






目录
前言
OSFormer模型中提到了反向边缘注意(Reverse Edge Attention)模块,通过十分简单的操作,就可以预测出伪装目标的边缘特征。作者也将OSFormer模型强大的细长边缘特征分割能力归功于反向边缘注意。那么,什么是反向注意(reverse attention)?反向注意有什么作用?为什么反向边缘注意可以预测出边缘特征?


1. Reverse Attention的提出
溯源Reverse Attention,发现Reverse Attention最早是2017年由来自美国南加州大学的团队提出的(Semantic Segmentation with Reverse Attention)。
这篇文章的主要目的是为了提高语义分割网络对于confusion area的预测能力。所谓的confusion area,是指网络对某些类别的预测概率都差不多大的区域。
下面这张图表示FCN网络提取特征和预测的过程。右下角表示最终预测的结果,圆形区域内部就是猫和狗重合部分的区域,也就是confusion area。
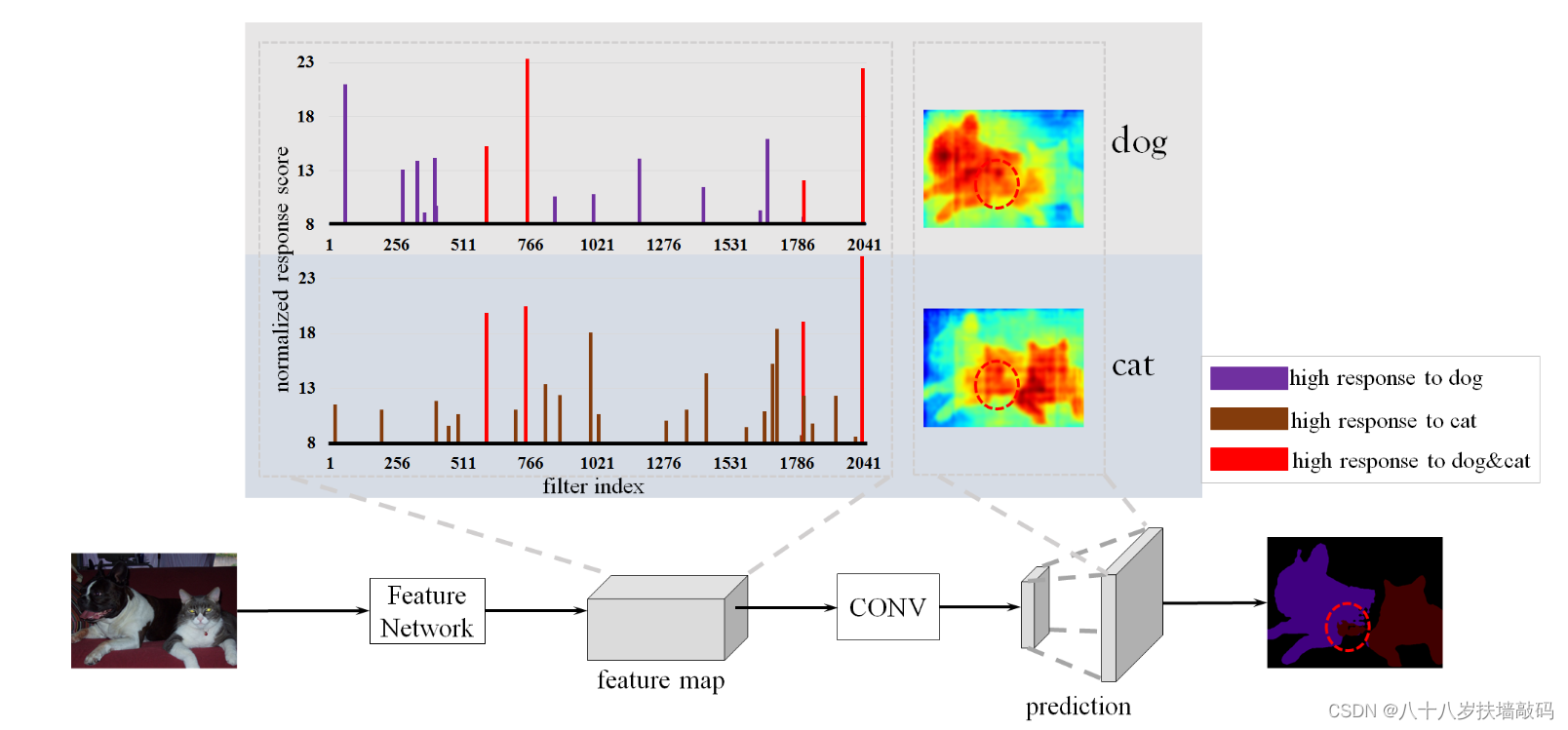
作者的观点是,FCN只是预测某个pixel属于各个类别的概率,而对于那些confusion area,如果能训练一个网络来预测得到这个区域不属于猫的概率比不属于狗的概率更大,那么结合原始FCN的预测,就可以得到这个区域应该预测成狗。所以构建了一个reverse learning process反向学习过程,来预测pixel不属于各个类别的概率。也就是Reverse Attention Network(RAN)。

