









2025.5.4周报
- 文献阅读
- 题目信息
- 摘要
- 创新点
- 网络架构
- 实验
- 结论
- 不足以及展望
文献阅读
题目信息
- 题目: Physics-Informed Neural Network Approach for Solving the One-Dimensional Unsteady Shallow-Water Equations in Riverine Systems
- 期刊: Journal of Hydraulic Engineering
- 作者: Zeda Yin, S.M.ASCE; Jimeng Shi; Linlong Bian, S.M.ASCE; William H. Campbell; Sumit R. Zanje, S.M.ASCE; Beichao Hu; and Arturo S. Leon, M.ASCE
- 发表时间: 2025
- 文章链接: https://ascelibrary.org/doi/epdf/10.1061/JHEND8.HYENG-13572
摘要
数值方法在求解非线性偏微分方程时,实际应用中存在一定困难。传统机器学习和深度学习模型依赖大量高质量训练数据,数据成本高且难度大。此外,这些模型多为黑箱模型,计算过程难以解释。尽管PINN近年来在多个领域取得成功,但在浅水方程及水文学和水力学领域的应用研究仍不充分。现有研究多集中于求解其他偏微分方程,且在考虑地形信息和摩擦的明渠水流问题上,尚无有效的PINN框架。基于以上背景,本论文提出一种新的PINN框架,为水系统工程问题提供更有效的解决方案。本论文的PINN框架,包括前向步骤、损失函数构建和反向步骤,还对其进行改进以解决大规模问题。通过两个案例验证,结果表明PINN能准确预测流速、流量和水位,且可进行位置和时间外推,但存在训练时间长和泛化性不足的局限。
创新点
该论文使用的PINN是无数据方法,不受数据获取难题限制。且PINN将物理规律数学表达式融入框架,能进行位置和时间外推,提升极端条件下可靠性。
网络架构
SVE由质量守恒方程和动量守恒方程组成,适用于任意形状的横截面,可写为:
∂
U
∂
t
+
∂
F
∂
x
=
S
\frac{\partial \mathbf{U}}{\partial t} + \frac{\partial \mathbf{F}}{\partial x} = \mathbf{S}
∂t∂U+∂x∂F=S
其中,向量变量定义为:
U
=
[
A
Q
]
,
F
=
[
Q
Q
2
A
+
g
I
1
]
,
S
=
[
0
g
A
(
S
0
−
S
f
)
]
