






前言
本文由迈阿密大学的研究团队于2023年3月30日发表,提出了双交叉注意力模块(Dual Cross-Attention , DCA),其目标是在轻微的参数和复杂性增加的情况下改进U-Net及其变体,能够简单而有效地增强u-net结构中的跳跃连接(skip-connection)。
DCA通过按顺序捕获多尺度编码器特征之间的通道和空间依赖关系来解决编码器特征和解码器特征之间的语义差距。
- 首先,通道交叉注意(CCA)通过利用多尺度编码器特征的跨通道token的交叉注意提取全局通道依赖关系。
- 然后,空间交叉注意(SCA)模块进行交叉注意操作,来捕获跨空间令牌的空间依赖性。
- 最后,将这些细粒度的编码器特征上采样并连接到相应的解码器部分,形成skip-connection方案。
传统的U-Net改进方法,例如残差和循环连接等存在以下缺陷:
- 卷积的局部性无法捕获不同特征之间的长距离依赖关系。
- skip-connection在简单地连接编码器和解码器特征时引起的语义差距。
受到顺序双重注意力和通道交叉注意力的启发,提出了双交叉注意力模块(DCA),有效提取多尺度编码器特征之间的通道和空间依赖,以解决语义差距问题。
1. 模型的特点
模型大致示意如下。DCA模块的结构不受编码器stage数量的影响,给定n+1个多尺度编码器stage,DCA将前n个stage的特征层作为输入,产生增强表示,并将它们连接到相应的n个解码器stage。
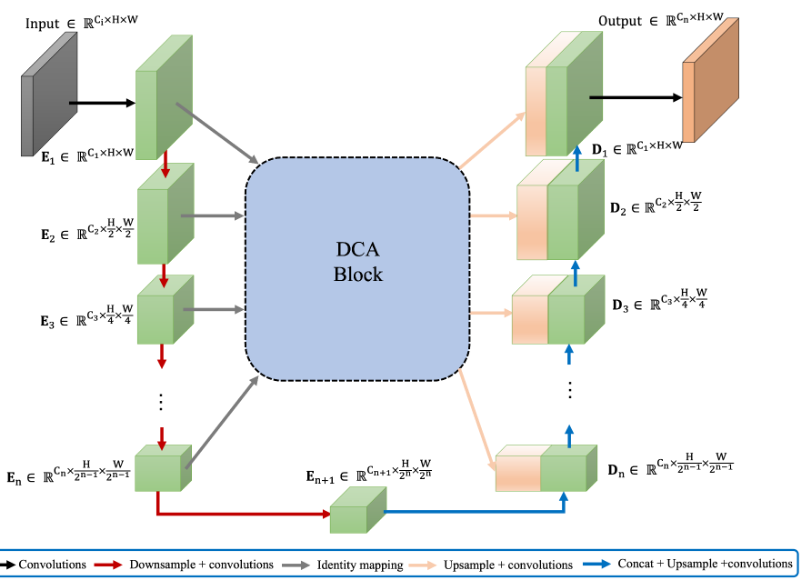
如下图所示,DCA可以分为两个主要阶段,三个步骤:
- 第一阶段由多尺度patch embedding模块组成,以获得编码器Token。
- 第二阶段,在这些编码器token上使用通道交叉注意(CCA)和空间交叉注意(SCA)模块来实现DCA,以捕获长距离依赖关系。
- 最后,使用层归一化和GeLU对这些token进行序列化和上采样,将它们连接到解码器对应部分。
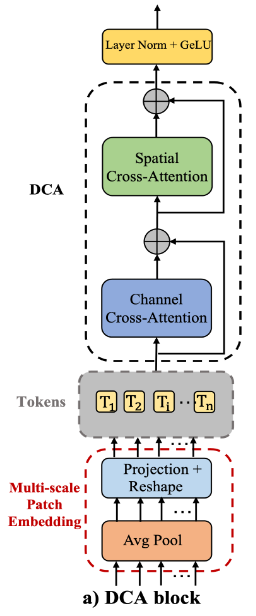
2. 基于多尺度编码器的Patch Embedding
首先从n个多尺度编码器stage中提取Patch。
给定n个不同尺度的编码器stage, E i ∈ R C i × H 2 i − 1 × W 2 i − 1 E_i \in \mathbb R^{C_i \times \frac{H}{2^{i-1}} \times \frac{W}{2^{i-1}}} Ei∈RCi×2i−1H×2i−1W,并且块大小 P i S = P S 2 i − 1 P_i^S=\frac{P^S}{2^{i-1}} PiS=2i−1PS,其中 i = 1 , 2 , … , n i=1,2,\ldots,n i=1,2,…,n。使用大小和步长为 P i S P_i^S PiS的平均池化来提取patch,并在展平的2维patch上使用 1 × 1 1 \times 1 1×1深度可分离卷积来进行映射。
