






(部分收录)
简介
本文设计为快速查询指南,所以假设读者熟悉了底层API的使用;我们将在其它文章中更详细地去讨论特定的主题,并花更多时间向仍在学习API的开发人员解释相关的概念。
注意:这些建议是为Mali GPU提供最佳实践,但实际中应用非常复杂,这些一般性的建议总会有例外。我们强烈建议对优化进行实测,来验证它们是否在目标设备上按预期执行。
Article structure
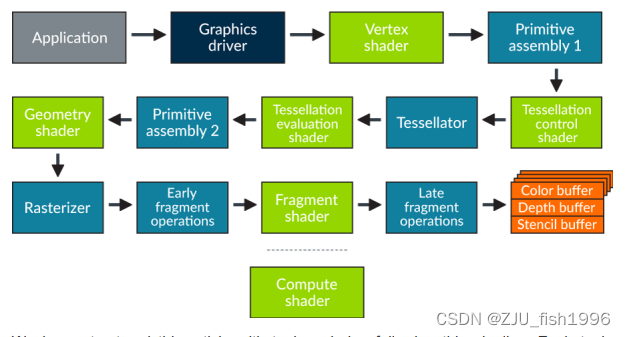
图形处理的过程可以被描述为一个包含了应用、图形驱动层以及GPU本身内部的各种硬件阶段的流水线。
大多数阶段遵循严格的架构管道,一个阶段的输出会作为下一个阶段的输入。其中计算着色器是一个例外,因为它们只是把结果写入到存储在系统内存的资源中,因此它们的输出可以在任何可以消耗这些资源的阶段中使用。
对于每个最佳实践主题,我们都提供了详细解释的建议,以及在开发过程中应该考虑的做和不做的技术要点。
如果可能的话,我们还记录了不遵循建议可能产生的影响,以及可应用的调试技术。
为了简洁起见,我们在本文档提供了相对直白的建议,例如,“不要在片元着色器中使用discard“。但有些情况下,由于算法需要,会不可避免地使用到我们不建议的功能。
不要被我们的建议约束而永远不去使用某个功能。但至少要在开始算法设计的时候能够意识到该算法可能存在的潜在性能影响。
Application logic
在每一帧的开始,应用程序都会在CPU上准备调用指令来驱动图形栈。因此,性能问题的首要可能来源就是CPU上运行的软件,它可能位于应用程序代码内部,也可能位于图形驱动程序内部。
本节着重给出可将图形驱动程序内部产生的CPU负载降至最低的建议。
Draw call Batching
对于驱动程序的CPU开销而言,将绘制调用提交到指令流是一项昂贵的操作,尤其是对OpenGL,其每次drawcall的运行时成本高于Vulkan。
将drawcall的渲染状态加载到硬件的成本是固定的,该成本会分摊到其执行的GPU线程。包含少量顶点和片元的绘制调用无法有效地分摊此成本,因此包含了大量小的绘制调用的应用程序可能无法充分利用硬件性能。
这些问题都可以通过drawcall合批来改善;将多个共享相同渲染状态的物件合并渲染,减少每帧需要的drawcall数量,从而降低CPU的负载和功耗。
Do
▪ 物件合批减少drawcall
▪ 绘制多个相同mesh使用Instancing,使用更灵活的实例化将静态批处理由更积极的示例剔除来实现,确保不可见的实例被剔除
▪ 即使未达到CPU上限也进行合批,以降低系统功耗
▪ 在OpenGL平台上一帧不应超过500drawcall
▪ 在Vulkan平台上一帧不应超过2000drawcall
需要注意的是,这些drawcall的建议是一个比较粗略的经验法则,CPU的性能由硬件集的区别有较大的差异。
Don't
▪ 批处理过大导致影响了剔除效率和渲染顺序
▪ 在不进行合批的情况下渲染大量小的drawcall,比如单个点或四边形
Impact
▪ 更高的CPU应用负载
▪ CPU达到瓶颈后降低性能
Debugging
▪ 分析应用的CPU负载率
▪ 跟踪每帧的API使用和call数量
Draw call culling
应用程序最快能够处理的drawcall是那些在API调用前就能够丢弃的drawcall,因为它们确保是不可见的。记住一旦drawcall调用了API,那么在几何体被剔除前,它至少需要执行顶点着色器以获得裁剪空间的坐标。
Do
▪ 剔除在视锥体外的物体; eg:包围盒视锥体检查
▪ 剔除被遮挡的物体;eg. 预剔除
▪ 在batching和culling之间达到平衡
Don't
▪ 无视世界坐标而发起所有物件的drawcall
Impact
▪ 更高的CPU应用负载
▪ 更高的顶点着色加载和内存带宽
Debugging
▪ 分析应用的CPU负载率
▪ 跟踪每帧的API使用和call数量
▪ 使用GPU性能计数器来验证tile阶段的几何体剔除率。我们通常期望~50%的三角形剔除率,因为它们通常处在视锥体内但位于背面,更高的剔除率意味着应用逻辑的剔除逻辑可能存在问题。
Draw call render order
GPU可以通过使用Early-Z测试最高效地剔除片元。为了达到Early-Z单元地最高剔除率,应该首先从前到后地渲染那些不透明的物件,然后再从后往前地在不透明物件上渲染那些透明物件,来确保alpha混合正确地工作。
自Mali-T620开始,Mali GPU提供了叫做Forward Pixel Kill的优化,这有利于降低被遮挡但未被Early-Z剔除的片元的耗时。但是,不应该仅依赖于此,Early-Z通常更加高效和一致,并且可以在不支持FPK的旧Mali GPUs设备上工作。
Do
▪ 从前往后渲染不透明物件
▪ 渲染不透明物件的时候关闭混合
Don't
▪ 在片元着色器中使用discard;这将强制Late-Z
▪ 使用alpha-to-coverage;这将强制Late-Z
▪ 在片元着色器中写入片元深度;这将强制Late-Z
Impact
更高的片元着色器加载
Debugging
▪ 渲染不带透明物件的场景,并使用GPU性能计数器来检查每个输出像素中片元的渲染次数。如果该值高于1,这意味着场景中包含了不透明的片元overdraw导致Early-Z失效。
▪ 使用GPU性能计数器来检查需要Late-Z测试的片元数量,以及被Late-Z测试剔除的片元数量。
Avoid depth prepasses
在PC和主机游戏上的一种通用技术是Depth prepass。在这个算法中,不透明物件将被绘制两次,第一次仅绘制深度,然后使用EQUALS类型的深度比较来绘制颜色。这个技术是为了最小化重复片元执行的数量,并以双倍的drawcall数量为代价。
对于Tile-based的GPU,例如Mali GPU,已经提供了类似FPK的优化来自动地减少重复的片元执行,这种重复drawcall,顶点执行以及内存带宽消耗已经抵消了这种好处。这属于可能会降低性能的“优化”。
Do
▪ 使用合适的drawcall渲染顺序来最大化利用Early-Z
Don't
▪ 使用深度prepass算法来避免片元的overdraw。
Impact
▪ 由于重复的drawcall带来的更高CPU负载
▪ 由于重复的几何体带来更高的顶点带宽消耗
Vulkan GPU pipelining
Mali GPU支持运行vertex/compute工作的同时,运行来自另一个Render Pass的fragment程序。性能良好的应用程序应该始终保证管线中不会产生大的空隙(Buddle)。
Vulkan中可能存在的管道间隙可能是因为:
▪ 没有及时地提交命令缓冲区,导致GPU利用率不足,或者限制了可能存在的调度机会。Tile-based渲染对此非常敏感,因为将来自一个渲染pass的vertex/compute工作和更早的渲染pass的fragment工作重叠起来是非常重要的
▪ 管线阶段中存在依赖关系,来自渲染pass N的结果将被输出到之后的渲染pass M,N和M之间没有足够的其它工作来隐藏延迟。
Do
▪ 相对频繁地提交渲染缓冲区;eg.对于帧中的每个主要渲染通道
▪ 如果较晚的管道阶段等待来自较早的管道阶段的结果,请确保通过在两个渲染通道之间插入独立的工作负载来隐藏延迟
▪ 考虑是否可以在管道中更早地生成依赖数据;compute是为顶点处理阶段输入数据的重要阶段
▪ 考虑是否可以将依赖于数据的处理移到管道靠后的位置;eg.依赖于片元着色的片元着色往往比依赖于片元的计算着色更高效
▪ 使用fence来异步回读数据到CPU,而不是同步地阻塞导致管道停滞
Don't
▪ 在CPU或GPU上不必要地等待GPU的数据
▪ 直到一帧的最后才去一次性的提交所有渲染pass
▪ 在没有足够的独立工作来隐藏延迟的情况下,在管线中创建后向的数据依赖
▪ 使用vkQueueWaitIdle()或vkDeviceWaitIdle()
Impact
▪ 影响可能会很小,也可能会非常显著,这取决于队列中工作负载的相对大小和顺序。
Debugging
▪ DS-5 Streamline系统分析器可以可视化两个GPU队列上的Arm CPU和GPU工作,并且可以快速显示调度中的空隙,无论是本地的GPU阶段(表示阶段依赖性问题)还是全局的跨CPU和GPU(表示正在使用阻塞CPU的调用)
Vulkan pipeline synchronization
Mali GPU公开了两个硬件处理槽,每个槽都实现了渲染管线阶段中的一个子集,并且能够和另一个槽并行。为了获得最佳性能,提交给GPU的工作负载允许跨这两个硬件槽进行最大化的并行执行,这一点至关重要。Vulkan阶段到Mali GPU执行槽的映射如下:
Vertex/compute hardward slot
▪ VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT
▪ VK_PIPELINE_STAGE_VERTEX_*_BIT
▪ VK_PIPELINE_STAGE_TESSELLATION_*_BIT
▪ VK_PIPELINE_STAGE_GEOMETRY_SHADER_BIT
▪ VK_PIPELINE_STAGE_TRANSFER_BIT
Fragment hardward slot
▪ VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT
▪ VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT
▪ VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT
▪ VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT
▪ VK_PIPELINE_STAGE_TRANSFER_BIT
Vulkan让应用程序来控制命令之间的依赖关系;应用程序必须确保一个命令的管线阶段在之后依赖于它的管线阶段之前完成。API有多个可用的原语可用于命令同步:
▪ subpass依赖,管线屏障(barrier),以及用于在同一队列中进行同步的事件(event)
▪ 用于跨队列同步的信号量(Semaphore)
这些不同细粒度的依赖工具允许应用指定作用域的同步,其中srcStage表明需要等待完成的管线阶段,而dstStage表明需要在执行前进行等待同步的管线阶段。正确地设置同步的最小作用域,在管线中尽可能早地设置srcStage,并且尽可能迟地设置dstStage,对于两个Mali硬件槽实现最大并行度有着很大帮助。信号量使用pWaitDestStages来允许控制依赖的命令何时执行,但是假设源阶段是最差的case也就是BOTTOM_OF_PIPE_BIT,所以仅在没有其它可用方式的时候启用信号量同步。
在低级别中Mali GPU有两种类型的同步:一个是在单个硬件槽中的同步,另外一个是跨硬件槽的同步。
▪ 硬件槽内的同步是轻量的,因为不同渲染命令之间的依赖可以由执行顺序来约束
▪ 在srcStage运行在vertex/compute槽,而dstStage运行在fargment槽的同步是免费的,因为在整体渲染管线中片元着色总是在vertex/compute之后处理,所以这仅仅是一个执行顺序的约束