\mathbf{U} = \begin{bmatrix} A \\ Q \end{bmatrix}, \quad \mathbf{F} = \begin{bmatrix} Q \\ \frac{Q^2}{A} + g I_1 \end{bmatrix}, \quad \mathbf{S} = \begin{bmatrix} 0 \\ g A (S_0 - S_f) \end{bmatrix}
U=[AQ],F=[QAQ2+gI1],S=[0gA(S0−Sf)]
A: 横截面湿周面积;Q: 横截面流量;
g
I
1
g I_1
gI1 : 静水推力;
S
f
S_f
Sf:摩擦坡度;
S
0
S_0
S0:地形高程坡度;t: 时间;x: 空间坐标。
其中:
g
∂
I
1
∂
x
=
g
A
∂
h
∂
x
g \frac{\partial I_1}{\partial x} = g A \frac{\partial h}{\partial x}
g∂x∂I1=gA∂x∂h
摩擦坡度通过Manning方程计算:
S
f
=
(
n
v
K
R
0.667
)
2
S_f = \left( \frac{n v}{K R^{0.667}} \right)^2
Sf=(KR0.667nv)2
地形高程坡度为:
S
0
=
−
d
z
d
x
S_0 = -\frac{d z}{d x}
S0=−dxdz
其中
n: Manning粗糙系数;v: 横截面流速;K: 单位转换因子;R: 水半径;z: 河床高程。
以上是用向量表示,拆开来第一行(即质量守恒),第二行(动量守恒)简化就是如下图所示:

论文的PINN结构如下:
输入: 输入为空间x和时间t
输出: 为流速𝑣及水位h
结构: 全连接多层感知器,8个隐藏层,每层80个隐藏单元,ReLU激活函数。
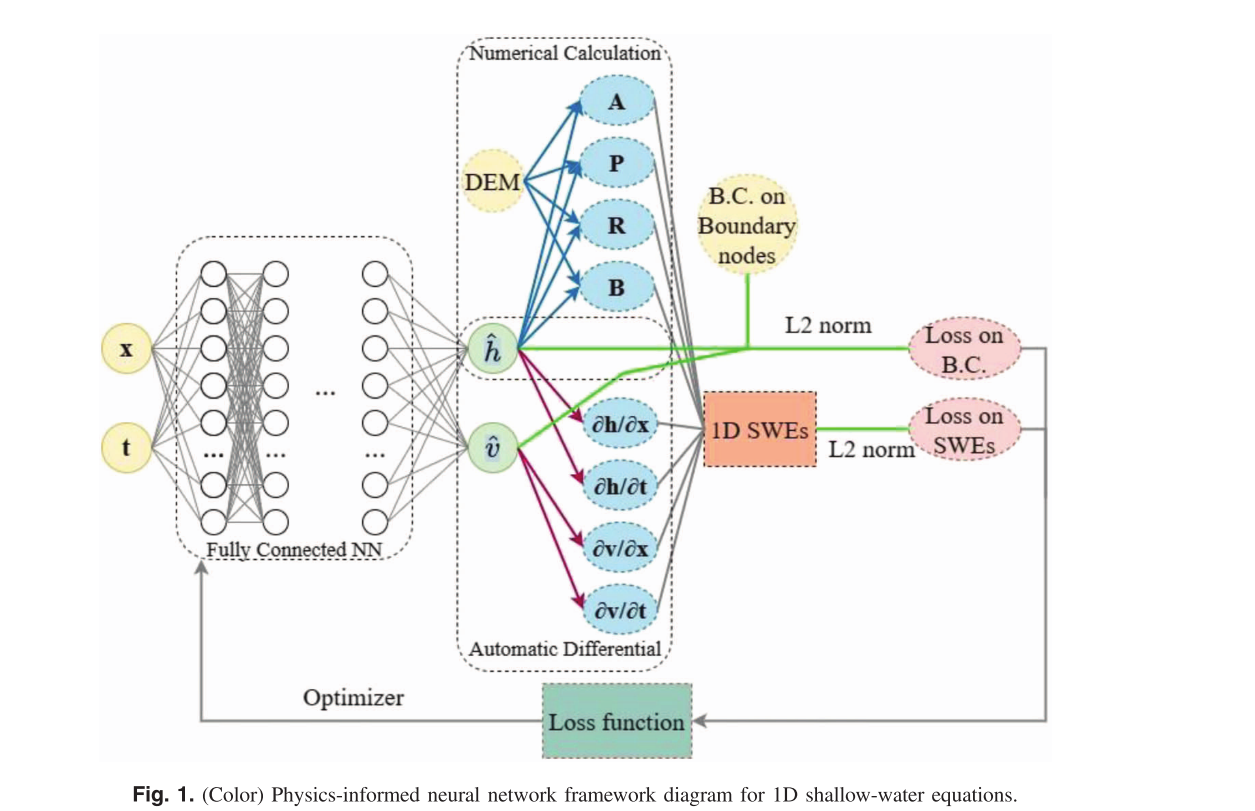
由于横截面形状复杂,参数(A,P,R,B)无法解析计算。
论文基于DEM数据,采用数值方法计算。
DEM(Digital Elevation Model,数字高程模型)是一种表示地表高程的数字化数据集,通常以网格或点云的形式存储。
它记录了地表在特定位置(通常以经纬度或投影坐标表示)的海拔高度
广泛应用于地理信息系统、水文建模、地形分析、洪水模拟等领域。
DEM数据可以描述地形特征,如河床、坡度、山谷等,对于模拟水流、洪水传播和地形相关计算至关重要。
DEM提供离散采样点,每个点包含横截面距离a和高程b。
然后将高程值转换为相对于预测水深的坐标,如下图所示:
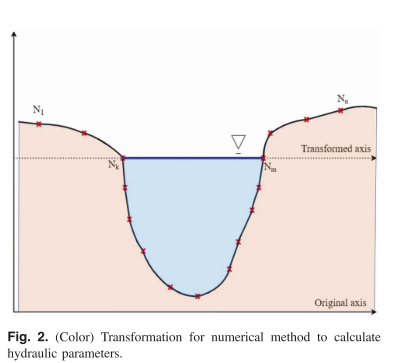
湿周面积A通过梯形规则积分高程和距离:
A
=
−
∑
i
=
1
n
−
1
(
b
i
+
1
+
b
i
)
∗
(
a
i
+
1
−
a
i
)
2
