










任务导向和开放域人机对话中的性格预测
摘要
如果对话系统能够从对话中预测用户的性格,它将能够根据用户的性格进行调整,从而提高任务成功率和用户满意度。在一项最新研究中,通过使用迈尔斯-布里格斯类型指标(MBTI)性格特征和端到端(基于神经网络)的系统进行任务导向的人机对话进行性格预测。然而,尚不清楚这种预测是否适用于其他类型的系统和用户性格特征。
为了弄清这一点,我们招募了378名参与者,要求他们填写涵盖25种性格特征的四份性格问卷,并让他们与一个流水线任务导向对话系统或端到端任务导向对话系统进行三轮人机对话。我们还让另186名参与者与一个开放域对话系统进行相同的操作。随后,我们构建了基于BERT的模型,从对话中预测参与者的性格特征。结果显示,与任务导向对话相比,开放域对话的预测准确性总体上更高,尽管外向性(五大性格特征之一)在开放域对话和流水线任务导向对话中都能同样准确地预测。
我们还通过对从任务导向和开放域对话中训练的模型进行交叉比较,研究了使用不同类型对话对性格预测的影响。结果表明,开放域对话不能用于预测任务导向对话中的性格特征,反之亦然。我们进一步分析了系统话语、任务表现和对话轮次对预测准确性的影响。
1 介绍
最近的研究表明,用户的性格与对话系统的性能显著相关,并且嵌入了与对话者性格匹配的性格的对话系统可以提高用户满意度和可信度。这意味着,如果对话系统能够从对话中预测用户的性格并适应用户的性格,就能提高任务成功率和用户满意度。
多年来,心理学家提出了众多性格理论。五大性格特征和迈尔斯-布里格斯类型指标(MBTI)这两大主流性格特征得到了广泛研究,并从人际对话中进行了预测。最近,有尝试使用基于神经网络的端到端系统从任务导向的人机对话中预测MBTI。然而,以往的研究仅从特定的任务导向对话中进行性格预测,因此尚不清楚性格预测是否可以普遍应用于人机对话,以及哪些性格特征可以准确预测。
为了解这一点,我们对从任务导向和非任务导向(开放域)人机对话中预测性格特征进行了广泛调查。我们首先招募了378名参与者,要求他们填写四份问卷。然后,让他们分别与流水线任务导向对话系统或端到端任务导向对话系统进行三轮人机对话。我们还让另186名参与者使用端到端对话系统进行开放域(闲聊)对话。根据Fernau等人的研究,我们使用收集到的数据构建了基于BERT的模型,从话语中预测参与者的性格特征。之后,我们通过对任务导向和开放域对话训练的模型进行交叉比较,研究了使用不同类型对话对性格预测的影响。我们进一步分析了系统话语、任务表现和对话轮次对预测准确性的影响。本文的贡献如下:
- 这是首次全面研究从任务导向和开放域人机对话中预测25种性格特征的研究,其中任务导向对话使用了流水线和端到端系统。
- 基于众包实验,我们证明了大多数五大性格特征、IOS和几个ATQ性格特征可以从开放域人机对话中预测,尽管外向性在开放域对话和流水线任务导向对话中都可以同样准确地预测。
- 通过对模型的交叉比较,我们明确了从开放域对话训练的预测模型不能用于预测任务导向对话中的性格特征,反之亦然。
2 相关工作
2.1 性格理论
性格理论多年来得到了广泛的发展和研究。目前,有两大主流性格理论描述了个体的主要性格特征:五大性格特征和迈尔斯-布里格斯类型指标(MBTI)。五大性格特征基于戈德伯格的词汇假设,利用众多英语词汇来描述个体间的差异。MBTI则源自荣格的理论,根据四个二元维度将性格分为16种类型:外向-内向、判断-感知、思考-感觉和感觉-直觉。除了这两大主流理论外,还有其他理论描述了个体的特定方面或特征,如社会或情感方面。自我包含量表(IOS)作为性格的社会方面,旨在通过七个尺度测量个体的人际亲密度。菊池的社交技能量表(KISS-18)用于衡量个体的六种主要社交技能。成人气质问卷(ATQ)则用于评估个体在情感方面的性格。
2.2 个性与人机交互作用