▪ 在srcStage运行在fragment槽,而dstStage运行在vertex/compute槽的同步可能会非常昂贵,因为它可能会产生管道空隙,除非在srcStage后有足够的隐藏延迟的工作。
请注意,在Vulkan管线中TRANSFER阶段是一个有些重叠的术语,因为传输过程可能在任一硬件执行槽中实现,因此前向或后向的依赖方向并不那么明显。使用那个硬件槽取决于传输类型和传输资源的当前配置。从缓冲区到缓冲区的传输总是在vertex/compute槽中实现,而其它传输可能在任一槽上实现,这取决于当前正在写入的数据资源的状态。使用不同的处理槽可能会对应用程序渲染工作负载的流水线产生较大影响,请注意这一点,并检查传输操作的执行情况。
Do
▪ 在管线中将srcStageMask设置的尽可能早
▪ 在管线中将dstStageMask设置的尽可能迟
▪ 检查你的依赖项是前向依赖(vertex/compute->fragment)还是后向依赖(fragment->vertex/compute),并尽可能减少后向依赖,除非可以在资源生成之间添加足够的工作延迟来隐藏引入的调度空隙。
▪ 在同步渲染pass的时候使用srcStageMask=ALL_GRAPHICS_BIT和dstStageMask=FRAGMENT_SHADING_BIT
▪ 最小化TRANSFER拷贝操作的使用 - 如果可以的话使用更高效的零拷贝算法-并且始终检查它们对硬件流水线的影响。
▪ 仅在需要时使用队列内的屏障,并在屏障之间放置尽可能多的工作
Don't
▪ 不必要的让硬件饿死,旨在重叠vertex/compute和fragment进程
▪ 使用如下srcStageMask->dstStageMask同步配对,它们常能带来管线的耗时:
▪ BOTTOM_OF_PIPE_BIT -> TOP_OF_PIPE_BIT
▪ ALL_GRAPHICS_BIT -> ALL_GRAPHICS_BIT
▪ ALL_COMMANDS_BIT -> ALL_COMMANDS_BIT
▪ 需要发起信号并等待事件的时候使用VkEvent(应该使用vkCmdPipelineBarrier)
▪ 在单一队列中使用VKSemaphore来管理依赖
Impact
错误的使用管道评到可能会导致GPU工作不足(同步太多)或渲染效果错误(同步太少),正确地实现这一部分是任何Vulkan应用程序的关键部分。
Warning
请注意,为不同类型的工作负载安排两个不同的独立硬件插槽是tile-based GPU(如Mali)和桌面即时模式渲染的一个不同的地方。当从桌面GPU移植到tile-based GPU时,要调整管线内容使其更好地适配。
Debugging
▪ DS-5 Streamline系统分析器可以可视化各个GPU硬件槽上Arm CPU和GPU的进程并快速显示调度中产生的空隙,这可能是GPU硬件内部的(意味着阶段依赖问题)或者全局的CPU和GPU之间的(意味着一个阻塞的CPU调用)
Pipelined resource updates
对于应用开发者来说,OpenES提供了一种同步渲染模型,尽管底层执行是异步的。渲染必须反映提交drawcall时数据资源的状态,这意味着,如果一个待提交的drawcall引用的资源被应用立即修改了,驱动必须采取规避操作来保证正确性。在Mali GPU中,我们会尽量避免阻塞和等待资源引用计数归0,这可能会耗尽管线并影响性能。相反,我们创建一个新版本的资源来反映新状态,并且保留老版本的资源-作为一个ghost-它将一直存在,直到drawcall完成且引用计数归0。
这一操作是非常昂贵的,它至少需要对新资源的内存分配,和不再需要时对旧资源的清理,并且可能需要将旧资源缓冲区拷贝到新资源中,如果更新并不是替换形式的。
Do
▪ 对动态更新的资源使用N-buffer资源,避免修改drawcall队列中正在引用的资源
▪ 使用GL_MAP_UNSYNCHRONIZED来允许使用glMapBufferRange来修改被drawcall引用的缓冲区中的未引用区域。
Don't
▪ 修改被drawcall引用的资源
▪ 使用GL_MAP_INVALIDATE_RANGE或GL_MAP_INVALIDATE_BUFFER标记的glMapBufferRange(),由于历史规范的存在歧义,这些标记现在仍然会导致ghost资源的创建
Impact
▪ ghosing资源会增加CPU负载,因为额外的内存分配和可能存在的创建新资源的拷贝
▪ 尽管表面上看起来它通常不会增加内存占用;常用的替代方法是应用程序手动对资源使用N-buffer,这将分配和ghost资源一样多的内存,在内存跟踪中你看到的是ghost资源不断分配和销毁导致的内存波动
Debugging
▪ DS-5 Streamline系统分析器可以可视化Arm CPU和GPU进程。如果资源更新管线出错可能会显示为CPU进程消耗的上升或者CPU忙碌时GPU中的空隙。
CPU overheads
Pipeline creation
在shader编译和链接的阶段,Vulkan和OpenGL有相似的性能影响,但在Vulkan中,应用开发者还需要提供编译管线的持久缓存。
Do
▪ 在应用启动或者游戏关卡加载的时候创建Pipeline
▪ 使用Piepline缓存来加速pipeline创建
▪ 将pipeline缓存序列化到硬盘,并在下次应用使用的时候重新加载它,让用户加载速度变快获得更好的用户体验
Don't
▪ 使用CREATE_DERIVATIVE_BIT来创建derivative pipeline,这对当前Mal GPU驱动没有任何帮助
Impact
▪ 存在高CPU负载和跳帧,如果在应用交互期间动态创建pipeline
▪ 无法序列化和重载pipeline缓存意味着应用无法从后续应用程序运行时减少的加载时间中受益
Allocating memory
vkAllocateMemory()分配器并不是给频繁的直接内存分配设计的;我们认为vkAllocateMemory()的所有分配都是一个比较重的分页内核调用。
Do
▪ 使用自己的分配器来对分配进行子管理
Don't
▪ 使用vkAllocateMemory() 作为通用的内存分配器
Impact
▪ 增加应用的CPU负载
Debugging
▪ 在运行时追踪vkAllocateMemory() 调用的频率和分配大小
Vulkan CPU memory mapping
Vulkan提供了对复杂缓冲区映射的更多支持,允许应用对使用的内存类型有更多的控制。
Mali GPU驱动暴露了Midgard架构GPU的三种内存类型:
▪ DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_COHERENT_BIT
▪ DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_CACHED_BIT
▪ DEVICE_LOCAL_BIT | LAZILY_ALLOCATION_BIT
以及四种Bifrost架构GPU上可能的内存类型:
▪ DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_COHERENT_BIT
▪ DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_CACHED_BIT
▪ DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_COHERENT_BIT | HOST_CACHED_BIT
▪ DEVICE_LOCAL_BIT | LAZILY_ALLOCATED_BIT
每一个都可以有着不同的用处。
Not Cached, coherent
HOST_VISIBLE | HOST_COHERENT内存标记是用于支持和匹配OpenGL ES描述的CPU上未缓存的数据。对于CPU上只写资源是最佳类型,因为它避免CPU缓存CPU永远不会使用的数据,并且使用CPU写入缓冲区将小的写入合并到更大更高效的外部存储设备。
Cached, incoherent
HOST_VISIBLE | HOST_CACHED内存类型设置了CPU端使用CPU缓存的映射内存。这适用于由应用软件可读的映射资源;由于能将数据预读取到CPU缓存中,使用memcpy()读取缓存回读的吞吐量观测的速度提升了10倍。
但是,由于其内存与GPU内存视图不一致,当CPU完成写入,要将数据发送到GPU时需要调用vkFlushMappedRanges(),并且还需要调用vkInvalidateMappedRanges()来确保安全回读GPU已经写入的数据。这两者都需要驱动插入手动CPU缓存维护操作,以确保CPU缓存和主内存内容之间的一致性,这是相对昂贵的。谨慎使用在CPU上回读的资源。
Cached, coherent
HOST_VISIBLE | HOST_COHERENT | HOST_CACHED内存类型仅在Birfrost GPU上支持,并且仅当芯片组支持CPU和GPU之间的硬件一致性协议时可用。如果平台不支持,驱动将使用HOST_VISIBLE | HOST_CACHED来代替。
CPU端缓存内存的时候提高了高效率的回读,硬件一致性的使用意味着避免了手动控制缓存的开销。所以当可行的时候,更推荐使用HOST_VISIBLE | HOST_COHERENT内存类型。
硬件一致性确实有一些比较小的功耗成本,并且对于大多数CPU上只写的资源是不需要的;对于这一类资源,我们仍然建议使用HOST_VISIBLE | HOST_COHERENT内存类型来绕过CPU缓存。
Lazily allocated
LAZILY_ALLOCATED内存类型是一种特殊的内存类型,它被设计为仅支持GPU上的虚拟地址空间而不存在物理地址,这是由于内存应该是临时的并且不会由GPU内部之外访问。
它适用于仅存在GPU tiled缓冲区内存的资源,并且不会在创建它们的render pass之外使用 - 比如用于简单渲染的深度/模板缓冲区以及G-buffer附件。如果需要,驱动程序将自动为这些资源分配物理内存,但这可能会导致停顿。
Do
▪ 对不变的资源使用HOST_VISIBLE | HOST_COHERENT类型
▪ 对CPU只写的资源使用HOST_VISIBLE | HOST_COHERENT类型
▪ 当向HOST_VISIBLE | HOST_COHERENT写入更新时使用memcpy()或确保写入是连续的,以便从CPU写入连续单元时获得最佳效率
▪ 对于只在一个renderpass中存在的临时帧缓冲attachment,使用LAZILY_ALLOCATED
▪ 持久映射那些经常访问的缓冲区,例如Uniform Buffer或Dynamic Vertex Buffer数据,因为映射和取消映射缓冲区都需要CPU成本
Don't
▪ 在CPU中从未缓存的数据回读数据
▪ 实现一个子分配器,并将其CPU侧管理的元数据存储在未缓存的缓冲区上
▪ 对TRANSITENT_ATTACHMENT帧缓冲区以外的内容使用LAZILY_ALLOCATED内存
Impact