A = -\sum_{i=1}^{n-1} \frac{(b_{i+1} + b_i) * (a_{i+1} - a_i)}{2}
A=−∑i=1n−12(bi+1+bi)∗(ai+1−ai)
湿周周长P累加相邻点间的欧几里得距离:
P
=
∑
i
=
1
n
−
1
(
a
i
+
1
−
a
i
)
2
+
(
b
i
+
1
−
b
i
)
2
P = \sum_{i=1}^{n-1} \sqrt{(a_{i+1} - a_i)^2 + (b_{i+1} - b_i)^2}
P=∑i=1n−1(ai+1−ai)2+(bi+1−bi)2
水面半径R和顶部宽度B直接从A,P和边界点计算:
R
=
A
P
R = \frac{A}{P}
R=PA
B
=
a
m
−
a
k
B = a_m - a_k
B=am−ak
损失函数: 损失函数包括上游边界、下游边界、质量方程和动量方程损失组成。
由于各部分量级差异,比如,水位h为102而偏导数
∂
h
∂
t
\frac{\partial h}{\partial t}
∂t∂h为10-3-10-8,直接求和会导致优化偏向某些分量。每个损失分量乘以权重(
W
1
−
W
4
W_1 −W_4
W1−W4),使其量级接近,权重通过边界条件的量级和网格划分,如下图所示:
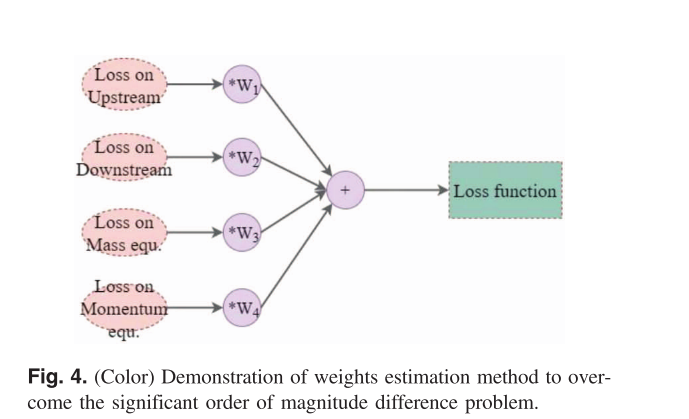
L
total
=
W
1
L
up
b
c
+
W
2
L
down
b
c
+
W
3
L
physics
m
a
s
s
+
W
4
L
physics
m
o
m
e
n
t
u
m
\mathcal{L}_{\text{total}} = W_1 \mathcal{L}_{\text{up}_{bc}} + W_2 \mathcal{L}_{\text{down}_{bc}} + W_3 \mathcal{L}_{\text{physics}_{mass}} + W_4 \mathcal{L}_{\text{physics}_{momentum}}
Ltotal=W1Lupbc+W2Ldownbc+W3Lphysicsmass+W4Lphysicsmomentum
PDE残差项基于SVE:
L
physics
=
1
N
physics
∑
i
=
1
N
physics
∣
∂
U
∂
t
+
∂
F
∂
x
−
S
∣
2
\mathcal{L}_{\text{physics}} = \frac{1}{N_{\text{physics}}} \sum_{i=1}^{N_{\text{physics}}} \left| \frac{\partial \mathbf{U}}{\partial t} + \frac{\partial \mathbf{F}}{\partial x} - \mathbf{S} \right|^2