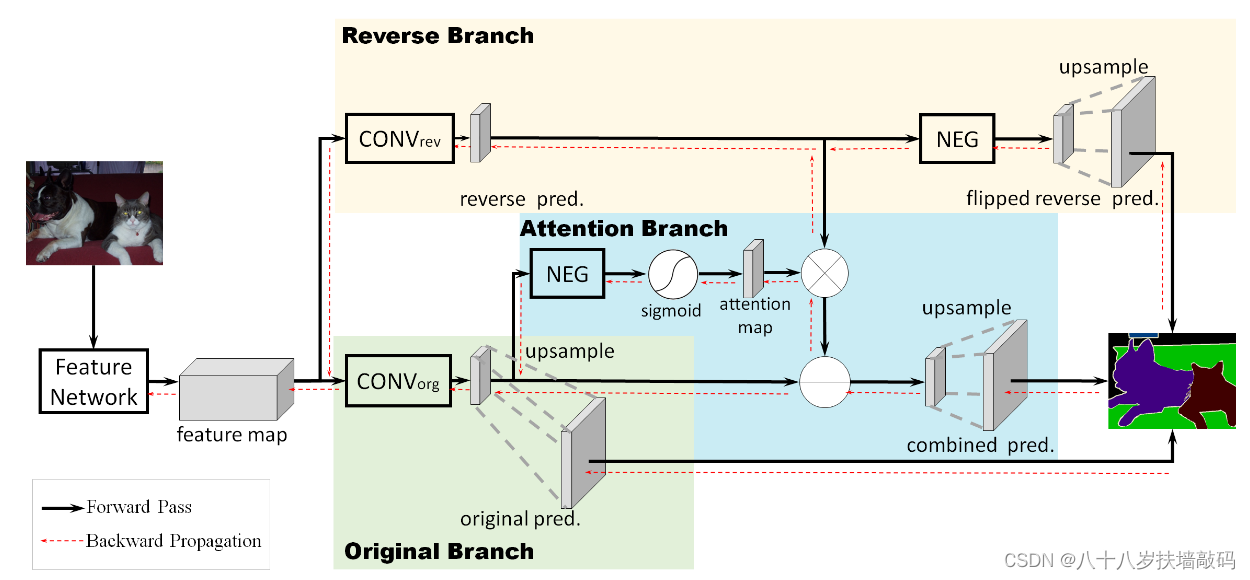
整体框架如上面两张图所示,主要分成三个分支。
- 第一个分支,也就是original branch,使用原始的FCN网络学习pixel属于各个类别的概率分布;
- 第二个分支,也就是reverse branch,学习pixel不属于各个类别的概率分布;
- 第三个分支,也就是reverse attention branch,学习第一、二个分支的预测图之间结合的权重。
最终用来预测的是经过attention branch输出的混合预测(combined pred)。
为什么需要第三个分支,也就是reverse attention branch:
最直接的想法是将original prediction和reverse prediction的结果直接相减,但是问题在于reverse learning的效果可能没有original learning的好。我们期望的是在original learning结果的confusion area上引入reverse learning的预测结果,因此需要引入一个attention机制,将reverse learning的结果引入confusion的区域。
数学表示:
I
r
a
(
i
,
j
)
=
S
i
g
m
o
i
d
(
−
F
C
O
N
V
o
r
g
(
i
,
j
)
)
I_{ra}(i,j)=Sigmoid(-F_{CONV_{org}}(i,j))
Ira(i,j)=Sigmoid(−FCONVorg(i,j))
(
i
,
j
)
(i,j)
(i,j)表示像素位置坐标,
F
C
O
N
