




前言
在数据驱动业务的时代,高效管理与利用结构化数据已成为企业数字化转型的核心诉求。阿里云云数据库 Clouder 认证(入门级)聚焦 “云数据库 RDS 快速入门”“SQL 基础开发与应用”“云原生数据库 PolarDB 快速入门” 三大实战场景,为技术从业者构建从数据库部署、SQL 开发到云原生数据库应用的全链路能力体系。
首个实验以云数据库 RDS 为载体,演示如何将 Excel 数据高效导入云端数据库,通过数据管理服务 DMS 完成表结构设计、数据查询及 ECS 连接操作,解锁关系型数据库的基础运维与数据处理能力。第二个实验深入 SQL 开发场景,结合 Python 环境搭建,实现数据库表创建、触发器配置、复杂查询及数据可视化分析,强化结构化数据处理的编程思维。第三个实验引入云原生数据库 PolarDB,探索其高效的数据导入、弹性扩展及云原生特性,展现新一代数据库在高并发、低延迟场景下的优势。
对于数据库新手而言,这不仅是三次认证考试,更是一次从 “数据存储” 到 “数据开发” 的系统化启蒙:从 RDS 的传统数据库部署到 PolarDB 的云原生架构实践,从手动数据导入到自动化 SQL 脚本开发,每一步均贴合企业真实数据场景,助力掌握数据库选型、性能优化及云原生技术的核心逻辑。无论你是希望夯实数据库基础,还是探索云原生数据库创新应用,这一系列实验都将为你铺设从理论到实战的进阶之路。
(1)《云数据库Clouder认证:云数据库RDS快速入门》
考试时长 120分钟
考试简介
本考试是《云数据库Clouder认证:云数据库RDS快速入门》认证考试。
注意事项
1. 考试形式为实验考试
2. 点击下方开始考试后,需要在12小时内创建资源并完成考试,否则本次考试机会作废。
3. 创建资源后,实验考试操作实验为2小时,请在实验结束前完成操作,并点击右上交的交卷按钮
1. 选择实验资源
本实验支持实验资源体验、开通免费试用两种实验资源方式。
在实验开始前,请您选择其中一种实验资源,单击确认开启实验。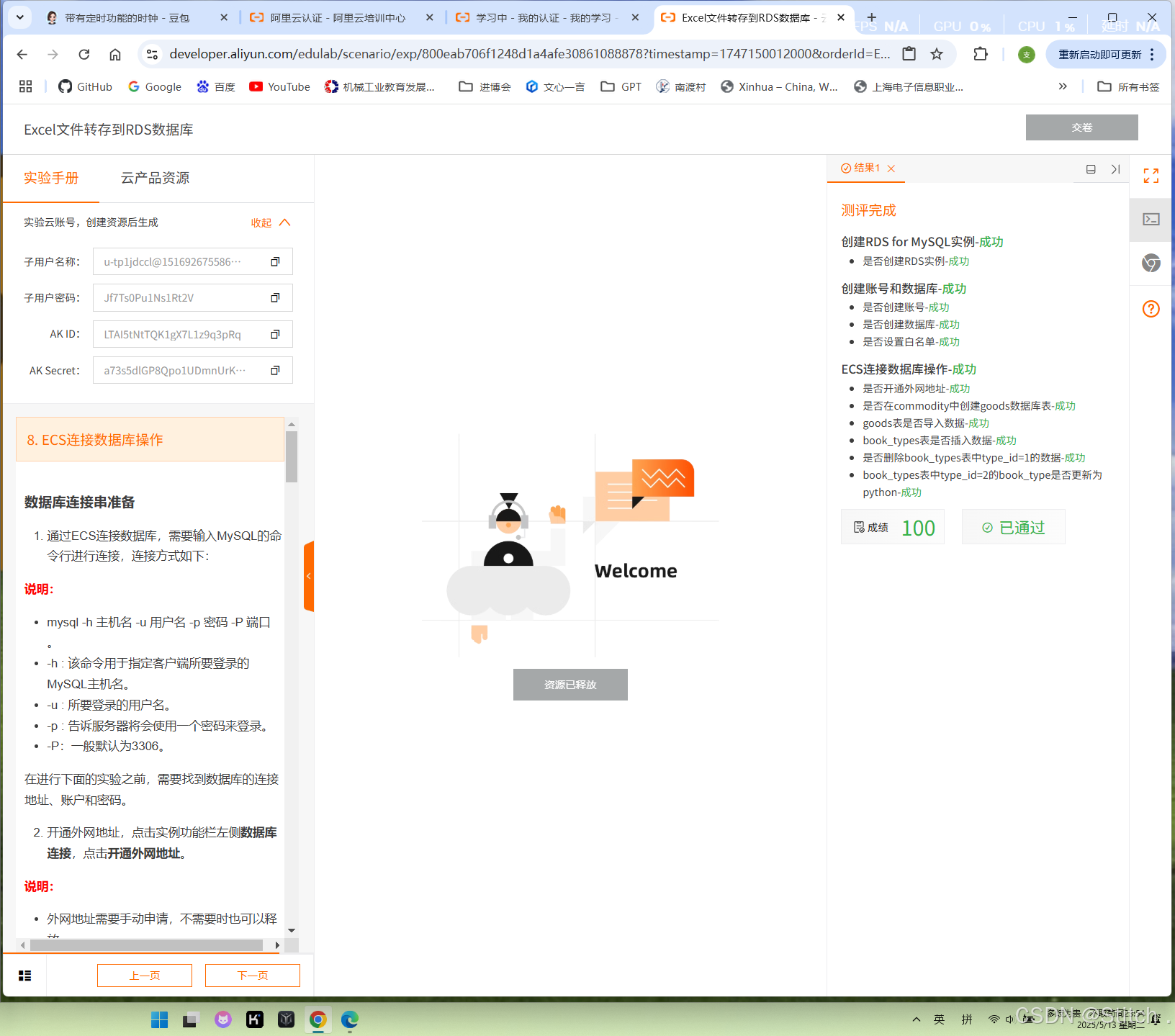

-
本实验推荐选择开通免费试用,可以免费体验云产品资源。下方卡片会展示本实验支持的试用规格,可以选择你要试用的云产品资源进行开通。您在实验过程中,可以随时用右下角icon唤起试用卡片。
说明:试用云产品开通在您的个人账号下,并占用您的试用权益。如试用超出免费试用额度,可能会产生一定费用。
阿里云支持试用的产品列表、权益及具体规则说明请参考开发者试用中心。

