







Name: Autonomous reinforcement learning agent for stretchable kirigami design of 2D materials
DOI: https://doi.org/10.1038/s41524-021-00572-y
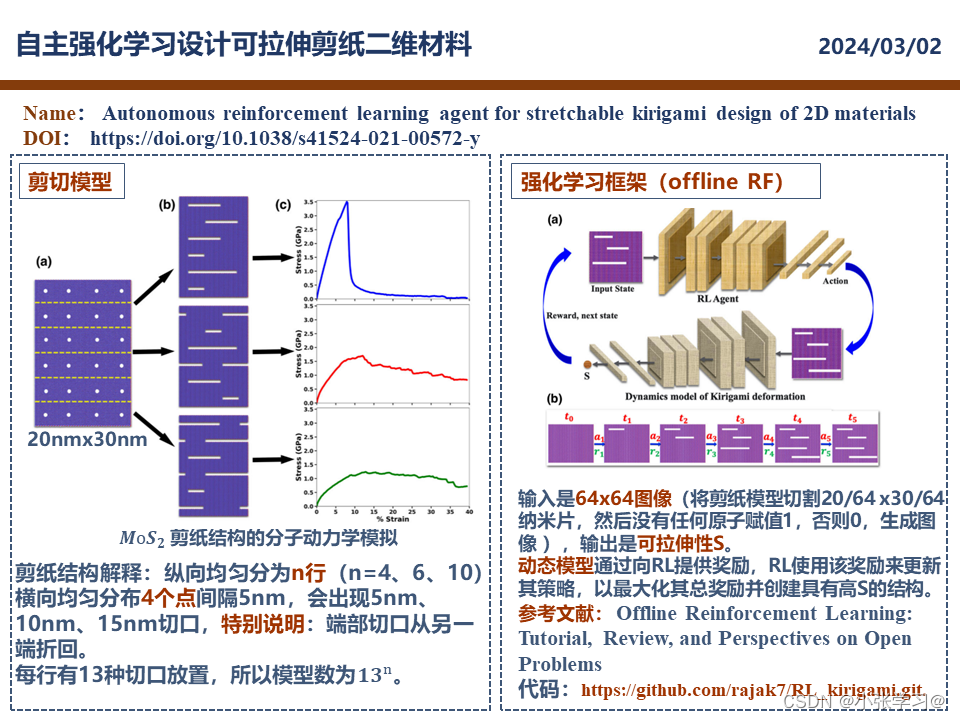
Name: Autonomous reinforcement learning agent for stretchable kirigami design of 2D materials
DOI: https://doi.org/10.1038/s41524-021-00572-y

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


