▪ 增加的CPU进程消耗,尤其是从未缓存内存的回读,这可能比缓存读取慢一个数量级
Debugging
▪ 检查所有CPU上读取的缓冲区是否被缓存
▪ 为缓冲区设计接口来支持按需进行隐式刷新/无效设置,如果这种基础的解耦,调试由于缺少维护操作导致的一致性错误是非常困难和耗时的。
Command pools
如果command pool创建的时候未添加RESET_COMMAND_BUFFER_BIT的标记,那么command pool不会自动回收已删除的command buffer的内存。未设置该标记的pool不会回收这些内存而是一直保留这些内存引用,直到应用程序重置了pool。
Do
▪ 使用RESET_COMMAND_BUFFER_BIT来创建command pool,或者定期调用vkResetCommandPool() 来释放内存。注意RESET_COMMAND_BUFFER_BIT将会强制pool中每个command buffer使用单独的内部分配器,相比起单个poold的重置会增加CPU的负载。
Impact
在command pool reset调用前,会有持续增长的内存使用
Command buffers
Command buffer的使用标记会影响性能。为了获得最佳性能,应该设置ONE_TIME_SUBMIT_BIT标记。如果使用了SIMULTANEOUS_USE_BIT标记可能会导致性能的下降。
Do
▪ 默认使用ONE_TIME_SUBMIT_BIT
▪ 考虑构造每帧的command buffer,考虑连续使用的command buffer的复用
▪ 如果应用程序逻辑每帧重播完全相同的command序列,使用SIMULTANEOUS_USE_BIT;相比起应用重播,驱动能更高效地处理这种情况,但是不如One-time submit buffer高效。
Don't
▪ 非必要时使用SIMULTANEOUS_USE_BIT
▪ 使用包含RESET_COMMAND_BUFFER_BIT标记的command pool。这将禁止驱动对pool中的所有command buffer使用单一的大分配器,这增加了内存管理的消耗。
Impact
▪ 如果标记使用的不恰当,会带来CPU负载的增长
Debugging
▪ 评估除了ONE_TIME_SUBMIT_BIT之外的任何命令的缓冲区标志的使用,并检查它是否是必要的。
▪ 评估每个vkResetCommndBuffer()的使用,并且测试它们是否能够被vkResetCommandPool()替代。
当前vkResetCommandBuffer的实现会比预期中更昂贵,因为它等价于释放并且重新分配command buffer。
Do
▪ 避免频繁的调用vkResetCommandBuffer
Impact
▪ 如果频繁的调用command buffer reset会带来CPU负载的增长
Secondary command buffers
当前Mali硬件层没有原生支持在secondary command buffer中发起命令,所以当使用secondary command buffer的时候会产生额外开销。应用程序通常会在需要构造多线程渲染的command buffer的时候会用到secondaryd command buffer,但是建议最小化secondardy command buffer的调用。对于primary command buffer而言,我们建议避免创建使用SIMULTANEOUS_USE_BIT的command buffer因为这会带来更高的负载。
Do
▪ 在需要使用多线程渲染的时候使用secondary command buffer
▪ 最小化每帧调用secondary command buffer的次数
Don't
▪ 对secondaryd command buffer使用SIMULTANEOUS_USE_BIT
Impact
▪ 增加CPU负载
Descriptor sets and layouts
Mali GPU在API层支持四个同时绑定的descriptor set,但在内部每个drawcall都需要一个物理的描述符表。
对于任一drawcall而言,如果API层中四个descriptor set中的一个或多个descriptor set发生了变化,驱动需要重建内部的表。descriptor变化后的第一个drawcall相比其后面重用相同descriptor set的drawcall有更高的CPU负载,并且descriptor sets越大,重建的代价也就越高。
此外,当前驱动中descriptor set pool分配并不是池化的,因此不建议在性能敏感的代码中调用vkAllocateDescriptorSets()
Do
▪ 尽可能地pack descriptor set绑定空间
▪ 更新已经分配但不再引用的descriptor set,而不是重置descriptor pool并且重新分配新的descriptor set
▪ 倾向于重用已经分配的descriptor set,而不是每次都使用相同的信息更新它们
▪ 如果你计划绑定相同的UBO/SSBO但仅使用不同的偏移,倾向于使用UNIFORM_BUFFER_DYNAMIC或STORAGE_BUFFER_DYNAMIC的描述符类型,备选方案是使用更多的descriptor set
Don't
▪ 使用稀疏的descriptor set
▪ 留下未使用的条目 - 需要付出拷贝和合并的代价
▪ 在性能敏感的代码段中从descriptor pool分配descriptor set
▪ 在不需要修改绑定偏移的时候使用DYNAMIC_OFFSET的UBO/SSBO,使用动态偏移的额外开销很小
Impact
▪ drawcall带来增加的CPU负载
Debugging
▪ 跟踪pipeline layout中未使用的条目
▪ 检查vkAllocateDescriptorSets中是否存在竞争,如果发生了会产生性能问题
Vertex shading
Index draw calls
索引绘制往往会比非索引绘制更高效,因为它们重用了更多的顶点,如在相邻的三角形strips之间。这里有一些可以提升索引绘制的建议。
Do
▪ 在可能进行顶点复用的时候使用索引绘制
▪ 对于post-transform缓存优化索引的局部性
▪ 确保索引缓冲区引用的每个值在最大和最小使用的索引值之间,来最小化顶点捕获的消耗
▪ 避免修改索引缓冲区中的内容,或者对volatile资源使用glDrawRangeElements(),否则驱动程序必须扫描索引缓冲区来决定有效的索引区间。
Don't
▪ 使用客户端侧的索引缓冲区
▪ 使用稀疏访问顶点缓冲区中顶点的索引
▪ 对于非常简单的模型比如一个四边形或者点的列表使用索引绘制,只有较少或没有顶点重用
▪ 通过从完整精度模型稀疏的采样顶点来实现几何LOD,应为每个层级创建连续的顶点。
Impact
▪ 使用客户端侧的索引缓冲区会带来CPU负载的增加,因为需要分配服务器侧的缓冲区存储,拷贝数据,并且遍历内容来确定有效的索引区间
▪ 使用频繁修改的索引缓冲区会带来CPU负载的增加,因为需要重新便利缓冲区来决定有效的索引区间
▪ 由于索引的稀疏性或者较低的局部性产生的低效模型索引通常会带来GPU顶点处理额外的开销和带宽,这还取决于模型的复杂性和内存中索引缓冲区的布局。
Debugging
▪ 遍历你提交的索引缓冲区并且确定你的索引缓冲区是否对顶点缓冲区存在稀疏访问,标记哪些包含未使用下标的缓冲区。
Index buffer encoding
索引缓冲区数据是Mali GPU几何体装配和tiling阶段的主要数据资源之一。通过最小化packing索引缓冲区能够降低tiling的消耗。
Do
▪ 使用最低精度的索引数据类型来尽可能降低索引列表的大小
▪ 倾向于使用strip格式而不是list格式来减少索引列表的大小
▪ 使用Primitive Restart来减少索引列表的大小
▪ 使用post-transform缓存来优化索引局部性
Don't
▪ 对所有数据都使用32-bit下标值
▪ 使用空间一致性较差的索引缓冲区,因为这会导致缓存命中下降
Impact
在实际中很少会带来比较大的问题,只要drawcall足够大,能确保顶点着色和tiling管道的清晰,但是这些小改进可以累积成比较大的优化。
Attribute precision
对于很多顶点属性数据来说,并不需要FP32 highp的精度,比如颜色。一个好的资产管线使用最小的精度去记录数据,并且能够确保最终的输出可用,节省带宽并提升性能。
OpenGL和Vulkan都能表达不同格式的属性来适配相应所需的精度,比如8-bit,16-bit还有packed格式如RGB10_A2。
Do
▪ 使用FP32来计算顶点的位置,额外的精度通常是为了确保稳定的几何位置输出的
▪ 对于其它属性使用最小精度的属性;Mali GPU硬件可以在数据加载的时候免费转换FP16/FP32,因此使用尽可能小的格式并打包数据格式会降低带宽
Don't
▪ 总是对任何属性使用FP32,因为这样非常简单并且桌面GPU也是这么做的;这会带来很多性能和功耗问题
▪ 使用FP32数据上传到缓冲区,并且将其作为mediump属性来访问,这是一种对内存存储和带宽的浪费因为额外的精度被丢弃了
Impact
▪ 更高的内存带宽和占用,并且降低了顶点着色的性能
Attibute layout
从Birfrost架构开始,顶点数据可以使用索引驱动的顶点着色(IDVS)来绘制,首先绘制位置,然后对剔除后的图元顶点进行着色。良好的缓冲区布局可以最大限度的发挥这种几何管道的优势。
Do
▪ 对位置信息使用单独的顶点缓冲区
▪ 在单个缓冲区中交错传递给顶点着色器未修改的属性
▪ 在单个缓冲区中交错由顶点着色器修改的每个非位置属性
▪ 保证顶点缓冲区属性步长紧凑
▪ 考虑移除特定用途未使用属性的专门优化网格版本:例如,为阴影贴图生成一个仅包含位置属性的缓冲区
Don't
▪ 对每个属性使用一个缓冲区;每个缓冲区占用了缓冲区描述符缓存中的一个槽,并且对于剔除的顶点更多属性带宽会在fetch的时候被浪费,因为它们和可见顶点共享cache line。
▪ 将交错的顶点缓冲区补偿对齐到2的幂来“帮助”硬件;这只会增加内存带宽
Varying precision
顶点着色器的输出-通常被称为可变输出(varying output)-会写回Mali GPU显存,因为在片元着色开始工作前所有的几何处理必须完成。最小化可变输出的精度可以带来双倍的提升,一次是顶点着色器输出的时候,另一次是片元着色访问的时候,因此正确设置非常重要的。
如下可变数据通常使用mediump精度:
▪ 法线
▪ 顶点色
▪ 视图空间的位置和方向
▪ 对于特定大小未tiled纹理的纹理坐标(大概在512x512)
如下可变数据通常使用highp精度:
▪ 世界空间的位置
▪ 对于大纹理的坐标,或者级别warpping的纹理坐标
Do
▪ 如果精度可接受的话对可变输出使用mediump
Don't
▪ 对可变输出使用超过所需的分量和精度
▪ 顶点着色输出一些片元不需要的输出
Impact
▪ 增加GPU内存带宽
▪ 降低顶点和片元着色器性能
Triangle density