-
如果您已经开通过免费试用,也可以选择公共资源体验,资源创建过程需要3~5分钟(视资源不同开通时间有所差异,ACK等资源开通时间较长)。完成实验资源的创建后,在实验室页面左侧导航栏中,单击云产品资源列表,可查看本次实验资源相关信息(例如子用户名称、子用户密码、AK ID、AK Secret、资源中的项目名称等)。
说明:实验环境一旦开始创建则进入计时阶段,建议学员先基本了解实验具体的步骤、目的,真正开始做实验时再进行创建。
2. 实验场景说明
场景描述
我们平时会将一些结构化的数据放在Excel表格中进行存储,但当数据量达到一定规模,在进行复杂的关联查询时,Excel运行起来就不太友好,这时我们可以选择将Excel中的数据导入到数据库中进行处理,以提高数据存取的效率。本次实验将带领您,把Excel的数据通过数据管理服务DMS(Data Management Service)导入到RDS MySQL数据库中。

实验流程
实验开始,需要创建一个RDS for MySQL的实例,再创建数据库和账号,通过DMS对该实例进行接管,DMS拥有MySQL客户端的功能,可以在SQL窗口进行创建存储Excel数据的表,然后通过DMS的数据导入功能将Excel表格数据导入RDS数据库中。最后,会带领大家操作ECS连接RDS实例,并通过命令行,做一些简单的增删改查的操作。
3. 创建RDS for MySQL实例
登录RDS控制台
本步骤将指导您如何使用实验室页面远程桌面功能,登陆阿里云数据库RDS控制台。
在实验室页面右侧,单击
![]()
图标,切换至无影浏览器。
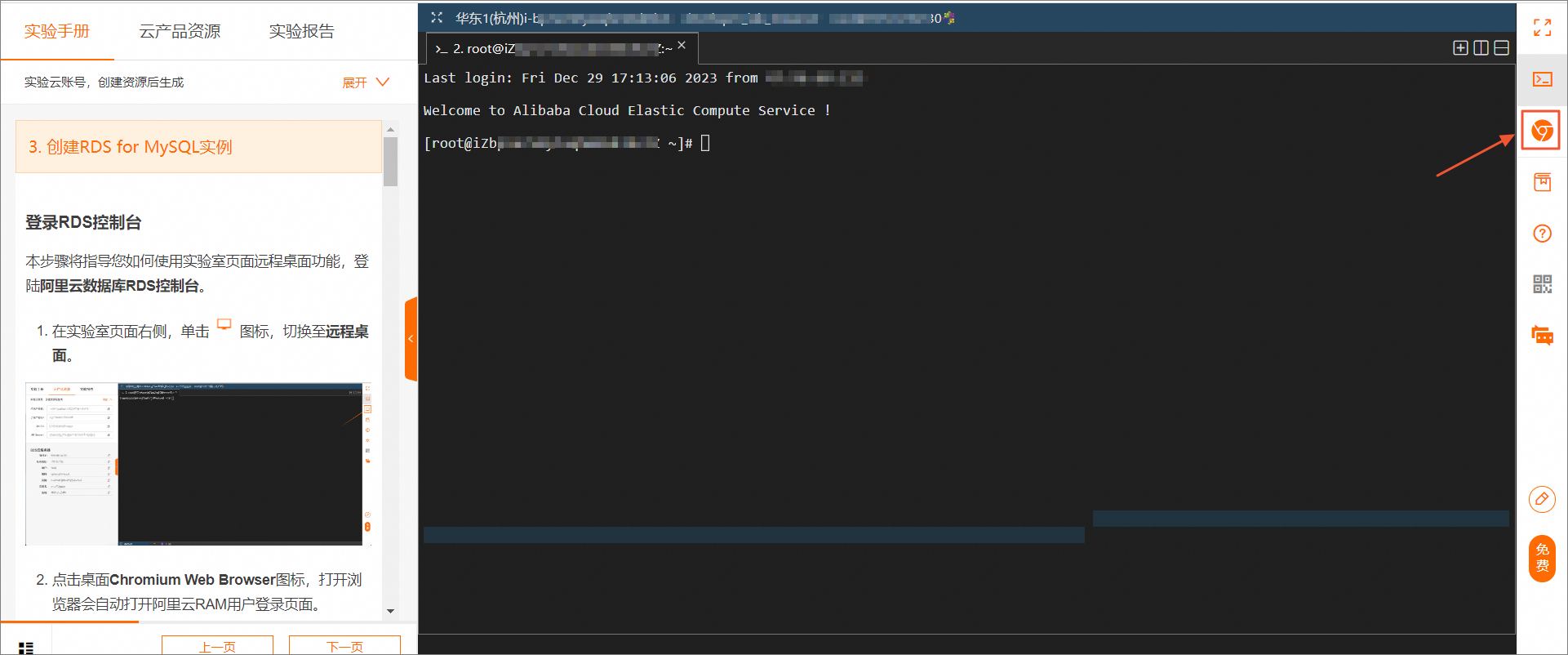
打开浏览器会自动打开阿里云RAM用户登录页面。
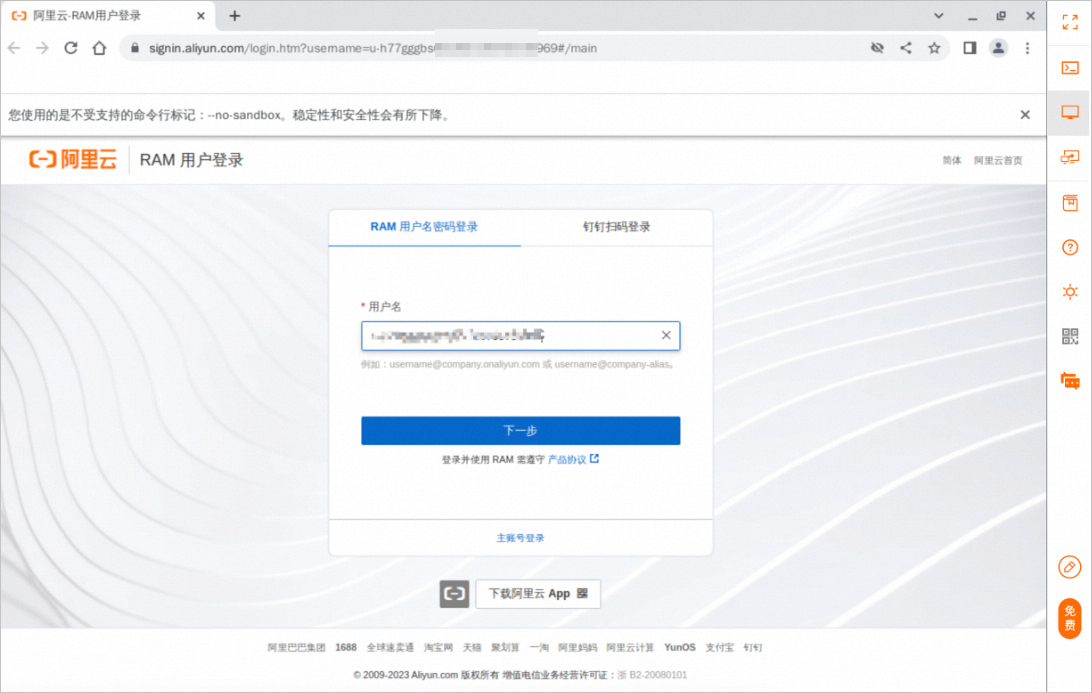
说明:浏览器如果未自动打开阿里云RAM用户登录页面,可通过浏览器手动输入RAM用户登录URL: Alibaba Cloud - RAM User Logon
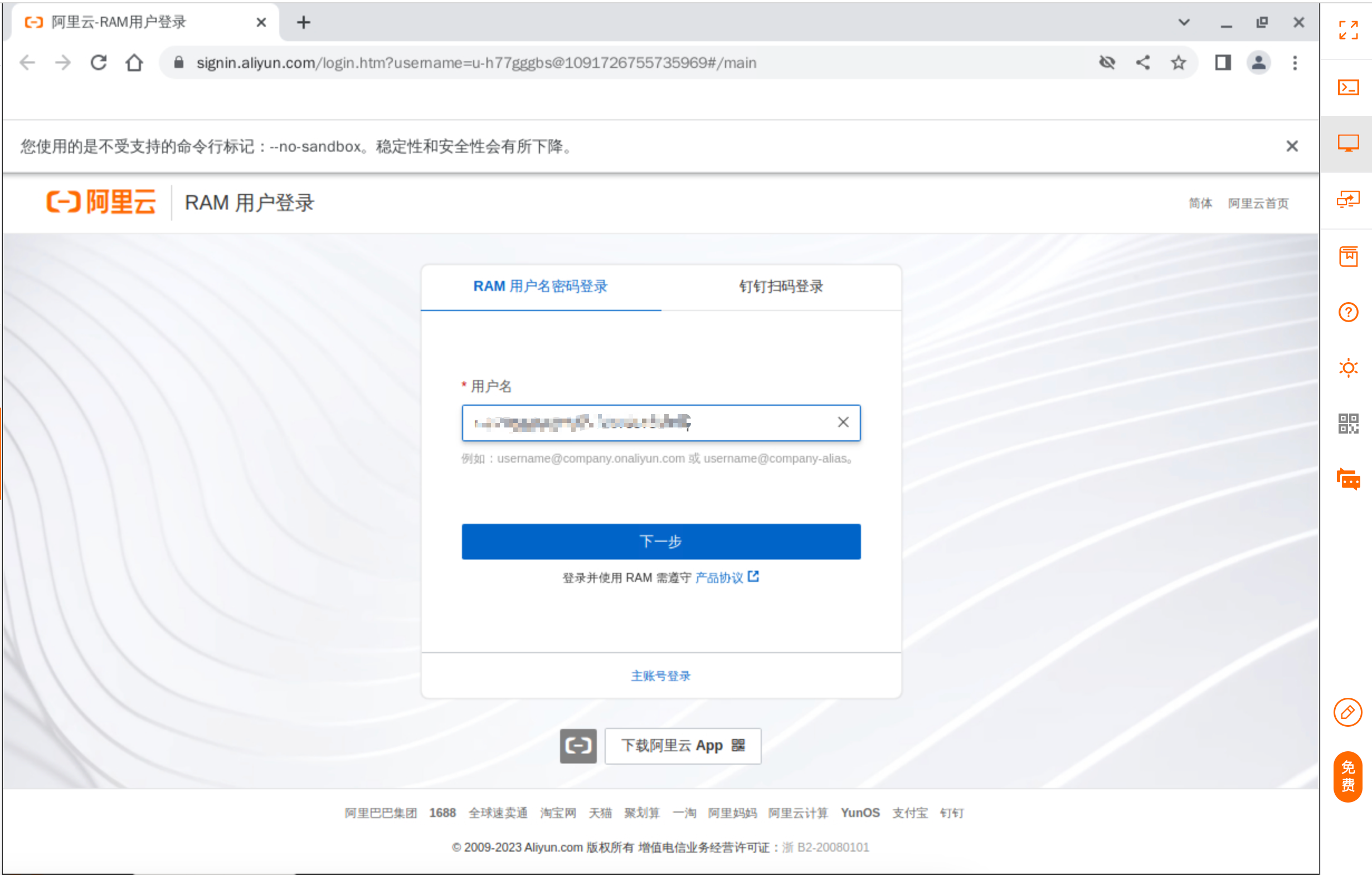
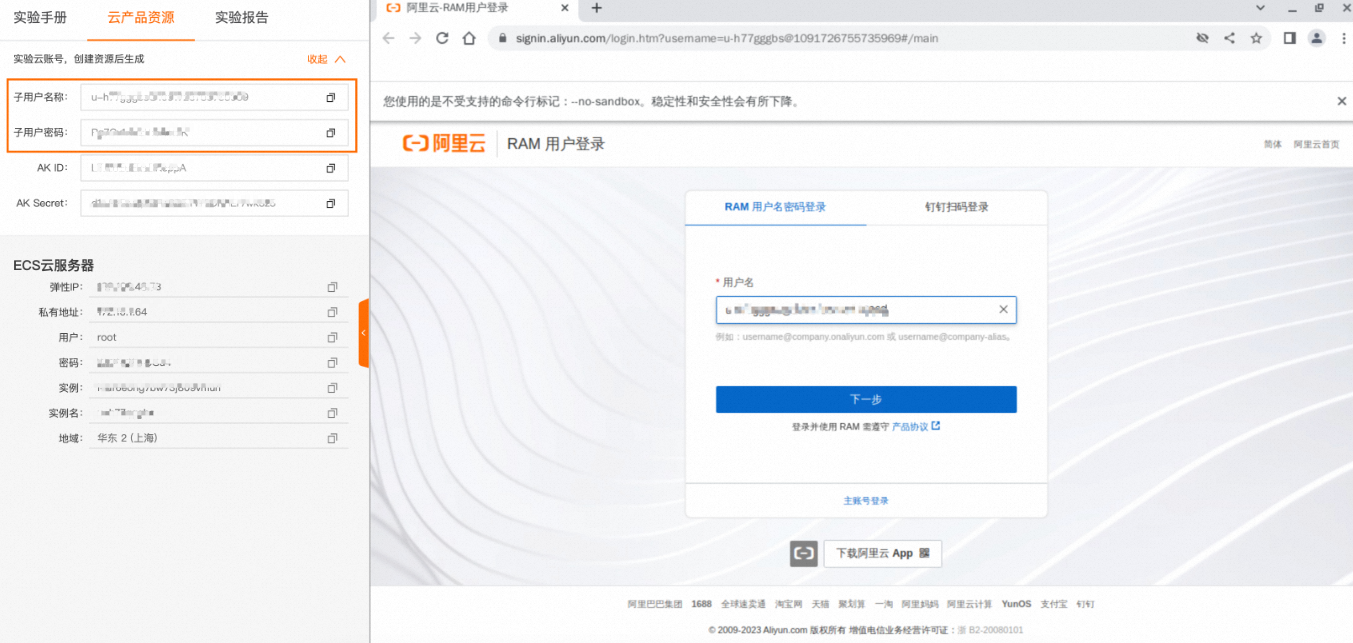
通过子用户名称和子用户密码完成RAM用户登录。
说明:您可以通过实验室左侧导航栏,点击云产品资源,即可获取子用户名称和子用户密码。
说明:控制台会提示相关教程,可点击跳过教程,继续执行下一步
点击浏览器阿里云控制台首页页面左上角