V
o
r
g
F_{CONV_{org}}
FCONVorg表示
C
O
N
V
o
r
g
CONV_{org}
CONVorg的响应图。
由于NEG反转和sigmoid函数的作用,Reverse Attention的效果是,对于FCN原始预测
F
C
O
N
V
o
r
g
F_{CONV_{org}}
FCONVorg中负的、较小的响应将会被突出,考虑它的reverse attention;对于正的、较大的响应就会被抑制,变得很小,不考虑它的reverse attention。
2. 显著目标检测中的Reverse Attention
显著目标检测(Salient Object Detection, SOD)的目的是突出图像中的显著目标区域,通常作为图像分割、图像字幕等高级视觉任务的预处理步骤。一篇ECCV 2018的论文Reverse Attention for Salient Object Detection受到上述工作的启发,采用自上而下的reverse attention来学习更准确的残差细节。
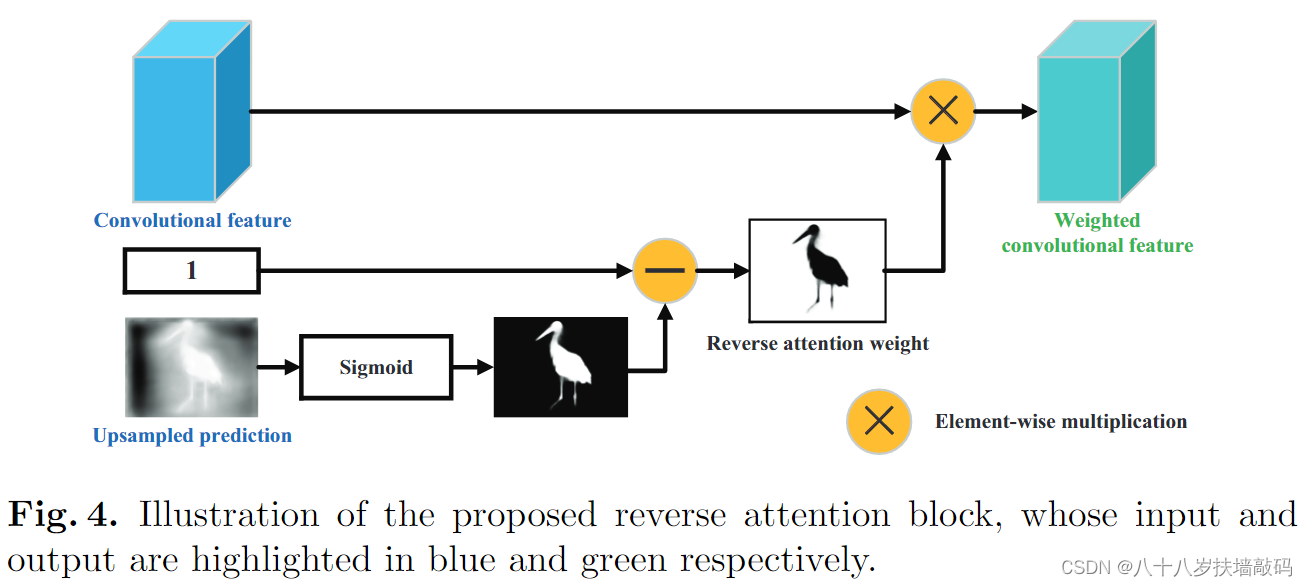
反向注意模块对应整体结构中的R模块。从最深层生成的显著图开始(最开始为Global saliency),进行上采样得到当前预测。然后用1减去使用sigmoid函数后的显著图,得到反向注意权重
A
i
=
1
−
S
i
g
m
o
i
d
(
S
i
+
1
u
p
)
A_i=1-Sigmoid(S_{i+1}^{up})
Ai=1−Sigmoid(Si+1up)。然后与所在层的卷积特征图的每一个通道做逐元素点积,得到输出的注意力特征,
F
