










Adaptive Graph Learning for Multimodal Conversational Emotion Detection
摘要
对话中的多模态情绪识别(ERC)的目的是识别对话视频中每个话语所表达的情绪。在处理模态内交互时,当前的工作在平衡说话者内部和说话者间的上下文依赖关系方面遇到了挑战。这种平衡是至关重要的,因为它包括建模自我依赖(情感惰性),其中说话者自己的情感影响他们,并建模人际依赖(共情),其中同伴的情感注入说话者。此外,在解决跨模态交互问题时也会遇到挑战,因为不同模态的内容会产生相互矛盾的情绪。为了解决这个问题,我们引入了一种名为AdaIGN的自适应交互图网络(IGN),它使用Gumbel Softmax (重参数化技巧)技巧来自适应地选择节点和边,增强模态内和跨模态交互。与无向图不同,我们使用有向IGN来防止未来的话语影响当前的话语。接下来,我们提出了节点和边级选择策略(NESP)来指导节点和边选择,并提出了图级选择策略(GSP)来整合原始IGN和NESP增强IGN的话语表示。此外,我们设计了一个任务特定丢失函数,它优先考虑文本模态和说话者内上下文选择。为了降低计算复杂度,我们通过自监督的方法使用预先掩盖的伪标签来掩盖不必要的话语节点进行选择。实验结果表明,AdaIGN在两个流行的数据集上优于最先进的方法。
1. 介绍
对话中的情感识别(ERC)因其在推荐系统(Zheng等2022)、对话生成(Zhu等2022)等领域的有价值的应用而获得了相当大的关注。大多数关于ERC的研究主要集中在文本模态上,包括递归神经网络(RNNs)(majederetal.2019)、记忆网络(焦、柳,和王2020)和基于图的模型(saxenana、黄和黑东2022)。
尽管取得了进展,但与多模式感知相比,文本本身不能提供足够的更深层次感情的线索。现有的多模态ERC方法主要关注基于聚合的串联融合(图等2022b)、张量积(麦、胡、兴2019;刘等2018)、注意网络(拉赫曼等2020;Wang等2019)或异构图(Yang等2021;胡等2022)等。例如,Hazarika等人(2018)提出了一种会话记忆网络来从多个视图对齐特征。Lian、Liu和Tao(2021)引入了一种用于隐式增强的跨模态变压器。Hu等人(2021)探索了基于无向图的融合,以捕获模式内和跨模式的交互作用。
然而,它们在建模模态内和跨模态交互作用方面存在局限性: (1)未来的话语会影响当前话语的情绪检测。以往建模模态内交互的方法往往依赖于使用未来的话语来预测当前人的情绪。然而,这种方法在现实世界中是不实用的。(2)平衡同理心和情感惰性的差异性。对话中的情绪动态(Poria et al. 2019)涵盖了两个主要方面:自我依赖(情感惰性),即说话者自己的情绪影响他们,以及人际依赖(同理心),即说话者的情感被他们的同伴注入。在共情和情感惰性之间取得正确的平衡,对于建模模态内交互作用是一个重大的挑战。这种平衡从根本上包括协调说话者之间和他们内部的上下文。如图1所示,识别话语8背后的情感需要为说话者内部的上下文分配更大的意义(话语4、6等)。而不是说话者之间的上下文(话语5、7等)。不幸的是,以前的研究忽略了这两种背景之间的平衡。(3)多模态信息包含了具有歧义情感的内容。 在建立跨模态交互模型时,某些语句会在不同模态中表现出相互矛盾的情绪。如图 1 所示,第 2 个语句通过擦拭眼泪直观地表达了悲伤的情绪,而文本本身则显得毫无感情色彩。现有的研究尚未提供解决这种差异的方案。