人们普遍认为,性格在人与计算机交互(HCI)中起着重要作用。Lee等人开发了一种与个体交谈的社交机器人,发现具有高度外向性的人说话更快,声音更大且音调更高。他们还提出了相似吸引原则,假设个体更容易被表现出相似性格的人所吸引。基于这一假设,性格被嵌入到机器人中以增强用户在HCI中的体验。Mairesse和Walker开发了一种高度参数化的对话生成器,可以生成具有内向或外向性格的话语。最近,Fernau等人将外向性融入到一个为工作推荐设计的机器人中,观察到用户满意度有所提高。
2.3 来自文本内容的性格预测
性格表现在个体的行为、认知和情感模式的特点上,并已通过文本信息得到了广泛的预测。在早期研究中,Pennebaker等人建立了包含2468篇匿名文章的Essays数据集,并标注了作者的五大性格特征,分析了作者的语言风格与其性格特征之间的关联。Argamon等人从Essays数据集中提取了一组与功能词和系统功能语法相关的词汇风格特征,以预测外向性和神经质。Mairesse等人从Essays数据集中提取了语言探究与词数(LIWC)特征和可读机器词典(MRC)心理语言学特征,并利用支持向量机(SVM)预测五大性格特征,达到了58%的平均准确率。
除了Essays,用户的数字足迹(例如社交媒体档案和博客文章)也被广泛用于性格预测。myPersonality数据集是通过Facebook应用程序收集的,包含用户的Facebook帖子以及五大性格特征。Yu等人利用神经网络架构(如全连接网络(FC)、卷积神经网络(CNN)和循环神经网络(RNN))从myPersonality数据集中预测五大性格特征。Tandera等人进一步利用长短期记忆(LSTM)更好地预测myPersonality中的性格特征,并在使用平衡数据时达到了71%的平均准确率。
2.4 人际对话中的性格预测
近年来,对话在性格预测中得到了越来越广泛的应用。Jurafsky等人通过使用韵律特征和词汇特征,从口头对话中预测用户的互动风格(如尴尬、友好或调情)。Gjurković等人通过收集10,000名用户的Reddit评论构建了PANDORA数据集,其中1,600名用户被标注了五大性格特征,并利用BERT模型从这些人际对话中进行性格预测。Khan等人通过微调BERT模型,从Reddit帖子组成的MBTI9k语料库中预测MBTI性格特征。Jiang等人从公开的《老友记》电视节目数据集中开发了FriendsPersona数据集,并采用BERT和RoBERTa(作为一种经过优化的BERT)模型预测五大性格特征。对于五大性格特征,RoBERTa实现了最佳的平均预测性能,分类准确率为63%。
2.5 人机对话中的性格预测
关于人机对话,Fernau等人发现,嵌入了与其对话者的个性相匹配的对话系统可以导致更好的用户满意度和感知可信度。Tey还使用基于bert的模型,从任务导向的人机对话中预测了MBTI的人格特征,并报告了外向性的准确率达到69.17%。我们的动机与这些研究相似,因为我们对人机对话的人格预测很感兴趣。我们的目标是从基于两种类型的对话(面向任务和开放领域的对话),使用不同的架构(管道和端到端)对广泛覆盖的人格特征(即五大人格特征、IOS、KISS-18和ATQ人格特征)的预测中得到一个普遍的结论。
3 方法
具有性格特征的人机对话数据集是实现人机对话性格预测的先决条件。为了对人机对话中的性格预测进行了全面的研究,我们首先收集了相关数据,然后建立了性格预测模型。
我们选择了五大性格特征,这些特征包括五个广泛的因素:开放性、尽责性、外向性、宜人性和神经质。我们还纳入了与社交性和情感/气质相关的性格特征,因为之前的研究强调了这两个方面在人机对话中的重要性。具体来说,我们从四个流行的性格问卷中获取了性格特征:(1)五大性格量表(BFI-44),包含44个问题评估五大性格特征;(2)自我包含他人量表(IOS),表示受访者对他人或团体的亲近感;(3)Kikuchi社交技能量表(KISS-18),包含18个问题识别六种社交技能;(4)成人气质问卷(ATQ),包含77个问题评估与四个维度相关的13种用户气质。
MBTI性格特征近年来越来越受到关注,特别是在社交媒体平台上。然而,考虑到MBTI与五大性格特征之间的重叠,以及五大性格特征在心理学中的更广泛接受度,我们在本研究中重点关注五大性格特征。