顶点的带宽和执行时间通常会比片元的消耗要大。确保你能够让每个片元的计算价值能够匹配的上几何体渲染的代价,将顶点处理的消耗分摊到输出的多个像素。
Do
▪ 确保模型中每个几何体至少会生成10-20个片元
▪ 使用LOD动态模型,当物体离相机更远时使用更简单的模型
▪ 使用法线贴图技术将逐像素光照计算所需的复杂几何信息烘焙到补充纹理,从而使用更简单的实时模型。ASTC压缩格式包括了对压缩法线贴图的专门设计的压缩优化,因而可以优化带宽
▪ 更倾向于提升光照表现和纹理来提升最终的图像质量,而不是暴力增加几何数量。
Don't
▪ 生成细节三角形
Impact
▪ 对于tiled-based渲染器高精度的几何体会带来许多问题,包括着色器计算,内存带宽以及由于内存流量带来的系统功耗
Debugging
▪ 跟踪总几何体数量并且检查像素数量,对于1080p渲染通道,实际上不需要超过250k的三角形(平均每个正面三角形16个片元)
▪ Bifrost GPU包含了一个硬件性能计数器,用于检查由于生成覆盖范围不足被杀死的微三角形;如果这个数量超过了特定比例,请检查网格对象,并考虑在运行时使用更积极的LOD选择。
Instanced vertex buffers
OpenGL和Vulkan都支持了实例化绘制,使用属性实例数来决定如何划分缓冲区以定位每个实例的数据。有一些硬件限制和实例化顶点缓冲区的正确使用相关。
Do
▪ 对所有实例数据使用单一交错的缓冲区
▪ 使用实例缓冲区来解决Uniform buffer需要小于16kb的限制
▪ 如果可行的话,使用二的幂次方,即每个实例的顶点实例数据应该是2的幂次
▪ 如果无法遵循此处的建议,则首选使用gl_InstanceID对Uniform buffer或shader存储缓冲区进行索引查找
▪ 如果实例数据可以用较小的数据类型表示,则首选实例化属性,因为Uniform buffer和shader存储缓冲区无法利用这些更密集的数据类型
Don't
▪ 使用超过一个类型为Instance的顶点缓冲区
Impact
▪ 受影响的实例drawcal会降低性能
Tiling
Effective triangulation
Tiling和光栅化都在比单个像素更大的片元patches上工作;eg.对于Mali GPUs而言,tiling会使用至少16x16像素大小的bins,片元光栅化需要使用2x2个像素小大用于片元着色。一个最佳实践是使用最少的三角形尽可能覆盖到所需的像素,尤其是提高三角形面积和边长的比率。
Do
▪ 尽可能使用接近等边的三角形;这提升了面积和变长的比率,减少了占用率不足的片元四边形生成的数量。
Don't
▪ 由于三角形在2x2像素的片元四边形中采样不足导致了上升的片元着色消耗
Debugging
▪ Mali图形调试器包含了模型可视化工具,允许可视化被提交的物件在物体空间的轮廓。
Fragment shading
Efficient render passes
Tile-based的渲染作用在渲染pass上;每个渲染pass都有明确的开始和结束,并且仅在pass结束的时候在内存中产生输出。pass开始的时候对应于GPU中tiled内存的初始化,pass结束对应于将输出写回主内存。所有中间帧的帧缓冲区工作状态都完全存在于图块内存中,并在主内存中不可见。
Vulkan渲染pss是API中显式概念,并且定义了loadOp操作 - 它定义了Mali GPUs在pass开始的时候如何初始化tile内存 - 以及storeOp操作 - 它定义了在pass的结束什么将被写回到主存。此外,Vulkan引入了延迟分配内存(lazily allocated memory)的概念,这意味着临时的attachment仅在单个渲染pass期间存在,并不会实际分配物理存储。
Do
▪ 在一个渲染pass开始的时候使用loadOp = LOAD_OP_CLEAR或loadOp = LOAD_OP_DONT_CARE来清除或使attachment失效
▪ 对那些只在一个渲染pass内生效的attachment使用TRANSIENT_ATTACHMENT标记,使用LAZILY_ALLOCATED内存,并确保在渲染pass结束的时候使用storeOp = STORE_OP_DONT_CARE使内容失效。
Don't
▪ 在renderpass内部使用的图像使用vkCmdClearColorImage()或vkCmdClearDepthStencilImage();将清除转移到loadOp设置上
▪ 在渲染pass内部使用vkCmdClearAttachments()来清除attachment;这并不是免费的,不想清除或失效的加载操作
▪ 在shader代码中通过写入一个常量的颜色来清除一个渲染pass
▪ 使用loadOp=LOAD_OP_LOAD,除非你的算法确实需要framebuffer的初始状态
▪ 为attachment设置渲染pass实际上不需要的loadOp和storeOp; 你将会为attachment生成一些不必要的tile内存的交互
▪ 在需要直接渲染UI/HUD的时候,设置loadOp=LOAD_OP_LOAD,并使用vkCmdBlitImage来实现低分辨率到原始分辨率的缩放,这会带来不必要的内存交互
Impact
▪ 正确的处理渲染pass是非常关键的;如果不遵循这个建议的话可能会带来显著的片元着色性能下降,以及由于在渲染开始的时候需要读取未清除的attchment到tile内存,并且在渲染结束的时候写出未失效的attachment,带来的内存带宽的增加。
Debugging
▪ 浏览渲染pass创建的API使用,以及任意vkCmdClearColorImage(), vkCmdClearDepthStencilImage()和vkCmdClearAttachments()的使用
Multisampling
多重采样的大多数用处,是将额外采样的数据保存在GPU内部的tile内存中,并且将该值解析为单个像素颜色,作为图块最终写入的一部分。这意味着这些额外采样带来的额外带宽永远不会影响到外部存储器,这使得它非常高效。
多重采样可以完全集成到Vulkan的渲染pass中,允许在subpass结束的时候明确指明使用多重采样解析。
Do
▪ 尽可能的使用4x MSAA;它并不昂贵并能提供较好的图像质量提升
▪ 对多采样图像使用loadOp = LOAD_OP_CLEAR或loadOp = LOAD_OP_DONT_CARE
▪ 在subpass中使用pResolveAttachments来自动从多采样颜色解析到单采样颜色缓冲区
▪ 对多采样图像使用storeOp = STORE_OP_DONT_CARE
▪ 对分配的多采样图像使用LAZILY_ALLOCATED内u才能,它们不需要持久保存到主存中,因此不需要物理分配
Don't
▪ 使用vkCmdResolveImage();这对带宽和性能有显著的影响
▪ 对多采样图像attachment使用storeOp=STORE_OP_STORE
▪ 对多采样图像attachment使用storeOp=LOAD_OP_STORE
▪ 使用超过4x的MSAA而没有考量过性能,由于它不是完整的吞吐量
Impact
▪ 未获得内敛解析可能会导致内存带宽的显著提升并降低性能;以60fps手动写入和解析4xMSAA1080p表面需要3.9GB/s的内存带宽,而使用内联解析时仅为500MB/s
Multipass rendering
Vulkan的一个主要特性就是多pass渲染,它允许应用程序使用标准API来充分利用Tile-based架构的全部功能。Mali GPU能够从一个subpass中获取颜色和深度attachment,并将它们用作后续subpass的输入attachment,而无需通过主内存。这使得强大的算法如延迟着色或可编程混合能够广泛高效的使用,但需要正确设置一些东西。
Per-pixel storage requirements
大多数Mali Gpus设计为使用tile缓冲区颜色存储每个像素128-bit来渲染16x16的像素tiles,此外最近的一些GPUs比如Mali-G72将其增长为每个像素256-bits。G-buffer需要比这更多的颜色存储,这可以以片元着色器期间使用更小的tile作为代价来使用,可以降低整体的吞吐量并增加读取列表的带宽。
例如,适用于128位带宽预算的G-Buffer布局可为:
▪ Light:B10G11R11_UFLOAT
▪ Albedo:RGBA8_UNORM
▪ Normal:RGB10A2_UNORM
▪ PBR material parameters/misc:RGBA8_UNORM
Image layouts
多pass渲染是图像布局能够产生影响的例子,因为它对允许驱动程序启用的优化有重大影响。这是一个包含所有良好路径的示例多pass布局:
Initial layouts:
▪ Light : UNDEFINED
▪ Albedo:UNDEFINED
▪ Normal:UNDEFINED
▪ PBR:UNDEFINED
▪ Depth:UNDEFINED
G-buffer pass(subpass#0) output attachments:
▪ Light : COLOR_ATTACHMENT_OPTIMAL
▪ Albedo:COLOR_ATTACHMENT_OPTIMAL
▪ Normal:COLOR_ATTACHMENT_OPTIMAL
▪ PBR:COLOR_ATTACHMENT_OPTIMAL
▪ Depth:DEPTH_STENCIL_ATTACHMENT_OPTIMAL
注意light attachment,它会作为我们最终的输出,因此应该作为VkRenderPass的attachment#0,这样它会占据渲染目标的第一个slot,硬件获取的性能更好。我们将light作为G-buffer pass的输出是因为渲染器可能需要输出一些不透明物件的发光参数。由于我们会合并subpasses因为不会有写出到渲染目标的额外带宽,因此-不像桌面端-我们不需要开发一些特别的方案来通过其它G-Buffer缓冲区转发自发光的贡献。
Lighting pass(subpass#1)input attachments:
▪ Albedo:SHADER_READ_ONLY_OPTIMAL
▪ Normal:SHADER_READ_ONLY_OPTIMAL
▪ PBR:SHADER_READ_ONLY_OPTIMAL
▪ Depth:DEPTH_STENCIL_READ_ONLY
这里重要的一点是,一旦任一pass开始从tile缓冲区读取,任何depth/stencil attachment之后将被标记为read-only。这允许了大幅提升多pass性能的优化;DEPTH_STENCIL_READ_ONLY为如下用例设计,只读的depth/stencil测试,同时也将其用作着色器的输入attachment,用程序方式访问深度值。
Lighting pass(subpass #1)output attachments:
▪ Light:COLOR_ATTACHMENT_OPTIMAL
在subpass#1期间的光照计算的混合应该在subpass#0期间提供的计算后的发光数据之上进行。如果需要的话,应用程序还可以在所有光照计算完成后将透明对象混合。
Subpass denpendencies