图标,搜索框输入"RDS",点击搜索结果中的云数据库RDS,进入RDS管理控制台。
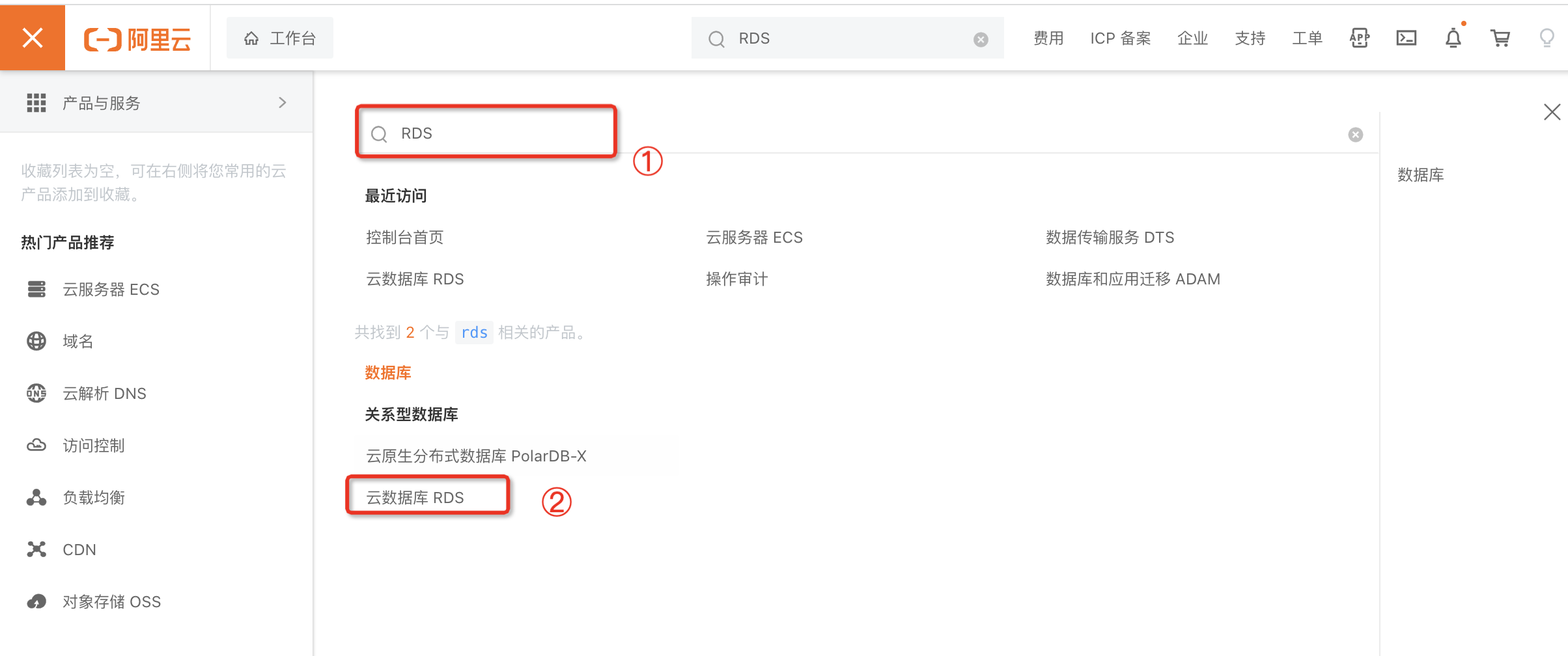
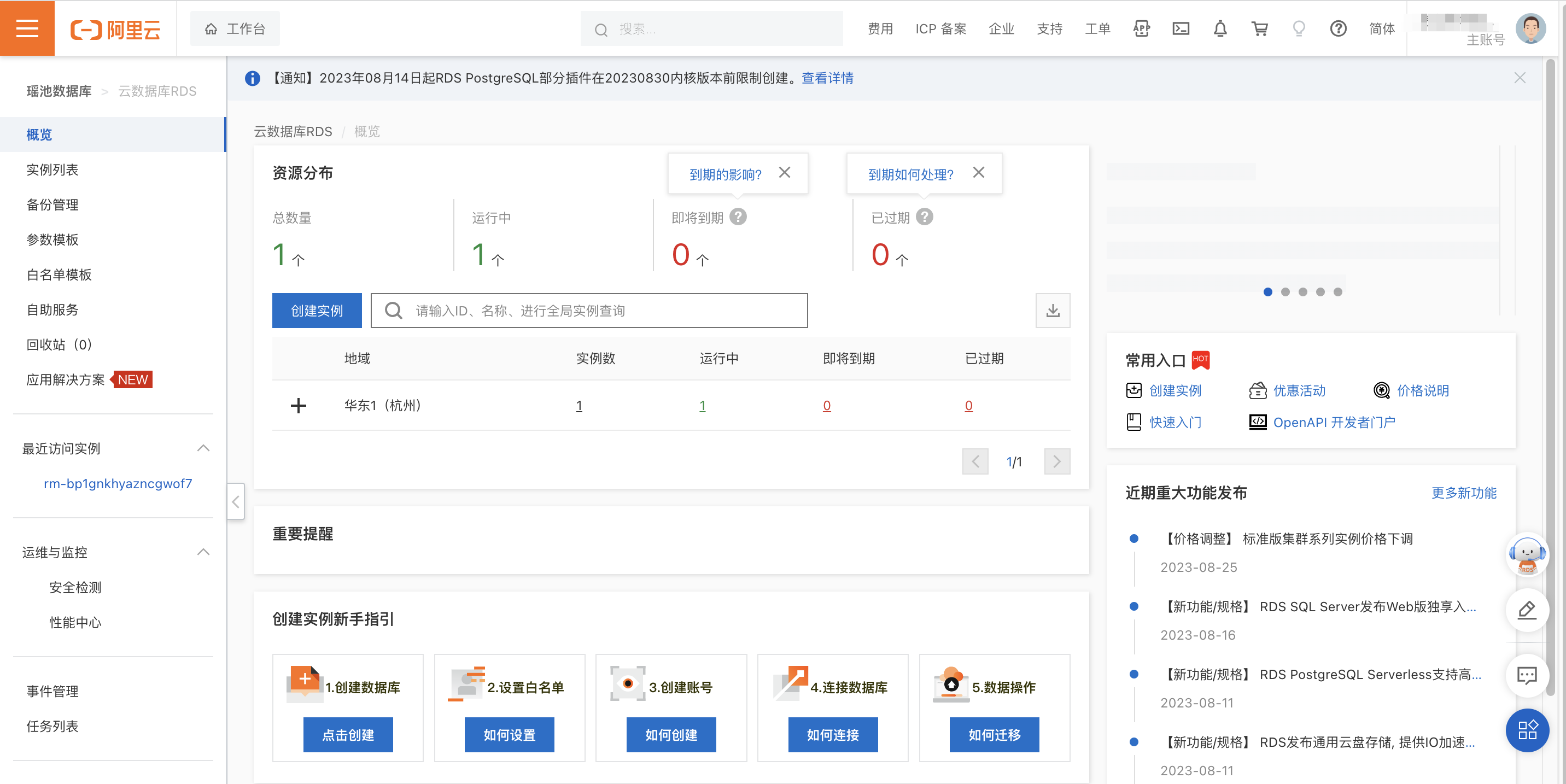
说明:如下图所示,代表您已经进入RDS管理控制台。
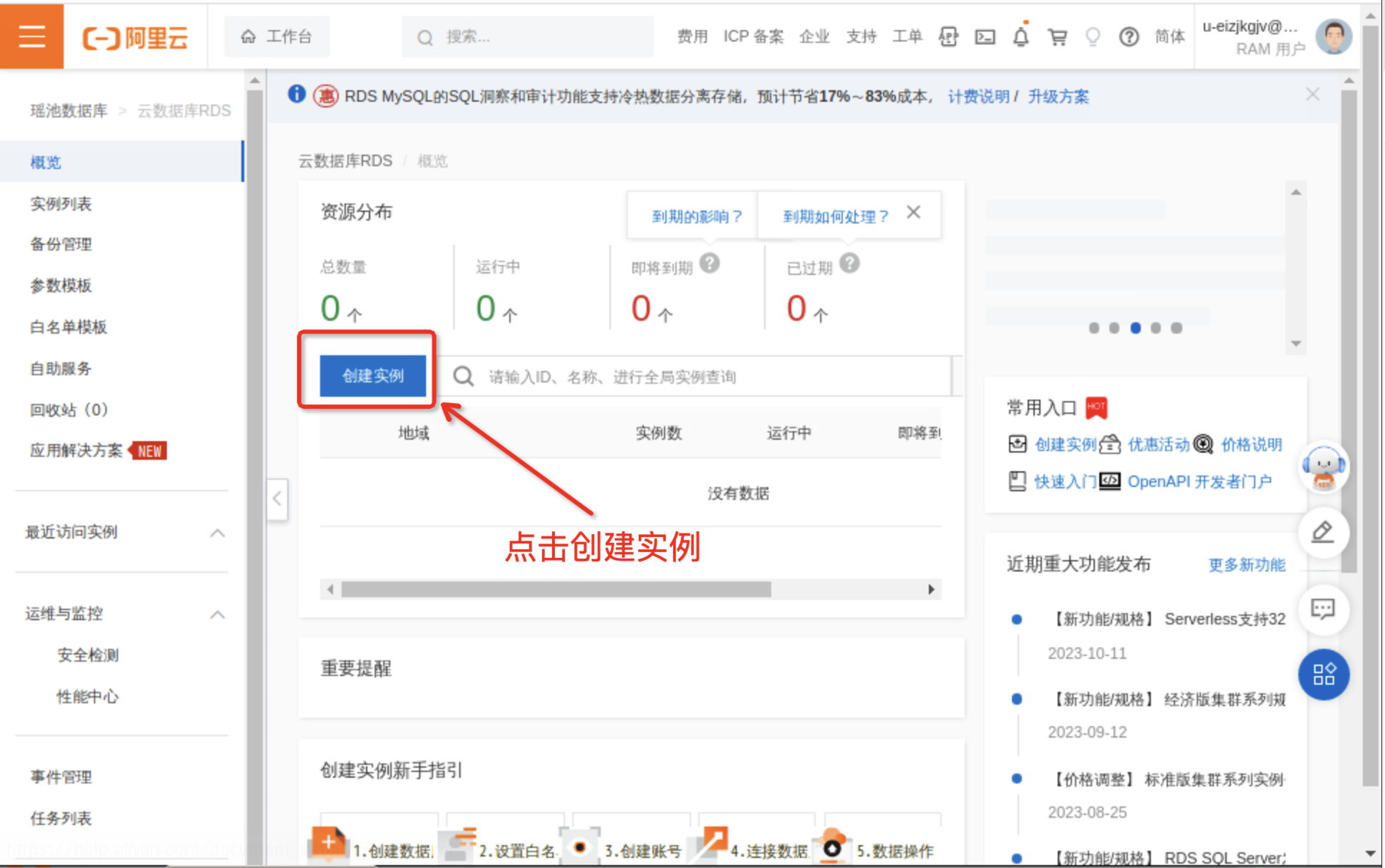
创建RDS for MySQL实例
点击创建实例的按钮,进入实例创建页面。
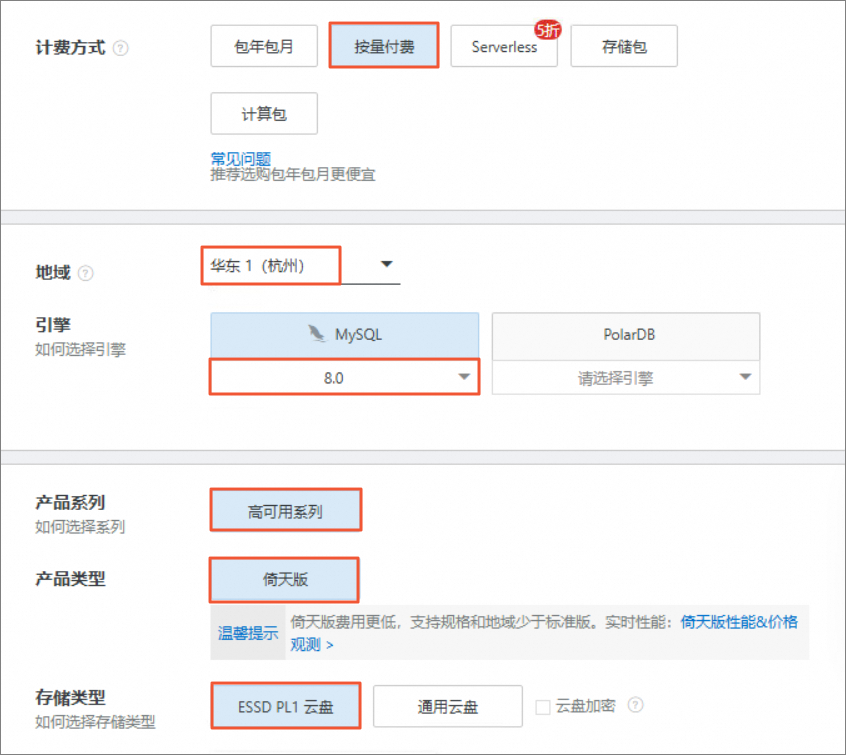
进入实例创建页面后,进行创建实例。
选择对应的参数进行配置实例,参数选择如下所示:
说明:详细参数说明,请参考官方文档:快速创建RDS MySQL实例。
-
计费方式:计费方式选择 按量计费,按量计费可随时释放实例,停止计费;
-
地域:选择 华东1(杭州);
-
引擎:选择 MySQL8.0 版本;
-
产品系列:选择 高可用版 ,高可用版本实例为一主一备架构,最高99.99%可用性;
-
产品类型:选择倚天版。
-
存储类型:选择 ESSD云盘PL1 ,ESSD云盘基于新一代分布式块存储架构,结合25GE网络和RDMA技术,为您提供单盘高达100万的随机读写能力和更低的单路时延能力;
-
主节点可用区:选择 杭州可用区J ,如果界面上无该可用区,也可选择其他可用区;
-
部署方案:选择 单可用区部署 ;

-
规格:规格分类选择通用规格,实例的规格推荐选择mysql.n2m.medium.2c,该规格为2C的CPU,4G内存;
存储空间:选择20G 。
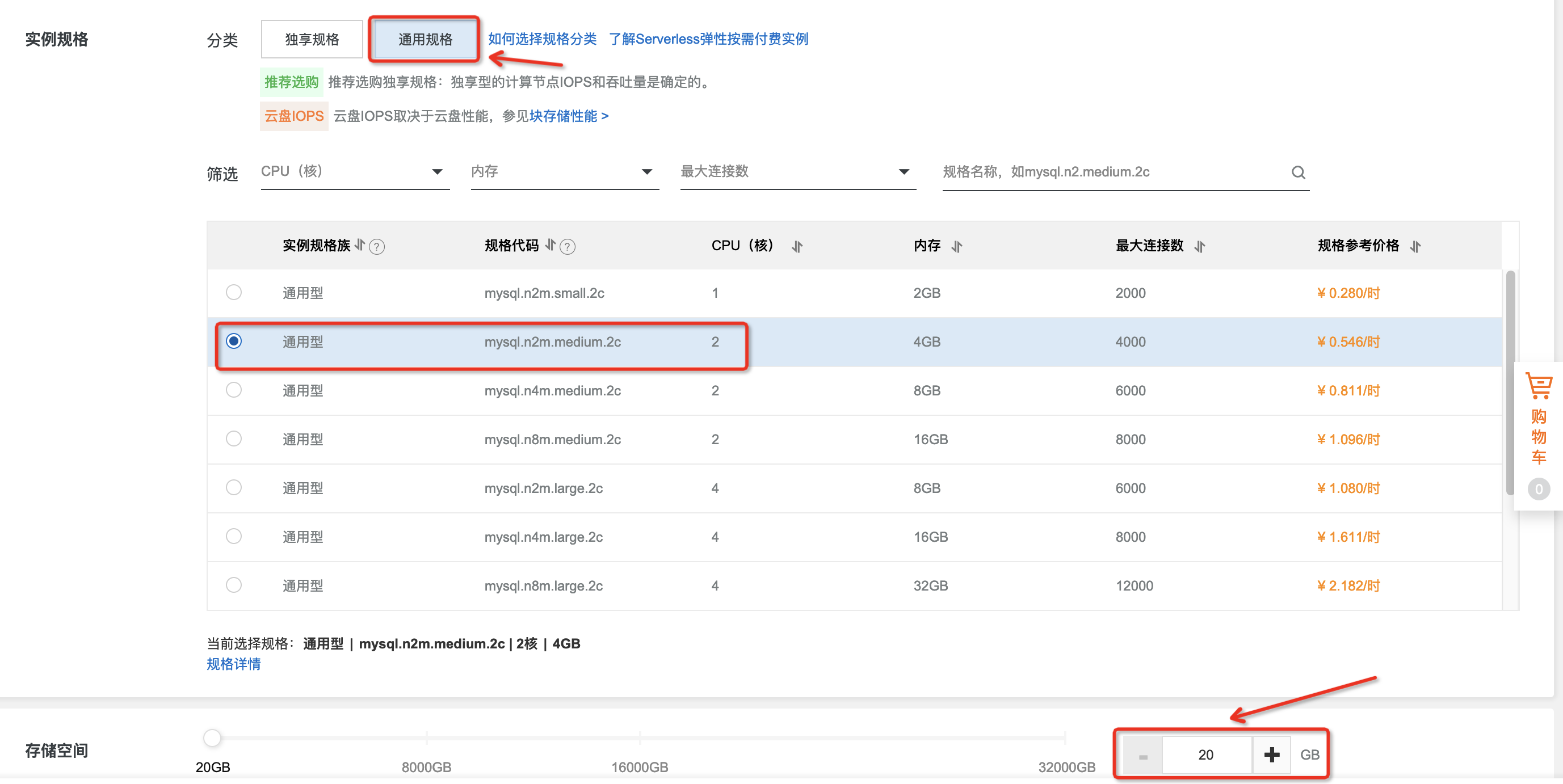
点击下一步:实例配置 。

实例配置页面,在实例描述框中填写rdstest ,其他配置按照默认即可。

直接点击下一步:确认订单进入下一步操作。
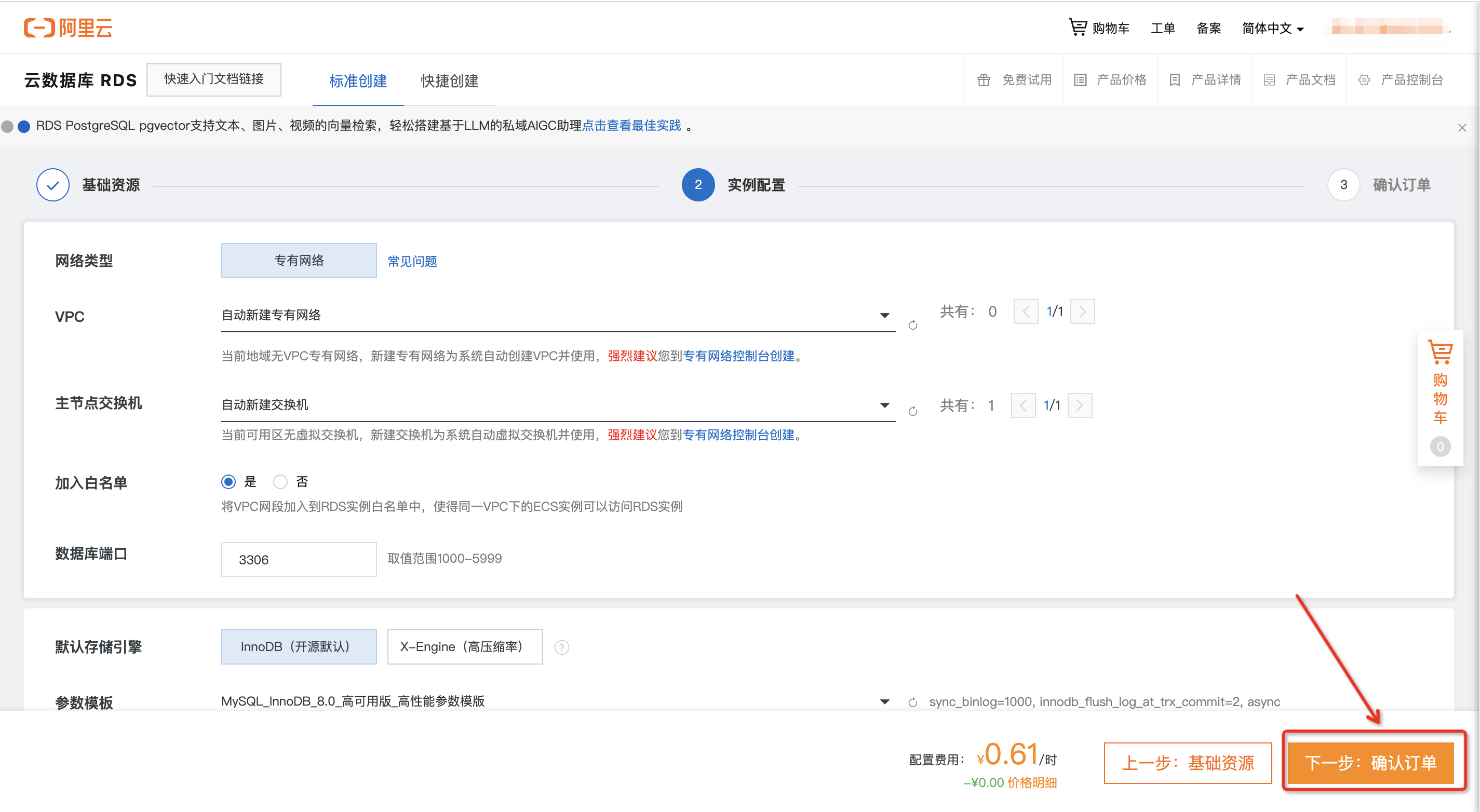
确认订单页面,选择去支付。
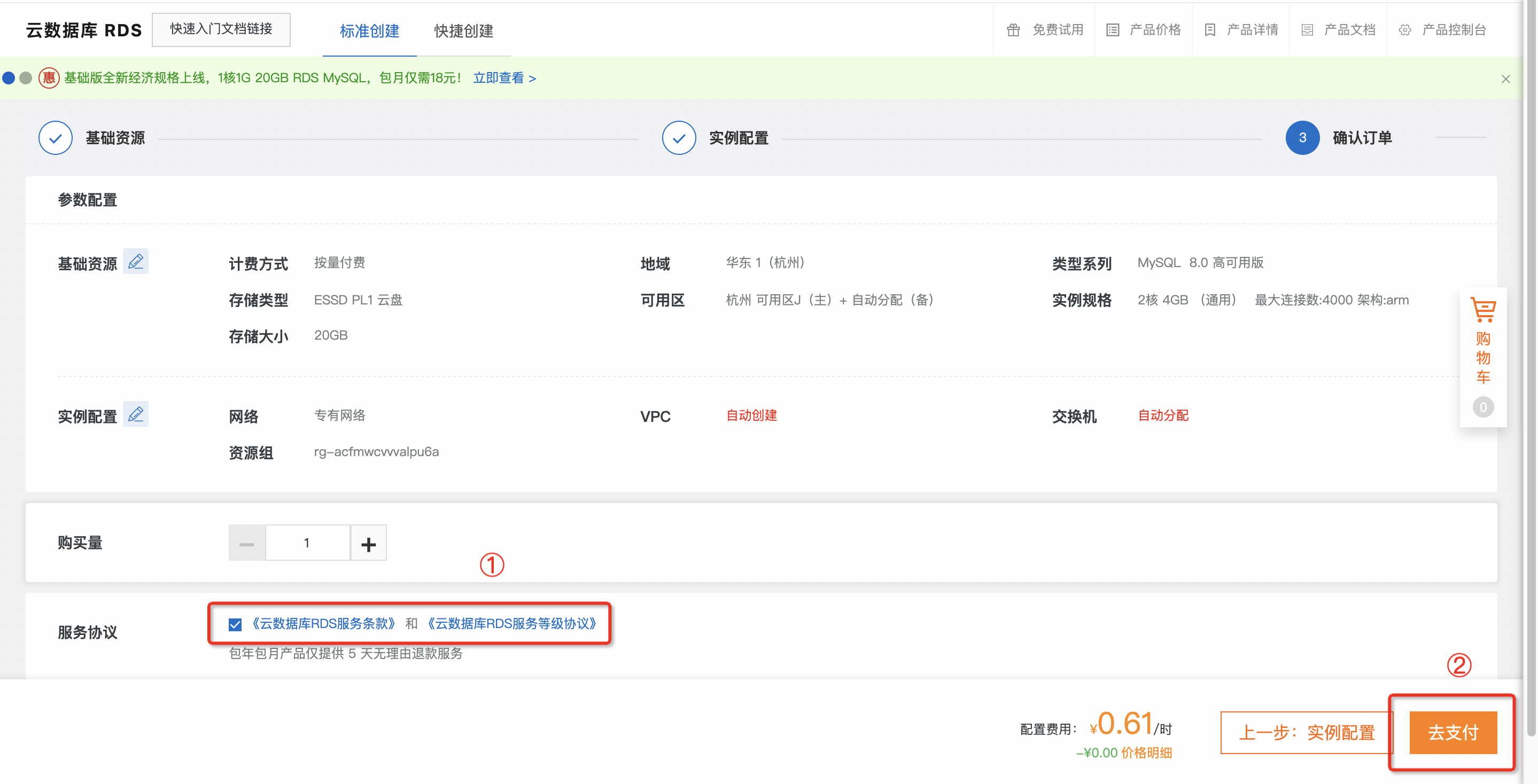
出现该界面,表示已创建完成,可继续其他步骤。

4. 创建账号和数据库
进入RDS实例详情页。
登录RDS实例管理界面。
https://rdsnext.console.aliyun.com/rdsList/cn-hangzhou/basic在RDS控制台界面选择上述步骤已创建好的实例。实例创建过程耗时3分钟左右,若实例ID暂不可跳转,请耐心等待,过程中可以刷新页面,等待实例状态变为运行中,单击实例ID 。
