






 FSPNet是一种基于Transformer的特征收缩金字塔网络,用于伪装目标检测。它通过非局部token增强模块(NL-TEM)强化局部特征,并使用特征收缩解码器(FSD)来层次性地融合和积累特征,提高伪装目标检测的准确性。NL-TEM利用非局部机制和图卷积网络增强局部表示,而FSD通过逐层收缩来优化特征聚合,避免信息丢失。
FSPNet是一种基于Transformer的特征收缩金字塔网络,用于伪装目标检测。它通过非局部token增强模块(NL-TEM)强化局部特征,并使用特征收缩解码器(FSD)来层次性地融合和积累特征,提高伪装目标检测的准确性。NL-TEM利用非局部机制和图卷积网络增强局部表示,而FSD通过逐层收缩来优化特征聚合,避免信息丢失。
前言
目前,一些工作已尝试使用Transformer解决伪装目标检测问题,并且性能良好。这些方法要么采用Transformer作为特征解码的网络组件,要么利用现成的vision Transformer作为特征编码器的backbone。通过对这些方法的深入分析,作者发现现有技术存在两个主要问题:
- Transformer backbone的局部特征建模效果较差。全局语义和局部特征在伪装目标检测任务中都起着至关重要的作用。然而,大多数基于Transformer的方法缺乏局部区域内信息交换的局部性机制。
- 特征聚合在解码器中的局限性。现有的解码器(图a-d)往往直接融合具有显著信息差异的特征(例如,具有丰富细节的低级特征和具有语义的高级特征),这往往会丢弃一些不明显但是有价值的线索,或者引入噪声,导致预测不准确。这对从微弱线索中识别伪装目标的任务来说是一个巨大打击。
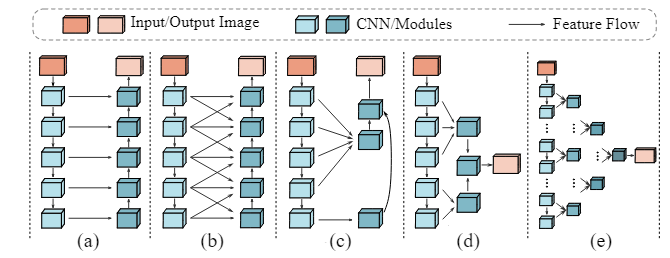
为解决上述两个问题,作者提出了一种基于Transformer的特征收缩金字塔网络FSPNet。通过逐步缩小来获取伪装目标的局部性增强的全局表示,来达到分层解码相邻的transformer特征的目的,从而在编码器和解码器中挖掘和积累丰富的伪装目标局部线索和全局语义,实现准确、完整的伪装目标分割。
具体地说,为了补充Transformer编码器中的局部特征建模,作者提出了一个非局部token增强模块(NL-TEM),该模块利用非本地机制来交互相邻的相似token,并探索token内基于图的高层关系来增强局部表示。
此外,作者还设计了一个具有相邻交互模块(AIMs)的特征收缩编码器(FSD),通过一个逐层收缩金字塔结构将相邻的Transformer特征成对地聚集起来,以尽可能多地积累微小但有效的细节和语义。
总结贡献如下:
- 提出非局部token增强模块(NL-TEM),用于token之间和token内部的特征交互和探索,以补偿Transformer的局部建模。
- 利用相邻交互模块(AIM)设计了一种特征收缩解码器(FSD),通过逐步收缩来更好的聚合相邻Transformer特征之间的伪装目标线索,实现伪装目标检测
- 实现了优越的性能
1. 模型的特点
模型整体结构如下所示。
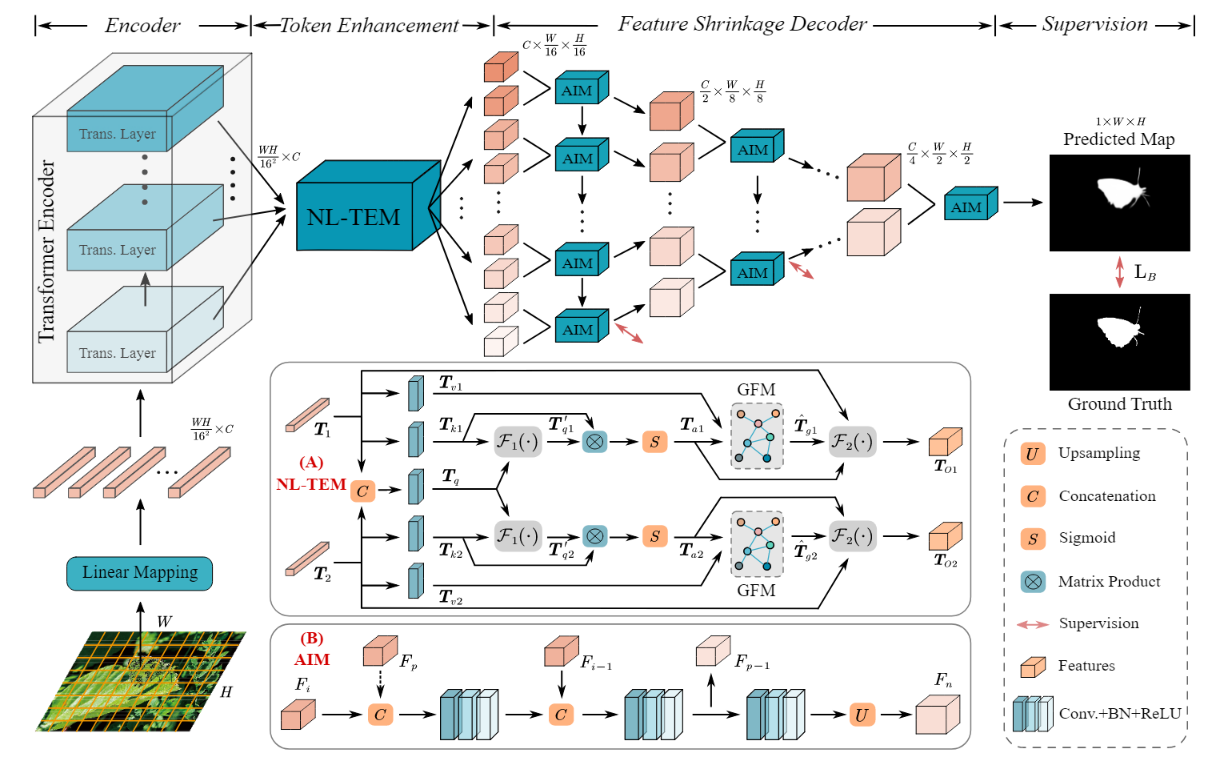
2. Transformer 编码器
a)序列化