Lphysics=Nphysics1∑i=1Nphysics∣∣∂t∂U+∂x∂F−S∣∣2
上游边界条件损失:
L
up
b
c
=
1
N
up
b
c
∑
i
=
1
N
up
b
c
∣
v
^
b
c
−
v
b
c
∣
2
\mathcal{L}_{\text{up}_{bc}} = \frac{1}{N_{\text{up}_{bc}}} \sum_{i=1}^{N_{\text{up}_{bc}}} \left| \hat{v}_{bc} - v_{bc} \right|^2
Lupbc=Nupbc1∑i=1Nupbc∣v^bc−vbc∣2
下游边界条件损失:
L
down
b
c
=
1
N
down
b
c
∑
i
=
1
N
down
b
c
∣
h
^
b
c
−
h
b
c
∣
2
\mathcal{L}_{\text{down}_{bc}} = \frac{1}{N_{\text{down}_{bc}}} \sum_{i=1}^{N_{\text{down}_{bc}}} \left| \hat{h}_{bc} - h_{bc} \right|^2
Ldownbc=Ndownbc1∑i=1Ndownbc∣∣∣h^bc−hbc∣∣∣2
其中:
N
physics
{N_{\text{physics}}}
Nphysics为配点总数;
N
up
b
c
{N_{\text{up}_{bc}}}
Nupbc与
N
down
b
c
{N_{\text{down}_{bc}}}
Ndownbc上下游边界点数;
W
1
−
W
4
W_1 −W_4
W1−W4为权重;
实验
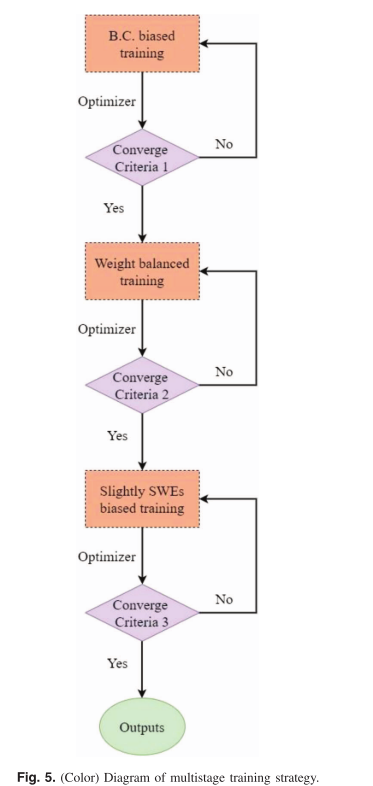
实验采用多阶段训练策略,如下图所示:
分阶段优化边界和物理方程,模拟了先确定边界再求解内部场的逻辑,加速收敛。论文将训练分为三个阶段优化。
第一阶段为放大边界条件权重,优先优化边界收敛。
第二阶段则平衡权重,降低学习率,优化SVE残差。
第三阶段略微增加SWEs权重,进一步提高精度。
论文通过假设和实际场景研究展示了PINN框架求解一维非定常浅水方程的性能,具体结果如下:
-
假设的均匀梯形渠道中流量和水位突然变化的场景
PINN框架和HEC - RAS输出的速度和水位剖面吻合良好,所有横截面速度和水位的平均绝对误差分别为0.002743 m/s和0.001219 m。
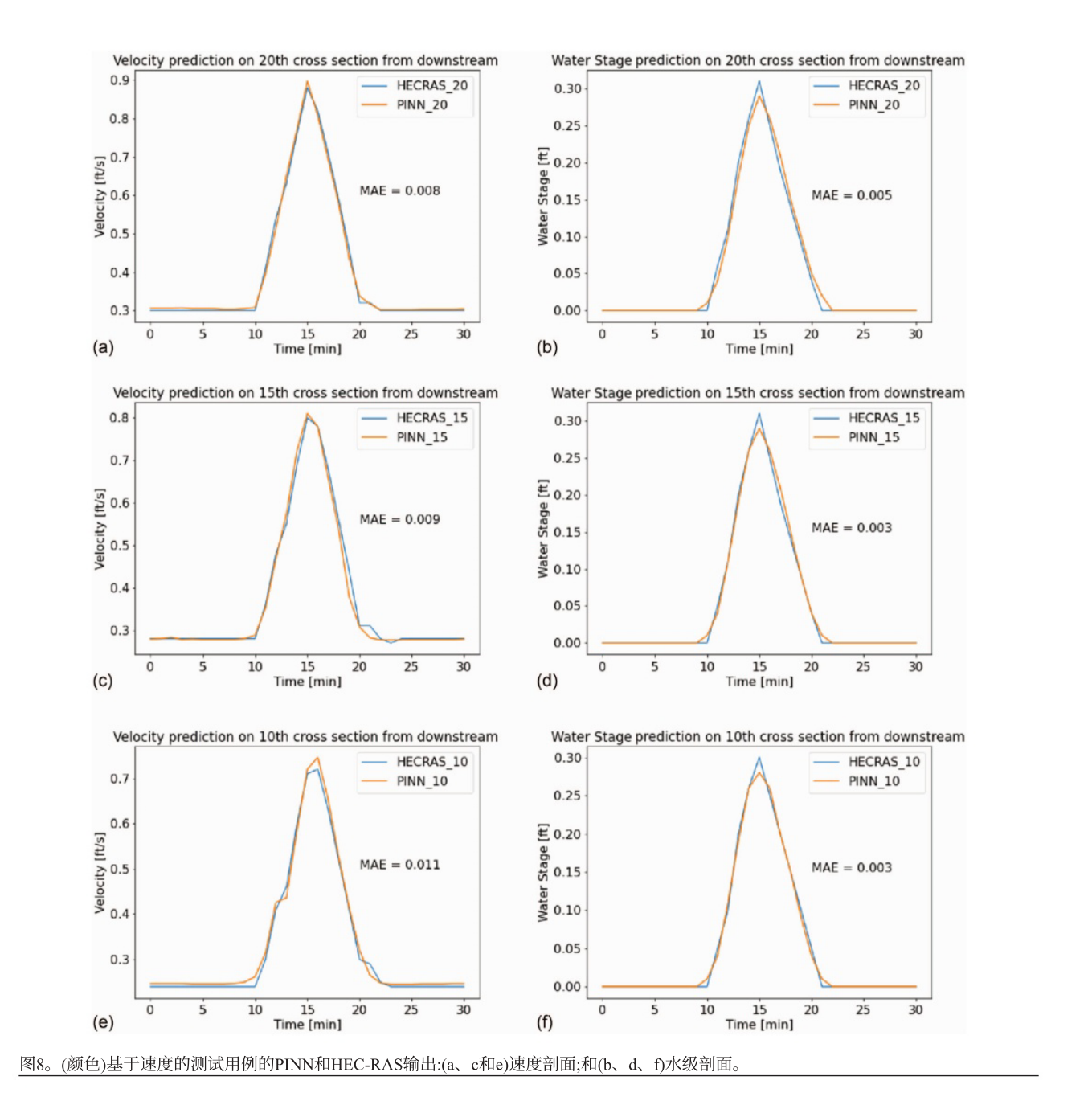
PINN能高精度求解流量基一维浅水方程,预测水位的平均绝对误差与速度基PINN相近,约为0.0012 m,但流量的平均绝对误差比速度大,这是因为流量尺度更大且未进行归一化。
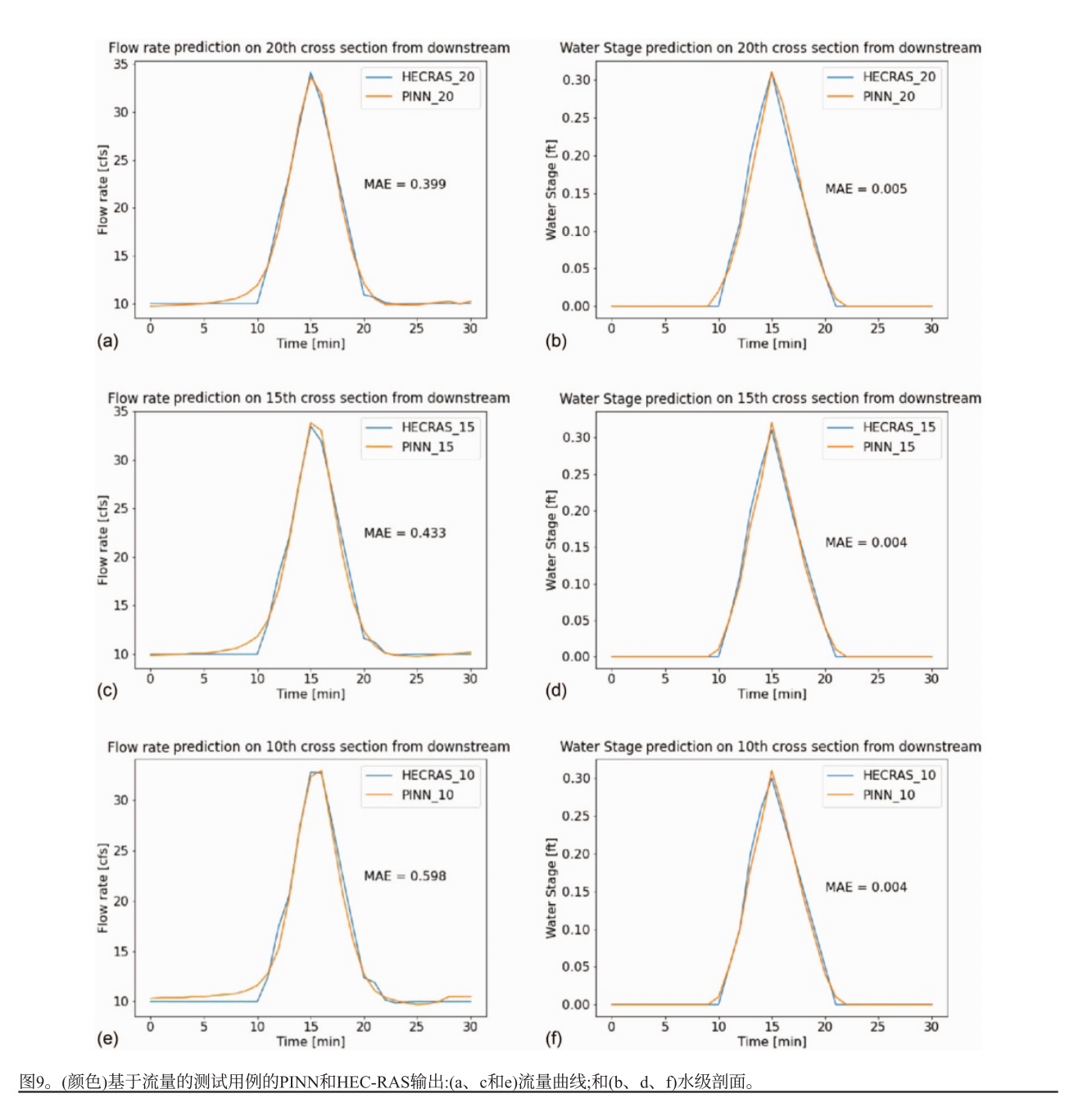