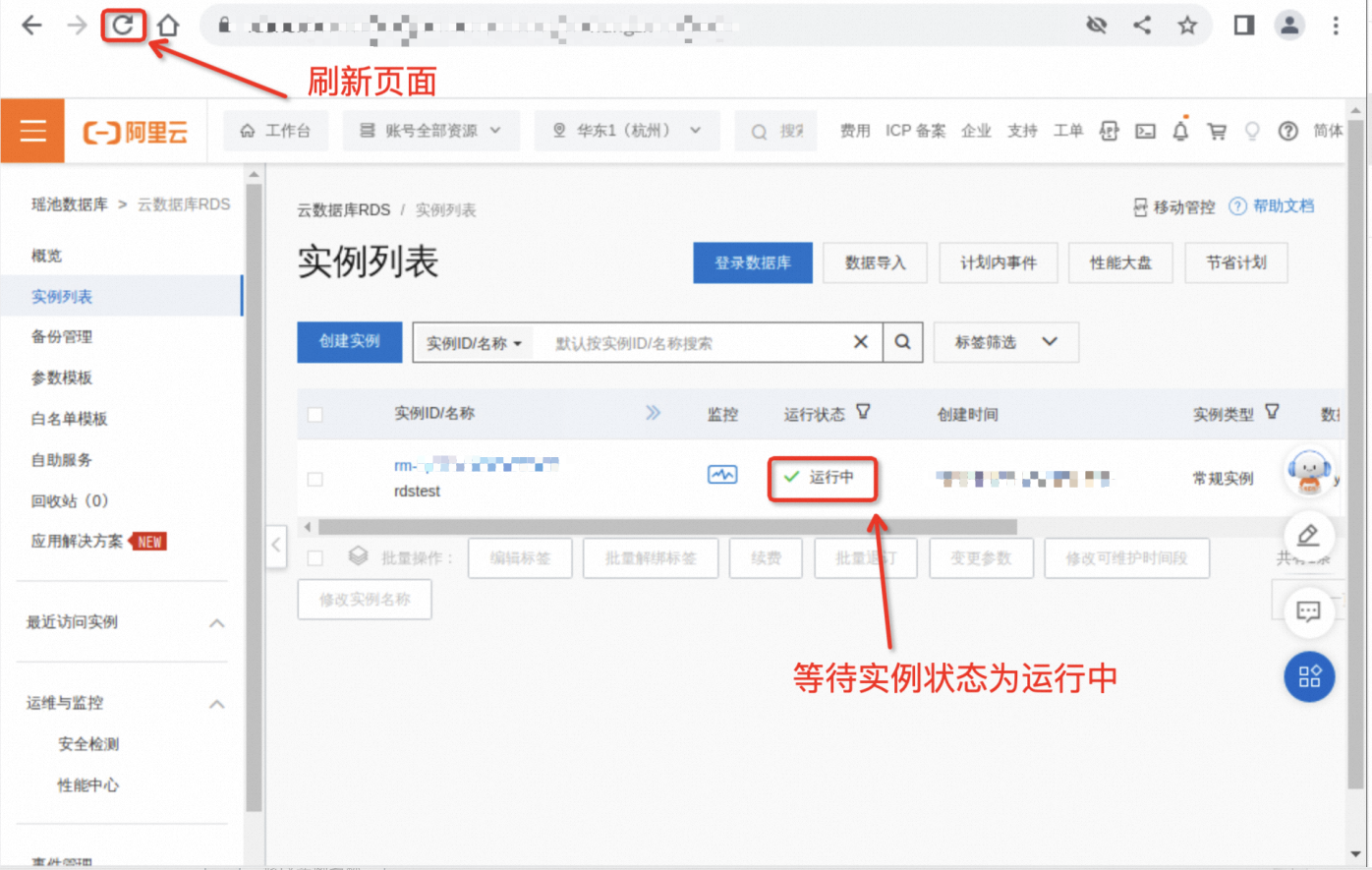
下图即为实例的管理界面。
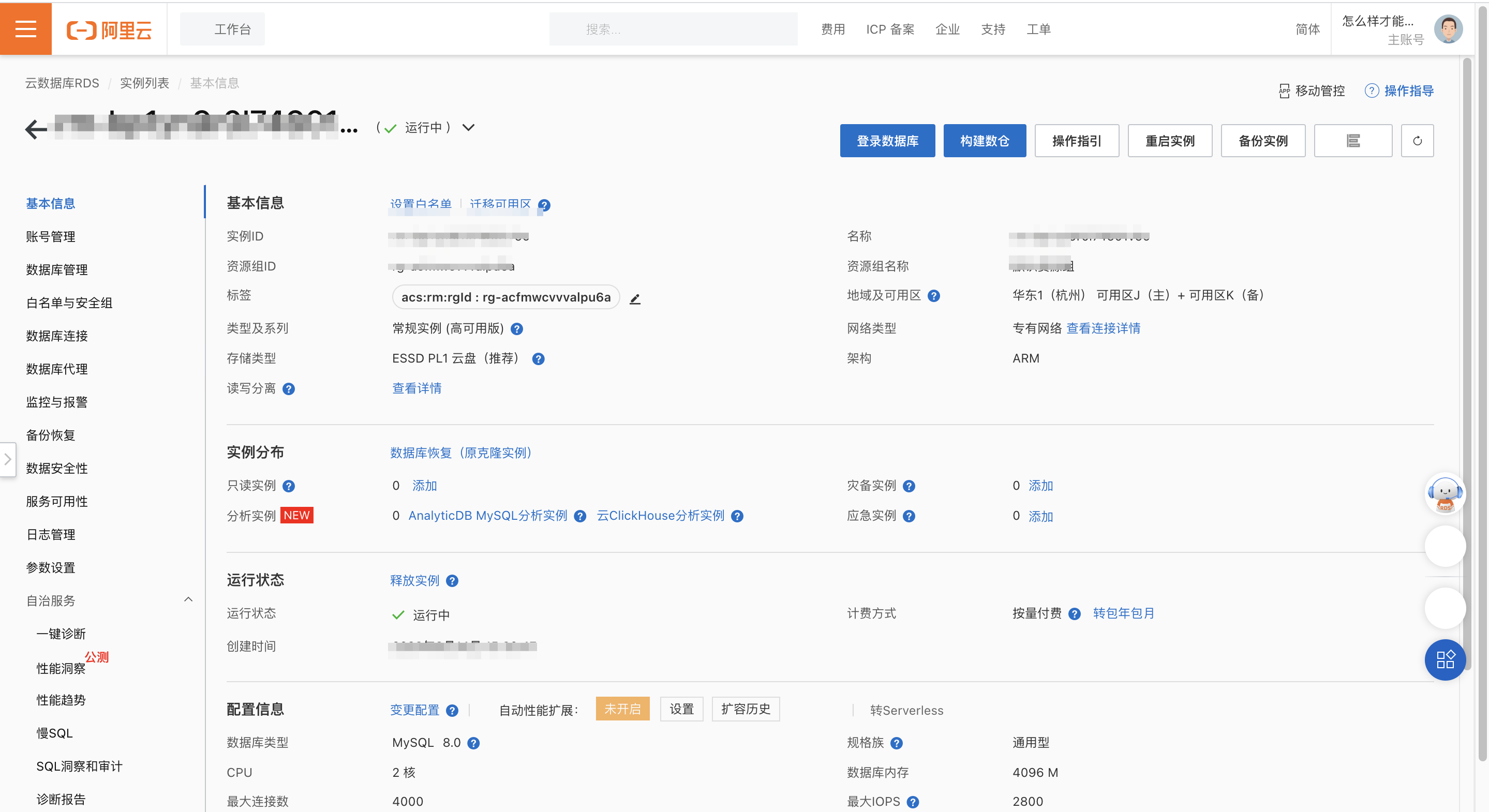
创建账号
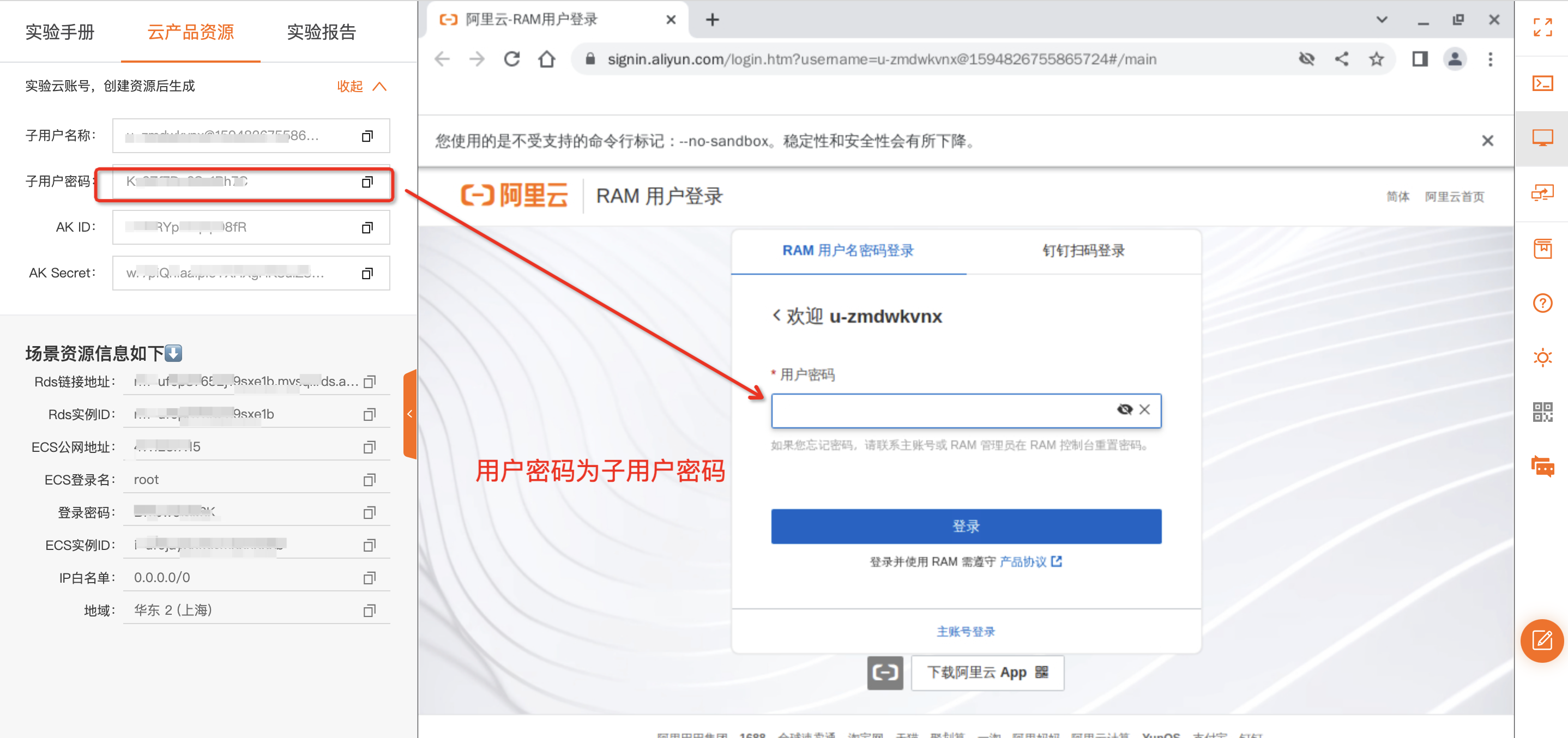
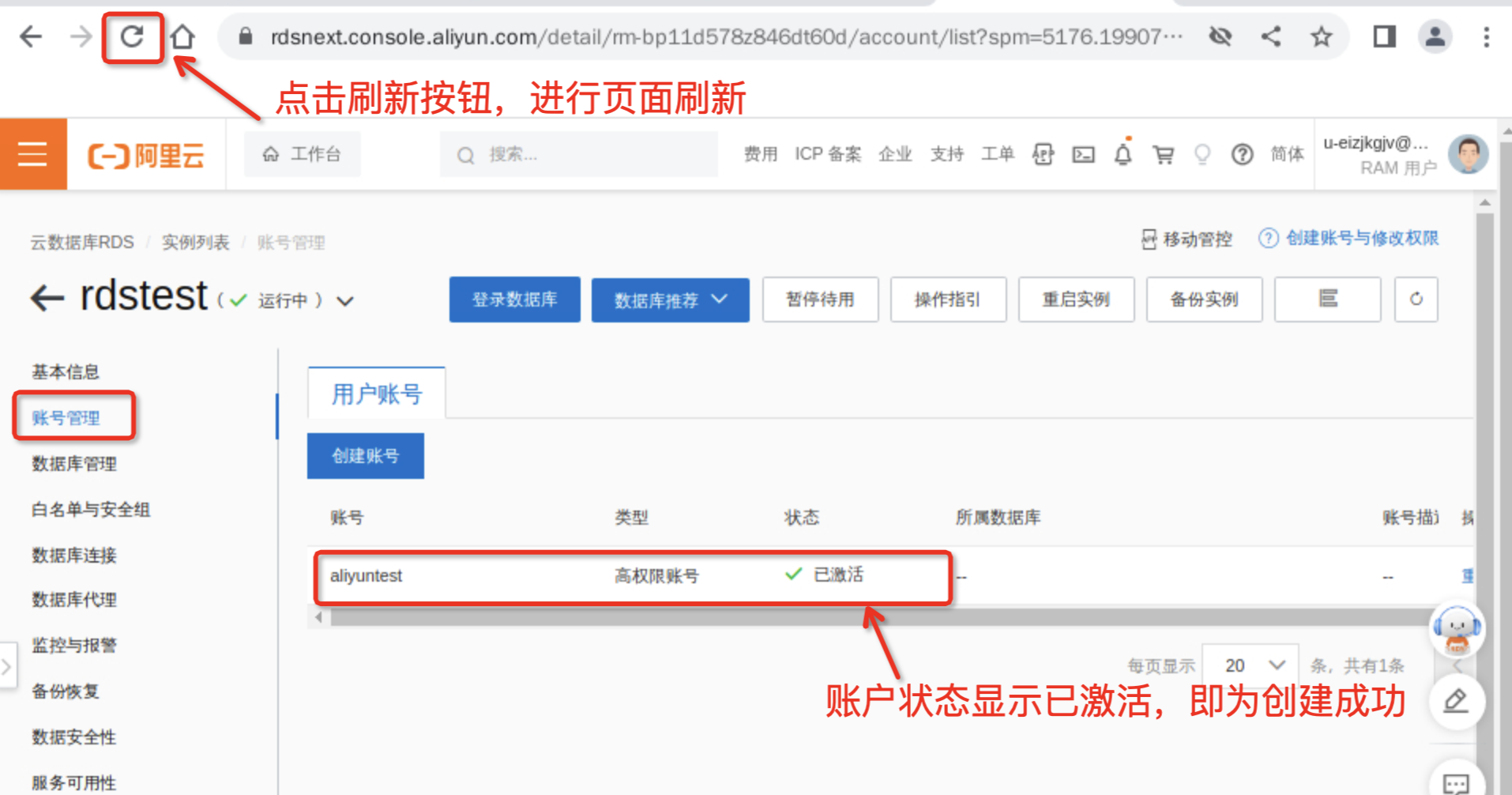
在账号管理界面,单击创建账号,创建 高权限账号,账号为aliyuntest,密码为实验提供的子账户密码。
子账户密码如下显示:
参数说明。
数据库账号:输入数据库账号名称aliyuntest。切记一定要设置账户名为aliyuntest,为了后续实验进行评分。
账号类型:选择高权限账号。
密码:设置账号密码。切记一定要设置为子用户密码,为了后续实验进行评分。
确认密码:再次输入密码。
备注:商品管理账户。
| 账号类型 |
说明 |
| 高权限账号 |
只能通过控制台或API创建和管理。 一个实例中只能创建一个高权限账号,可以管理所有普通账号和数据库。 开放了更多权限,可满足个性化和精细化的权限管理需求,例如可按用户分配不同表的查询权限。 拥有实例下所有数据库的权限。 可以断开任意账号的连接。 |
| 普通账号 |
可以通过控制台、API或者SQL语句创建和管理。 一个实例可以创建多个普通账号,具体的数量与实例内核有关。 普通账号默认仅拥有登录数据库的权限,您需要手动给普通账号授予其他特定的权限。更多信息,请参见修改账号权限。 普通账号不能创建和管理其他账号,也不能断开其他账号的连接。 |
显示账号已激活 ,账号已创建完成。若一直处于创建中,请手动刷新页面。
创建数据库
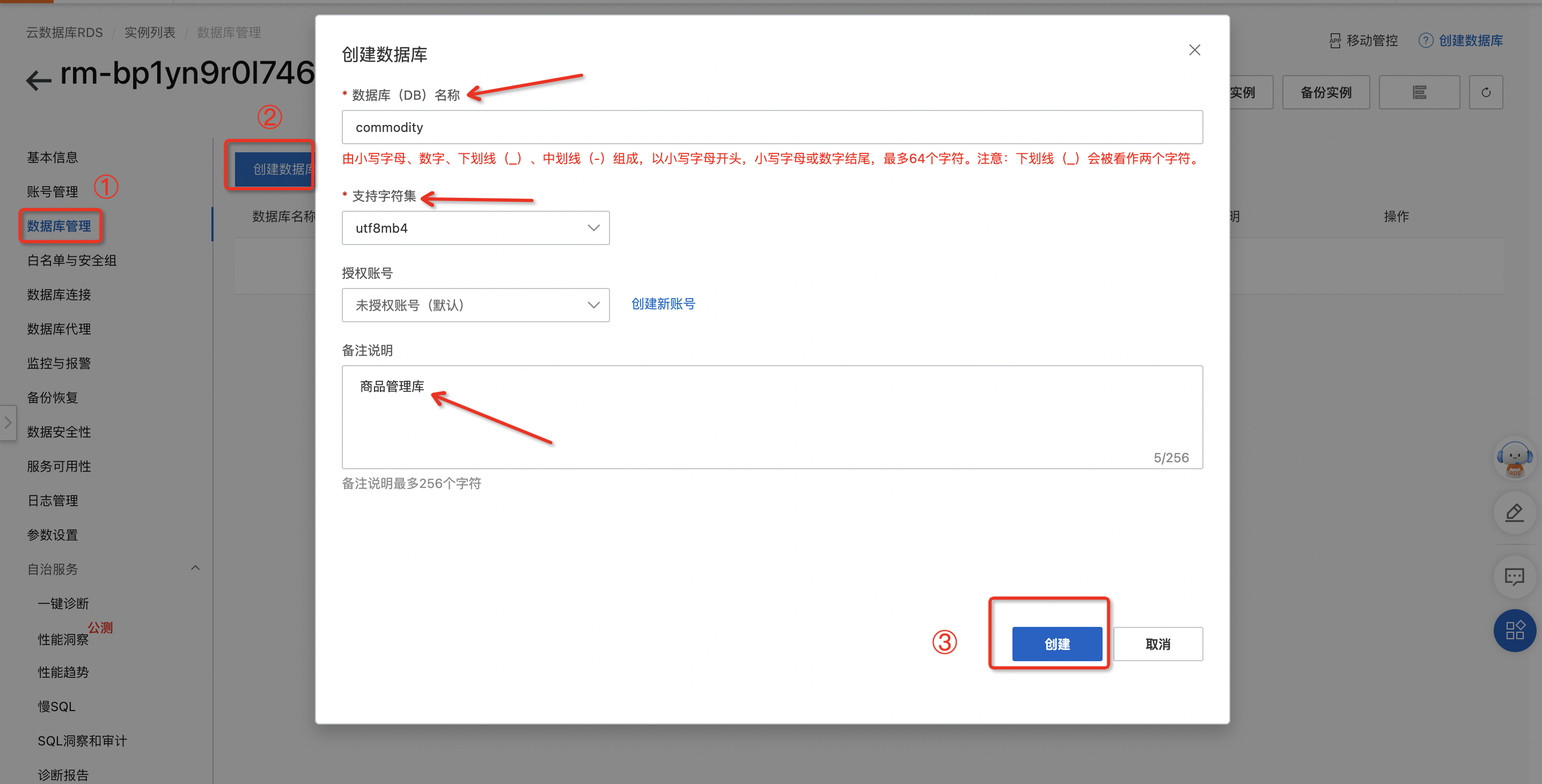
点击数据库管理,在点击创建数据库,在页面中输入数据库(DB)名称,选择支持字符集 ,并书写对应的备注说明,点击创建按钮,进行提交。
该示例创建数据库名称为:commodity
支持的字符集为:utf8mb4
备注说明:商品管理库
MySQL8.0支持多种字符集,字符集的特点如下:
utf8mb4:支持4字节Unicode字符,可以表示大部分国家的字符,是现代web应用中广泛使用的字符集。
utf8:只支持3字节Unicode字符,较老的MySQL服务器和许多库如LAMP(Linux + Apache + MySQL + Python/PHP/Perl)默认采用该字符集。