T i = D C o n v 1 D E i ( R e s h a p e ( A v g P o o l 2 D E i ( E i ) ) ) T_i=DConv1D_{E_i}(Reshape(AvgPool2D_{E_i}(E_i))) Ti=DConv1DEi(Reshape(AvgPool2DEi(Ei)))
其中, T i ∈ R p × C i , ( i = 1 , 2 , … , n ) T_i \in \mathbb R^{p \times C_i},(i=1,2,\ldots,n) Ti∈Rp×Ci,(i=1,2,…,n)表示第i个编码器stage展平后的patch。注意, P P P代表patch的数量,对于每个 T i T_i Ti都是相同的,所以可以利用这些token之间的交叉注意。
3. 通道交叉注意力(CCA)
如下图所示,使用CCA对每个token T i T_i Ti进行处理。
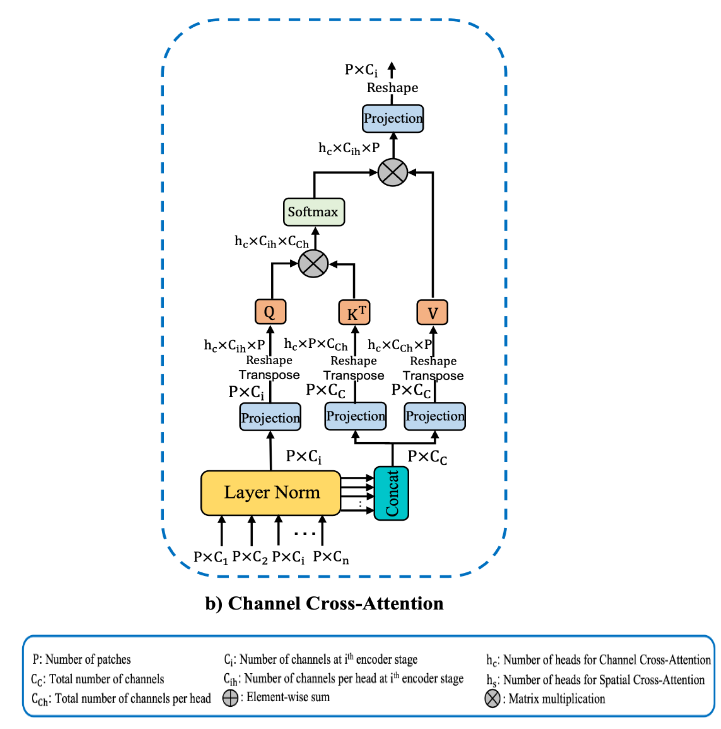
首先对每个 T i T_i Ti进行层归一化(LN),然后沿通道维度对 T i , ( i = 1 , 2 , … , n ) T_i,(i=1,2,\ldots,n) Ti,(i=1,2,…,n)进行拼接,得到 T c T_c Tc,来产生Key和Value,同时使用 T i T_i Ti作为Query。将深度可分离卷积引用到自注意力中,以便捕获局部信息并降低计算复杂性。
Q i = D C o n v 1 D Q i ( T i ) a n d K = D C o n v 1 D K ( T c ) a n d V = D C o n v 1 D V ( T c ) Q_i=DConv1D_{Q_i}(T_i) \quad and \quad K=DConv1D_K(T_c) \quad and \quad V=DConv1D_V(T_c) Qi=DConv1DQi(Ti)andK=DConv1DK(Tc)andV=DConv1DV(Tc)
其中, Q i ∈ R P × C i Q_i \in \mathbb R^{P \times C_i} Qi∈RP×Ci, K ∈ R P × C c K \in \mathbb R^{P \times C_c} K∈RP×Cc, V ∈ R P × C c V \in \mathbb R^{P \times C_c} V∈RP×Cc,分别为映射的queries,keys,values。从而CCA表示如下:
C C A ( Q i , K , V ) = S o f t m a x ( Q i T K C c ) V T CCA(Q_i,K,V)=Softmax(\frac{Q_i^TK}{\sqrt{C_c}})V^T CCA(Qi,K,V)=Softmax(CcQiTK)VT
