









题目信息
- 题目: An Improved PINN Algorithm for Shallow Water Equations Driven by Deep Learning
- 期刊: Symmetry
- 作者: Yanling Li, Qianxing Sun, Junfang Wei, Chunyan Huang
- 发表时间: Symmetry
- 文章链接:https://www.mdpi.com/2073-8994/16/10/1376
摘要
传统数值算法求解浅水方程时,依赖复杂的网格离散化,计算成本高,且无法预测任意时间点的解。数据驱动的机器学习方法虽在多领域取得进展,但在复杂领域尤其是数据稀缺场景下应用受限。且传统机器学习算法未充分利用先验知识,导致算法泛化能力较低。因此本文提出一种改进的PINN算法求解浅水方程,算法基于PINN和LSTM模型,在损失函数中引入L1正则化项作为惩罚,并在LSTM网络结构中加入注意力机制。通过一维浅水方程模拟实验,与经典PINN算法对比,结果表明改进算法在捕捉细节和处理复杂现象等方面优势显著,虽增加了计算成本,但更适用于需要精确细节和复杂流动模拟的场景。
创新点
将L1正则化项引入PINN损失函数,使模型更简洁易解释,避免过拟合;在LSTM网络结构中融入注意力机制,增强模型性能和表征能力;结合L1正则化、PINN和LSTM网络,提升浅水方程数值解精度。
网络架构
关于L1正则化这个知识点,有点遗忘了,所以现在来回顾一下:
对于L1正则化中任何的正则化算子,如果他在Wi=0的地方不可微,并且可以分解为“求和” 的形式,那么这个正则化算子就可以实现稀疏。

LSTM主要分为3个部分,分别是输入门、遗忘门、输出门。
输入门: 输入门决定当前时间步 𝑡 的输入信息 xt 中哪些将被存储到单元状态Ct。
it是通过sigmoid函数计算的输入门激活值,范围 [0,1],控制信息保留程度。
W
i
,
U
i
,
W
c
,
U
c
W_{i}, U_{i}, W_{c}, U_{c}
Wi,Ui,Wc,Uc为权重矩阵为权重矩阵,
b
i
,
b
c
b_i,b_c
bi,bc为偏置。
i
t
=
σ
(
W
i
x
t
+
U
i
h
t
−
1
+
b
i
)
i_t = \sigma(W_i x_t + U_i h_{t-1} + b_i)
it=σ(Wixt+Uiht−1+bi)
C
ˉ
t
\bar{C}_t
Cˉt是候选单元状态,通过 Tanh 函数生成。
C
ˉ
t
=
tanh
(
W
c
x
t
+
U
c
h
t
−
1
+
b
c
)
\bar{C}_t = \tanh(W_c x_t + U_c h_{t-1} + b_c)
Cˉt=tanh(Wcxt+Ucht−1+bc)
tanh函数的输出范围在-1到1之间,具有零中心性质,即均值为0。
有助于减少梯度消失问题,使得神经网络的训练更加稳定和快速
遗忘门: 遗忘门ft决定是否丢弃上一时间步的单元状态
C
t
−
1
C_{t-1}
Ct−1,范围 [0,1],0 表示完全丢弃,1 表示完全保留。W与b的含义同上。
f
t
=
σ
(
W
f
x
t
+
U
f
h
t
−
1
+
b
f
)
f_t = \sigma(W_f x_t + U_f h_{t-1} + b_f)
ft=σ(Wfxt+Ufht−1+bf)
单元状态更新:当前单元状态Ctt通过输入门和遗忘门的组合更新,
i
t
⊗
C
ˉ
t
i_t \otimes \bar{C}_t
it⊗Cˉt表示表示新输入的信息,
f
t
⊗
C
t
−
1
f_t \otimes C_{t-1}
ft⊗Ct−1示保留的上一时间步信息。