-
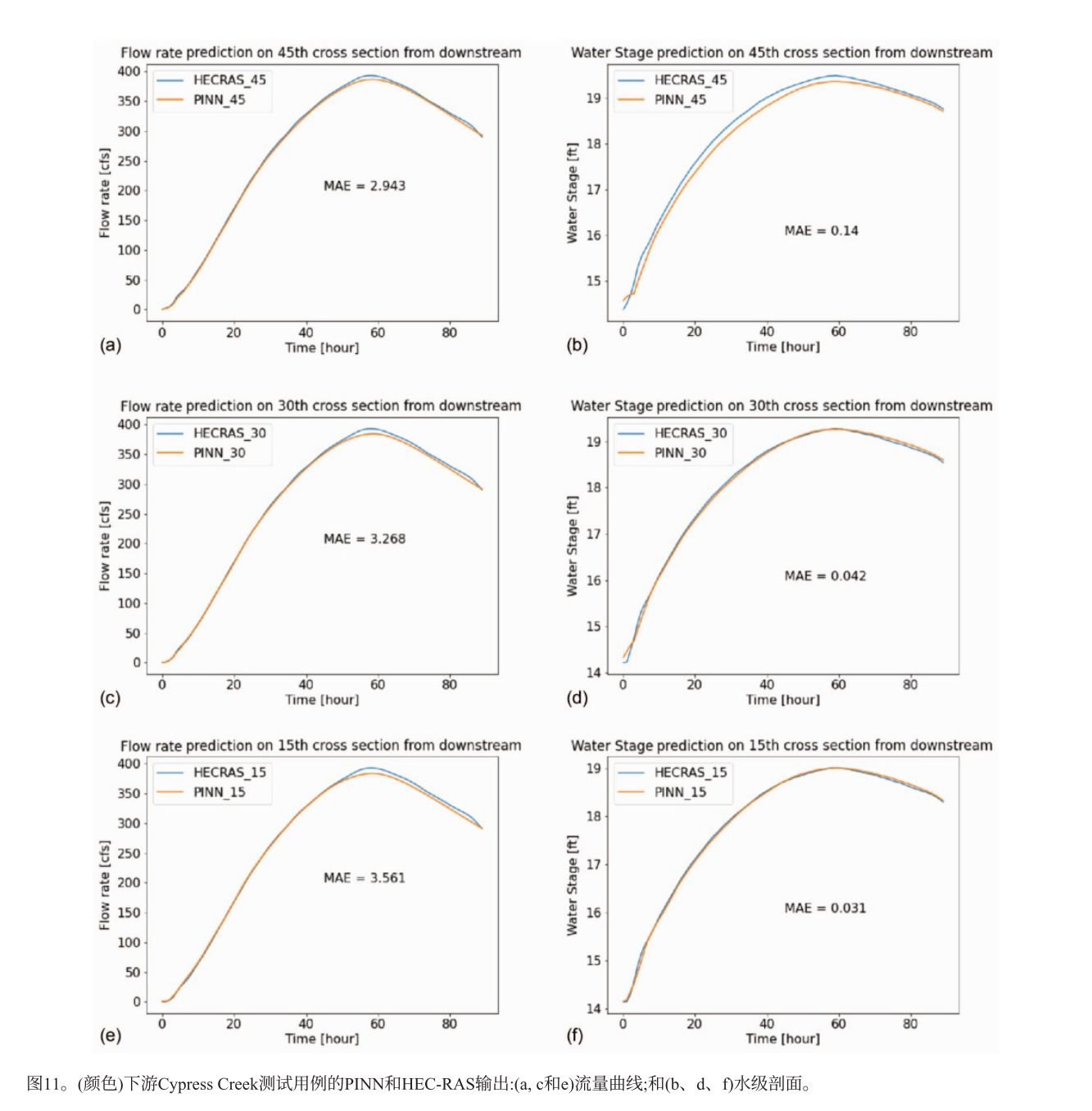
休斯顿赛普拉斯溪下游的实际案例
PINN框架和HEC - RAS输出对比,流量预测的平均绝对误差在0.0833 - 0.10083 m³/s之间,水位预测的平均绝对误差在0.0152 - 0.079 m之间,PINN输出趋势对流量和水位略有低估。
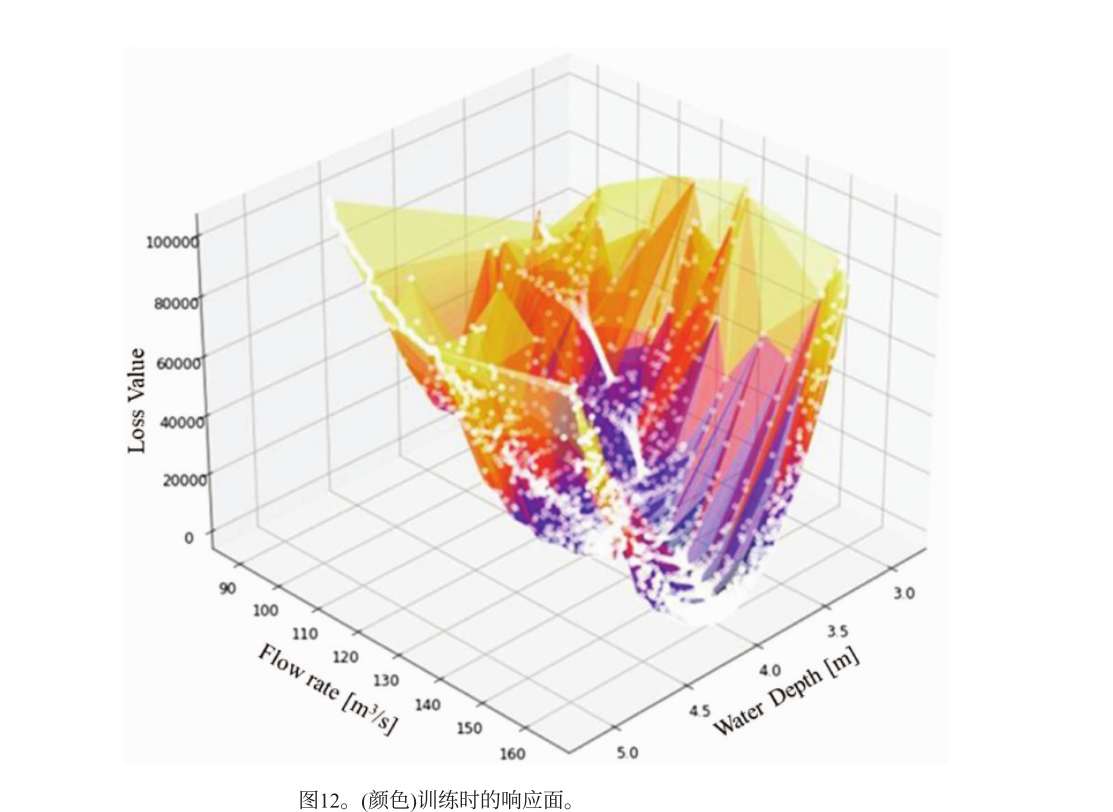
通过追踪内部横截面在每次迭代中的损失函数值,发现存在全局最小值,证明PINN框架理论上可获得一维浅水方程的小残差解。
PINN在计算域内的位置外推结果准确,平均绝对误差甚至小于非外推预测结果。
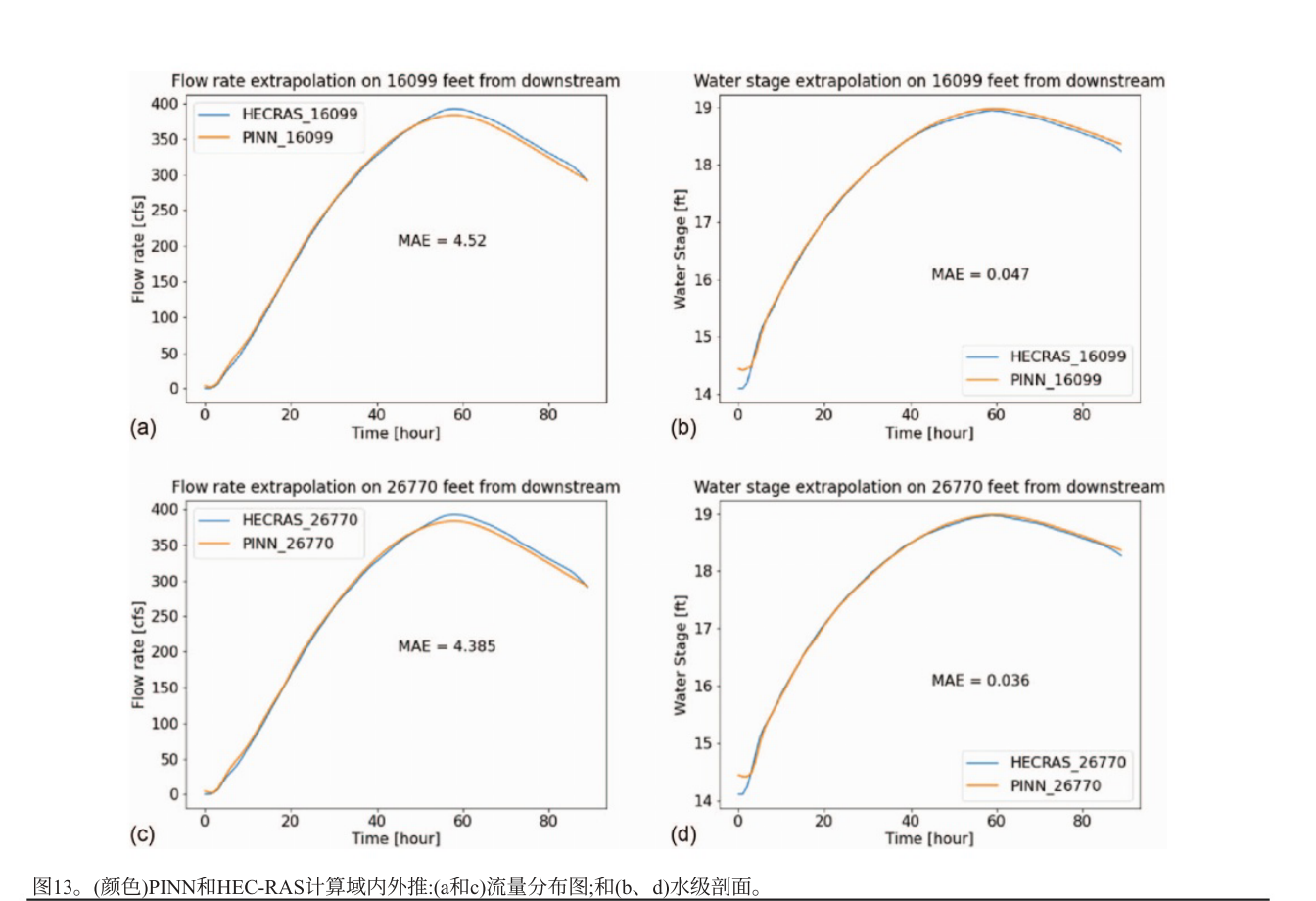
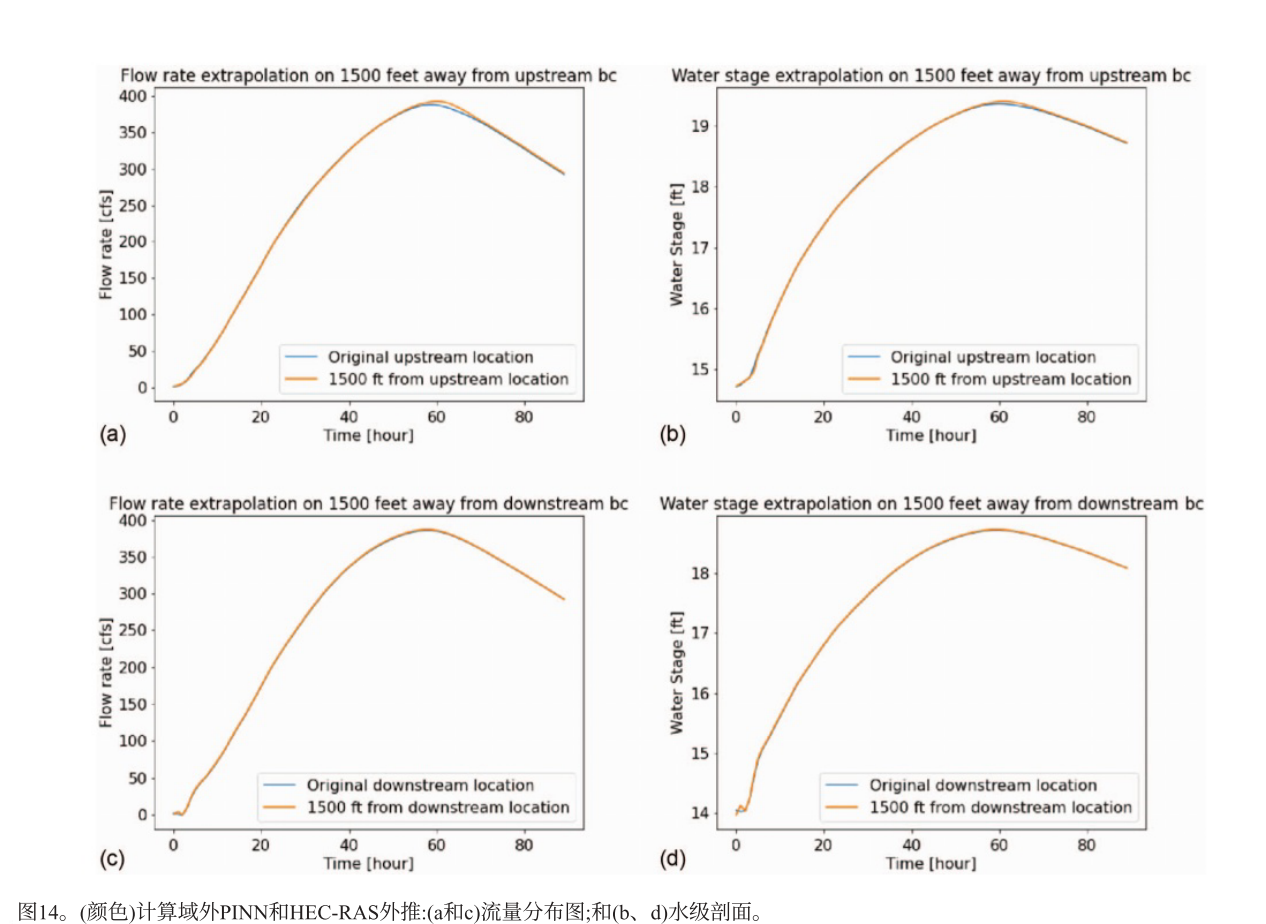
在计算域外进行外推测试,与边界位置的结果无显著差异,表明PINN可在域外进行合理外推。
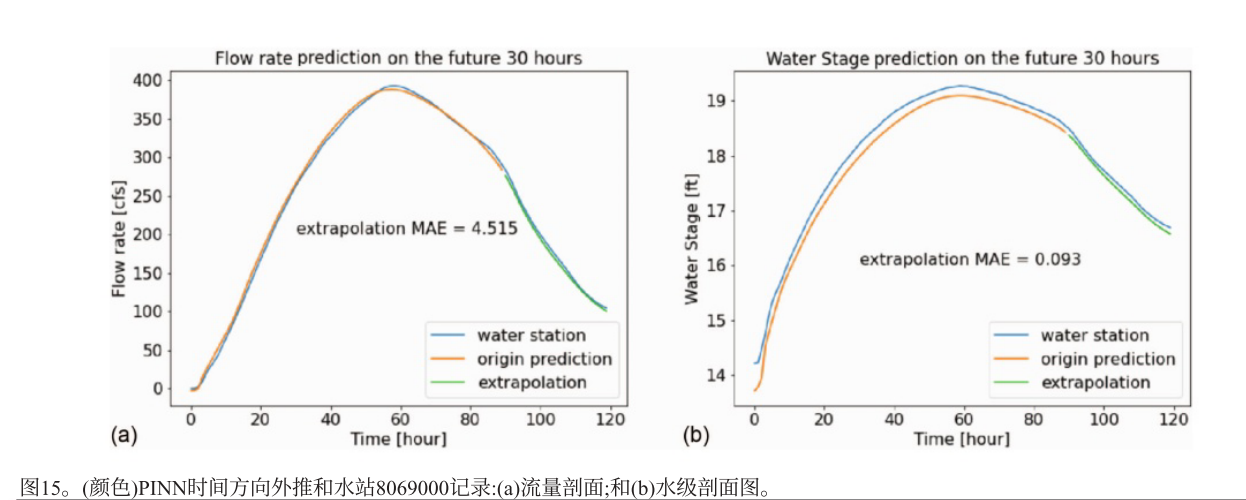
以水位站记录的历史数据为参考,对未来30小时进行外推,外推结果的平均绝对误差与非外推预测相似,趋势与历史曲线拟合良好。
代码如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from uuid import uuid4
# 设置随机种子,确保可重复性
tf.random.set_seed(42)
np.random.seed(42)
g = 9.81 # 重力加速度 (m/s^2)
n = 0.013 # Manning粗糙系数
K = 1.0 # 单位转换因子(SI单位)
def compute_hydraulic_params(h, x):
# 假设梯形横截面:底宽2m,边坡1:1
b0 = 2.0 # 底宽
z = 1.0 # 边坡
A = h * (b0 + z * h) # 湿周面积
P = b0 + 2 * h * tf.sqrt(1 + z**2) # 湿周周长
R = A / P # 液压半径
B = b0 + 2 * z * h # 顶部宽度
S0 = -0.001 # 假设地形坡度
return A, P, R, B, S0
# 定义神经网络模型
class PINN(tf.keras.Model):
def __init__(self):
super(PINN, self).__init__()
# 8层全连接网络,每层80个单元,ReLU激活
self.layers_list = [tf.keras.layers.Dense(80, activation='relu') for _ in range(8)]