为了解决上述问题,我们提出了一种新的自适应交互图网络(IGN),称为AdaIGN,它由节点级和边级选择策略(NSP和ESP,统称为NESP)以及图级选择策略(GSP)指导。IGN是一个有向图,以防止未来的话语影响当前的话语。为了与网络权值联合优化这些策略,我们使用了标准的反向传播和Gumbel Softmax 技巧(Jang、Gu和Poole 2016)。具体地说,NSP被用于在一个话语中选择跨多种模态的节点。ESP能够在同一模态中选择每个节点的不同上下文边(包括说话者之间和说话者内部上下文)。GSP通过在图的层次上选择话语表示来整合这两个图。此外,我们引入了一个基于keep或drop策略的任务特定损失函数,优先选择文本模态和说话者内部上下文,以满足ERC任务。为了降低计算复杂度,我们利用通过自监督方法生成的伪标签来掩盖不必要的话语节点进行选择,并冻结其相应的选择策略的梯度。综上所述,我们的贡献如下:
- 我们提出了一种新的AdaIGN,通过动态选择节点或边来增强模态内和跨模态交互。并设计了基于keep或drop策略的任务特殊损失函数来满足ERC任务。
- 为了优化选择策略的计算复杂度,我们使用预先设置的伪标签来掩盖不需要选择的话语。
- 在两个流行的ERC数据集上的实验结果表明,我们的AdaIGN优于最先进的方法。
2. 方法
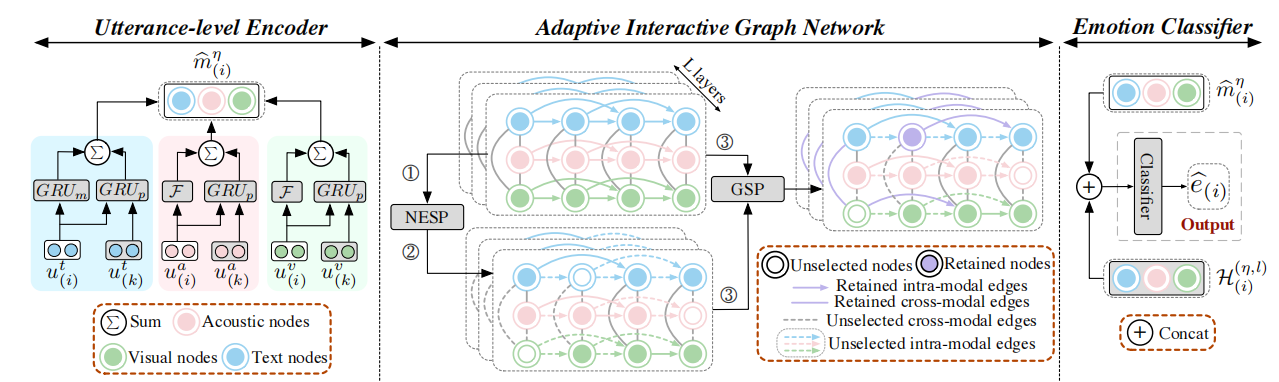
在本节中,我们将详细介绍所提出的AdaIGN的每个组成部分,如图2所示。
任务定义

2.1 特征提取
接下来(Ghosal et al. 2020a),我们对Roberta模型(Liu et al. 2019)的最后四个隐藏层进行层归一化和平均操作来获得文本特征。为了提取声学和视觉特征,我们使用OpenSmile(l等人2011)、音频特征提取工具包和预先训练的DenseNet模型(Huang等人2017),根据之前的工作(Hu等人2022)。
2.2 句子级别的编码器
捕获上下文信息和处理多模态数据中不一致的维度,我们使用双向GRU(BiGRU)∈R dh×dt获取文本模态和完全连接层Fξ∈R dh×da/v获取声学和视觉模态,映射的特征序列u η (i)每个模态η∈{a,v,t}fsexe大小表示m η (i)∈R dh。