C
t
=
i
t
⊗
C
ˉ
t
+
f
t
⊗
C
t
−
1
C_t = i_t \otimes \bar{C}_t + f_t \otimes C_{t-1}
Ct=it⊗Cˉt+ft⊗Ct−1
Hadamard乘积 是矩阵的一类运算,对形状相同的矩阵进行运算,并产生相同维度的第三个矩阵。
如: ( A ⊗ B ) i j = a i j ∗ b i j (\boldsymbol{A} \otimes\boldsymbol{B})_{i j}=a_{i j} * b_{i j} (A⊗B)ij=aij∗bij
输出门: 输出门决定当前时间步的输出 ht。
ot是通过 sigmoid 函数计算的输出门激活值,控制输出信息。
o
t
=
σ
(
W
o
x
t
+
U
o
h
t
−
1
+
b
o
)
o_t = \sigma(W_o x_t + U_o h_{t-1} + b_o)
ot=σ(Woxt+Uoht−1+bo)
h t是单元状态 𝐶𝑡 经过 Tanh 激活后与ot逐元素相乘的结果。W与b的含义同上。
h
t
=
o
t
⊗
tanh
(
C
t
)
h_t = o_t \otimes \tanh(C_t)
ht=ot⊗tanh(Ct)

一维浅水方程描述了水深和动量如何随时间和空间变化,适用于模拟河流或湖泊中的水流。
该方程以守恒形式表示为:
∂
t
(
h
h
u
)
+
∂
x
(
h
u
h
u
2
+
1
2
g
h
2
)
=
0
\partial_t \begin{pmatrix} h \\ hu \end{pmatrix} + \partial_x \begin{pmatrix} hu \\ hu^2 + \frac{1}{2}gh^2 \end{pmatrix} = 0
∂t(hhu)+∂x(huhu2+21gh2)=0
h 表示总水深;hu 表示动量;u 为沿 x 方向的平均流速;g 为重力加速度常数。
输入:时空坐标 (x,t)
输出:神经网络的解 𝑈𝜃,其中 θ 表示网络参数(权重 w 和偏置 b)。
结构:使用多层全连接神经网络,结合非线性激活函数(Tanh),通过自动微分计算输出对输入的偏导数,构造方程残差
F
(
x
,
t
)
=
∂
t
U
θ
+
∂
x
f
(
U
θ
)
F(x, t) = \partial_t U_\theta + \partial_x f(U_\theta)
F(x,t)=∂tUθ+∂xf(Uθ)
其中Uθ(x,t) 表示神经网络输出的解,包含水深 hθ(x,t) 和流速uθ(x,t)
损失函数:损失函数由数据拟合损失和方程残差两部分组成:
LOSS
(
θ
)
=
ω
h
L
h
(
θ
)
+
ω
u
L
u
(
θ
)
+
ω
f
L
f
(
θ
)
+
α
∥
w
∥
1
\text{LOSS}(\theta) = \omega_h L_h(\theta) + \omega_u L_u(\theta) + \omega_f L_f(\theta) + \alpha \|w\|_1
LOSS(θ)=ωhLh(θ)+ωuLu(θ)+ωfLf(θ)+α∥w∥1
ω h ,ω u,ω f为权重,用于平衡各损失项的比例。
其中:
L
h
=
1
N
∑
n
=
1
N
[
h
(
x
n
,
t
n
)
−
h
θ
(
x
n
,
t
n
)
]
2
L_h = \frac{1}{N} \sum_{n=1}^N \left[ h(x^n, t^n) - h_\theta(x^n, t^n) \right]^2
Lh=N1∑n=1N[h(xn,tn)−hθ(xn,tn)]2,表示水深的数据拟合损失
L
u
=
1
N
∑
n
=
1