self.output_layer = tf.keras.layers.Dense(2) #v(流速),h(水位)
def call(self, inputs):
x, t = inputs[:, 0:1], inputs[:, 1:2]
X = tf.concat([x, t], axis=1)
for layer in self.layers_list:
X = layer(X)
return self.output_layer(X) # [v, h]
# 计算物理残差
def compute_physics_loss(model, x, t):
with tf.GradientTape(persistent=True) as tape:
tape.watch([x, t])
inputs = tf.concat([x, t], axis=1)
vh = model(inputs)
v, h = vh[:, 0:1], vh[:, 1:2]
# 一阶偏导数
dv_dx = tape.gradient(v, x)
dh_dx = tape.gradient(h, x)
dh_dt = tape.gradient(h, t)
A, P, R, B, S0 = compute_hydraulic_params(h, x)
# 摩擦坡度
Sf = (n * v / (K * tf.pow(R, 2/3)))**2
# 方程残差
res_mass = dh_dt + (A / B) * dv_dx + v * dh_dx
res_momentum = g * A * (dh_dx + Sf - S0)
loss_mass = tf.reduce_mean(tf.square(res_mass))
loss_momentum = tf.reduce_mean(tf.square(res_momentum))
return loss_mass, loss_momentum
# 边界条件损失
def compute_bc_loss(model, x_bc, t_bc, v_bc, h_bc):
inputs = tf.concat([x_bc, t_bc], axis=1)
vh = model(inputs)
v_hat, h_hat = vh[:, 0:1], vh[:, 1:2]
# 流速损失
loss_up_bc = tf.reduce_mean(tf.square(v_hat - v_bc)) if v_bc is not None else 0.0
# 水位损失
loss_down_bc = tf.reduce_mean(tf.square(h_hat - h_bc)) if h_bc is not None else 0.0
return loss_up_bc, loss_down_bc