其中 1 C c \frac{1}{\sqrt{C_c}} Cc1是比例因子。交叉注意的输出是values的加权和,权重由queries和key之间的相似性决定。最后使用深度可分离卷积对交叉注意的输出进行处理,并将其输入SCA模块。
4. 空间交叉注意力(SCA)
SCA模块如下图所示。
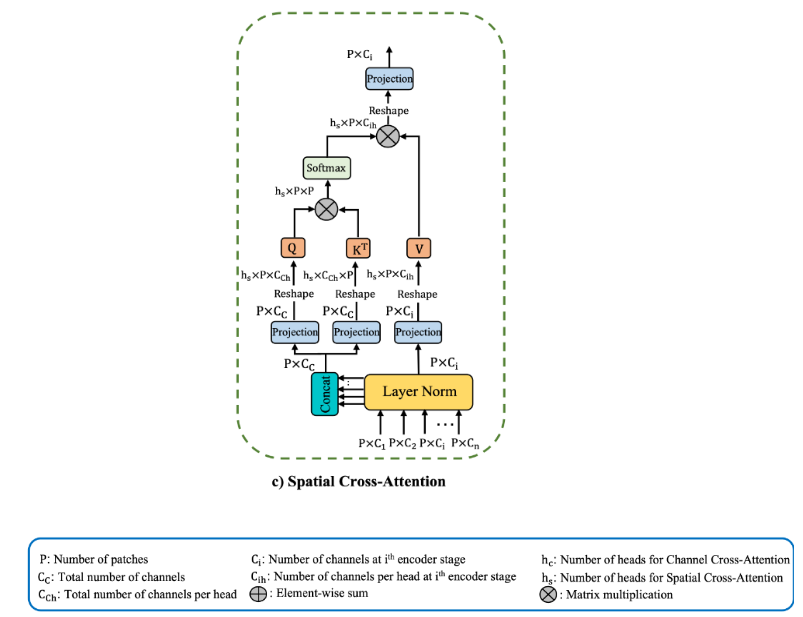
给定CCA模块处理后的输出 T i ˉ ∈ R P × C i , ( i = 1 , 2 , … , n ) \bar{T_i} \in \mathbb R^{P \times C_i},(i=1,2,\ldots,n) Tiˉ∈RP×Ci,(i=1,2,…,n),沿通道维度进行层归一化和拼接。与CCA模块不同,利用拼接后的token T c ˉ \bar{T_c} Tcˉ作为queries和key,而将每个 T i ˉ \bar{T_i} Tiˉ作为value。对queries,keys,values上使用 1 × 1 1 \times 1 1×1深度可分离卷积进行投影。
Q i = D C o n v 1 D Q ( T c ˉ ) a n d K = D C o n v 1 D K ( T c ˉ ) a n d V = D C o n v 1 D V i ( T i ˉ ) Q_i=DConv1D_{Q}(\bar{T_c}) \quad and \quad K=DConv1D_K(\bar{T_c}) \quad and \quad V=DConv1D_{V_i}(\bar{T_i}) Qi=DConv1DQ(Tcˉ)andK=DConv1DK(Tcˉ)andV=DConv1DVi(Tiˉ)
然后SCA可表示为:
S C A ( Q , K , V i ) = S o f t m a x ( Q K T d k ) V i SCA(Q,K,V_i)=Softmax(\frac{QK^T}{\sqrt{d_k}})V_i SCA(Q,K,Vi)=Softmax(dkQKT)Vi
其中, 1 d k \frac{1}{\sqrt{d_k}} dk1是比例因子。对于多头的情况, d k = C c h c d_k=\frac{C_c}{h_c} dk=hcCc,其中 h c h_c hc是head的数目。然后使用深度可分离卷积对SCA的输出进行处理得到最终DCA的输出。
然后对DCA的输出进行层归一化和GeLU处理。最后,DCA的n个输出通过上采样连接到它们对应的解码器部分。
注意交叉注意和自注意之间的主要区别在于,交叉注意通过将多尺度编码器特征融合在一起,而不是单独利用每个stage来创建注意力图,这也允许交叉注意捕获编码器不同stage之间的长距离依赖关系。

















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