在pass之间的subpass依赖必须使用设置了DEPENDENCY_BY_REGION_BIT标记的VkSubpassDependency,这告诉驱动每个subpass仅在该像素坐标处依赖于前一个subpass,因此保证不会从先前的subpass读取出tile外的数据。
根据我们描述的例子,subpass依赖设置可能为:
VkSubpassDependency subpassDependency = {};
subpassDependency.srcSubpass=0;
subpassDependency.dstSubpass=1;
subpassDependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT |
VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT |
VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT
subpassDependency.dstStageMask = VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT |
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT|
VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT |
VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT;
subpassDependency.srcAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT|
VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT
subpassDependency.dstAccessMask = VK_ACCESS_INPUT_ATTACHMENT_READ_BIT|
VK_ACCESS_COLOR_ATTACHMENT_READ_BIT|
VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT|
VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_READ_BIT|
VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
subpassDependency.dependencyFlags = VK_DEPENDENCY_BY_REGION_BIT;
Subpass merge considerations
驱动会合并subpasses,如果它们满足以下条件:
▪ 颜色缓冲区数据格式可以合并
▪ 合并可以节约写出/回读,两个不相关的不共享任何数据的subpasses不会从多pass受益,因此不会合并
▪ 如果在所有subpass中用于输入和颜色attachments的VkAttachments数量<=8,注意depth/stencil不受该限制
▪ depth/stencil attachment在subpasses之间未发生改变
▪ 多采样数量对每个attachments都是相同的
Do
▪ 使用多pass
▪ 对颜色使用128-bit G-Buffer预算
▪ 在subpasses之间使用区域依赖
▪ 对深度使用DEPTH_STENCIL_READ_ONLY的图像布局,在G-Buffer pass完成后
▪ 对使用LAZILY_ALLOCATED内存为每个attachment备份图像,除了lighting buffer,它是唯一写入内存的纹理
▪ 遵循以下渲染pass最佳实践:对加载的attachments使用LOAD_OP_CLEAR或LOAD_OP_DONT_CARE,对短暂的存储使用STORE_OP_DONT_CARE
Don't
▪ 将G-buffer存储到内存
Impact
▪ 未正确的使用多pass会导致驱动使用多个物理passes,将pass之间的及时图像数据传输到内存中。这就丢失了多pass渲染特性的所有优势。
Debugging
▪ GPU性能计数器提供了渲染的物理tiles的数量信息,这可用于确定哪些pass在被合并
▪ GPU性能计数器提供了使用late-z测试的片元线程数量,如果值比较高说明未正确地设置DEPTH_STENCIL_READ_ONLY。
HDR rendering
对于移动端内容,渲染HDR图像相关的格式包括:RGB10_A2(unform),B10R11G11和RGBA16F(float)
Do
▪ 如果需要让动态范围得到小的提升,更倾向于使用RGB10_A2 UNORM的格式
▪ 如果仅有32bpp,更倾向于使用B10G10R11,相比起f16 float,这可以节省大量带宽,并且可以维持G-Buffer带宽在128bpp内
Don't
▪ 使用RGBA16,除非B10G11R11表现得不够好,或者实际上需要framebuffer中的alpha值
Impact
▪ 增加带宽并减低性能
▪ 对于多pass渲染适配到128bpp比较困难
Stencil updates
许多模板的掩码算法在创建使用模板时,会使用比较小的值来修改模板值(比如0或1)。当设计使用多个drawcall完成的模板掩码算法时,应该尽可能最小化模板更新的次数。
Do
▪ 当已经值是相等的时候,使用KEEP而不是REPLACE
▪ 在执行成对绘制的算法中 - 一个用于创建模板掩码,另一个用于对未掩码的片元着色 - 使用第二次绘制重置模板值,为下一次绘制做好准备,避免需要单独做中途清除操作。
Don't
▪ 写入一个不需要的新模板值
Impact
▪ 写入模板值的片元不能被快速丢弃,这会引入额外的片元处理成本
Blending
在Mali GPUs中混合通常都是非常高效的,因为我们可以在on-chip tile缓冲区上直接访问到dstColor,但是对于特定格式来说可能会更加高效。
Do
▪ 更倾向于使用无符号归一化的格式(unorm)
▪ 物体是不透明的时候总是禁用混合
▪ 关注逐像素混合的层数;高层数会带来需要计算的片元数量的增加,哪怕着色器非常简单
▪ 考虑将大的包含透明和半透明区域的UI元素拆分为透明和不透明两个部分,来确保early-zs/FPK能够移除不透明部分的过度绘制(overdraw)
Don't
▪ 对浮点格式的帧缓冲区执行混合
▪ 对多重采样浮点格式的帧缓冲区执行混合
▪ 通用的用户渲染代码接口,总是开启混合,并通过将alpha设为1.0来"禁用"混合
Impact
▪ 混合导致很多移除片元过度绘制的优化失效了,比如early-z测试和FPK,所以它对性能有显著的影响。对于用户界面渲染和2D游戏尤其如此,它们通常会有多层sprites。
Debugging
▪ 使用Mali图形调试器来单独调试每帧的组成,观察哪些drawcall包含了混合并且带来了多少overdraw
Transaction elimination
Transaction elimination是Mali的一项技术,当tile中的渲染颜色和内存中的数据一致时,避免产生写入到帧缓冲区的带宽,仅当tile与内存中的签名对比失败后才从tile中写出。该技术对于包含大量静态不透明覆盖层的用户界面以及游戏特别有帮助。
Transcation elimination可作用于如下图像:
▪ 采样数量为1
▪ mipmap层级为1
▪ 图像属性包括COLOR_ATTACHMENT_BIT
▪ 图像属性不包括TRANSIENT_ATTACHMENT_BITT
▪ 使用单个颜色附件(除了Mali-G51)
▪ 最高效的tile大小,由像素数据存储要求决定,为16x16像素
Transaction elimination是为数不多的驱动会关注图像布局的例子之一。当图像从”安全“转换到”不安全”布局时,Transaction elimination标记的缓冲区必须失效。“安全"的图像布局被认为是哪些只读或者只能在片元着色中被写入的图像布局,这些布局为:
▪ VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL
▪ VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL
▪ VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL
▪ VK_IMAGE_LAYOUT_PRESENT_SRC_KHR
所有其它的布局都被认为是”不安全“的,因为它们可以被写入到tile写入路径之外的图像,这意味着签名元数据和实际颜色数据可能不同步。如果颜色attachment的布局和最终布局不同,签名缓冲区失效可能作为vkImageMemoryBarrier, vkCmdPipelineBarrier(),vkCmdWaitEvents()的一部分或作为vkRenderPass的一部分发生。
从UNDEFINED布局转换保留了图像的内存内容,因此从UNDEFINED布局转换本身不会让签名缓冲区失效,除非其它的触发效果需要它。
Do
▪ 对颜色attachment使用COLOR_ATTACHMENT_OPTIMAL图像布局
▪ 尝试对颜色attachment使用”安全“图像布局来避免签名失效
Don't
▪ 将颜色attachment从”安全“转换到”不安全“,除非算法需要这么做
Impact
▪ Transaction elimination失效将增加跨帧的静态区域场景的外部存储器带宽。这可能会降低内存带宽受限的系统的性能。
Debugging
▪ GPU性能计数器可以统计由于transaction elimination剔除的tile数量,因此你可以确定它是否被触发
Buffers
Robust buffer access
Vulkan设备支持robustBufferAccess的特性。当开启这一特性的时候,会向GPU缓冲区内存访问添加边界检查,确保不会出现越界访问。Mali GPU的边界检查不总是免费的;开启这一特性可能会带来性能的损失,尤其是对uniform缓冲区和着色器存储缓冲区的访问。
Do
▪ 使用robustBufferAccess作为开发期间的调试工具
▪ 当发行编译版本中禁用robustBufferAccess,除非应用用例中由于使用了用户提供的绘制参数,而确实需要额外级别的可靠性保证。
▪ 如果需要robustBufferAccess,为了Uniform buffer的性能使用push constants的方式。这样降低了每帧访问缓冲区的次数,这样需要的边界检查次数会变少。
Don't
▪ 开启robustBufferAccess,除非确实需要
▪ 开启robustBufferAccess,而没有关注性能影响
Impact
▪ 使用robustBufferAccess可能带来能够可衡量的性能损失
Debugging
▪ 通过对比两次跑测来验证性能影响 - 一个开启robustBufferAccess另一个关闭。