latin1:最基本的字符集,其它的字符集都可以通过该字符集的不可改变子集表示。这个字符集支持大部分计算机常见的字符,包括所有西欧语言的字母、数字、标点符号以及一些特殊字符。它在日语、中文和俄语等非拉丁字母语言中不适用。
gb2312:早期中国字符集,支持除异体字之外的3500左右的中文汉字和基本的拉丁字母、数字、标点符号,以及一些特殊字符。
gbk:统一汉字编码,是中国的现代字符集,包含了中国国家标准GB 2312-1980的全部字符,支持包括繁体字、日本汉字和韩国汉字等在内的多种汉字。
utf16:Unicode字符二进制编码的16位配对码,支持几乎所有语言的字符和符号。
总之,选择什么字符集要根据自己的实际情况进行综合考虑,例如需要支持哪些语言、字符等。utf8mb4通常是最好的选择,如果面临扩展部署考虑,则可考虑 utf16的使用,中文网站中,唯一建议不使用latin字符集。
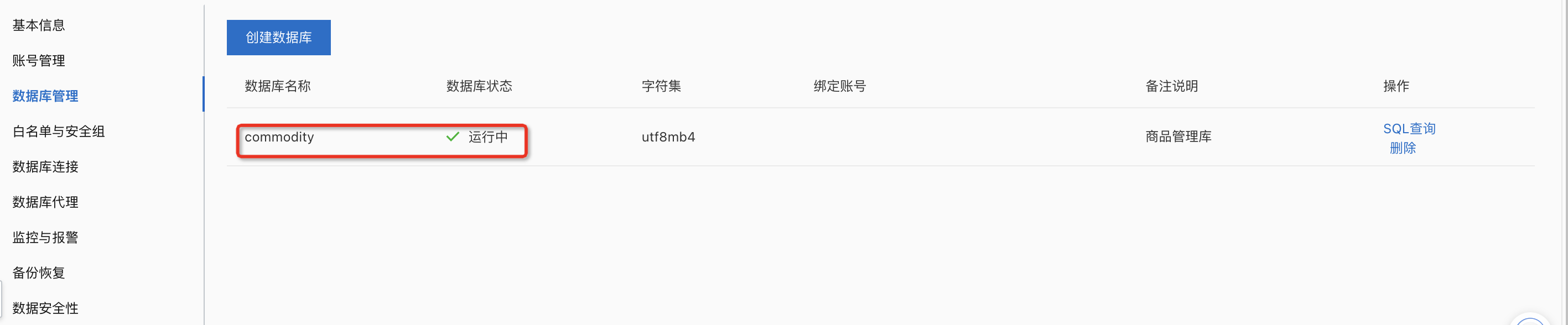
显示如下界面,表示数据库已创建完成。
设置白名单
在左侧导航栏中,单击白名单与安全组。
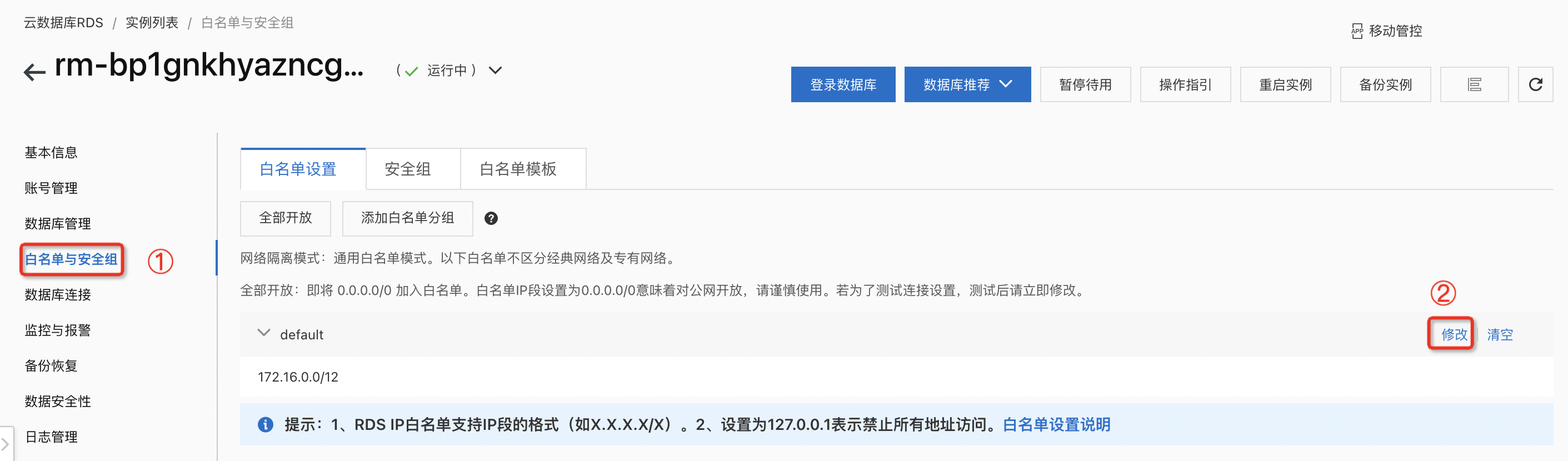
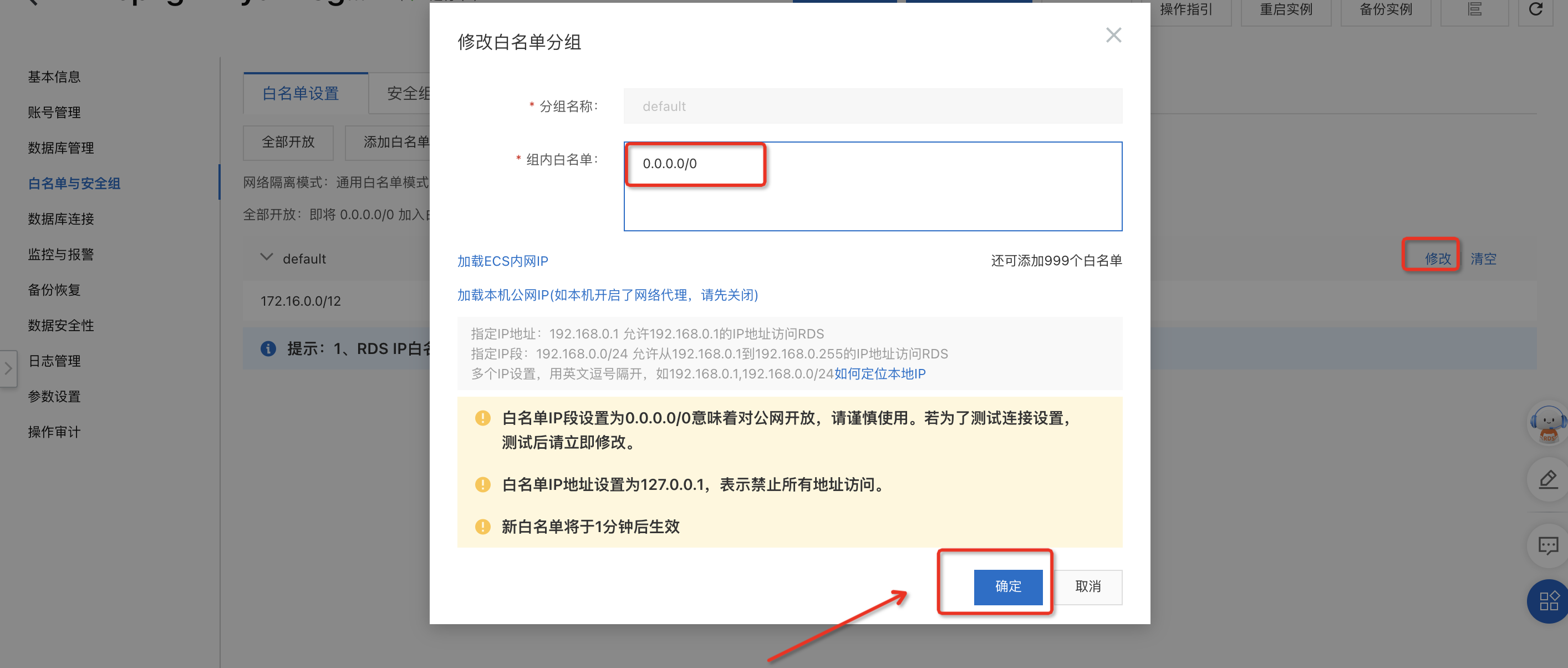
单击default分组右侧的修改。
说明:如有需要,也可以单击添加白名单分组,并自定义一个分组名称。
全部开放:将0.0.0.0/0加入白名单中,点击确定。
白名单说明:
-
多个IP地址用英文逗号隔开,且逗号前后不能有空格。
-
单个实例最多添加1000个IP地址或IP段。如果IP地址较多,建议将零散的IP合并为IP段,例如10.10.10.0/24。
-
如果第3步获取的白名单模式是通用模式,则无额外注意事项。如果是高安全模式,需注意:
-
把公网IP或经典网络ECS实例私网IP添加至经典网络分组。
-
把专有网络ECS实例私网IP添加至专有网络分组。
-
添加后,所有的应用服务器都能访问RDS实例。
5. 连接数据库
连接数据库
-
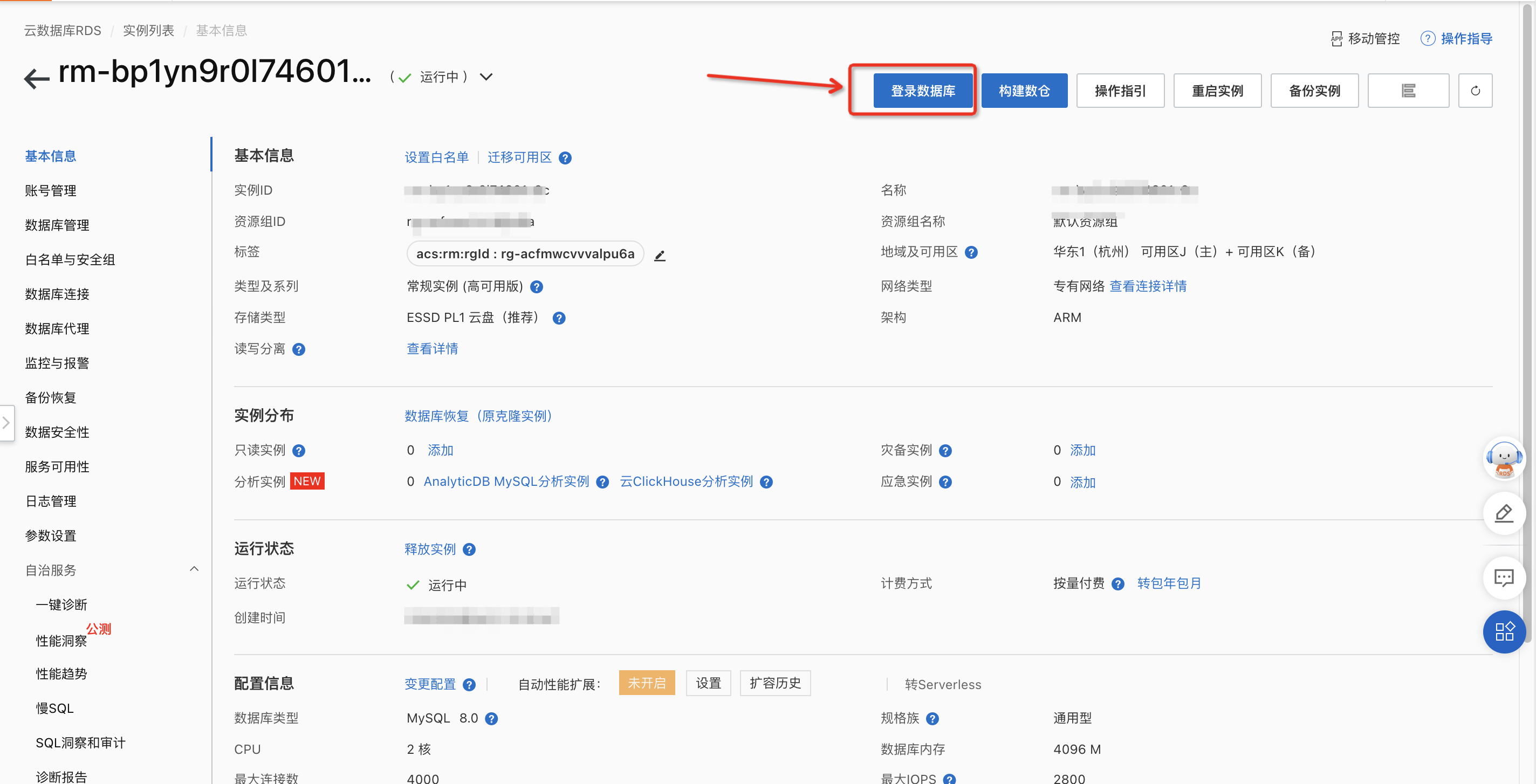
在实例基本信息页面上单击 登录数据库 ,跳转DMS界面。
-
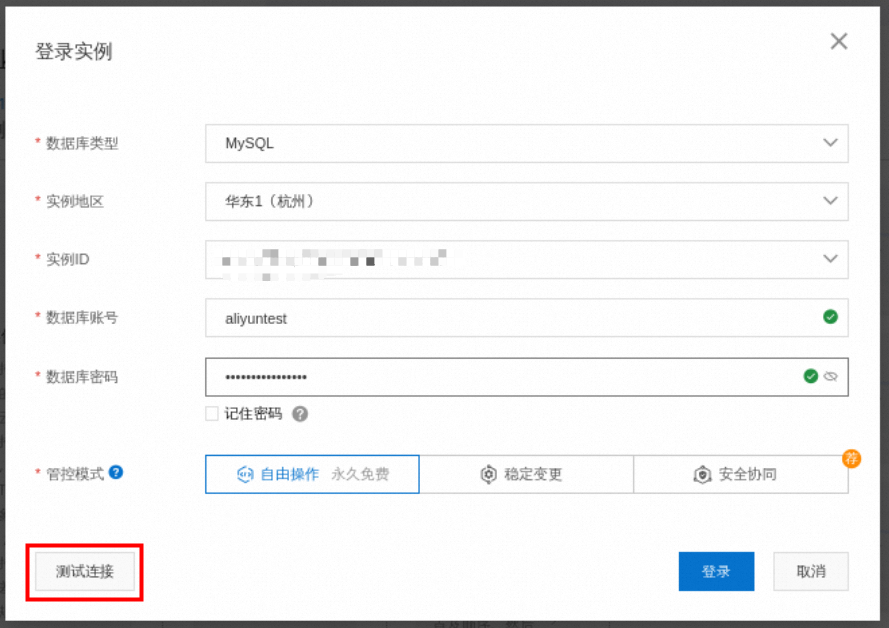
在DMS界面,输入创建的 数据库账号 、 数据库密码。
-
完成以上信息填写后,单击左下角的测试链接,测试连通性无问题后,点击 登录。