def train_pinn(model, x_physics, t_physics, x_bc_up, t_bc_up, v_bc_up, x_bc_down, t_bc_down, h_bc_down, epochs, lr, weights):
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
for epoch in range(epochs):
with tf.GradientTape() as tape:
# 物理残差
loss_mass, loss_momentum = compute_physics_loss(model, x_physics, t_physics)
# 边界条件
loss_up_bc, loss_down_bc = compute_bc_loss(
model, x_bc_up, t_bc_up, v_bc_up, x_bc_down, t_bc_down, h_bc_down
)
# 总损失
loss = (weights[0] * loss_up_bc + weights[1] * loss_down_bc +
weights[2] * loss_mass + weights[3] * loss_momentum)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.numpy():.6f}, "
f"BC_up: {loss_up_bc.numpy():.6f}, BC_down: {loss_down_bc.numpy():.6f}, "
f"Mass: {loss_mass.numpy():.6f}, Momentum: {loss_momentum.numpy():.6f}")
def main():
L = 79.25 # 渠长
T = 600.0 # 时间
N_physics = 1000 # 物理配点数
N_bc = 100 # 边界点数
x_physics = tf.random.uniform((N_physics, 1), 0, L)
t_physics = tf.random.uniform((N_physics, 1), 0, T)
# 生成边界点
t_bc = tf.random.uniform((N_bc, 1), 0, T)
x_bc_up = tf.zeros_like(t_bc) # 上游 x=0
x_bc_down = L * tf.ones_like(t_bc) # 下游 x=L
# 模拟边界条件
v_bc_up = tf.sin(2 * np.pi * t_bc / T) * 0.5 + 0.5
h_bc_down = tf.sin(2 * np.pi * t_bc / T) * 0.2 + 0.5