N
[
u
(
x
n
,
t
n
)
−
u
θ
(
x
n
,
t
n
)
]
2
L_u = \frac{1}{N} \sum_{n=1}^N \left[ u(x^n, t^n) - u_\theta(x^n, t^n) \right]^2
Lu=N1∑n=1N[u(xn,tn)−uθ(xn,tn)]2,流速的数据拟合损失。
L
f
=
1
N
∑
n
=
1
N
∥
F
(
x
n
,
t
n
)
∥
2
L_f = \frac{1}{N} \sum_{n=1}^N \left\| F(x^n, t^n) \right\|^2
Lf=N1∑n=1N∥F(xn,tn)∥2,方程残差损失
(
x
n
,
t
n
)
(x^n, t^n)
(xn,tn)。
α
∥
w
∥
1
\alpha \|w\|_1
α∥w∥1则是加入了L1正则化,该项通过惩罚权重的绝对值和,促进模型稀疏性,减少过拟合,增强对浅水方程物理特征的捕捉能力。
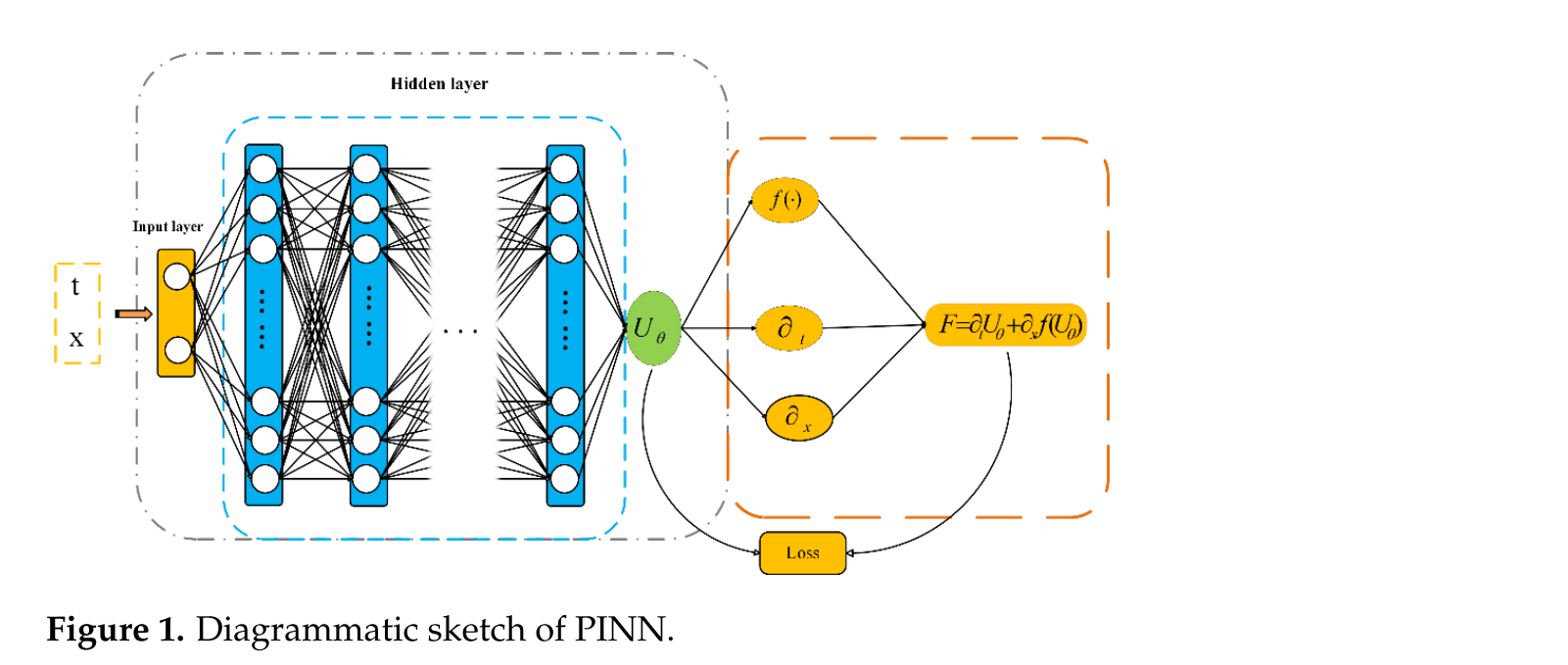
实验
该论文通过一维浅水方程的具体算例验证改进算法的性能,并与经典PINN算法进行对比,具体实验结果和数据分析如下:
一维溃坝问题
初始条件:
h
(
x
,
0
)
=
{
2
,
x
<
0
1
,
x
>
0
h(x, 0) = \begin{cases} 2, & x < 0 \\ 1, & x > 0 \end{cases}
h(x,0)={2,1,x<0x>0
初始水深条件,模拟水从高水位 (h=2) 流向低水位 (h=1) 的场景。
经典PINN在数值模拟中t = 0附近存在非物理数值振荡,导致激波和稀疏波不符合实际物理行为;改进算法能清晰展现激波和稀疏波的传播,边缘处不受数值耗散过度影响,能准确捕捉波的传播,且在t = 0.08、t = 0.12、t = 0.16时刻的解与参考解接近,激波和稀疏波拐角处无平滑现象,对细节更敏感。
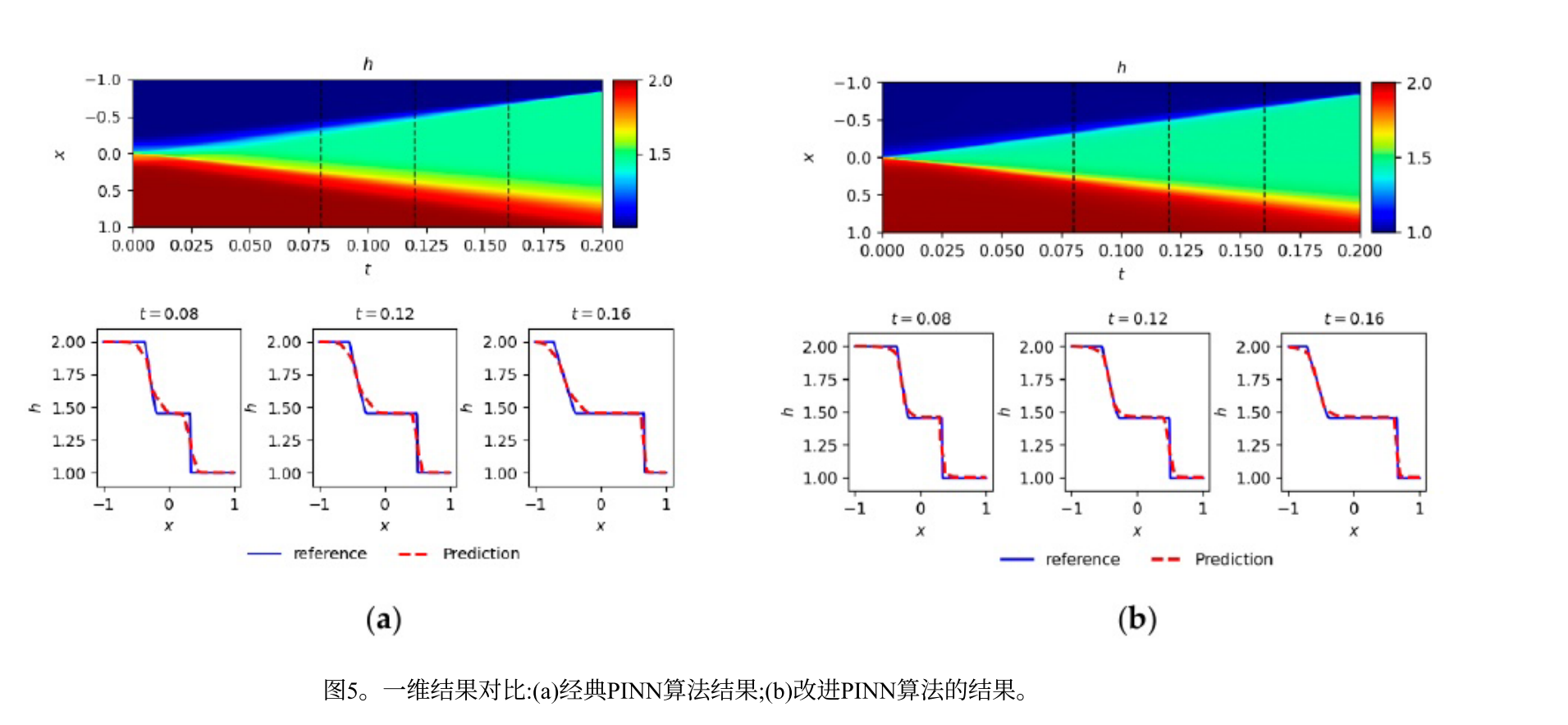
采用RMSE量化与参考解的整体误差,结果显示改进PINN的RMSE值更小,且随时间推移整体误差减小,表明改进算法数值稳定性更好,能更准确描述系统真实动态行为。
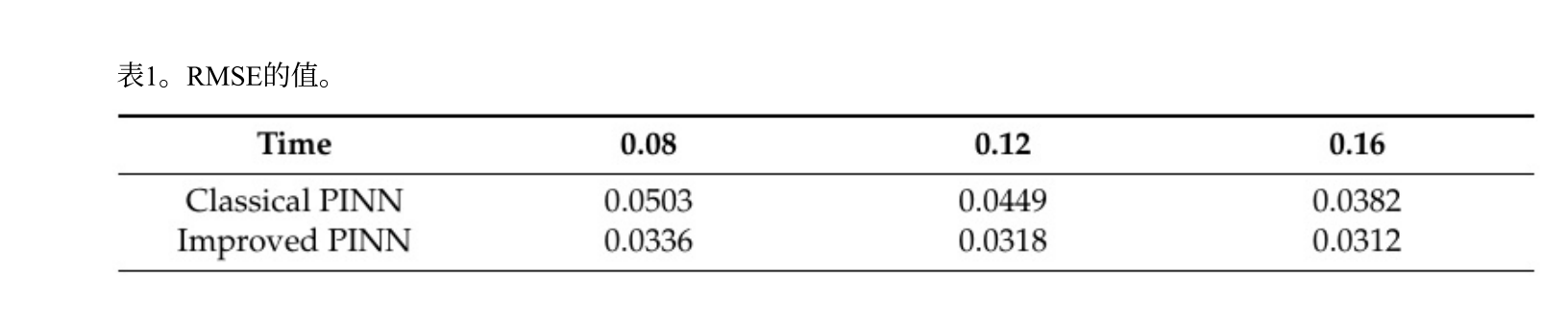
对比训练过程中损失函数的收敛情况,改进PINN收敛速度更快、拟合精度更高,训练过程中损失波动更小,更稳定可靠。
论文代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 注意力机制
class SimpleAttention(nn.Module):
def __init__(self, hidden_dim):
super(SimpleAttention, self).__init__()
self.attn = nn.Linear(hidden_dim, 1) # 简化为单层线性变换
def forward(self, x):
# x: [batch_size, seq_len=1, hidden_dim]
weights = torch.softmax(self.attn(x), dim=1) # 计算注意力权重
out = x * weights # 加权
return out
class ImprovedPINN(nn.Module):
def __init__(self):
super(ImprovedPINN, self).__init__()
# 全连接层:简化到3层
self.fc1 = nn.Linear(2, 32) # 输入 [x, t]
self.fc2 = nn.Linear(32, 32)