说明 如果测试连接失败,请按照报错提示检查您录入的实例信息。
-
出现连接成功提示后,单击提交。
-
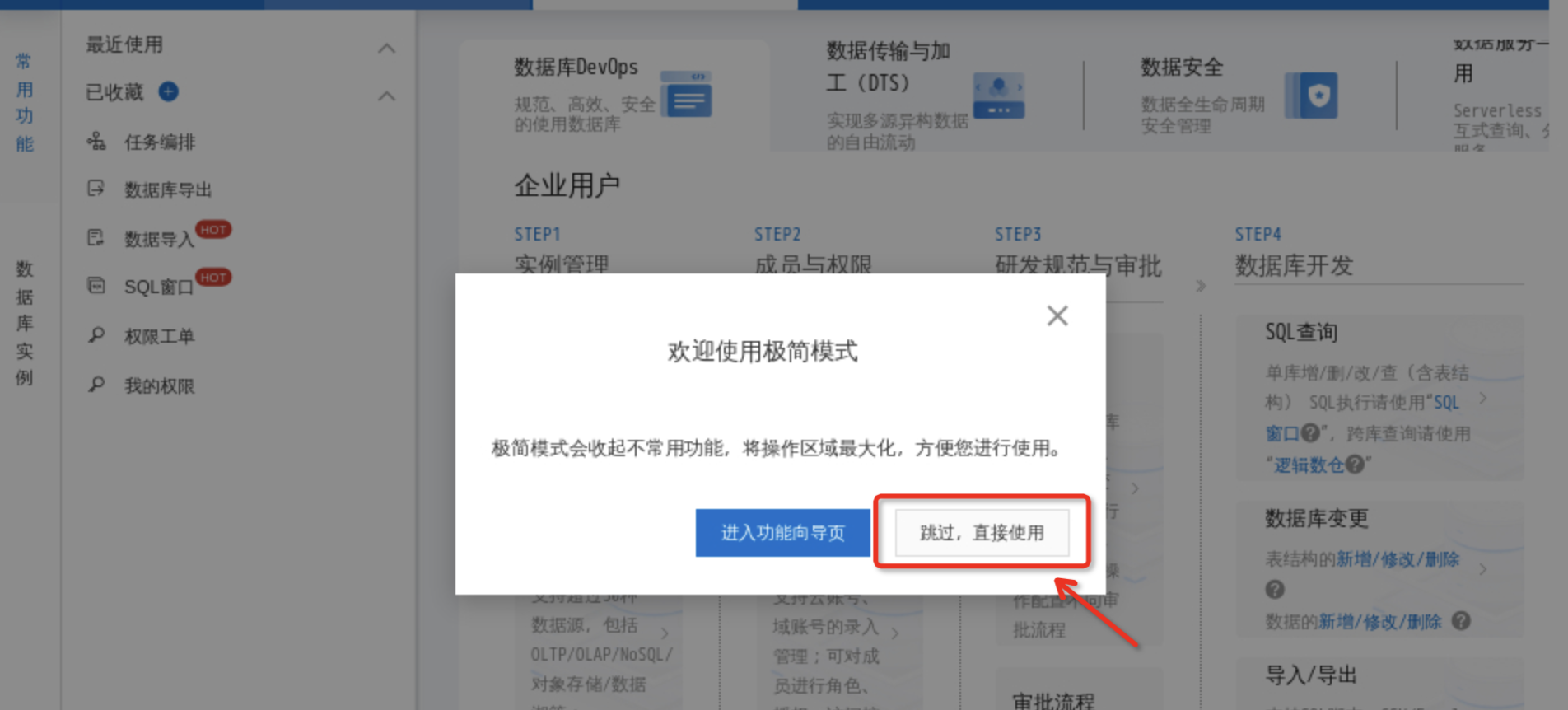
连接成功后,点击 跳过,直接使用
6. 上传Excel表格数据到RDS数据库
执行SQL窗口
在DMS控制台,单击 首页,点击常用功能,选择SQL窗口,进入SQL执行窗口。
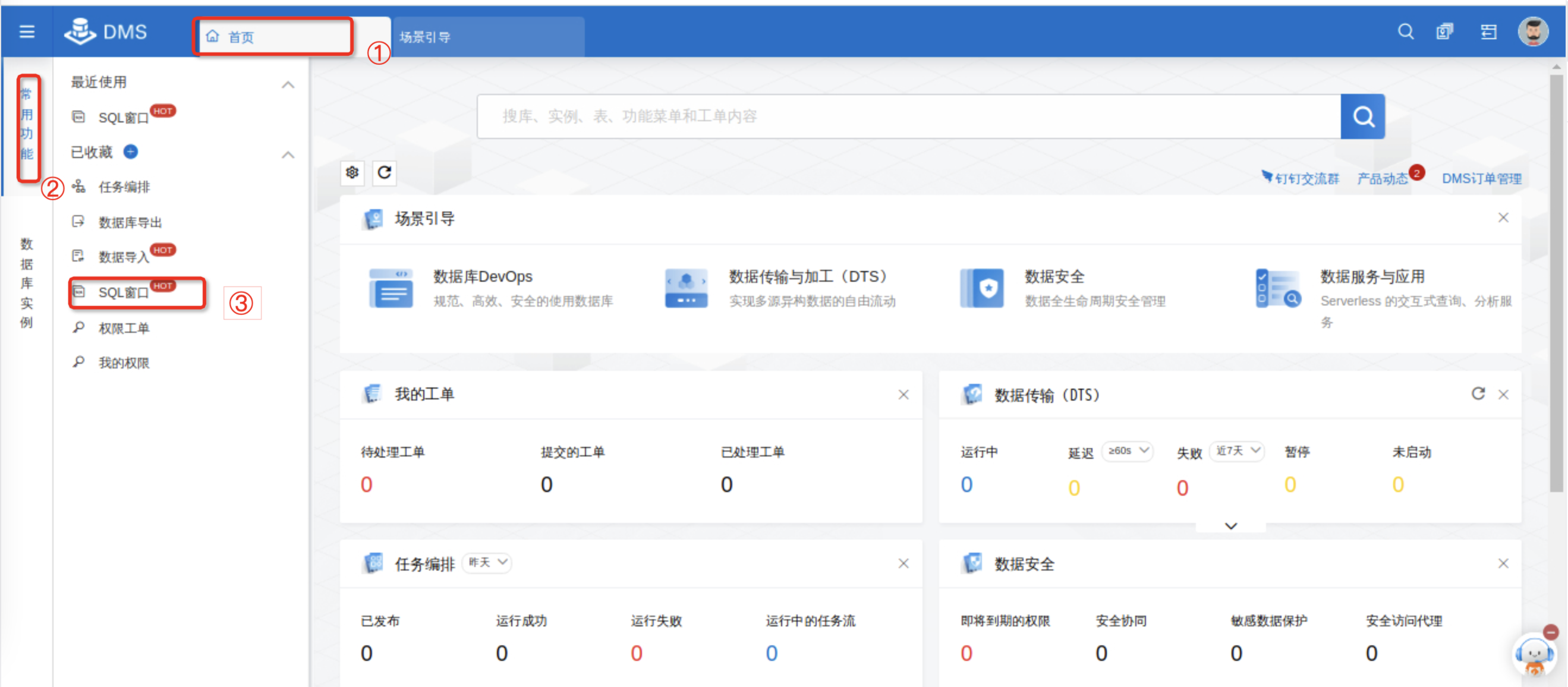
若出现以下界面,请缩小界面,点击 右上角 关掉广告页面,关掉操作指引。

进入SQL窗口后,选择commodity数据库进行连接,点击确认
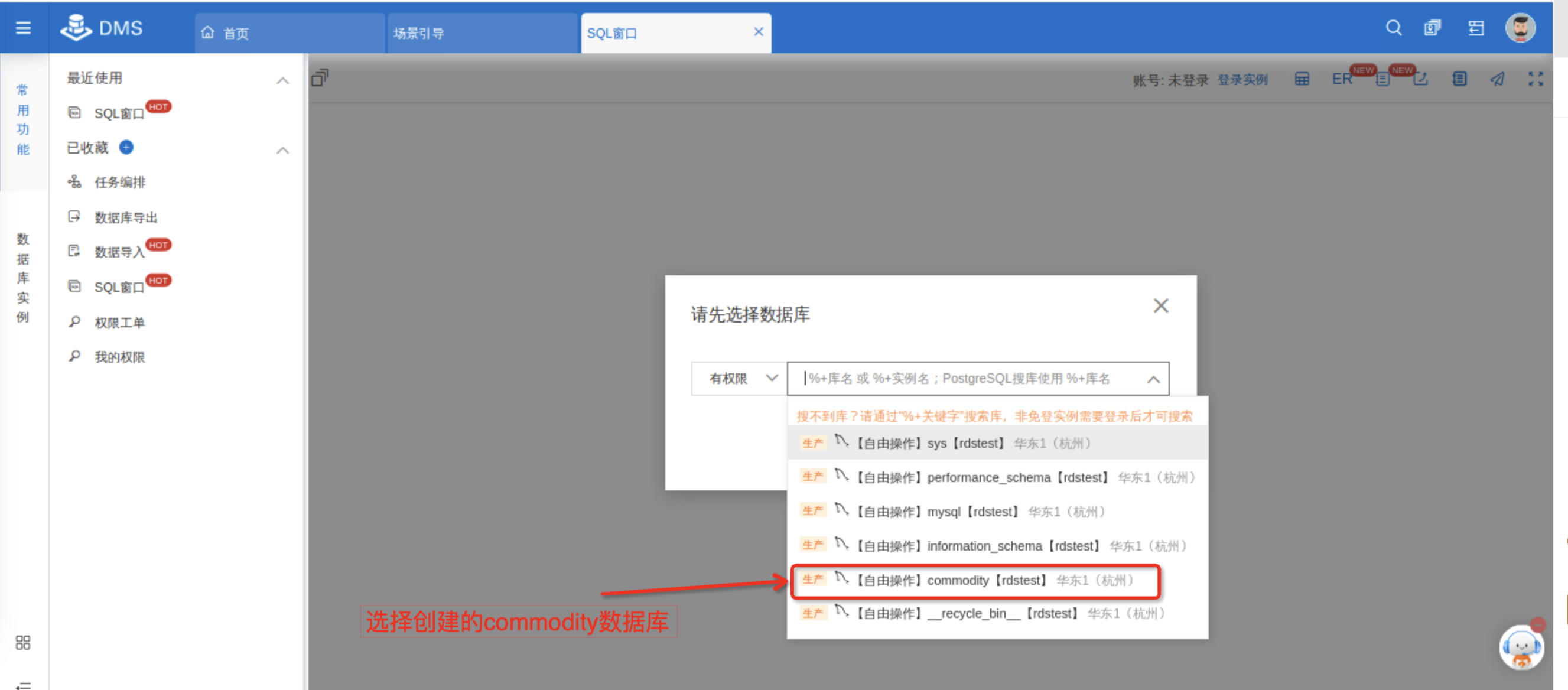
点击 我已知晓,不在提示,进入SQL窗口。
执行SQL
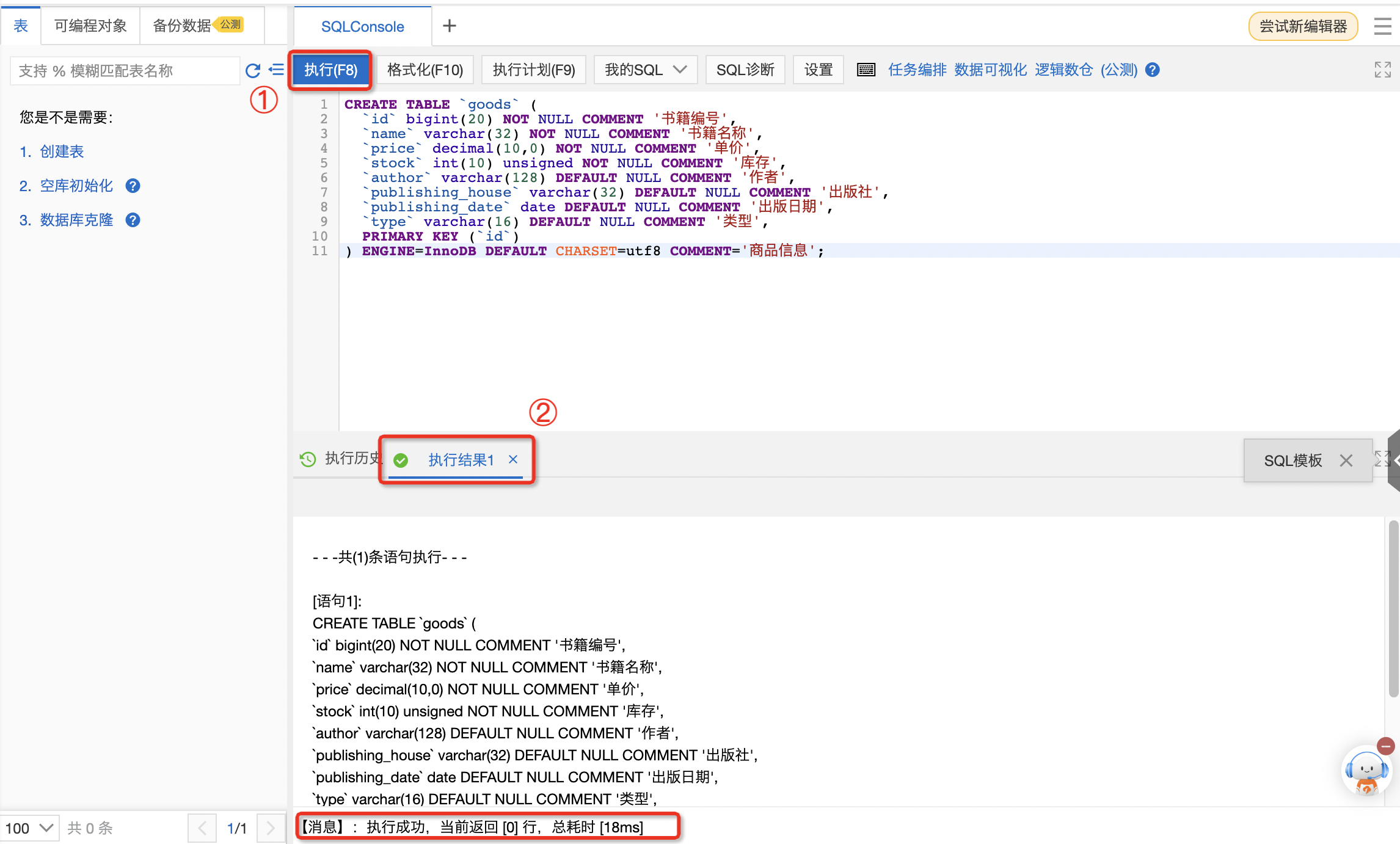
将以下SQL复制到SQL窗口,创建goods表,用于存储Excel表格中的数据。
说明:表的名字可自定义,使用数据库的流程是先创建出数据库,然后创建表,最后在往表中插入数据,关于表的相关操作,可参考数据库cloud认证第二阶段,SQL基础开发与应用。
CREATE TABLE `goods` (
`id` bigint(20) NOT NULL COMMENT '书籍编号',
`name` varchar(32) NOT NULL COMMENT '书籍名称',
`price` decimal(10,0) NOT NULL COMMENT '单价',
`stock` int(10) unsigned NOT NULL COMMENT '库存',
`author` varchar(128) DEFAULT NULL COMMENT '作者',
`publishing_house` varchar(32) DEFAULT NULL COMMENT '出版社',
`publishing_date` date DEFAULT NULL COMMENT '出版日期',
`type` varchar(16) DEFAULT NULL COMMENT '类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品信息';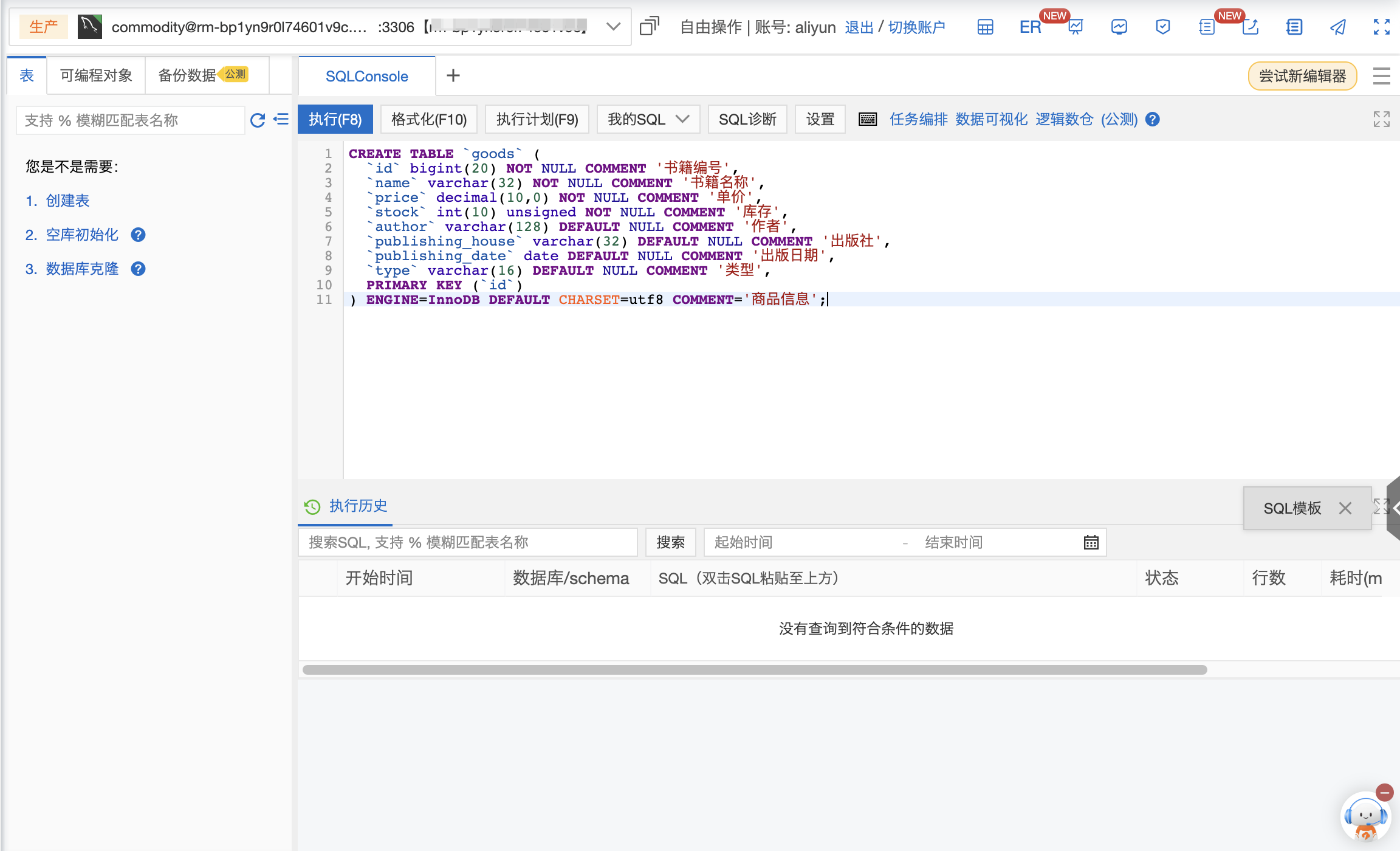
单击执行 ,页面返回执行成功标志,消息通知执行成功。
可点击
![]()