受Swin-Transformer的启发,给定图像 I ∈ R C × H × W I \in \mathbb R^{C \times H \times W} I∈RC×H×W,首先将其分割成一系列不重叠的图像patch,patch大小为(s,s),其中C、H、W分别表示图片的通道数、高度和宽度,且实验中s=16。
然后将图像patch投影成patch embedding的一维序列 T 0 ∈ R l × d T^0 \in \mathbb R^{l \times d} T0∈Rl×d,其中 l = H W s 2 l=\frac{HW}{s^2} l=s2HW为序列长度, d = s 2 ⋅ C d=s^2 \cdot C d=s2⋅C是embedding维数。
b)Transformer层
为了保留位置信息,将可学习的位置embedding E p E^p Ep添加到token中,形成新的token, T p = T 0 + E p T^p=T^0+E^p Tp=T0+Ep。然后将所有token输入到具有n个transformer 层的transformer编码器中,其中每层包含一个多头自注意力(MSA)和一个多层感知机(MLP)。数学表示如下:
T = M L P ( M S A ( T p ) ) T=MLP(MSA(T^p)) T=MLP(MSA(Tp))
其中, T ∈ R l × c T \in \mathbb R^{l \times c} T∈Rl×c,c是token的维度数。
注意,在每个block之前使用了层归一化,在每个block之后使用了残差连接。从而从编码器中获得输出token。
3. 非局部token增强模块(NL-TEM)
受论文Non-local Neural Networks(非局部神经网络)的启发,设计了一个非局部token增强模块(NL-TEM),使用相邻token(局部区域)来增强局部特征表示。
首先采用非局部操作对相邻相似token进行交互,聚合相邻伪装线索。然后采用图卷积网络(GCN)运算来探索标记内不同像素之间的告诫语义关系,以发现细微的判别特征。
如下图所示。具体来说,给定来自Transformer编码器的两个相邻token T 1 T_1 T1和 T 2 T_2 T2,首先将它们归一化。以 T 1 T_1 T1为例,分别通过两个线性投影函数( w v w_v wv和 w k w_k wk)来得到特征序列 T v T_v Tv和 T k T_k Tk( ∈ R l × c 2 \in \mathbb R^{l \times \frac{c}{2}} ∈Rl×2c),分别表示为 T v = w v ( T 1 ) T_v=w_v(T_1) Tv=wv(T1)和 T k = w k ( T 1 ) T_k=w_k(T_1) Tk=wk(T1)。
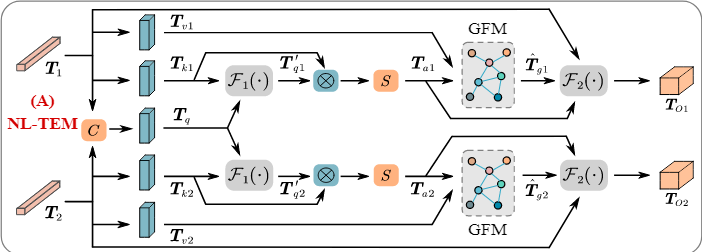