self.fc3 = nn.Linear(32, 16)
# LSTM层:单层,隐藏维度16
self.lstm = nn.LSTM(input_size=16, hidden_size=16, num_layers=1, batch_first=True)
# 简化的注意力层
self.attention = SimpleAttention(16)
# 输出层:预测 h 和 hu
self.output = nn.Linear(16, 2)
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
def forward(self, x, t):
# 输入拼接:x, t -> [batch_size, 2]
inputs = torch.cat([x, t], dim=1)
# 全连接层
inputs = torch.tanh(self.fc1(inputs))
inputs = torch.tanh(self.fc2(inputs))
inputs = self.fc3(inputs)
# 扩展为序列输入给LSTM
inputs = inputs.unsqueeze(1) # [batch_size, seq_len=1, 16]
# LSTM
lstm_out, _ = self.lstm(inputs) # [batch_size, seq_len=1, 16]
# 注意力
attn_out = self.attention(lstm_out) # [batch_size, seq_len=1, 16]
# 输出
out = self.output(attn_out.squeeze(1)) # [batch_size, 2]
h = out[:, 0:1] # 水深 h
hu = out[:, 1:2] # 动量 hu
return h, hu
# 计算物理损失(浅水方程残差)
def physics_loss(model, x, t, g=9.8):
x = x.requires_grad_(True)
t = t.requires_grad_(True)
h, hu = model(x, t)
u = hu / h # 流速 u = hu / h
# 计算偏导数
h_t = torch.autograd.grad(h, t, grad_outputs=torch.ones_like(h), create_graph=True)[0]
h_x = torch.autograd.grad(h, x, grad_outputs=torch.ones_like(h), create_graph=True)[0]
hu_t = torch.autograd.grad(hu, t, grad_outputs=torch.ones_like(hu), create_graph=True)[0]
hu_x = torch.autograd.grad(hu, x, grad_outputs=torch.ones_like(hu), create_graph=True)[0]
# 浅水方程残差:
# \partial_t h + \partial_x (hu) = 0
res1 = h_t + hu_x
# \partial_t (hu) + \partial_x (hu^2 + \frac{1}{2} g h^2) = 0
flux = hu * u + 0.5 * g * h**2
flux_x = torch.autograd.grad(flux, x, grad_outputs=torch.ones_like(flux), create_graph=True)[0]
