










可计算人格分析的综合话语数据集
A Data Set of Synthetic Utterances for Computational Personality Analysis
摘要
人类人格的计算分析主要集中在五大人格理论上,尽管心理动力学方法具有丰富的理论基础和与各种任务的相关性,但它几乎不存在。在这里,我们提供了4972个合成话语的数据集,与心理动力学方法描述的大五人格维度相对应:抑郁、强迫症、偏执、自恋和反社会精神变态。这些话语是通过人工智能产生的,具有深刻的理论方向,激发了GPT-4提示的设计。该数据集已经通过14个测试进行了验证,它可能与人类人格的计算研究和数字领域中真实人格的设计有关,从游戏到电影角色的艺术生成。
1 背景和总结
人类的人格涉及到相对稳定的思维、情绪和行为模式。它们是将这些模式减少到几个维度的不同方法。例如,最流行的人格理论,“大五”考虑了人类人格的重要维度,如外向性和神经质。
不同的计算工具来分析人类人格主要依赖于这一理论。与五大方法相比,精神动力学方法是在临床环境中理解人格类型的主要理论方法,如精神动力学诊断手册(PDM)和Shedler Westen评估程序(SWAP)。然而,PDM强调,它的目标是代表不同的“类型”的人,与DSM相比,它不是一个疾病的分类。一个人可以被描述为自恋者,而没有病理或障碍。在本文中,我们使用心理动力学的方法作为一个人格理论来建立一个代表大五人格类型的话语数据集。该论文的目的仅限于一个数据集的构建和验证,而任何临床意义都超出了该论文的范围。
人格的心理动力学方法强调人类人格的多维结构,以及无意识过程和内在矛盾在塑造人格和行为中的作用。 例如,抑郁人格有几个维度:假设的贡献成熟模式(例如,抑郁的遗传倾向),这种人格类型背后的中心紧张感(例如,自我批评),描述人格的中心情绪(例如,悲伤),对自我和他人的信念(例如,我是一个失败者,其他人不喜欢我),以及人格使用的中心防御机制(例如,自我贬值)。换句话说,当描述抑郁的人格,心理动力学方法描述它的主要矛盾潜在的人格,情感伴随这种紧张,自我和他人的表现,和主要的心理防御机制用来应对压力伴随他的自我和他人的经验。
通过心理动力学方法对人格进行评估,几乎仅限于临床环境和人类专业知识的使用。通过心理动力学方法评估人格的最结构化的工具是SWAP-200:SWAP-200的核心,是一组200个项目,描述了各种人格特征、态度和行为。临床医生根据他们的观察结果和与客户的互动对这些项目进行评分。换句话说,这个工具严重依赖于人类的专业知识和精心选择的项目的存在。目前,没有一种结构化的、自动化的工具可以使用心理动力学方法从自由文本中提取人格类型。我们再次强调,本文中提出的数据集不是一个用于临床设置的诊断工具,如SWAP-200,而是一个表达大五人格维度的话语数据集。这个数据集是为有兴趣在文本数据中测量这些人格维度的研究人员设计的。
由于其复杂性,心理动力学方法很少被用于计算人格分析。它在计算领域的表示不足可能是由于尽管它有深刻的理论基础和对各种任务的相关性,但它缺乏实质性的数据集。然而,使用心理动力学方法可能与各种任务相关。例如,**革命性的大型语言模型(LLMs)可以模仿不同人的思维、感觉和行为。这种新技术可以用来建立在对话中坚持对话者个性的对话代理。**一个被描述为高度自恋的顾客可能比一个被描述为高度痴迷的顾客更容易被接近。目前,我们缺乏一个根据心理动力学方法表达不同人格类型的实质性话语数据集,而目前的论文旨在弥补这一差距。