z
,
c
=
A
z
⋅
T
z
,
c
F_{z,c}=A_z \cdot T_{z,c}
Fz,c=Az⋅Tz,c。其中,z表示特征图的空间位置,c表示特征通道的索引。
通过逐步的自上而下、自深到浅的反向注意的处理,得到最终的输出预测。

3. PraNet:用于息肉分割的并行Reverse Attention网络
PraNet是2020年发表在MICCAI的一篇文章。使模型精准地分辨息肉边缘的粘膜是息肉分割任务中的一个难点。PraNet中使用RA (Reverse Attention)模块挖掘对应的边缘信息。
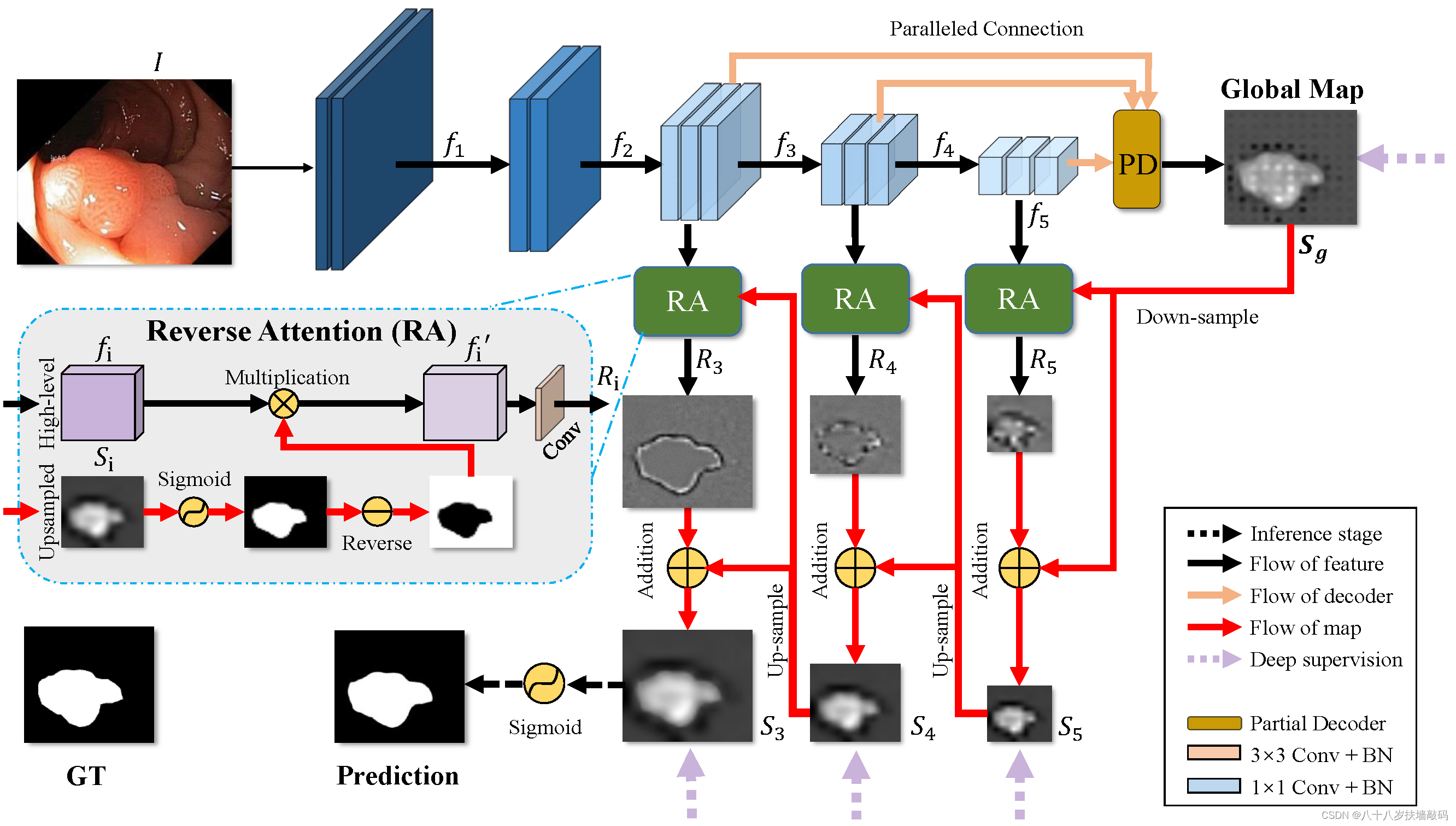
从整体网络结构中可以看到,PraNet网络结构的设计与Reverse Attention for Salient Object Detection论文中网络结构的设计十分接近。首先计算反向注意力模块的权重
A
i
=
1
−
S
i
g
m
o
i
d
(
S
i
+
1
u
p
)
A_i=1-Sigmoid(S_{i+1}^{up})
Ai=1−Sigmoid(Si+1up)。然后将高层输出特征{
f
i
,
i
=
3
,
4
,
5
f_i,i=3,4,5
fi,i=3,4,5}与
A
i
A_i
Ai做逐元素的点积,来获得反向注意力特征
R
i
R_i
Ri,即
R
i
=
f
i
⊙
A
i
R_i=f_i \odot A_i
Ri=fi⊙Ai。
4. OSFormer中的Reverse Edge Attention