res2 = hu_t + flux_x
# 残差均方误差
loss_f = torch.mean(res1**2 + res2**2)
return loss_f
# L1 正则化
def l1_regularization(model, alpha=1e-4):
l1_loss = 0.0
for param in model.parameters():
l1_loss += torch.sum(torch.abs(param))
return alpha * l1_loss
# 生成训练数据
def generate_training_data(N, x_range=(-1, 1), t_range=(0, 0.2)):
x = np.random.uniform(x_range[0], x_range[1], N)
t = np.random.uniform(t_range[0], t_range[1], N)
x_tensor = torch.FloatTensor(x).reshape(-1, 1).to(device)
t_tensor = torch.FloatTensor(t).reshape(-1, 1).to(device)
return x_tensor, t_tensor
# 初始条件
def initial_condition(x):
h = np.where(x < 0, 2.0, 1.0)
u = np.zeros_like(x)
return h, u
# 训练函数
def train(model, epochs=5000, N=500, lr=1e-3):
optimizer = optim.Adam(model.parameters(), lr=lr)
# 初始条件数据
x_ic = np.linspace(-1, 1, 50)
h_ic, u_ic = initial_condition(x_ic)
x_ic_tensor = torch.FloatTensor(x_ic).reshape(-1, 1).to(device)
t_ic_tensor = torch.zeros_like(x_ic_tensor).to(device)
h_ic_tensor = torch.FloatTensor(h_ic).reshape(-1, 1).to(device)
u_ic_tensor = torch.FloatTensor(u_ic).reshape(-1, 1).to(device)
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
# 随机训练点
x_col, t_col = generate_training_data(N)
# 前向传播
h_pred, hu_pred = model(x_col, t_col)
u_pred = hu_pred / h_pred
# 物理损失
loss_f = physics_loss(model, x_col, t_col)
# 初始条件损失
h_ic_pred, hu_ic_pred = model(x_ic_tensor, t_ic_tensor)
u_ic_pred = hu_ic_pred / h_ic_pred
loss_ic_h = torch.mean((h_ic_pred - h_ic_tensor)**2)
loss_ic_u = torch.mean((u_ic_pred - u_ic_tensor)**2)
# L1 正则化
loss_l1 = l1_regularization(model)