▪ robustBufferAccess特性是开发期非常有用的调试工具。如果你的应用存在崩溃或返回了DEVICE_LOST的错误,开启robust accesst特性,并观察问题是否结束了。如果不再有问题的话,说明有些drawcall或compute dispatch发生了越界访问。
Textures
Sampling performance
Mali GPU纹理单元可以花费可变的周期对纹理进行采样,具体取决于纹理格式和过滤模式。纹理单元的设计旨在为nearest和bilinear过滤(LINEAR_MIPMAP_NEAREST)提供全速的性能。
忽略数据缓存效果,需要额外周期的例子如下:
▪ 三线性(LINEAR_MIAPMAP_LINEAR)过滤:2x 消耗
▪ 3D格式:2x 消耗
▪ FP32格式:2x 消耗
▪ 深度格式:2x 消耗(Utgard/Midgard), 1x 消耗(Bifrost)
▪ 立方体贴图格式:每个面的访问 1x 消耗
▪ YUV格式:Nx 消耗,其中N表示旧的Mali GPU的纹理平面数量。第二代Bifrost架构内核(Mali-G51后)YUV的消耗是1x,与平面数量无关
举例来说,一个三线性过滤的RGBA8 3D纹理访问时间是线性过滤的2D RGBA纹理的4倍。
Do
▪ 使用可用的最低分辨率
▪ 使用可用的最小精度
▪ 对于静态资源使用离线纹理压缩,比如ETC,ETC2,或ASTC
▪ 对3D场景中的纹理总是使用mipmap来提升纹理缓存命中率和图像质量
▪ 选择性地使用三线性过滤如果你的内容纹理速率受限;它对于那些有着精细细节的纹理很有帮助,比如文字渲染
▪ 使用mediump采样器;highp采样器由于更宽的数据路径要求可能会更慢
▪ 考虑打包的32位格式,比如RGB10_A2或RGB9_E5,来取代fp16和f32纹理,如果你希期望更高的动态范围精度。
▪ 使用ASTC压缩模式扩展 - 如果可行的话 - 降低解压数据的准确性。这会显著提升过滤的性能以及Mali-G77之后的功耗。
Don't
▪ 使用超出所需的更宽的数据类型
▪ 对所有纹理都使用三线性过滤
Impact
▪ 加载了过多纹理数据的内容,由于缺失mipmap导致的稀疏采样,或者使用了更宽的数据类型,可能会导致纹理缓存的压力或通用外部内存带宽问题。
▪ 合理使用纹理压缩和mipmap的内容通常受限于过滤性能而不是外部内存带宽。只有当纹理单元是着色器的关键路径单元的时候才能看到一定的影响;如果着色器主要消耗在计算上,那么纹理过滤的消耗可能会被隐藏。
Debugging
▪ GPU性能计数器能够直接显示纹理单元的利用率,来确定你的程序是否受限于纹理过滤,以及外部带宽计数器可以监测到外部系统内存的流量。
▪ 尝试强制禁用三线性过滤来观测性能是否提升
▪ 尝试强制缩小纹理分辨率来观测性能是否提升
▪ 尝试使用更小精度的纹理格式来观测性能是否提升
Info
Mali的离线编译器可以显示相关功能单元使用的分析,这可以让你确定你的关键shader是否受限于纹理速率。但是,要注意离线编译器的纹理周期描述了每个像素1个周期的性能,因为编译器无法知道实际使用的sampler或格式精度。你需要基于纹理和sampler的使用情况手动推算纹理的性能。
Anisotropic sampling performance
最新一代的Mali GPUs支持了各向异性过滤,这允许纹理采样单元考虑三角形的朝向并决定采样使用的样式。这提高了图像质量,尤其是以相对于视平面陡峭的角度观察的图元,但需要额外的纹理采样成本。
以下图像显示了一个木质纹理的立方体,左边的图像使用传统的三线性过滤,右边的图像使用2x各向异性的线性过滤。可以观察到立方体右侧的面在使用各向异性过滤后有了明显的提升。

从性能的角度考虑,各向异性过滤的最差情况下的消耗是每个级都采样了最大的各向异性,这是由应用程序控制的,其中采样可以是线性的(LINEAR_MIPMAP_NEARESET)或者三线性(LINEAR_MIPMAP_LINEAR)。一个2x的双线性的各向异性过滤因此可以构成两次双线性采样。各向异性过滤的一个显著的优势是实际采样的数量可以基于当前样本下几何体的朝向动态减少。
Do
▪ 首先使用最大为2的各向异性来看是否满足质量需求。更高的数字会提升质量,但是更多数量的样本将提高质量,但收益增长会递减,通常不值得付出这样的成本
▪ 优先考虑2x双线性各向异性过滤,而不是各向同性三线性过滤;因为它的速度更快,并且能在高各向异性区域具有更好的图像质量。注意如果你切换到双线性过滤你可能会看到一些mipmap级别之间的一些接缝。
Don't
▪ 忽视性能而使用更高级别的各向异性;8x双线性各向异性过滤相比起简单的双线性过滤要花费8倍的时间。
▪ 忽视性能而是用三线性各向异性过滤;8x三线性各向异性过滤相比起简单的双线性过滤要花费16倍的时间。
Impact
▪ 使用2x双线性各向异性过滤而不是三线性过滤,这样可以增加图像质量并且提升性能
▪ 使用更高级别的各向异性会提高图像质量,但是也会明显降低性能
Debugging
▪ 为了调试纹理过滤的性能问题,首先完全关闭各向异性过滤并观测是否带来了性能提升。然后逐渐增加允许的最大各向异性的数量,并评估质量是否值得额外的性能成本。
Texture and sampler descriptors
Mali GPUs在控制结构缓存中缓存纹理和采样器的描述符,它们可以基于内容来存储可变数量的描述符。为了确保描述符条目的最大缓存容量,我们建议使用如下描述符设置:
Do
对于Vulkan来说,在填充VkSamplerCreateInfo结构的时候:
▪ 设置sampler addressMode(U|V|W)时使它们都相同(哪怕对于2D纹理addressModeW也和U以及V设置的一致)
▪ 设置sampler mipLodBias为0
▪ 设置sampler minLod为0
▪ 设置sampler maxLod为LOD_CLAMP_NONE
▪ 设置sampler anisotropyEnable为FALSE
▪ 设置sampler maxAnisotropy为1.0
▪ 设置sampler borderColor为BORDER_COLOR_FLOAT_TRANSPARENT_BLACK
▪ 设置sampler unnormalizedCoordinates为FALSE
以及在填充VkImageViewCreateInfo结构体的时候:
▪ 设置视图组件每个通道都设置为COMPONENT_SWIZZLE_IDENTITY或等效的逐通道映射
▪ 设置视图subresourceRange.baseMipLevel为0
需要注意的是,最大化描述符存储的要求与Vulkan规范推荐的为mipmapped纹理模拟GL_NEAREST和GL_LINEAR采样的方法相冲突。Vulkan规范指出:
Vulkan过滤模式并没有直接对应于OpenGL中缩小过滤器中的GL_LINEAR或GL_NEAREST,但可以使用SAMPLER_MIPMAP_MODE_NEAREST,minLod = 0, maxLod = 0.25和使用minFilter = FILTER_LINEAR或FILTER_NEAREST来模拟它们。
为了具有多个mipmap级别的纹理模拟这两种纹理过滤模式,同时还与紧凑采样器的要求兼容,一个推荐的应用程序行为是创建一个唯一的VkImageView实例,该实例仅引用级别0的mipmap,并使pCreateInfo的VkSampler.maxLodsetting为LOD_CLAMP_NONE,来遵循紧凑采样器的限制。
Info
使用imageLoad()和imageStore()在着色器程序中访问纹理(或者SPIR-V中的等效程序)不受此问题的影响。
Don't
▪ 把maxLod设置为纹理链中的最大mipmap级别;使用LOD_CLAMP_NONE
Impact
▪ 降低纹理过滤的吞吐量
sRGB textures
sRGB纹理由Mali GPU硬件原生支持;对于sRGB surface执行采样,渲染以及混合不会带来性能消耗。sRG纹理相比起不包含伽马矫正的格式在深度格式相同时,能够更好地感知颜色的分辨率,因此强烈建议使用。
Do
▪ 使用sRGB纹理来提升颜色质量
▪ 使用sRGB帧缓冲区来提升颜色质量
▪ 对于离线压缩纹理,ASTC压缩支持sRGB压缩模式
Don't
▪ 使用16位线性格式来获得更高颜色感知分辨率而不是使用8位sRGB
Impact
▪ 在适当的地方不适用sRGB会降低渲染图像的质量
▪ 使用更宽的浮点格式来替代sRGB会带来带宽的增加和性能的降低
AFBC textures
最近许多Mali GPUs支持了Arm的帧缓冲区压缩(AFBC),这是一种用于压缩GPU输出的帧缓冲区的无损图像压缩格式。对于应用程序来说AFBC是自动且透明的,但了解一些不能使用它的场合是有必要的,这可能需要驱动程序运行时解压缩,从AFBC回退到未压缩的像素格式。
Do
▪ 通过在shader中调用texture()访问函数访问之前由GPU作为帧缓冲区attachment渲染的图像和纹理,而不是ImageLoad(),这会触发解压缩。
▪ 当把数据压缩到颜色通道 - 例如,对于G-Buffer - 把精度最不敏感的位存储在最低有效位的通道能够获得最佳的压缩率。
Don't
▪ 使用imageLoad()或imageStore()来读写GPU之前作为帧缓冲区渲染的纹理或图像,和会触发解压缩
Impact
▪ 错误的使用会触发解压缩
▪ 使用更宽的浮点格式来替换sRGB会增加带宽而降低性能
Compute
Workgroup sizes
Mali Midgard和Bifrost GPU在每个着色器核中有一个固定数量的可访问的寄存器。并且可以根据着色器程序的寄存器的使用要求将这些寄存器拆分到可变数量的线程中。硬件可以在着色器核心资源调度期间分离和合并工作组,除非使用了屏障/共享内存,这种情况下,工作组中所有线程都必须在着色器核心中同时执行。
此时,较大的工作组大小会限制每个线程可用的寄存器数量,如果寄存器不足,会迫使着色器程序使用堆栈内存。
Do
▪ 使用64作为基线工作组大小
▪ 使用4的倍数作为工作组大小
▪ 尝试在使用较大的工作组前先使用更小的工作组,尤其是在使用屏障或共享内存时
▪ 当作用于图像或纹理时使用平方维度 - 如 8x8 - 利用最佳缓存位置
▪ 如果工作组具有逐个线程组的工作要完成,考虑将其分离2个pass来避免屏障和内核使得大多数线程空闲
▪ 计算着色器性能并不总是直观的
Don't
▪ 每个线程组使用超过64个线程组
▪ 认为小线程组的屏障是免费的
Impact
▪ 大的工作组可能会让着色器核心饿死,如果大部分比例的线程都在等待屏障的话
▪ 着色器溢出到堆栈可能会导致更高的加载/存储单元利用率,并且还可能带来更高的外部内存带宽
Shared memory
Mali GPUs并没有对计算着色器实现专用的on-chip共享内存;共享内存是由加载存储缓存支持的系统RAM,就像任何其它内存类型那样。
Do
▪ 使用共享内存在线程组中共享重要的计算
▪ 使得你的共享内存尽可能小,这样减少了破坏数据缓存的机会
▪ 降低数据的精度和宽度来降低所需共享内存的大小
▪ 记住你需要在使用共享数据的时候添加屏障;一些桌面端开发的着色器代码有时候会忽略屏障,但这是不安全的!