这篇论文提供了一个高质量的合成话语数据集,对应于五大人格类型:抑郁(DEP)、强迫症(OBS)、反社会精神病(PSY)、偏执狂(PAR)和自恋(NAR)。我们决定关注这些五大人格类型主要有两个原因。首先,一些人格类型,如焦虑回避和抑郁,彼此更接近,不容易分化。我们决定专注于几种典型的人格类型。其次,我们的项目不是心理学项目,而是计算科学项目,因此,我们主要通过使用机器学习分类模型来测试我们的数据集的质量。将话语分类为越来越多的类别(例如,人格类型)可能会导致模型的表现的急剧下降。因此,我们将目前的项目仅限于研究人格类型。
此外,对于每一个话语,我们提供了五大PDM维度的详细描述: (1)在话语中表达的主要心理动力学主题(例如,与权威相符),(2)完美(例如,深度悲伤的表达),(3)对自我的信念(例如,我是做几乎任何事情的电缆),(4)对他人的信念(例如,人不能被信任),以及(5)防御机制(例如,情感超然)。这是同类数据中最早的数据集,可能与许多研究人员高度相关,从那些处理计算心理学的人到那些为游戏产业或社会辅助机器人开发对话代理和人工角色的人。该数据集可以用于人格研发的一些方法有:
-
- 为游戏产业创造一个数字角色(例如,为“坏人”创造一个真正的精神变态人格)。
-
- 分析老年人对话以确定抑郁症状及其动态的代理。
-
- 自动分析家庭治疗,为治疗师提供一个在线实时分析工具。
2 方法
2.1 生成角色
生成表达不同性格类型的话语绝非易事。直接要求 AI 生成话语而没有具体指示可能会导致生成夸张和不具代表性的话语。**为了避免夸张的性格表达,我们认为生成一系列虚构的角色(即人物)来产生这些话语非常重要。**这一步骤对确保表达特定性格类型的话语包含最佳语言多样性至关重要。因此,过程的第一步是生成不同的人物角色,即产生话语的虚构主体。为了解决这一挑战,我们选择了几个生成话语人物的一般维度,如性别、职业和年龄。这些选定的维度被假设为能够产生同一性格的不同表达方式。例如,一个35岁的男性高科技公司首席执行官可能会以不同于90岁祖母的方式表现出自恋性格。
为了解决这一挑战,我们使用了GPT-416(API版本GPT-4-0613)和以下提示:
[生成人工角色]
生成100个独特的美国英语使用者,每个使用者由以下八个维度的不同组合来代表:性别、年龄(16-80岁)、文化身份、社会经济地位、教育水平、家庭状况、职业和个人身份。
确保在这些维度上具有多样性。


2.2 生成数据集
在第二阶段,我们使用人物角色列表和下面的提示符模板来生成表达不同人格类型的话语。在这里,我们提供了一个模板:
[生成表达性格类型的人造话语]
总结陈述:[在此部分,我们插入了性格类型的简短描述]
(在此部分,我们插入了性格类型的更详细描述)。
你的任务是生成五个不同的话语,其中人物表达出[性格类型]。确保使用的语言准确反映人物的:

以下是对这个角色的描述:[在这里我们插入了对这个角色的描述]。
我们在每个100个人工角色上运行了该提示。结果是一个包含5000个话语的列表,代表上述五种性格类型。在完成论文中提到的所有过程后,我们删除了重复项,最终文件包含4972个话语。每个话语都标有五种性格类型之一的标签。