# 总损失
loss = 1.0 * loss_f + 1.0 * loss_ic_h + 1.0 * loss_ic_u + loss_l1
# 反向传播
loss.backward()
optimizer.step()
# 打印损失
if (epoch + 1) % 1000 == 0:
print(f"Epoch [{epoch+1}/{epochs}], 总损失: {loss.item():.6f}, "
f"物理损失: {loss_f.item():.6f}, 初始 h 损失: {loss_ic_h.item():.6f}, "
f"初始 u 损失: {loss_ic_u.item():.6f}, L1 损失: {loss_l1.item():.6f}")
# 可视化
def plot_results(model, x_range=(-1, 1), t=0.2, N=100):
x = np.linspace(x_range[0], x_range[1], N)
x_tensor = torch.FloatTensor(x).reshape(-1, 1).to(device)
t_tensor = torch.full_like(x_tensor, t).to(device)
model.eval()
with torch.no_grad():
h_pred, hu_pred = model(x_tensor, t_tensor)
u_pred = hu_pred / h_pred
h_pred = h_pred.cpu().numpy()
u_pred = u_pred.cpu().numpy()
# 绘制结果
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(x, h_pred, label="预测水深 h")
plt.title(f"水深 h (t={t})")
plt.xlabel("x")
plt.ylabel("h")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(x, u_pred, label="预测流速 u")
plt.title(f"流速 u (t={t})")
plt.xlabel("x")
plt.ylabel("u")
plt.legend()
plt.tight_layout()
plt.show()
# 主函数
def main():
model = ImprovedPINN().to(device)
train(model, epochs=5000, N=500, lr=1e-3)
plot_results(model, t=0.2)
if __name__ == "__main__":
main()
结论
本文在经典PINN基础上引入LSTM网络、注意力机制和L1正则化项。在一维浅水方程模拟中,改进算法处理间断问题优势明显,随时间推移捕捉激波和稀疏波能力增强。
不足以及展望
引入LSTM和注意力机制虽提升了模型性能,但显著增加了计算负担。如在一维问题中,改进PINN的运行时间均比经典PINN长。另外,损失函数权重选择主要基于实验方法,缺乏自适应调整机制,可能影响模型的收敛速度和准确性。后续可进一步探索该算法在实际流体动力学问题中的应用,如洪水模拟和海岸工程等,与实际领域合作验证算法有效性和潜在影响。还可考虑引入自适应权重机制,如基于损失变化的自适应权重调整方法和贝叶斯优化技术,以加速收敛速度、提高模型精度。

















 8186
8186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