model = PINN()
stages = [
# 第一阶
{"epochs": 5000, "lr": 1e-4, "weights": [1.0, 1.0, 0.1, 0.1]},
# 第二阶
{"epochs": 4000, "lr": 1e-5, "weights": [1.0, 1.0, 1.0, 1.0]}
]
for stage in stages:
print(f"训练阶段:学习率={stage['lr']}, 权重={stage['weights']}")
train_pinn(
model, x_physics, t_physics,
x_bc_up, t_bc, v_bc_up,
x_bc_down, t_bc, h_bc_down,
stage["epochs"], stage["lr"], stage["weights"]
)
x_test = tf.linspace(0, L, 100)[:, None]
t_test = tf.ones_like(x_test) * 300.0 # t=300s
inputs = tf.concat([x_test, t_test], axis=1)
vh_pred = model(inputs)
v_pred, h_pred = vh_pred[:, 0], vh_pred[:, 1]
plt.figure(figsize=(10, 5))
plt.plot(x_test, v_pred, label="预测流速 (v)")
plt.plot(x_test, h_pred, label="预测水位 (h)")
plt.xlabel("x (m)")
plt.ylabel("值")
plt.legend()
plt.savefig("pinn_result.png")
plt.close()
if __name__ == "__main__":
main()
结论
本文提出并测试了用于求解SVE的物理信息神经网络。PINN框架能准确预测假设场景和历史洪水场景结果,误差小。可求解基于速度和流量的浅水方程,能对下游赛普拉斯溪案例在大流量下准确预测流量和水位。实验结果表明PINN理论上可获小残差解,还能进行位置和时间外推,与参考数据高度吻合。
不足以及展望
PINN训练时间长,因优化器找最优解难,且本文方法集成数值计算,GPU处理表现差。且PDE在边界和初始条件不确定时有无限解,PINN只能在特定边界条件下求近似解,不同条件需重新训练。后续希望探索优化训练算法或硬件加速方式,减少PINN训练时间,如改进GPU对数值计算的处理能力。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