以下是为以下人物生成的三个话语示例:
- 女性,84岁
- 低收入阶层,高中学历
- 寡妇,农民的妻子
- 非裔美国家庭主妇。

3 数据记录
数据记录包含多个文件。所有文件都是结构非常简单的CSV文件。文件包括:
(1) 100个人物角色列表
(2) 包含性格类型、话语和相关数据的文件。链接中还包括运行SetFit模型的代码。
4 技术验证
技术验证部分包括几个验证测试,以支持数据集的质量。测试分为以下几个类别:
验证1。通过人类专家进行验证。
验证2。通过计算工具进行验证。
验证3。通过机器学习模型进行验证。
验证4。扩展话语的生态有效性。
4.1 人类专家的验证
如果合成的话语有效地代表了它们背后的人格类型,那么在话语的标签和专家人类注释者的决定之间应该达成一致。
我们选择了100个话语,每种性格类型代表20个话语。这些代表性话语是从那些在性格类型评分中最高(见验证2)且在其他评分中最低的话语中随机选择的。接下来,我们使用两位独立专家/注释者来确定哪种性格类型最能描述这些话语。这两位注释者(“A”和“N”)是两名研究生,他们完成了一年的性格分析和剖析课程。该课程涉及分析文本数据的专项培训,“A”和“N”都以优异的成绩完成了课程。每位注释者随机顺序接收到这100个话语,并附上以下指示:

在附带的Excel电子表格中,你会找到100个话语。每个话语都表达了五种性格类型之一。对于每个话语,选择最能描述它的性格类型。使用以下缩写来写出性格类型的名称:DEP、PSY、PAR、NAR 和 OBS。
专家的注释与“黄金标准”进行了对比测试,即用于生成话语的性格类型(即标签),以及彼此之间的对比测试。
专家注释之间的关联在统计上具有显著性(Χ²=360.25,p<0.001),表示他们之间几乎完全一致。他们在95%的情况下达成了一致。每位注释者与黄金标准之间的关联也被发现具有统计显著性,“A”(Χ²=386.32,p<0.001)和"N"(Χ²=369.31,p<0.001)。这些结果验证了话语的质量及其代表性格类型的程度。
4.2 通过计算工具验证话语
假设这些话语有效地代表了人格类型。在这种情况下,话语的标签和由不同的计算工具给出的话语的标签之间应该达成一致。为了检验收敛效度的假设,我们使用了LangChain和GPT-4的两个检验。
测试2.1
我们使用的第一个工具是LangChain,它是“一个用于开发由语言模型驱动的应用程序的框架。它使得应用程序能够
(1)具有上下文感知能力:将语言模型连接到上下文来源(提示指令、少量示例、内容依据等),
(2)进行推理:依靠语言模型根据提供的上下文进行推理(关于如何回答、采取什么行动等)。”我们使用LangChain生成每个话语的对话式和逐步评估。参见以下提示:
提示
用户:我给AI的任务是生成表达[性格类型]性格的合成话语。
这是生成的话语:“[话语]。”
请提供您对AI生成的话语的总体评估。根据心理动力学诊断手册(PDM)和SWAP,它是否真实地表达了[性格类型]性格?
请以YES或NO的形式提供一个简单明了的回答。
ChatGPT响应:[响应]
**
现在,根据个性的PDM(心理动力学诊断手册)维度来评估这个话语:主题或关注点、情感、对自我的信念、对他人的信念以及主要的防御机制。生成维度标题,然后进行评估。