2.3 自适应交互式图网络
2.3.1 图构造
我们提出使用一个多模态有向图网络Gd = {vd,δd,
P
d
ν
P^ν_d
Pdν ,
P
d
δ
P^δ_d
Pdδ },以确保对当前话语的预测不会被未来的话语所影响。
P
d
ν
P^ν_d
Pdν和
P
d
δ
P^δ_d
Pdδ表示一组NSP和ESP。我们还建立了另一个图网络
G
ι
G_ι
Gι = {νι,δι}。
ν
ι
/
d
ν_{ι/d}
νι/d和
δ
d
δ_d
δd分别表示一组图的节点和边。
G
ι
/
d
G_{ι/d}
Gι/d由3×N个节点组成,
m
(
i
)
η
m_{(i)}^η
m(i)η∈R dh是第i个话语的三个节点表示。模态内和模态间交互使用一组边
δ
ι
/
d
δ_{ι/d}
δι/d建模,遵循两个规则: (1)来自同一模态的节点在对话中连接,(2)来自不同模态的三个节点通过同一个话语连接。节点i和节点j之间的权值,用
W
(
i
j
)
η
W^η_{(ij)}
W(ij)η表示,∀i < j,使用余弦相似度函数sim(.)计算,如:
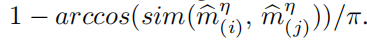
2.3.2 节点级和边级的选择策略
为了实现NSP和ESP,我们为每个节点及其对应的边设计了一个二进制随机变量 ϱ ( ζ ) ν / δ ϱ^{ν/δ}_ {(ζ)} ϱ(ζ)ν/δ∈ R N × 2 R^{N×2} RN×2。具体地说, ϱ ( ζ ) ν ϱ^{ν}_ {(ζ)} ϱ(ζ)ν∈ P d ν P^ν_d Pdν和 ϱ ( ζ ) δ ϱ^{δ}_ {(ζ)} ϱ(ζ)δ∈ P d δ P^δ_d Pdδ确定节点和边是否被选定。使用ESP,我们将上下文划分为说话者内部和说话者之间的类别,允许 P d δ P^δ_d Pdδ决定上下文类别。我们没有手动调整这些选择策略,而是使用标准的反向传播来联合学习网络权重θ和 P d ν / δ P^{ν/δ}_d Pdν/δ。然而,优化不可区分的策略是具有挑战性的。为了克服这一问题,我们采用了Gumbel Softmax采样(Jang,Gu,和Poole 2016)。
2.3.3 Gumbel Softmax采样
Gumbel Softmax介绍: https://juejin.cn/post/7441104710214910003
设Π =[π(1),π(2),…,π(N))为二元随机变量γ∈[0,1]的一组分布向量,其中π(ζ) = [1−γ(ζ),γ(ζ) ]∈R2。在Gumbel Softmax采样中,不是直接从π(ζ)中采样Γ(ζ),而是生成如下:

2.3.4 选取策略
在以上基础上,我们可以分配一个属性值Oν=[ϱν (1),…,ϱν(N)],它表示二进制随机变量的一组γ∈[0,1]的分布向量给Gd中的每个节点ν。ϱν (ζ) = [1−γ(ζ),γ(ζ) ]和γ(ζ)表示在Gd中第ζ个节点被选择的概率。在训练过程中,我们使用Gumbel Softmax采样生成ϱν (ζ)如下。
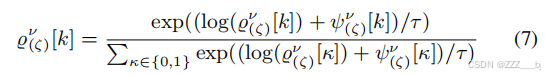
其中,ϱν (ζ) [0]和ϱν (ζ) [1]是互斥的,因此在测试期间,ϱν (ζ)的值只能为[0,1]或[1,0]。对于ESP,我们可以添加另一个属性值Oδ,以生成策略ϱδ (ζ)∈Pδ。ϱδ (ζ) [0]和ϱδ (ζ) [1]分别表示选择说话者之间和说话者内上下文的概率。
2.3.5 伪标签
由于有大量的节点和边,单独训练每个策略会导致较高的计算复杂度。为了解决这个问题,我们使用伪标签来识别不需要进行训练的策略。
(1)我们使用a和t两种模态训练了一个新的图,并将其预测结果与Gι的预测结果进行了比较。具有相同预测结果的话语被标记为MASKv,而MASKa也使用类似的方法获得。我们省略了MASKt,因为模态t已经在ERC中表现出了优越的性能(Wu et al. 2021)。
(2)我们去除Gι中相同模态(如v)的模态内边,然后将预测与原始Gι进行比较。具有相同预测的话语被标记为\ MASK v,ESP设置为[1,1],对于说话者内部和内部上下文选择的概率都为1。
在上述步骤之后,我们初始化NSP和ESP:

2.4 图卷积操作
根据(Chen et al. 2020),在一个小批数据中,Gd/ι的图卷积操作如下:

2.5 IGN with GSP
为了避免高维连接两个表示Gι和Gd,我们利用GSP类似于NSP和ESP通过设置策略ϱg∈R 2,这也是一个二进制随机变量和自适应选择H (l) d和H (l) ι获得在图级的话语表示b H (l)∈RN×3。
2.6 情感分类
我们利用一个线性单元来预测情绪的分布:

