
chr(x) | 将一个整数x转为一个Unicode字符,返回值是当前整数对应的 ASCII 字符 |
ord(x) | 将一个字符x转为对应ASCII整数值,返回值是当前字符对应的十进制整数 |
hex(x) | 将整数x转为十六进制字符串 |
oct(x) | 将整数x转为八进制字符串 |
bin(x) | 将整数x转为二进制字符串 |
set(s) | 将序列s转为可变集合,& | - 表示集合间的交、并、差运算 |
9.5 函数式编程 //2023.3.21
最近在和朋友讨论问题时发现在Python当中有一种操作叫做函数式编程,即某些函数需要传入函数和可迭代对象作为参数,从而得到可迭代对象经过函数操作之后得到的结果。
-
filter(function, iterable)
这个函数是Python内置函数。顾名思义,这个函数的主要功能是过滤,即对传入iterable对象进行过滤操作,原理就是依次将iterable对象中的元素代入function函数,当函数返回True时,则保留;当函数返回False时则去除,最后返回保留下来的元素结合的对象。
根据官网的介绍,当function不为None时,它等价于[item for item in iterable if function(item)]; 当function为None时,它等价于[item for item in iterable if item]。看个例子:

-
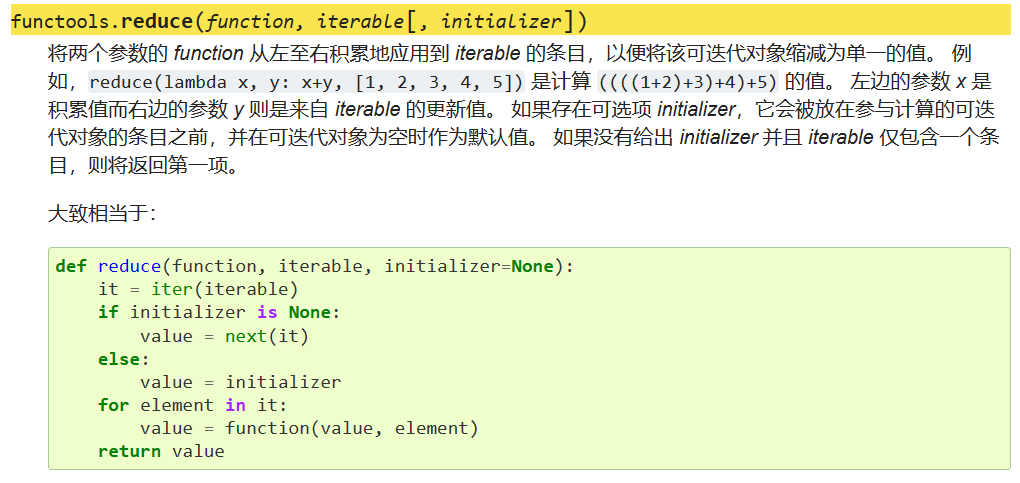
reduce
这个函数不是内置函数,而是内置库functools中的一个函数,这个包在官网的介绍中也是叫“函数式编程模块”:

关于reduce函数的使用,建议直接参考官网:
-
map(function, iterable, *iterables)
map函数也是Python的内置库之一,它的主要作用就是映射,将传入的函数应用于迭代器中的每个对象,然后再返回一个迭代器。
2023.5.12更新:
map函数返回的是一个迭代器,这个实际上是不会执行的,只有在“有取出迭代器中每个元素的操作”之后才会执行其中的函数,因此为了得到结果,往往需要进行强制的类型转换,比如list()
9.6 python多线程
找到一篇非常好的博客:
权当收藏链接了。
补充一些后续遇到的问题:
- threads can only be started once python
在运行代码时出现上述报错,经过查找资料发现这个问题是在线程关闭(thread.join())后,再次调用thread.start()函数启动线程,这个是不允许的,每个线程只能启动一次,运行结束之后需要重新创建线程对象。
9.7 日志输出logging模块
使用方法可以参考这篇博客。
下面是一个函数例子,可以用在类当中。
def __log_init(self):
''' @func: 初始化log
@para none
@return: 返回logger对象
'''
# 创建一个logger对象
logger = logging.getLogger("sqllog")
# 创建处理函数
handle1 = logging.StreamHandler() #输出到终端的处理函数
handle2 = logging.handlers.TimedRotatingFileHandler( #输出到文件,定时删除
"./log/sql.log", #指定写入文件
interval=4, #定时删除时间间隔,默认单位为h
backupCount=100, #最后保留100个
encoding='utf-8',#指定编码格式
)
# 设置处理函数的格式和响应等级
format = logging.Formatter('%(asctime)s %(name)s %(levelname)s %(message)s %(funcName)s') #设置输出格式
handle1.setFormatter(format); handle2.setFormatter(format)
handle1.setLevel(logging.ERROR); handle2.setLevel(logging.ERROR)
# 关联logger和handler
logger.addHandler(handle1)
logger.addHandler(handle2)
# 返回对象
return logger
9.8 显示当前时间和日期
import datetime #导入相应的包
#获取年月日
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
#获取年月
current_date = datetime.datetime.now().strftime('%Y-%m')
current_date = datetime.datetime.now().date()
#获取年份
current_date = datetime.datetime.now().strftime('%Y')
# 直接获取一整个结构体
d1 = datetime.date.today()
print(f'日期所属的年份为 : {d1.year}')
print(f'日期所属的月份为 : {d1.month}')
print(f'日期具体的日期号为 : {d1.day}')
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