刷新按钮,将会出现新创建的goods表。

数据导入
下载数据。
将已准备好的Excel表格数据,通过OSS的bucket地址粘贴至浏览器中进行下载。
https://clouder-labfileapp.oss-cn-hangzhou.aliyuncs.com/database/%E5%95%86%E5%93%81%E7%AE%A1%E7%90%86%20.xlsx
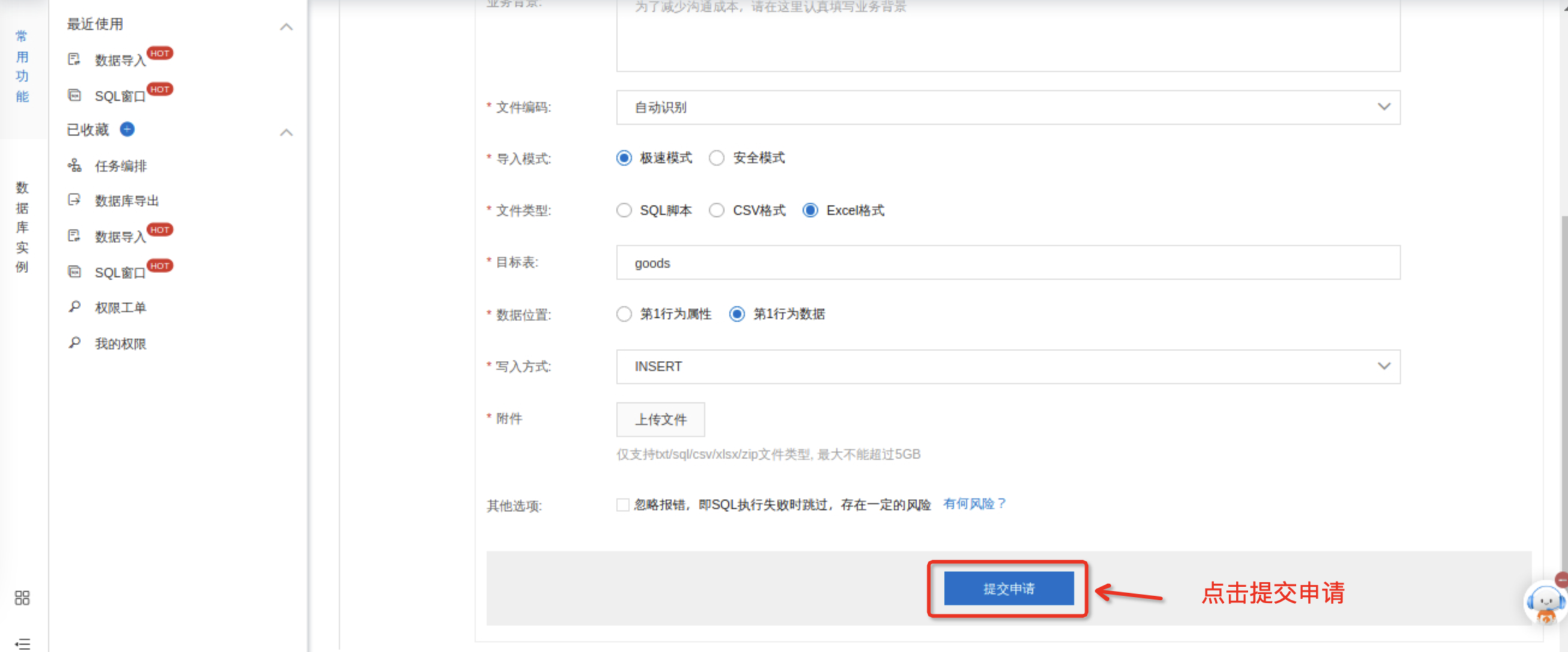
数据导入。在DMS控制台上,选择常用功能--->数据导入。
数据库:选择创建数据库步骤中所创建的数据库commodity;
文件类型:选择Excel格式;
目标表:选择创建的表goods;
数据位置:选择第1行为数据;
说明:
第1行为属性:表格首行是字段名。
第1行为数据:表格首行是数据。
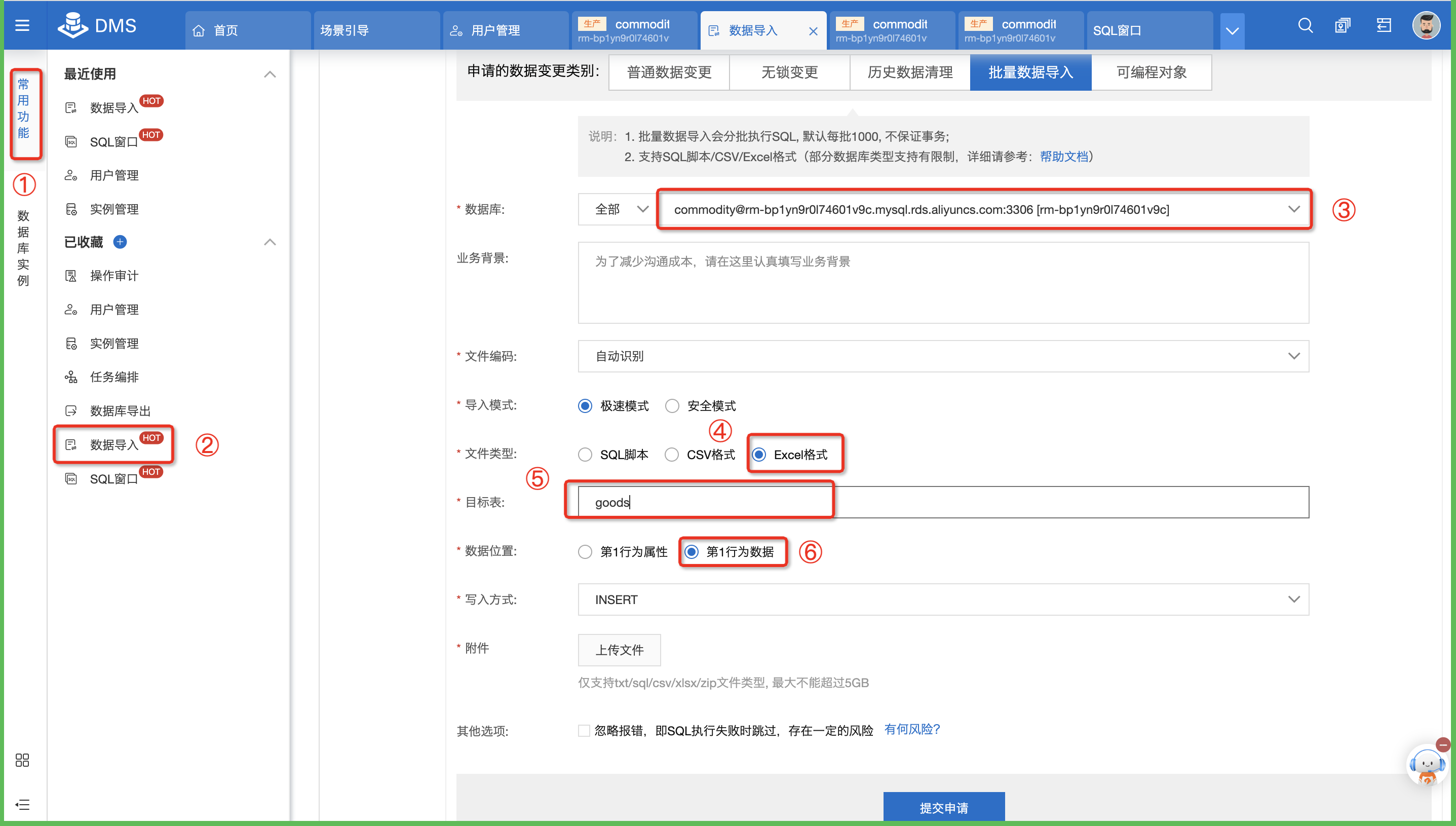
单击上传文件,将商品管理文件进行上传。
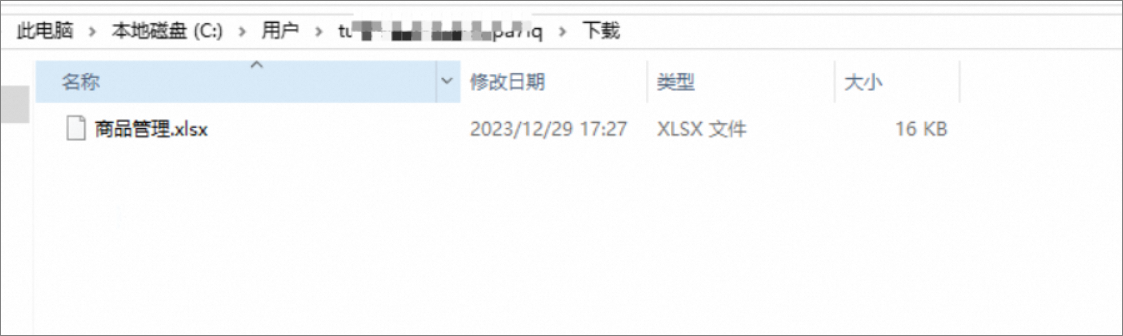
单击提交申请。
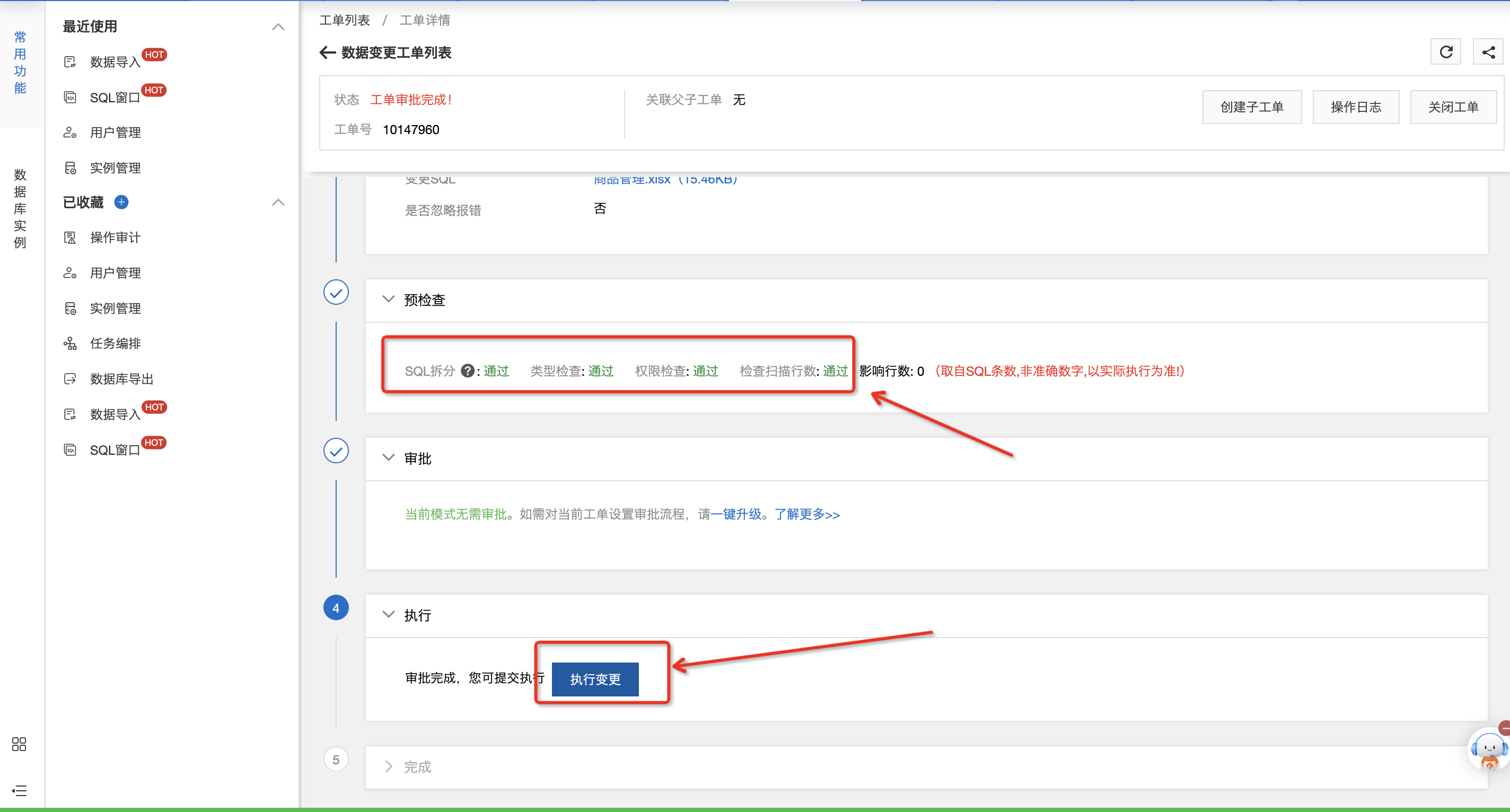
预检查阶段,需显示全部通过,单击执行变更。
单击确定执行。
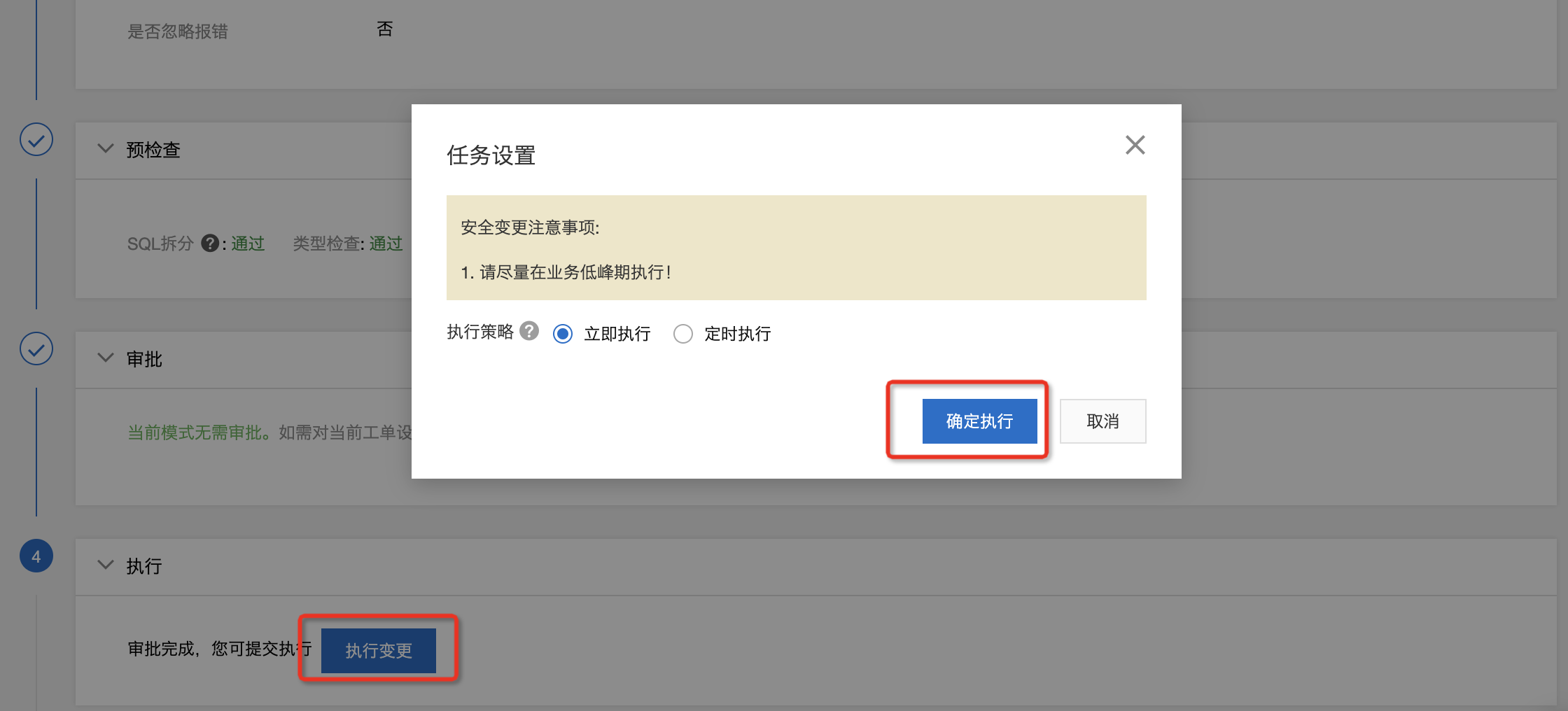
界面显示执行成功,即为文件上传成功。
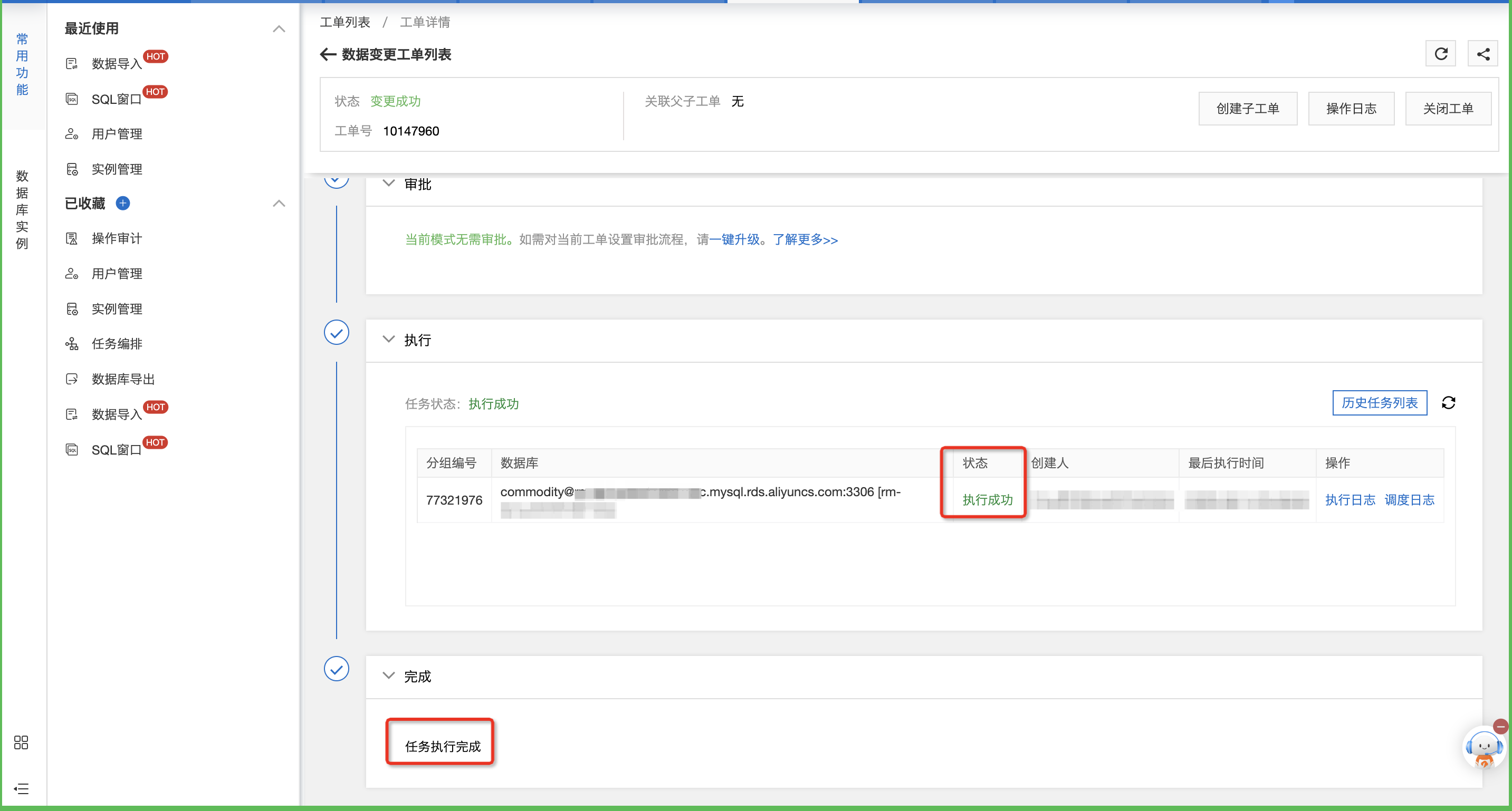
至此,已经完成了Excel表格数据上传到RDS数据库的操作,接下来,让我们一起在数据库中查询数据。
7. 查询导入RDS数据库中的数据
单击SQL窗口,选择数据库,单击确认,进行连接数据库。
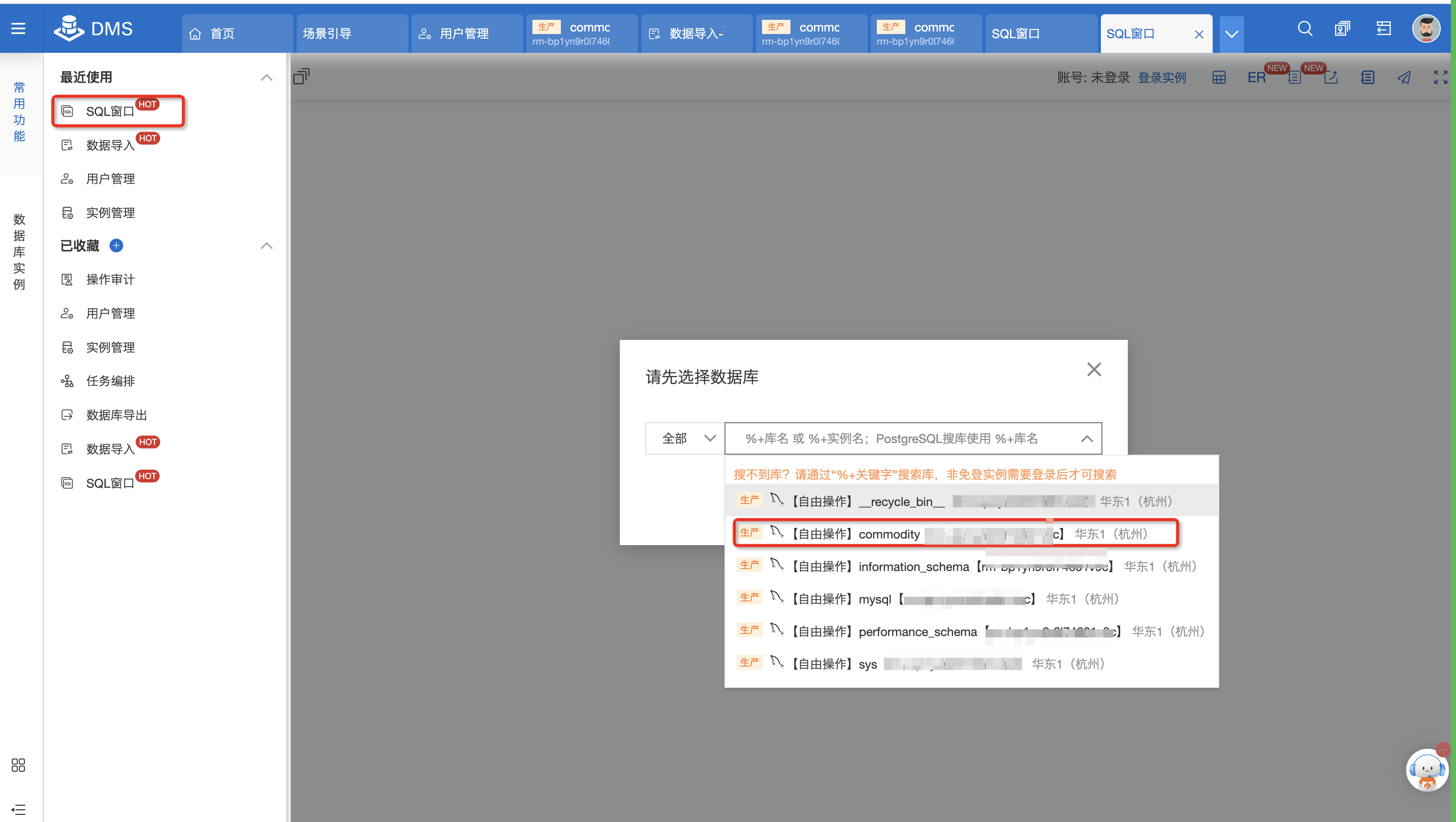
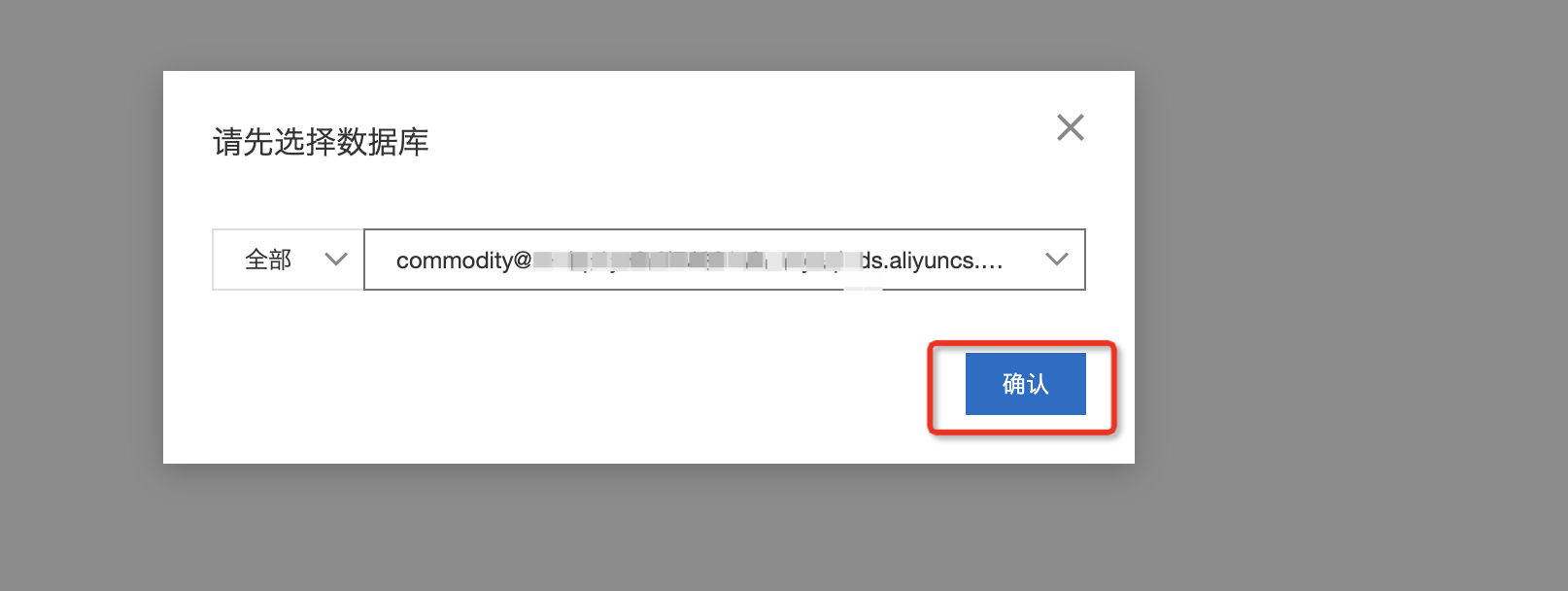
打开新的SQL窗口。
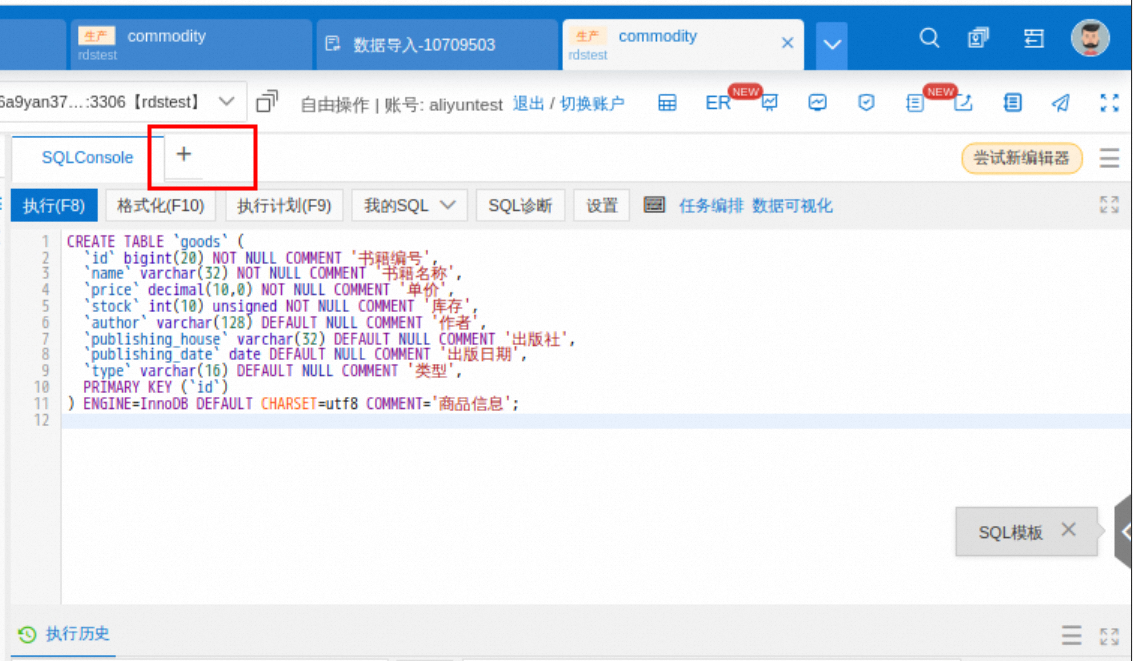
SQL窗口中,输入SQL,单击执行,查询goods表中的全量数据。
select * FROM `goods`;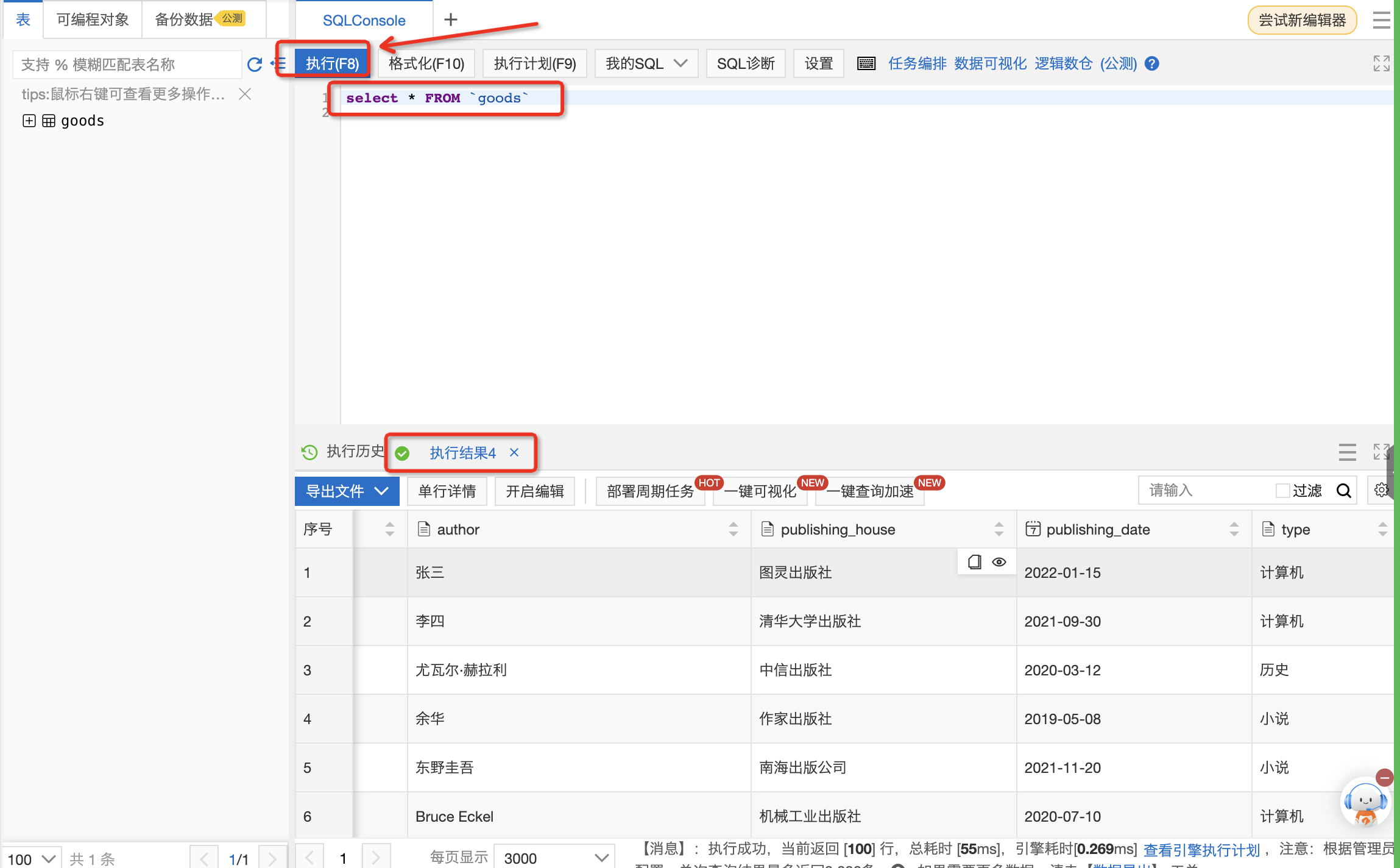
查询出的数据为全量的数据,与Excel表格中的数据进行对比,可发现数据一致。
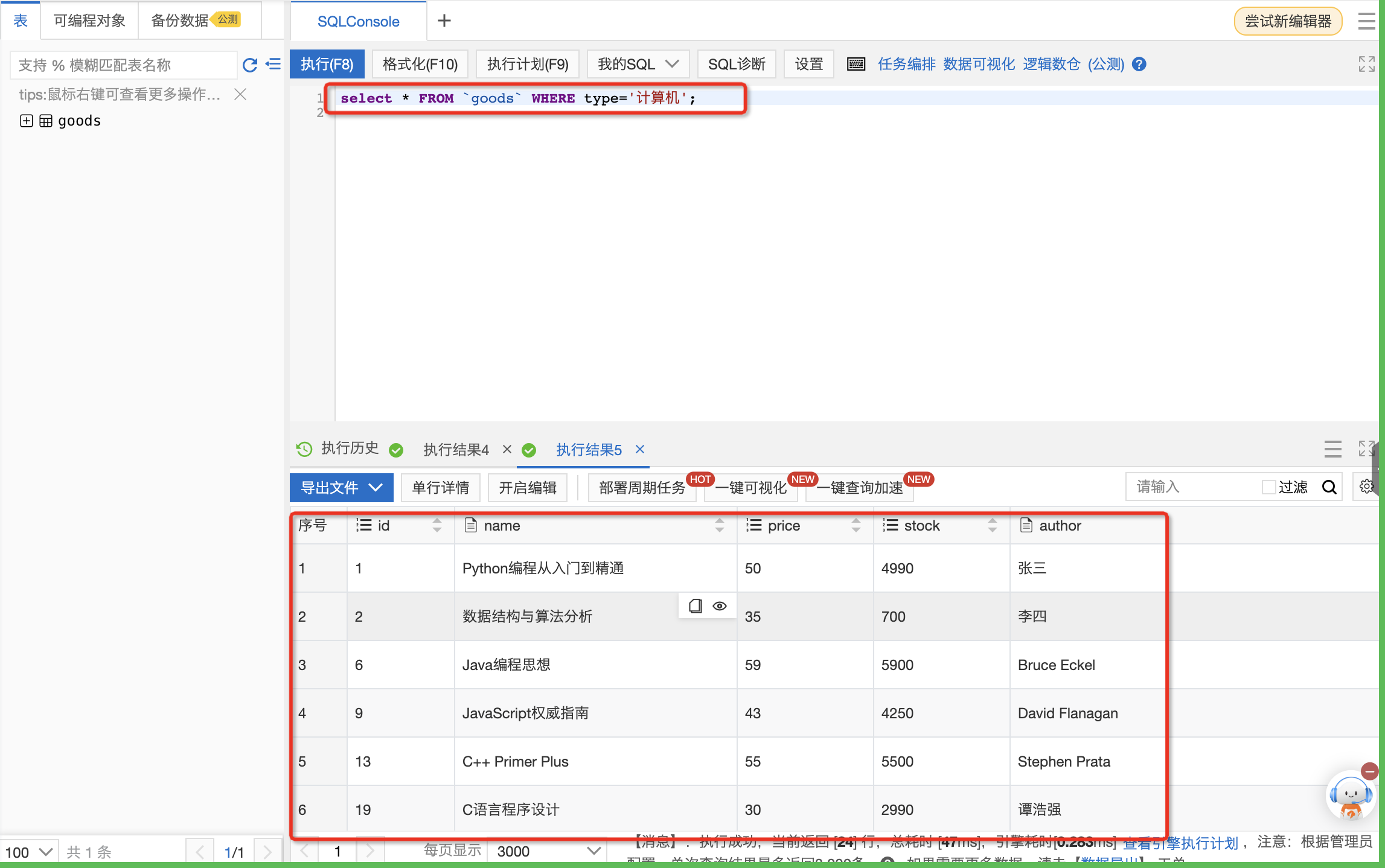