其中,Θ是一组投影参数。ς表示l2-正则化的系数。Lce是分类损失。γ、ϕ、ω、µ是决定各成分对l的贡献的超参数。这四个损失项目主要用于设置基于保持或下降策略的选择策略学习的约束。
2.7 损失
2.7.1 keep保留损失
损失项Lm和Lk是保留损失的组成部分。最小化Lk鼓励为每个模态选择文本模式和说话者内部上下文边。最小化Lm鼓励选择其他两种模式和原始图Gι。

2.7.2 drop丢失损失
通过最小化下降损失Ld和Ln,这些策略分别与keep保持损失Lm和Lk相反。为了满足ERC任务,在保持损失中,γ必须小于ω。同样,在下降损失中,µ应该小于ϕ。此外,γ和ϕ也需要分别小于ω和µ。
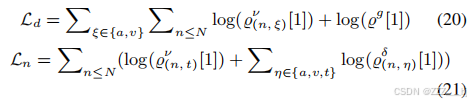
3. 实验
3.1 数据集
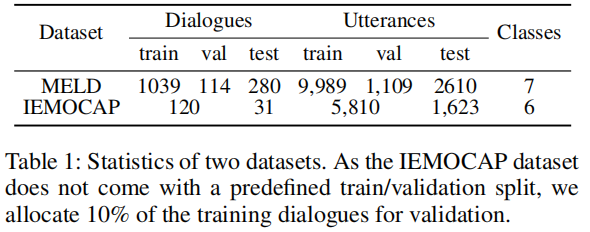
IEMOCAP、MELD
3.2 基线
-
基于聚合的融合
DialogueRNN(Majumder等人2019)利用三个GRUs来跟踪说话者的状态和上下文,而DialogueGCN(Ghosal等人2019)通过图网络处理上下文传播;两者都使用连接的多模态特征。CTNet(Zhang et al. 2020)利用基于transformer的结构来建模模态间和模态内交互。SCMM(Yang et al. 2023)结合了上下文建模、模态交互和自适应路径选择来增强多模态表示。 -
基于图的融合
MMDFN(Hu等人,2022年)利用一个具有统一结构的多模态图来表示模态之间的关系。MMGCN(Hu et al. 2021)使用了一个基于图的融合模块来捕获模态内和模态间的上下文特征。CMCF-SRNet (Zhang and Li 2023)是一个通过位置约束transformer结合跨模态交互和使用基于图的增强transformer增强话语之间的语义关系的框架。
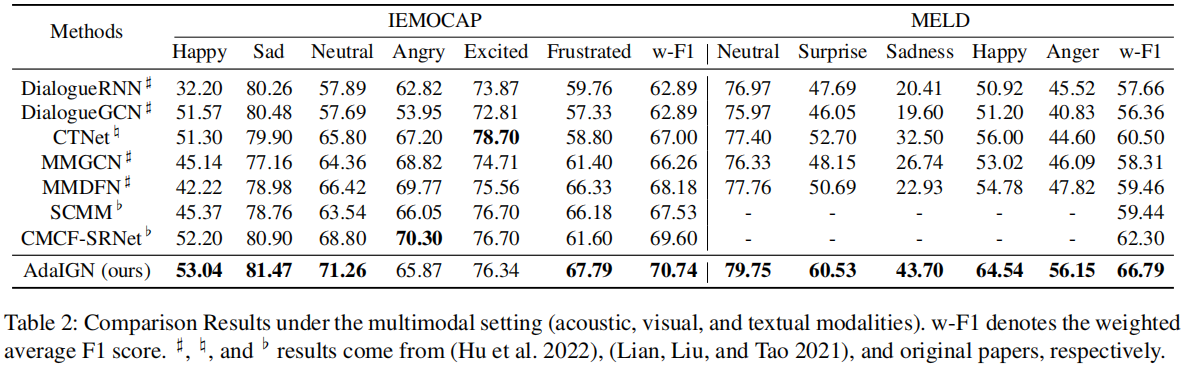
3.3 总体结果
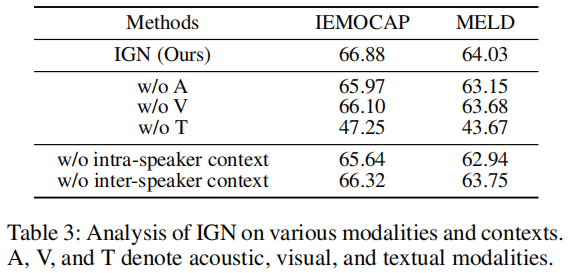
3.4 分析各种模态和上下文
 #
#
3.5 情感歧义分析
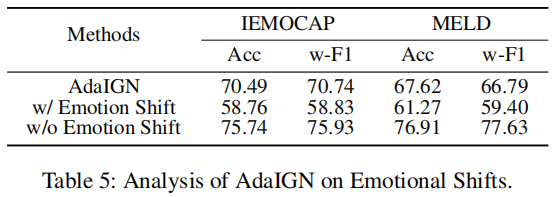
为了计算显示情感冲突问题的话语的比例,我们只使用单模态数据作为输入来训练IGN。随后,我们为每个模态生成三组预测。随后,我们为每种模态生成三组预测。在两两预测中观察到的不一致性表明这些模式之间存在冲突。在IEMOCAP数据集中,VA(声学-视觉)模式的一致性比率为83.73%,AT(声学文本)模式为50.71%,VT(视觉-文本)模式为77.45%。对于MELD数据集,VA、AT和VT模式内的对比比分别为27.32%、43.60%和47.20%,强调了探索选择政策的意义和价值。
3.6 消融研究
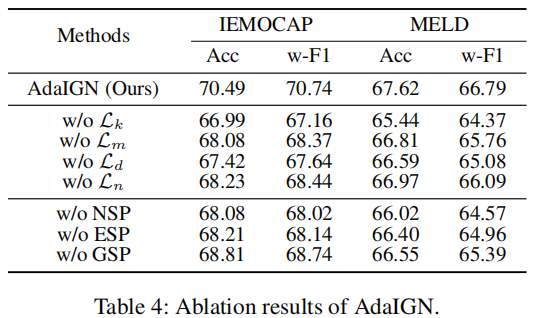
3.7 选择策略分析研究
3.8 损失项分析

