









前言
后缀数组是个十分有用的东西,上一年就学过,结果又还给pdf了,如今再看一遍,好懂很多。
怎么说呢,get了height后,SA能解决很大一部分字符串问题。
后缀是什么大家都知道···
sa[i]表示第i小(大)后缀是哪里开头的后缀
rank[j]是是第j个后缀的排名
弄出SA数组
(DC3好恶心,学倍增实现!)
后缀数组关键就是要弄出后缀数组嘛。
我们现在有一个字符串r,好我们把它弄成int的x数组。
设j表示当前我们针对每个位置为开头,j个位置后结束的后缀进行处理,最后那些后面没有j个字符的后缀我们统统设没有的是最小的字符。
倍增的主要想法是用目前的针对长度为j的后缀得到的排序,更新长度为2*j的后缀。如图。
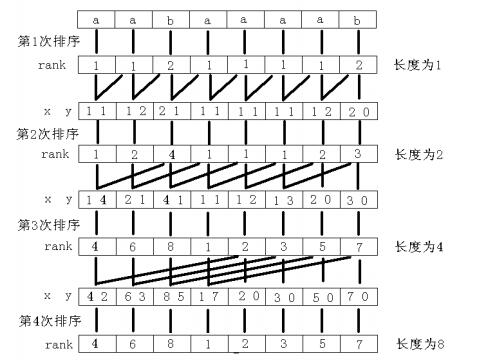
看了一下图,有没有联想起一些用来打牛奶的东西~~~那就是桶了。
对,基数排序,两个关键字!
好难讲啊···贴个get sa的代码
·C++
并没有···
·Pascal
procedure getsa(n:longint);
var
i,j:longint;
begin
for i:=1 to 256 do ws[i]:=0;
for i:=1 to n do inc(ws[x[i]]);
for i:=1 to 256 do ws[i]:=ws[i-1]+ws[i];//刚开始每一个字母ASCII码的范围小于等于255
for i:=n downto 1 do
begin
sa[ws[x[i]]]:=i;
dec(ws[x[i]]);
end;
j:=1;
while j<=n do
begin
p:=0;//j为前一次排序后缀的关键字长度
for i:=n-j+1 to n do
begin
inc(p);
y[p]:=i;
end;//这些后缀的后j长度组成的串都爆掉了n
for i:=1 to n do
if sa[i]>j then
begin
inc(p);
y[p]:=sa[i]-j;
end;//y数组:储存每个后缀以后j长度为关键字的从小到大位置,位置是整个字符串的开始位置
for i:=1 to n do wv[i]:=x[y[i]];//x数组:储存每个后缀以前j个长度为关键字的排名(可能会有重复)
for i:=0 to n do ws[i]:=0;
for i:=1 to n do inc(ws[wv[i]]);
for i:=1 to n do ws[i]:=ws[i-1]+ws[i];
for i:=n downto 1 do//y数组是已经按照之前的次序排过序了,也是按顺序放入wv中,n downto 1使得之前的某些顺序性质在后来能继续维护
begin
sa[ws[wv[i]]]:=y[i];
dec(ws[wv[i]]);
end;//以每一个后缀的后j长度为关键字排序,SA以按第二关键字排序
y:=x;//重新计算x数组
p:=1;
x[sa[1]]:=1;
for i:=2 to n do
begin
if (y[sa[i-1]]<>y[sa[i]])or(y[sa[i-1]+j]<>y[sa[i]+j]) then//SA使满足s[i]<=s[i+1],先比较前j关键字是否相等,否则比较后j关键字
inc(p);
x[sa[i]]:=p;
end;
j:=j*2;
end;
end;一开始的桶排都没有问题吧···
为什么要n downto 1?其实这里并不需要,因为只有一个关键字,第二个还没出来···
好了get出j=1时的sa了,当然,对于j=n来说,他是不大准确的。
好了进循环,我们准备开始弄j=2的sa数组了。
y数组是为了成为j=2时的排序第二关键字而,根据j=1时的sa数组改动的。
我们看改动了些什么,把当前、后面没有东西的后缀赋为最小,以及把原来sa数组记录的位置提前了j。
没忘掉原来的x吧,这里他做临时rank用了。注意,他不会像临时sa一样使本来较大的排在较小的前面,他只会把他们弄成同样的排名。
看着一句for i:=1 to n do wv[i]:=x[y[i]]; 成功以y为关键字的x数组排了个序,存进wv里面。
然后又是基数排序。注意,这里的n downto 1就有用了,因为考虑了第二关键字。
现在,我们弄出j=2的sa了,更新x数组。
值得注意的是这句话x[sa[1]]:=1; 因为sa[1]是不可能有比他大的,至少对于目前j=2的情况是这样。然后后面的更新谁都懂了。
弄完一次,j*2,继续弄到n为止。
弄出height数组
height[i]就是sa[i]与sa[i-1]的公共前缀的大小。先发散思考一下height的一些周边性质~~~
一般来说,弄出sa数组很麻烦,而一般只弄他并没有卵用,他只是为了我们getheight做准备;height不难弄,用处却很大。
考虑方法····
暴力?O(
n2
)那还用什么倍增求sa啊···这里复杂度这么大
所以我们考虑一些别的东西。
设f[i]=height[rank[i]],则f[i]>=f[i-1]-1;
证:设suffix(k)是排在suffix(i-1)的前一名后缀,那么他们最长公共前缀是f[i-1]。那么显然suffix(k+1)排在suffix(i)的前面(不一定是前一名,有可能有别的后缀参和进来)。所以,f[i]起码有f[i-1]-1的大小(因为向后推进了一位所以减一)。
按照f数组的顺序来求height,我们可以O(n)得height。求的时候不需要求f,只需要按位置顺序求height就好了。
procedure getheight;
var
i,j:longint;
begin
k:=0;
for i:=1 to n+1 do rank[sa[i]]:=i;
for i:=1 to n do
begin
if k>0 then k:=k-1;
j:=sa[rank[i]-1];
while (r[i+k]=r[j+k])and(j+k<=n)and(i+k<=n) do inc(k);
height[rank[i]]:=k;
end;
end;
一些题目
还没做呢,做过一些也忘了,后面再补。
后记
刚学会的算法要多练,不在计算机旁要用脑子想,想关于算法的什么都好。感性理解不要太多,否则记不住。
学算法嘛,最好赶紧学完,不要学学停停,很容易忘掉前面内容的,到时候学完了再巩固也不迟。趁寒暑假要多干点事。其实一个小组进行学习讨论会更高效。















 4589
4589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