为了获得普遍的结果,我们关注了两种主流的人机对话类型:任务导向型对话和开放域对话。任务导向型对话旨在帮助用户实现特定目标,例如获取旅游信息或预订餐厅。我们使用了管道和端到端(基于神经网络)的任务导向型对话系统,因为它们代表了两种典型的对话系统。它们生成话语的不同机制使其成为测试性格预测普遍性的理想选择。管道对话系统具有模块化和透明的管道,每个模块可以独立实现。端到端对话系统由神经网络序列到序列模型实现,可以从对话历史生成系统响应。与任务导向型对话相比,开放域对话的目的是保持用户的参与度,并讨论他或她感兴趣的话题。考虑到端到端系统在开放域对话中的表现压倒性地更好,我们只使用了端到端系统进行开放域对话。
我们首先从任务导向型和开放域对话的训练数据中训练了一组性格预测模型,然后根据它们使用测试数据准确预测性格特征的程度来评估这些模型(“任务导向型和开放域对话的预测结果”)。此外,我们进行了交叉比较,以验证从不同类型对话创建的模型的普遍性(“不同类型对话创建的模型的交叉比较结果”),例如,是否可以使用从开放域对话中训练的预测模型来预测任务导向型对话中的性格。所有实验均符合适用的规则和指南。
3.1 性格标签
在大多数将性格预测视为分类问题的研究中,我们将性格预测视为二元分类问题。用户的性格特征被标记为“低”或“高”:如果其值低于训练和验证数据中所有用户特征值的第50百分位数,则为“低”;如果其值高于第50百分位数,则为“高”。尽管我们必须承认,预测的性格二元结果更易于解释,但这种方法存在细微差别的丧失,从而降低了统计处理的程度。
3.2 基于bert模型
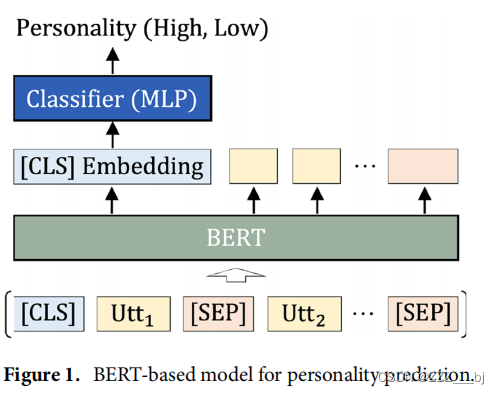
BERT模型在近期的性格预测研究中被广泛使用并表现良好。在本研究中,我们也训练了一个基于BERT的模型来预测性格特征,如图1所示。对话中的用户话语或对话中的用户和系统话语都可以作为性格预测的输入。当使用用户话语时,对话中的每个用户话语按顺序连接,使用特殊的[SEP]标记。为了进行性格分类,一个特殊的[CLS]标记被添加到序列的开头,以输出性格特征的二元标签。当使用用户和系统话语时,每个用户或系统话语前都会添加一个特殊的[USR]或[SYS]标记,而不是[SEP]标记。
3.3 评价指标和基线
由于在“性格预测的模型配置”中使用了10折交叉验证,每折中的测试数据可能是不平衡的。为了评估模型在具有不平衡性格标签的数据上的预测性能,我们选择了平衡准确率作为评估指标。平衡准确率通过平均真实正率(TPR)和真实负率(TNR)来计算:

作为一个基线,我们选择了一个基于多数的分类器,它使用在训练和验证数据中出现的最频繁的人格标签作为其预测。由于我们有两个标签,所以基线的平衡精度一直有50%。
4 数据收集
数据收集实验被设计为一个人类智能任务(HIT),目的是在Amazon Mechanical Turk(AMT)众包平台上获取参与者的性格特征及其与机器人的对话。HIT由两部分组成:填写性格问卷和与一个管道任务导向对话系统、一个端到端任务导向对话系统或一个开放领域对话系统进行三轮对话。我们收集了大约600名参与者的性格特征及其与上述三种对话系统之一的三轮对话记录。HIT获得了我们组织伦理审查委员会的批准。
为了保证收集到的对话的质量,我们将参与者的地区限制在英语国家,并设置了HIT资格:(1) HIT完成数量大于100次;(2) HIT批准率大于95%。每个完成HIT的参与者获得10美元的报酬。HIT完成数量是指一个工人在AMT上完成的任务总数【49】。这个资格限制了任务的参与者,以确保他们基于以往工作的高水平经验。每个参与者只被允许完成其中一个对话系统的HIT。
4.1 面向任务的对话收集
我们选择了MultiWOZ 2.1,这是一个大型的涵盖多个旅游信息咨询任务的人类对话语料库,用于构建收集任务导向对话的对话系统。任务领域包括餐馆、酒店、景点、出租车、火车、医院和警察。需要注意的是,我们没有使用医院或警察领域,因为它们的槽和值明显少于其他五个领域。在开始之前,参与者需要仔细阅读所分配任务的描述。该描述包括用户需要实现的目标,例如,预订一家有三人桌位的印度餐馆。我们实现了以下的管道和端到端对话系统。