此外,将 T 1 T_1 T1和 T 2 T_2 T2拼接起来,得到一个集成的令牌 T q T_q Tq,它聚集了两个令牌的特征,然后利用它于各自的输入令牌交互以增强特征。具体来说,在这个token上执行另一个线性投影函数 w q w_q wq,来降维 c 2 \frac{c}{2} 2c。然后使用softmax函数生成一个权重映射 T q w T_q^w Tqw。接下来,使用映射通过元素乘法对 T k T_k Tk进行加权,然后进行自适应平均池化操作(P( ⋅ \cdot ⋅))以减少计算成本。上述操作 F 1 ( ⋅ ) F_1(\cdot) F1(⋅)可以表示为:
T q ′ = F 1 ( T k , T q ) = P ( T k ⊙ s o f t m a x ( w q ( T q ) ) ) T'_q=F_1(T_k,T_q)=P(T_k \odot softmax(w_q(T_q))) Tq′=F1(Tk,Tq)=P(Tk⊙softmax(wq(Tq)))
然后,对 T k T_k Tk和 T q ′ T'_q Tq′进行矩阵乘法来探索二者之间的相关性,并使用softmax运算生成注意力图 T a T_a Ta,记为 T a = s o f t m a x ( T q ′ ⊗ T k ⊤ ) T_a=softmax(T'_q \otimes T_k^{\top}) Ta=softmax(Tq′⊗Tk⊤)。
类似于论文Edge-aware Graph Representation Learning and Reasoning for Face Parsing中的做法。将交互token T a T_a Ta和token T v T_v Tv送入图像融合模块(GFM)中。在GFM中, T v T_v Tv通过注意力图 T a T_a Ta被投影到图域,表示为 T g = T v ⊗ T a ⊤ T_g=T_v \otimes T_a^{\top} Tg=Tv⊗Ta⊤。
在此过程中,将具有相似特征的像素集合(“区域”)投影到一个顶点,并采用单层GCN学习区域之间的高级语义关系,并通过跨顶点信息在图上传播,对非局部区域进行推理,以捕获token内的全局表示。具体来说,将顶点特征 T g T_g Tg输入到谱图卷积的一阶近似中,我们可以得到输出的 T g ^ \hat{T_g} Tg^:
T g ^ = R e L U ( ( I − A ) T g w g ) \hat{T_g}=ReLU((I-A)T_gw_g) Tg^=ReLU((I−A)Tgwg)
其中, A A A是编码图连通性的邻接矩阵,而 w g ∈ R 16 × 16 w_g \in \mathbb R^{16 \times 16} wg∈R16×16是GCN的权重。
最后,使用跳跃连接将输入的token T 1 T_1 T1于基于图的增强表示相结合,然后使用反序列化( D ( ⋅ ) D(\cdot) D(⋅))运算将token序列转换为与原始特征具有相同维度的2D图像特征用于解码,如下所示:
T O 1 = F 2 ( T g ^ , T a , T 1 ) = D ( T g ^ ⊗ T a ⊤ + T 1 ) T_{O1}=F_2(\hat{T_g},T_a,T_1)=D(\hat{T_g} \otimes T_a^{\top}+T_1) TO1=F2(Tg^,Ta,T1)=D(Tg^⊗Ta⊤+T1)