▪ 记住在使用屏障的时候小的工作组会更便宜一些
Don't
▪ 从全局内存拷贝数据到共享内存;这对于Mali GPUs来说是无用的并且通常会污染缓存
▪ 使用共享内存来实现以下形式的代码:
if(localInvocationID == 0) {
common_setup();
}
barrier();
//per-thread workload here
barrier();
if(localInvocationID == 0) {
result_reduction();
}
作为替代应该将问题划分为三个着色器,在common_setup()和result_reduction()使用更少的活动线程。
Impact
▪ 错误地使用共享内存带来的影响因应用程序而异
Debugging
▪ 分析共享内存性能通常是非常困难的;尝试使用不同的实现并对比性能影响
Image processing
一个常见的使用计算着色器的例子是图像后处理效果。片元着色器访问硬件中的固有函数特性可以加快速度,降低功耗,减少带宽,因此不应该轻易放弃这些优势。
对图像处理使用片元着色的优势是:
▪ 当使用varying变量时,纹理坐标可以使用硬件固有函数进行插值,这节省了着色器周期可以做一些更有用的工作负载
▪ 写出到内存可以使用tile-writeback硬件与着色器代码并行执行
▪ 不需要执行对imageStore()的坐标进行的范围检查,这可能会导致使用无法完全整除帧大小的工作组数量时出现问题
▪ 帧缓冲区压缩和转换消除(Transaction elimination)是可能的
对图像处理使用计算着色器的优势是:
▪ 对于一些算法,可以利用相邻像素之间的共享数据,避免额外的pass
▪ 每个线程更容易处理更大的工作集,避免额外的pass
▪ 对于一些复杂的算法比如FFTs,可能会需要多个片元渲染pass,通常可以合并到一个独立的计算着色器
Do
▪ 对于简单的图像处理更倾向于使用片元着色器
▪ 如果你足够聪明的话更倾向于使用计算着色器
▪ 更倾向于texture()而不是imageLoad()来读取只读的纹理数据;这对于前一帧片元pass绘制的AFBC纹理表现更好,并且更好地平衡了GPU管线的加载,因为texture()操作使用了纹理单元,而imageLoad\Store()使用了load/store单元,而这在计算着色器执行通用内存访问时非常重
Don't
▪ 在计算着色器中使用imageLoad(),除非你打算在调度中同时读写
▪ 使用计算着色器来处理片元着色器生成的图像;这会带来后向依赖并可能产生气泡(bubble),如果我们使用片元着色器来处理片元着色器生成的图像,渲染pass管线通常会更加清晰。
Impact
▪ 计算着色器相比起片元着色器,在处理简单的后处理工作负载上通常会更慢且功效更低,比如降采样、上采样以及blur
Shader Code
Minimize precision
对输入输出使用最小精度的数据,除了能够带来数据带宽的优势外,Mali Gpus还对shader core寄存器文件和运算单元中支持了低精度数据处理。对计算机图形学使用16位精度通常非常好,尤其是在从片元着色器中计算输出颜色的时候。
ESSL以及Vulkan GLSL都支持了使用mediump关键字标记变量和临时量为低精度的。对Mali GPUs来说使用lowp关键字并不会带来收益;它和mediump是一致的。
Do
▪ 当结果精度可接受时使用mediump
▪ 可行的话对输入,输出,变量以及采样器使用mediump
▪ 对于角度使用-PI到PI的范围而不是0到2PI;这对mediump变量能带来有效的精度收益,因为利用了浮点的符号位
Don't
▪ 在桌面GPU测试mediump精度的正确性;它们通常会忽略mediump并将其视为highp,因此你通常不会看出任何不同(功能或性能)
Impact
▪ 使用fp32全精度会影响性能和功耗
Debugging
▪ 尝试对除了gl_Position以外的所有东西强制mediump,来观测会带来多少帮助
Vectorize code
Mali Utgard和Midgard GPU架构实现了SIMD数学单元,将向量指令放到每个线程来计算;Mali Bifrost GPU架构转向scalar数学指令集,但依旧实现了向量化的内存访问。
Do
▪ 在你的着色器中写向量计算代码来获得Mali GPUs上最佳性能。随着Bifrost架构的引入这显得没那么关键了,但对于Utgard和Midgrad架构来说还是很有帮助的。
▪ 编写计算着色器时确保有足够的工作项工作在向量执行单元上。
Don't
▪ 写标量的代码并期望编译器进行优化;它通常会优化,但这基于输入的数据也是以向量的形式
Vectorize memory access
Malid GPU着色器核心加载/存储缓存具有一个较宽的数据路径,可以在一个时钟周期返回多个值。对于像计算着色器这样对底层内存提供了更直接访问的着色器程序,对数据的向量访问从而从数据缓存获得更高的访问带宽是十分重要的。
Do
▪ 在单一线程中使用向量数据类型进行内存访问
▪ 对于Bifrost GPUs这样同时运行四个相邻线程 - 称作quad - 在锁步中,跨四个线程重叠或顺序内存范围访问可允许负载合并
Don't
▪ 尽可能避免标量加载
▪ 尽可能避免跨线程quad访问不同地址
Impact
▪ 许多常规计算着色器运行比较轻量级的计算,而使用较大的数据集,正确的内存访问可以带来系统的显著提升。
Manual optimization
着色器编译器可能无法安全的执行在现实数学中合法的代码变换,因为它们可能会导致无穷大的浮点数或NaN的出现,这在源程序中无法体现,因而带来渲染错误。在可能的情况下离线重构源代码以减少所需计算量,而不是依赖编译器优化;它可能无法按照预期优化。
Do
▪ 根据你的知识重构源码尽可能的手动优化
▪ 如果图形对结果准确度要求不高可以使用近似来重构,比如(A*0.5)+ (B*0.45)可以近似为(A + B) * 0.5来节约一个乘法的计算
▪ 如果可行的话使用内置的函数,在多数例子下硬件实现相比起手写的着色器代码会更加快/功耗更低。
Don‘t
▪ 在自定义着色器代码中重写内置函数
Impact
▪ 由于低效的着色器程序降低了性能
Debugging
▪ 使用离线Mali编译器来测量着色器代码改变的影响,包括分析程序的最短和最长路径
Instruction caches
着色器核心指令缓存是我们在考虑影响性能的因素中通常会忽略的区域,但是由于同时运行的线程数量这可能会成为需要注意的比较重要的一部分。
Do
▪ 倾向于使用更多线程的最短的着色器,而不是使用更少线程的更长的着色器,更短的程序在缓存上通常是激活状态
▪ 倾向于没有流程控制分支的着色器,这会降低局部性并提升缓存压力
▪ 注意片元着色器会在一个tile上有很多可见层;未被early-zs或FPK剔除的所有层上的着色器必须被加载和执行,这会增加缓存压力
Don't
▪ 过于激进的展开循环,尽管一些展开会有帮助
▪ 从相同的源代码生成重复的着色器程序/二进制文件
Debugging
▪ Mali离线编译器可以用于静态分析对于任意Mali GPU生成的程序的大小
▪ Mali图形调试器可用于单步查看逐个drawcall并且可视化在渲染pass中创建多少透明层
Uniforms
Mali GPU可以将来自API的uniform和Uniform buffer提升到着色器核心寄存器中,这些寄存器会在每次绘制时加载一次,而不是每个着色器线程加载一次。这减少了着色器程序大量的加载操作。
并不是所有的uniform都能被提升到寄存器。动态索引的uniform,比如非常量访问的数组下标,无法被提升为寄存器映射的uniform,除非编译器能够将其识别为常量 - eg.使用Unroll来提供固定次数的迭代。
Do
▪ 保证你的Uniform数据足够小,128字节是一个比较好的经验数值,它可以确保uniform在任意给定着色器中被提升到寄存器
▪ 使用#define来将uniform提升到编译期常量(OpenGL ES)或专用常量(specialization constants, Vulkan),或者着色器中静态的字面常量
▪ 避免Uniform中向量/矩阵使用用于计算的常量数据来padding,比如总是0或1的数据
▪ 更倾向于使用glUniform*()(OpenGL ES), 或push constants(Vulkan) 来设置Uniform,而不是从缓冲区中加载Uniform
Don't
▪ 动态从Uniform数组中索引
▪ 过度使用实例化;使用gl_InstanceID来索引的实例Uniform是一种动态索引,因此无法使用寄存器映射uniform
Impact
▪ 寄存器映射的uniforms相当于免费的;任何溢出到内存的缓冲区都会增加每个线程Uniform获取的load/store消耗
Debugging
▪ Mali离线编译器提供了uniform寄存器使用的数量的分析,以及生成的load/store数量
Uniform sub-expressions
一个常见的低效的来源是着色器代码中uniform sub-expressions;它们是一段仅依赖于字面量或其它uniform的值的代码,会对所有的调用产生相同的结果
Do
▪ 最小化uniform-on-unifom或uniform-on-literal计算的数量;在CPU上计算uniform sub-expression最终的结果并传输到uniform中