4.2 开放域对话收集
4.3 数据统计
4.4 实验
利用收集到的数据,我们进行了一项实验,以评估任务导向和开放领域对话的人格预测,其中任务导向的对话系统是使用管道和端到端架构开发的。十,我们对面向任务和开放领域对话创建的模型进行了交叉比较,以验证此类模型的通用性。
4.5 人格预测的模型融合
基于BERT的人格预测模型是使用Simple Transformers实现的,该库构建于Hugging Face的Transformers库之上。我们选择了常用的“BERT-base-uncased”模型来进行不涉及系统发言作为输入的对话分类(参见“系统发言的影响”;我们发现系统发言并不能提升人格预测效果)。我们将输入对话限制为最多512个token,并使用批量大小为8进行模型训练,优化器为AdamW,学习率设为2e-5,采用早停策略,耐心度为3。我们将最大训练轮数设为20,并每25个训练步骤验证一次模型。
4.6 预测结果
总结和未来工作
我们的目标是从不同系统类型和架构的人机对话中得出关于预测人格特征的一般结论。为此,我们收集了使用管道任务导向对话系统和端到端任务导向对话系统的人格标注对话数据。我们还收集了使用开放域对话系统的对话数据。然后,我们构建了一个基于BERT的模型,从对话中的用户话语预测用户的25种人格特征。
结果表明,虽然外向性可以在相同水平上从管道任务导向对话中预测,但开放域对话的预测准确性优于任务导向对话。我们还对从任务导向和开放域对话中创建的模型进行了交叉比较,发现预测模型的泛化能力较低,不能准确预测不同类型对话中的人格特征。我们的研究结果建议,在对话开始时启动开放域对话是开发能够预测和适应用户人格的对话系统的最有效方法。如果专注于外向性,可能也可以通过管道架构的任务导向对话来预测用户人格。我们进一步研究了使用系统话语和从不同轮次对话中进行预测的效果,发现系统话语和对话轮次对人格预测的影响有限。我们还发现所实施的端到端对话系统(SimpleTOD)的低能力限制了人格预测。
关于本研究中人格预测的60%性能,我们承认这不是一个很高的值。然而,我们相信这大概是目前技术能够达到的最佳水平。这得到了先前工作的支持以及我们当前研究的实证结果。我们对端到端任务导向对话预测准确率低的原因进行了分析,发现准确率与对话系统的词汇量有限有关。当对话系统的词汇量有限时,它无法很好地理解用户的发言,这反过来限制了用户对系统的自由表达。然而,先前研究中与人际对话相关的人格预测的60-70%准确率表明,可能还有其他因素影响人格预测。例如,由于人际关系或对话者的沟通风格等因素,个人的人格可能无法完全表达出来。
即使在人格预测中达到60%的准确率,也能使对话系统在一定程度上适应对话者的人格,从而提高用户满意度。然而,当用户的人格被误分类时,用户满意度可能会下降。为了提高用户人格预测的准确性,需要结合其他方法。
未来还有许多额外的研究需要进行。首先,应考虑其他分类模型(例如RoBERTa或DeBERTa)以提高预测准确性。其次,我们希望对实验结果进行更严格的分析,例如结合额外的词汇相关特征(例如词性标注和语言心理词汇计数)来研究端到端任务导向对话预测准确率低的原因。第三,我们还希望对系统响应的影响进行更全面的分析,彻底检查其可能的效果。第四,应采用其他对话任务(例如职位推荐和汽车助手)和更多种类的对话系统(例如基于大型语言模型的对话系统)进行更全面的评估。第五,关于影响人格预测的因素,我们希望调查人格预测准确率限制的原因。最后,由于当对话系统的人格特质与其对话者的人格特质一致时,系统可以实现更高的满意度,我们旨在从人机对话中评估对话者的人格特质,并将相应的人格特质融入对话系统。

















 5065
5065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