SQL窗口中,点击+号,新增SQL执行窗口,输入SQL,单击执行,在goods表中查询type字段为‘计算机’类型的数据。
select * FROM `goods` WHERE type='计算机';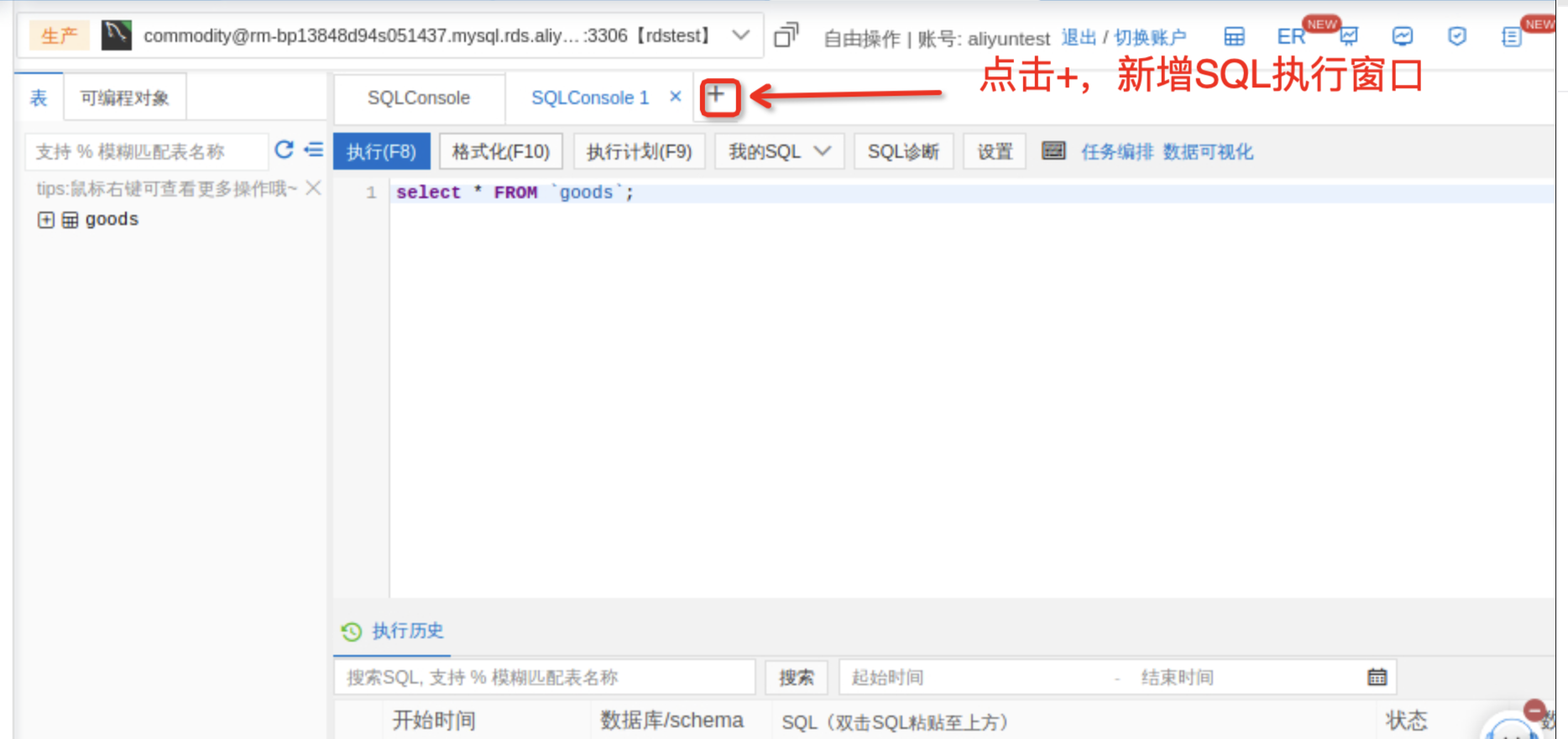
8. ECS连接数据库操作
数据库连接串准备
通过ECS连接数据库,需要输入MySQL的命令行进行连接,连接方式如下:
说明:
-
mysql -h 主机名 -u 用户名 -p 密码 -P 端口 。
-
-h : 该命令用于指定客户端所要登录的MySQL主机名。
-
-u : 所要登录的用户名。
-
-p : 告诉服务器将会使用一个密码来登录。
-
-P:一般默认为3306。
在进行下面的实验之前,需要找到数据库的连接地址、账户和密码。
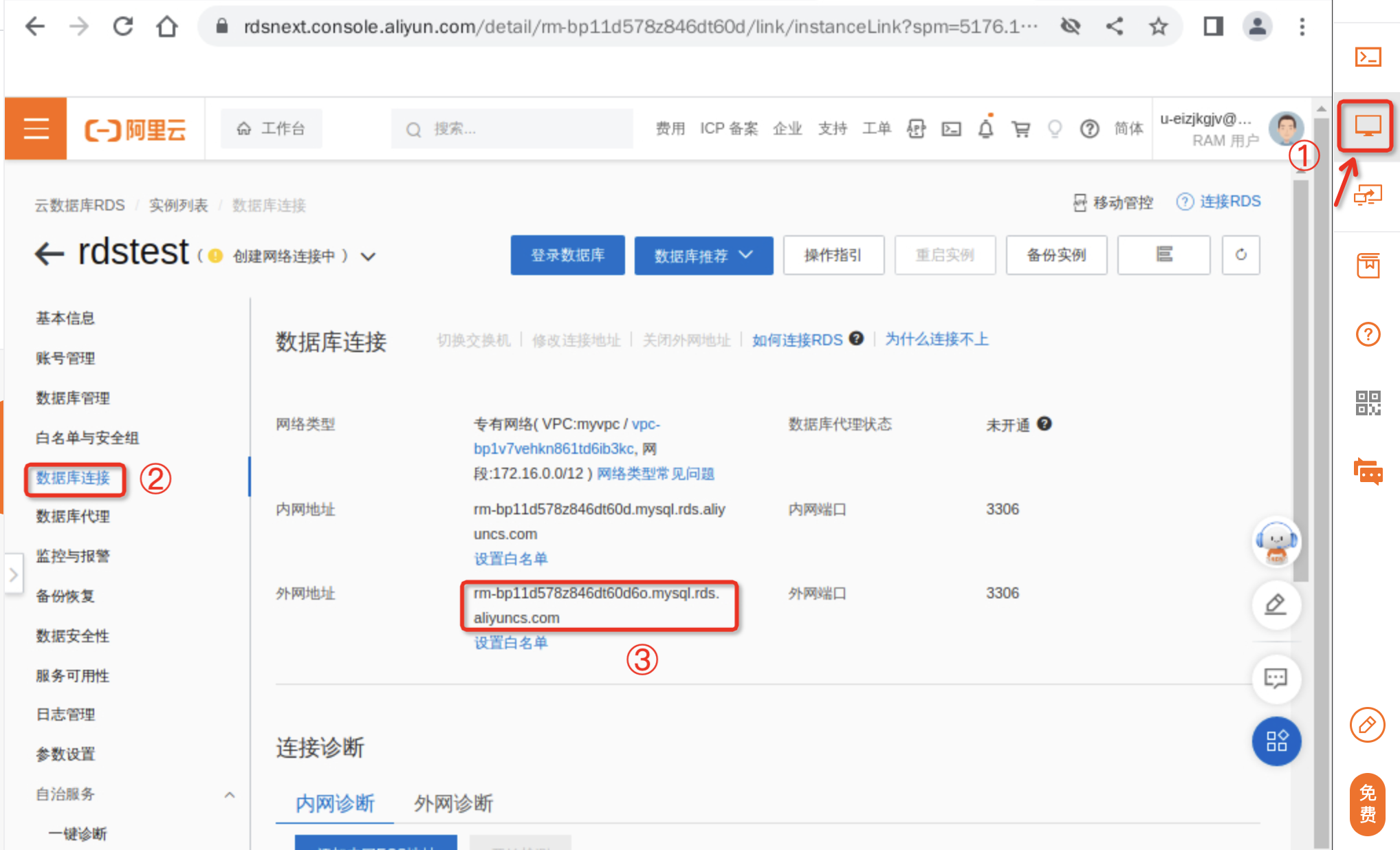
开通外网地址,点击实例功能栏左侧数据库连接,点击开通外网地址。
说明:
-
外网地址需要手动申请,不需要时也可以释放。
-
无法通过内网访问RDS实例时,您需要申请外网地址。具体场景如下:
-
ECS实例访问RDS实例,且ECS实例与RDS实例位于不同地域,或者网络类型不同。
-
阿里云以外的设备访问RDS实例。
-
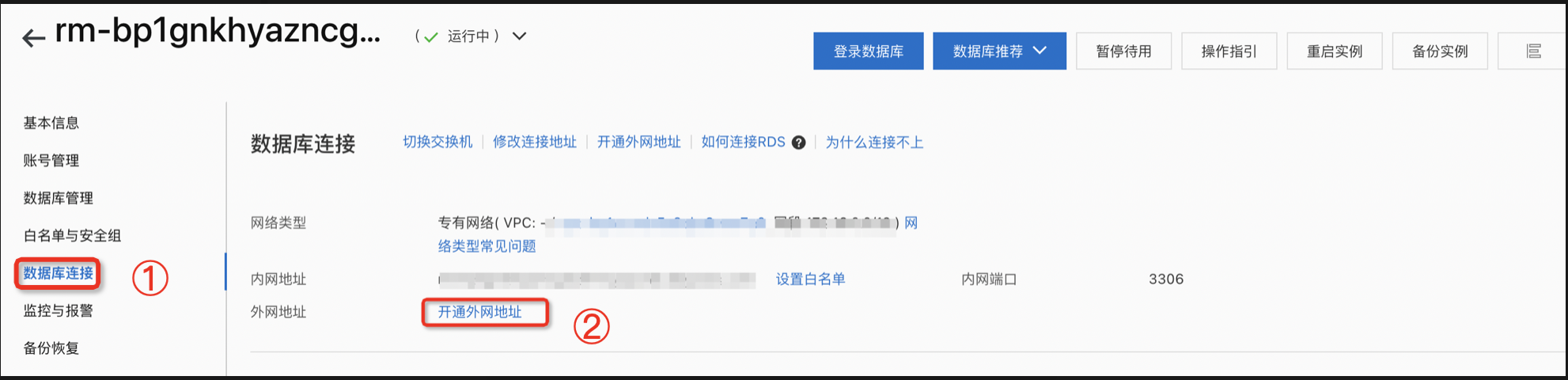

开通外网地址以后,将外网地址进行复制,后续步骤会进行使用该地址。
说明:在页面上显示外网地址,即为开通成功,一般需要等待1分钟,刷新页面即可看到。
ECS服务器登录数据库
在实验室页面右侧,单击单击
![]()
图标,切换至Web Terminal。
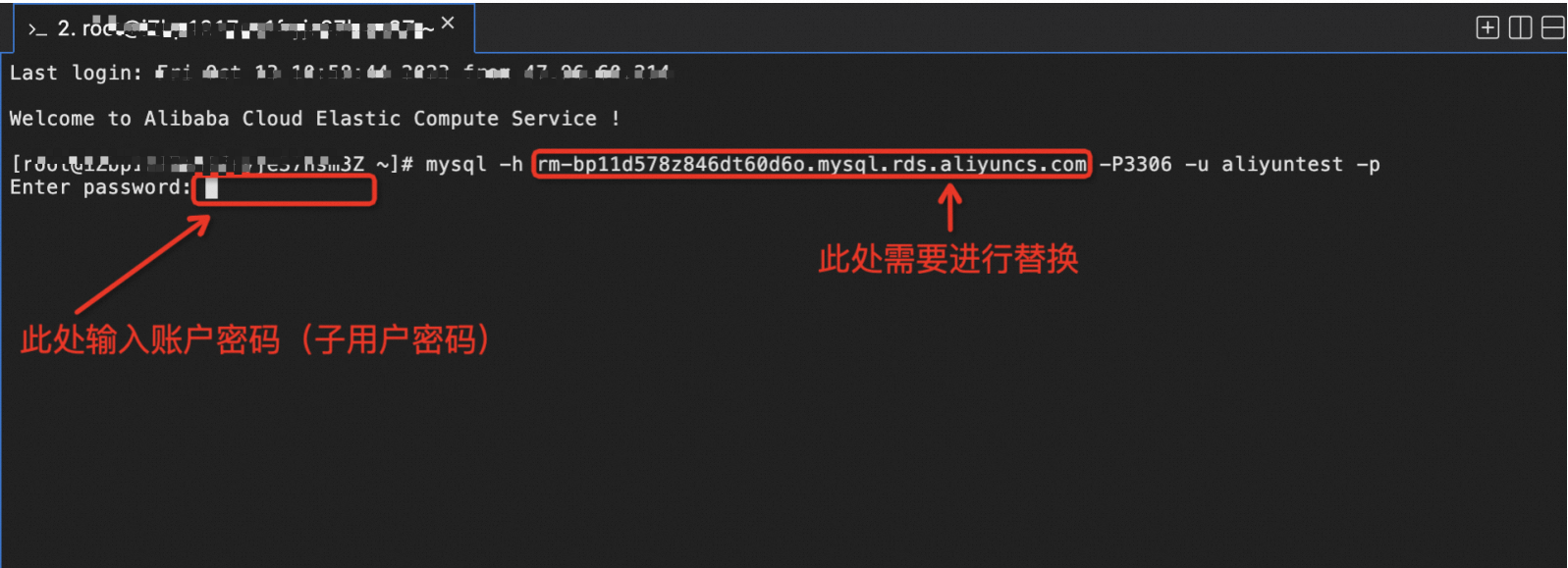
执行如下命令,登录数据库。
mysql -h rm-bp1gnkhyazncgwof78o.mysql.rds.aliyuncs.com -P3306 -u aliyuntest -p 说明:
需要将命令行中的rm-bp1gnkhyazncgwof78o.mysql.rds.aliyuncs.com地址替换为上述步骤查找到的外网地址,其他的参数无需更改
外网地址:跳回浏览器界面,进入数据库链接,获取外网地址。
数据库账户为之前步骤中所创建的数据库账号:aliyuntest
数据库密码为之前步骤中所创建的密码:子用户密码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