Impact
▪ Mali GPU驱动可以优化大多数uniform sub-expressions的消耗,因此它们在每个绘制中只会计算一次,因此看起来的影响不会太大,但是这些优化依然会对每个drawcall产生小的影响,这可以通过删除冗余的数据来避免。
Debugging
▪ 使用Mali离线编译器来测量着色器代码改变带来的影响,包括分析程序中最短和最长路径
Uniform control-flow
一个常见的低效来源是条件控制流,例如if或者for的使用,这可以用Uniform表达式来参数化。
Do
▪ 对所有控制流使用编译期#defines(OpenGL ES)或专用常量(specialization constants, Vulkan),这可以完全移除无用的代码段和静态展开的循环。
Don't
▪ 使用Uniform值参数化的控制流;反之,为每个需要特定路径的材质使用特化的shader
Impact
▪ 低效的shader程序会降低性能
Debugging
▪ 使用Mali离线编译器去衡量shader code改变带来的影响,包括分析程序中最短和最长路径
Branches
分支在GPU上非常昂贵,因为它要么限制了编译器把指令组打包到一个线程,要么在多个线程之间存在分歧的时候引入跨线程调度限制。
Do
▪ 最小化着色器程序中复杂分支的使用
▪ 最小化在相邻着色器线程之间不同的控制流量
▪ 使用min()/max()/clamp()/mix()函数来避免小的分支
▪ 检查分支对计算带来的收益 - eg.跳过距离相机超过阈值距离的灯光 - 在许多情况下会计算的更快
Don't
▪ 实现多个昂贵的数据路径,并使用mix()来选择结果;分支可能是这种情况下最小化重复开销的最好解决方案
Impact
▪ 由于低效的着色器程序带来的性能损失
Debugging
▪ 使用Mali离线编译器来测量着色器代码改变带来的影响,包括分析程序中的最短和最长路径
Discards
在片元着色器中使用discard或者使用alpha-to-coverage(实际上是隐式的discard),通常用于实现对诸如植被和树的复杂形状进行alpha测试。
这些技术强制片元使用late-zs更新,因为它们需要保留管线的片元操作阶段,直到着色完成,因为我们需要跑完着色器来决定每个样本的discard状态。这既会导致冗余的着色器,又会导致由于像素依赖导致的管线饥饿。
Do
▪ 最小化着色器中discard和alpha-to-coverage的使用
▪ 在使用discard剔除灯光片元,对延迟着色解析灯光使用预计算的深度缓冲区时,禁用深度和模板写入
▪ 在开启深度测试的状态下从前往后渲染alpha-test几何体;这会导致尽可能多的片元early-z测试失败,最小化late-z更新的数量
Impact
▪ 由于额外的片元着色开销导致性能损失或带宽增加
▪ 由于管线等待像素依赖的解决导致的饥饿产生性能损失
Atomics
原子操作是许多计算(和一些片元)算法的主要内容,它允许许多串行算法在稍作修改的情况下在高度并行的GPU上实现。原子的基本性能问题是竞争,来自不同着色器核心的原子操作命令了相同的缓存行,会需要通过L2缓存来确保数据一致性,这是非常昂贵的。
使用原子操作的性能良好的计算着色器应该旨在通过原子操作保持在单个着色器核心本地来分散竞争。如果着色器核心在L1中有必要的缓存行,那么原子操作会非常高效。
Do
▪ 在算法设计中使用原子的时候考虑避免竞争
▪ 考虑将原子量间隔64字节避免多个原子操作在同一缓存行上竞争
▪ 考虑是否可以通过累积到共享内存原子来分摊竞争,然后让一个线程在工作组的末尾推送全局原子操作
Don't
▪ 在多个pass可行的情况下使用原子操作
Impact
▪ 单个原子缓存条目的竞争会显著降低整体的吞吐量,并影响在具有更多着色器核心的GPU上运行时问题会被放大
Debugging
▪ GPU性能计数器包括用于监控来自系统中其它着色器核心的L1缓存检测频率的计数器。
System integration
Swapchain surface count
对于Vulkan来说应用程序可以控制窗口表面交换链,特别是决定应使用多少表面。几乎所有移动平台都使用vsync来防止缓冲区交换时的屏幕私立,这意味着如果GPU的渲染速度比vsync周期慢,则仅包含两个缓冲区的交换链很容易使GPU停滞。
Do
▪ 在交换链中使用两个表面,如果你的应用总是比vsync更快;这会降低内存消耗
▪ 在交换链中使用三个表面,如果你的应用总是比vsync更慢;这会带来最佳的应用性能
Don't
▪ 在应用总是比vsync慢的情况下,在交换链中使用两个表面
Impact
▪ 使用双倍的缓冲区和vsync会将渲染锁定为vsync速率的整数部分,如果应用程序的渲染速度低于vsync,这将降低性能;例如,在具有60fps面板刷新率的系统中,原本能以50fps运行的应用程序将快速降至30fps
Debugging
▪ 像DS-5 Streamline这样的系统分析器,可以显示GPU什么时候停滞。如果GPU处于空闲状态并且帧周期是vsync周期的倍数,则可能表示渲染阻塞并等待释放缓冲区是由vsync触发的。
Swapchain surface rotation
对于Vulkan来说应用程序可以控制窗口表面朝向,并处理窗口的逻辑方向(随着设备旋转在设备上可能发生变化)与显示器物理方向的差异。如果应用程序与显示面板物理方向窗口表面相匹配,则对于系统来说时更有效的。
Do
▪ 为了避免引擎转换pass,确保交换链preTransform与vkGetPhysicalDeviceSurfaceCapabilitiesKHR返回的currentTransform值相匹配
▪ 如果交换链图像采集返回SUBOPTIMAL_KHR或ERROR_OUT_OF_DATE_KHR,则重新创建交换链,同时考虑任何更新的表面属性,包括通过currentTransform的潜在方向更新。
Don't
▪ 假设除currentTransform外的引擎转换支持是免费的;许多表现引擎可以处理旋转/镜像,但需要额外的处理成本
Impact
▪ 非本地方向可能需要显示引擎中进行额外的转换,这可能需要在某些系统上使用GPU,这些系统使用GPU作为显示引擎的一部分,来处理控制器无法本地处理的情况
Debugging
▪ 像DS-5 Streamline的内核集成版本的系统分析器,能够将Mali GPU的使用归类到特定进程,这允许额外的GPU工作负载归类到合成器进程,假设合成器正在使用GPU对应用执行转换
Swapchain semaphores
Vulkan典型的一帧如下:
▪ 在帧获取的开始创建一个VkSemaphore(#1)
▪ 在帧释放的结束创建一个VkSemaphore(#2)
▪ 调用vkAcquireNextImage()返回#N的交换链下标,且与信号量#1相关
▪ 交换链下标#N等待所有fence
▪ 构造command buffers
▪ 提交command buffers用于窗口表面渲染到vkQueue,并告知它们在渲染开始前等待(#1),并在完成的时候发起信号(#2)
▪ 调用vkQueuePresent(),确保等待信号量(#2)
这其中的关键部分是为任何command buffers设置等待(#1),因为我们还需要指定哪些流水线阶段需要实际上等待WSI信号量。除了pWaitSemaphores[i], 还有pWaitDstStageMask[i],该掩码指定了哪些流水线阶段需要等待WSI信号量。
我们只需要使用COLOR_ATTACHMENT_OUTPUT_BIT等待最终的颜色缓冲区,还需要在渲染时将WSI图像从UNDEFINED或PRESENT_SRC_KHR布局转换为不同的布局。此布局转换会等待COLOR_ATTACHMENT_OUTPUT_BIT,它会创建信号量依赖链。
Do
▪ 使用pWaitDstStageMask=COLOR_ATTACHMENT_OUTPUT_BIT用于等待WSI的信号量
Impact
▪ 由于vertex/compute的停止,将产生大的管道气泡(bubbles)
Window buffer alignment
如果行未充分对齐,线性格式帧缓冲区的写入性能可能会显著降低。为了确保高效的写入性能,导入到Mali驱动程序中的内存系统分配表面应对齐,以便16x16tile中每一行都可以作为单个AXI突发事务写入。
Do
▪ 在线性格式的帧缓冲区中使用要么16像素的倍数或64字节(会更小)作为行的最小对齐值;eg.对于RGB565的帧缓冲区你可以使用32字节对齐,对于RGBA8和RGBA fp16帧缓冲区你可以使用64字节对齐。
▪ 使用2的幂次格式比如RGBX8包含冗余的通道,而不是不含alpha通道的RGB8,这具有更好的内存对齐属性。
Don't
▪ 使用除了16像素的倍数或64字节之外的行对齐量
▪ 使用非2的幂次的帧缓冲区格式,比如24bit RGB8
Impact
▪ AXI突发必须与突发大小对齐,未对齐的行必须分成多个较小的AXI突发才能满足需求,这将降低内存总线的使用效率,并且在许多情况下会导致GPU停滞,因为它耗尽了可用事务ID池。

















 9949
9949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