其中, T O 1 ∈ R C × H s × W s T_{O1} \in \mathbb R^{C \times \frac{H}{s} \times \frac{W}{s}} TO1∈RC×sH×sW是从token输出的局部增强特征。我们可以经过同样过程得到 T O 2 T_{O2} TO2。
4. 特征收缩解码器(FSD)
特征收缩解码器同时构建自下而上和从左到右的特征流以保留更有用的特征。所提出的解码器可以平滑地流动和积累伪装对象线索,避免特征差异过大造成干扰。
具体来说,假设 F i F_i Fi和 F i − 1 F_{i-1} Fi−1是当前层的相邻特征对, F p F_p Fp是前一个AIM输出的聚合特征,则AIM可以表示为:
F p = C B R ( C a t ( C B R ( C a t ( F p − 1 , F i ) ) , F i − 1 ) ) a n d F i ′ = U p ( C B R ( F p ) ) F_p=CBR(Cat(CBR(Cat(F_{p-1},F_i)),F_{i-1})) \quad and \quad F'_i=Up(CBR(F_p)) Fp=CBR(Cat(CBR(Cat(Fp−1,Fi)),Fi−1))andFi′=Up(CBR(Fp))
其中, F p F_p Fp是传递给下一个AIM的特征, F i ′ F'_i Fi′是当前AIM针对下一层的输出特征。 C B R ( ⋅ ) CBR(\cdot) CBR(⋅)由卷积、批归一化和ReLU操作组成。 C A T ( ⋅ ) CAT(\cdot) CAT(⋅)和 U p ( ⋅ ) Up(\cdot) Up(⋅)分别是拼接和2倍上采样。
注意FSD一共包含4层收缩金字塔和12个AIM。算法1总结了FSD的整个过程,最后以此AIM的输出特征通过sigmoid和上采样操作后的GT来监督伪装目标预测。

作者还是用二元交叉熵损失(LBCE)来监督FSD每一层的输出预测( P i P_i Pi),并为检测精度较低的浅层输出分配较小的权重。最后,总损失函数为:
L t o t a l = ∑ i = 0 2 2 ( i − 4 ) L b c e ( P i , G ) + L b c e ( P 3 , G ) L_{total}=\sum_{i=0}^2 2^{(i-4)}L_{bce}(P_i,G)+L_{bce}(P_3,G) Ltotal=i=0∑22(i−4)Lbce(Pi,G)+Lbce(P3,G)
其中,i表示FSD的第i层, P 3 P_3 P3表示输出预测的最后一层。
注意,与Pyramidal Feature Shrinking for Salient Object Detection不同,FSD不仅采用了跨层的特征交互,而且还采用了同层内的特征交互,以更好地在金字塔结构中流动和积累有效的特征,从而更有效地捕获微小但关键的特征。
此外,我们对每一层进行横向监督,迫使每一层解码器层挖掘和聚合有效的伪装目标特征。此外为了简化编码器的结构,该解码器只集成相邻的特征,没有重叠。
模型效果很好,但是参数量如何?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