3.9 伪标签分析

3.10 案例分析

3.11 误差分析
4. 相关工作
4.1 情感识别中的上下文建模
ERC中的上下文信息为情绪分析提供了重要的线索(Tu等人,2023b)。与普通的句子级情绪分析不同,ERC模型需要建模上下文和说话者感知依赖(屠等2022a),包括基于循环网络(Majumder等2019;胡、魏、怀2021;李等2022)、transformer网络(连、刘、陶2021;沈等20212022a;江等2022)和基于图的网络(Ghosal等2020b;Shen等2021b;屠等2023a)。然而,在不同的模态之间建模上下文仍然是一个重大的挑战。最近的研究工作(Kang和Kong 2022;Hu等人2021;Lian等人2023)探索了模态内和模态间交互的建模。尽管ERC取得了进展,但这些方法尚未有效地解决平衡同伴间和同伴内情境依赖的基本需要,从而在共情和情感惰性之间取得平衡。
4.2 多模态融合
多模态融合旨在通过特征、决策和模型级融合策略结合来自不同模态的信息。特征级融合涉及将多模态特征连接到输入级的联合特征向量中(Jiang et al. 2023),但由于高维度特征集,它面临数据稀疏性(Wu,Lin,and Wei 2014)。决策级融合通过投票(莫凡特、哈布拉德和阿亚奇2014年)、平均(舒托瓦、基拉和美拉德2016年)或加权和(Glodeketal.2011年)结合了单模态决策值,但忽略了模态之间的相关性。模型级融合,一个中间方法,融合了不同模式的中间表示(Hsu et al. 2023)。最近,研究人员探索了基于图的融合来捕获模态内和模态间的交互信息(Hu et al. 2021,2022;Yang et al. 2023)。然而,这些图结构使用未来的话语来预测情绪,这在现实世界的场景中是不切实际的。此外,他们在处理具有不同模态的情绪歧义的内容方面面临着局限性。
5. 结论
在本文中,我们提出了一种新的自适应IGN,称为AdaIGN,它学习了一个多模态异构图中的节点和边的选择模式。这个选择过程是由我们提出的选择策略NSP和ESP指导的。这些策略优先选择文本模态和说话者内部上下文,以满足ERC任务。此外,我们引入了GSP来整合来自原始IGN和NESP增强IGN的话语表示。为了降低策略学习的计算复杂度,我们利用伪标签来掩盖不必要的话语节点进行选择。实验结果表明,我们的方法在两个著名的数据集上优于最先进的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