了解Reverse Attention的提出及后续演进模型之后,回头再看OSFormer中对Reverse Attention的使用。从结构图中能够明显看出的是,REA模块的输入同样来自不同层级的特征图,不同点在于用于监督Reverse Attention模块卷积核参数更新的不再是Ground Truth标签,而是边缘标签和Edge loss边缘损失函数。原论文中提到,这里用于监督的边缘标签没有经过任何手工标记,而是通过侵蚀实例掩码标签来获得的。
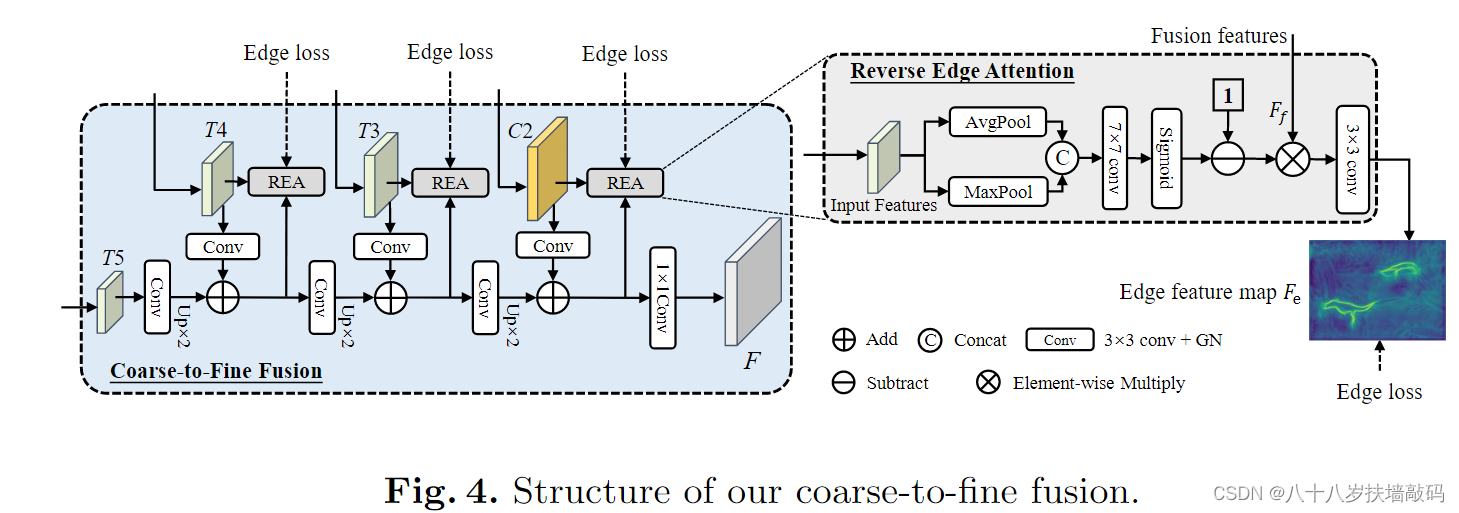
结构图中仍然有以下几个问题没有清楚说明:
- 输入REA模块的不同层级的特征图(T4、T3、C2)是否和之前的Reverse Attention一样经过了上采样?
- REA模块的输出边缘特征图 F e F_e Fe最终输出到了哪里?是否和之前的Reverse Attention一样与不同层级的REA输出相加到了一起?
- 通过侵蚀实例掩码标签来获得边缘标签是怎么实现的?
- Edge loss是怎么进行计算的?原论文中3.5节提到, L e d g e = ∑ j = 1 J L d i c e ( j ) L_{edge}=\sum_{j=1}^{J}L_{dice}^{(j)} Ledge=∑j=1JLdice(j)。那么, L d i c e L_{dice} Ldice又是什么?是V-Net论文中提到的Dice loss吗?那Dice loss有什么特别之处呢?这与之前的Reverse Attention所用的损失函数有什么区别?














 3664
3664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