ChatGPT Response
用户:请在1到5的评分尺度上提供一个数字评分,其中1表示‘完全不’,5表示‘非常’,以表达[性格类型]性格特征在给定话语中的程度。
ChatGPT:一个单一的数字评分。
根据这个过程,我们为文件生成了几个额外的列。首先,AI是否同意我们评估的合成话语表达了它们所代表的性格类型(YES或NO)。其次,话语在表达其所要表达的性格类型方面的程度(1-5)。
如果合成话语有效,我们应该期望原始标签和LangChain生成的标签之间的一致性。结果支持假设:LangChain的结果显示,在97%的情况下,话语表达了DEP性格类型;在98%的情况下表达了NAR性格类型;在63%的情况下表达了OBS性格类型;在99%的情况下表达了PAR性格类型;在65%的情况下表达了PSY性格类型。
4.3 通过机器学习模型验证
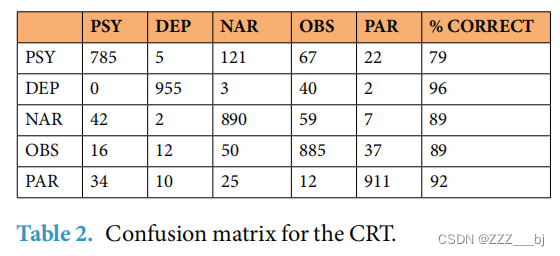
我们假设,如果这些话语有效地代表了不同的个性,它们就可以用于训练和测试机器学习分类器。提出这一假设的原因如下。机器学习模型在数据集上进行训练来识别模式。在我们的案例中,这种模式涉及到由话语所表达的不同的性格类型。模型的成功是通过根据学习阶段学习的模式来分类新话语的能力。如果话语是高质量的,那么我们可以期望模型成功地学习模式,我们使用了三个机器学习模型来测试假设: CRT,SetFit和RoBERTa。
4.4 通过各种数据集和间接测量进行验证
我们进行了几项间接测试,以检验话语的生态有效性。
测试4.1
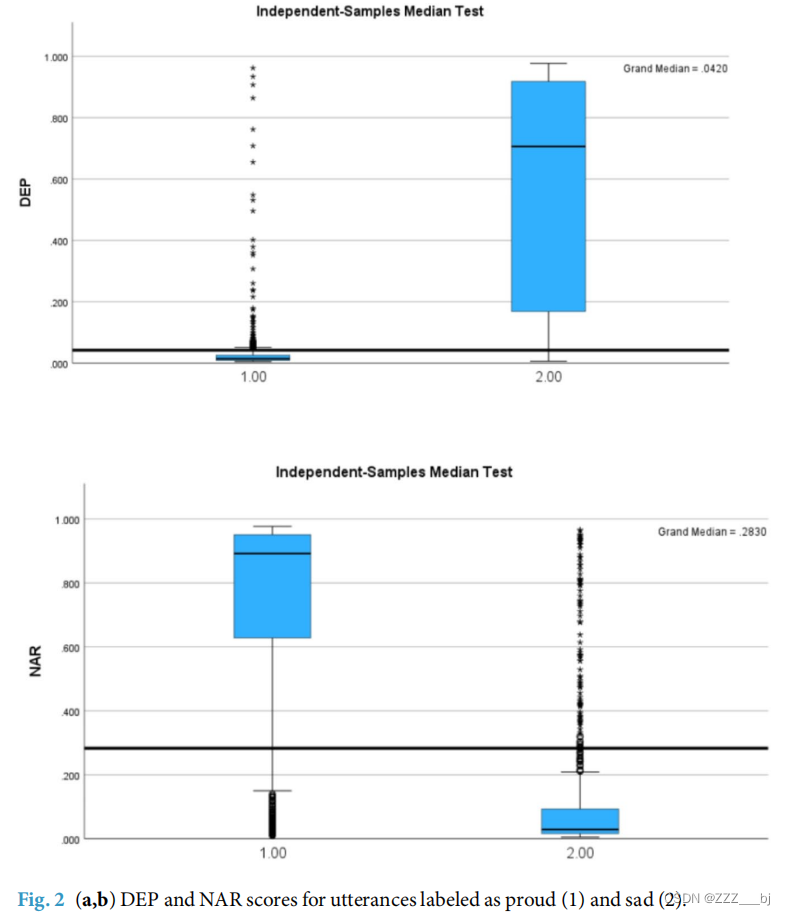
我们使用SetFit模型分析了EmpatheticDialogues数据集,这是一个大规模的多轮对话数据集,包含话语及其情感。首先,我们关注标记为“骄傲”和“悲伤”的话语。我们选择了667个标记为“悲伤”的话语和686个标记为“骄傲”的话语。接下来,我们使用先前训练的SetFit模型来分析“骄傲”和“悲伤”的话语。我们假设“骄傲”的话语应表达更高水平的自恋性格,而“悲伤”的话语应表达更高水平的抑郁性格。如果这一假设有实证依据,那么SetFit模型对“骄傲”话语给出的自恋性格评分应高于“悲伤”话语,而“悲伤”话语的抑郁性格评分应高于“骄傲”话语。验证这些假设可以进一步支持话语的质量,因为我们期望在高质量话语上训练的模型在其他情境中识别性格类型表达方面是有用的。
结果见图2a-b:
我们可以看到这些评分支持我们的假设。中位数检验在统计上具有显著性(p<0.001)。此外,使用Mann-Whitney U检验,我们发现“悲伤”话语的抑郁性格评分的平均排名高于自恋性格评分(分别为984.47对378.04),而“骄傲”话语的自恋性格评分的平均排名较高(分别为958.53对387.45)。这些结果支持了假设,并进一步验证了话语的质量。
5 代码可用性
https://doi.org/10.6084/m9.fgshare.24971943.v1
所有的文件都是简单的CSV文件。(1)100个人物角色的列表(2)包括人格类型、话语和伴随的数据。链接还包括运行SetFit模型的代码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









