




前言
友友们,以后别再叫我小北啦!从现在起,大家叫我小支同学会更好记哦!我也要跟过去的自己 say bye bye 啦~这也是小支同学今年的第一篇技术博客,希望能给大家带来有价值的内容。最近国产大模型 DeepSeek 可是火得一塌糊涂,频繁出现反应迟缓甚至宕机的情况,这和两年多之前 ChatGPT 的遭遇颇为相似。不过万幸的是,DeepSeek 是一个开源模型,我们完全可以通过本地部署,在自己的终端上随时使用它!接下来我就一步一步教大家具体的操作方法。
一文搞懂DeepSeek - 开源模型R1
在当下 AI 领域蓬勃发展的浪潮中,开源大型语言模型 DeepSeek-R1 宛如一颗璀璨的新星,强势崛起,备受瞩目。它凭借在数学、编程、推理等诸多任务中展现出的强大性能,迅速在大模型的赛道上占据了一席之地。其独特的纯强化学习训练方法,开源、低成本的特性,以及领先的技术创新,让它在竞争激烈的 AI 世界中脱颖而出,吸引了众多开发者和研究人员的目光。
在众多权威的基准测试中,DeepSeek-R1 的表现十分亮眼,甚至能与行业巨头 OpenAI o1 一较高下。以 AIME 2024 数学测试为例,DeepSeek-R1 的准确率与 OpenAI o1-0912 不相上下;在 MATH-500、Codeforces 以及 MMLU 等测试中,同样斩获了优异的成绩,充分证明了自身的实力。

要深入了解 DeepSeek-R1,首先得认识它的 “诞生地”——DeepSeek(深度求索)。DeepSeek 既是杭州深度求索人工智能基础技术研究有限公司的简称,也是该公司全力打造的通用人工智能开源大模型平台。这家公司凭借着自研训练框架、自建智算集群以及万卡算力等强大的资源,在极短的时间内就取得了令人瞩目的研发成果。DeepSeek 最大的优势之一,便是成功大幅缩减了以往大模型所需的庞大算力,极大地降低了大模型的成本,因此被形象地誉为 “AI 界的拼多多”。

DeepSeek 旗下拥有一系列丰富多样的模型,每一款都独具特色。DeepSeek-R1,作为数学、代码及推理领域的开源大模型,以其全面详实的回答和结构化的输出,在同类模型中表现出色;DeepSeek-V3,凭借自研的 MoE 模型和高达 671B 的参数,性能超越了所有已发布的开源模型,堪称极具性价比的顶尖大模型;DeepSeek-VL,是专为视觉和语言理解而设计的开源多模态模型,能够轻松处理复杂场景下的逻辑、公式识别以及自然图像等问题;DeepSeek-V2,以创新的模型架构和极低的推理成本,成为了追求性价比的用户的不二之选;DeepSeek-R1-Zero,作为采用强化学习训练的预模型,摒弃了传统的监督微调路线,展现出了独特的优势;还有从 R1 数据蒸馏而来的蒸馏版 Qwen 和 Llama 小模型,在部分任务上的表现甚至超越了 GPT-4o,令人刮目相看。
DeepSeek-R1:一款在数学、代码及自然语言推理领域与OpenAI o1比肩的开源大模型,以其全面、详实的回答和结构化输出著称。
- DeepSeek-V3:凭借自研MoE模型和671B参数,在性能上超越所有已发布的开源模型,成为极具性价比的顶尖大模型之一。
- DeepSeek-VL:专为视觉和语言理解设计的开源多模态模型,能够处理复杂场景下的逻辑、公式识别及自然图像等问题。
- DeepSeek-V2:以创新的模型架构和极低的推理成本,成为性价比极高的大模型选择。
- DeepSeek-R1-Zero:采用强化学习训练的预模型,不走传统监督微调路线,展现独特优势。
- 蒸馏版Qwen、Llama系列小模型:从DeepSeek-R1数据上蒸馏得到的小模型,表现优秀,部分任务上甚至超越GPT-4o。
DeepSeek-R1 于 2025 年 1 月 20 日正式发布,它采用了包含 6710 亿参数的 MoE(专家混合)架构,主打推理功能。值得一提的是,DeepSeek-R1 开源了模型权重,并采用了宽松的 MIT 许可协议,这一举措为广大开发者提供了极大的便利和灵活性,让他们能够更自由地使用和探索该模型。与 OpenAI-o1 相比,DeepSeek-R1 的优势显而易见,开源特性、强化学习训练带来的高效推理能力以及低成本,为开发者提供了更多的选择。

DeepSeek-R1 的核心亮点非常突出。它是首个完全通过强化学习训练的大型语言模型,无需进行监督微调,这一特性大大简化了模型的训练流程。同时,通过结合冷启动数据进行训练,有效解决了 R1-Zero 在可读性和语言混合方面的局限性,显著提升了模型的推理能力。此外,DeepSeek-R1 还提供了六个不同规模的蒸馏版本(1.5B 至 70B),以满足不同规模开发者的需求。与 OpenAI o1 相比,其 API 调用成本大幅降低,进一步增强了它的竞争力。
在技术创新方面,DeepSeek-R1 也有着独到之处。它开发了 GRPO 算法,通过群组相对优势估计来优化策略网络,有效避免了传统 Critic 网络的高计算开销。同时,设计了包括准确性、格式和语言一致性在内的多层次奖励机制,确保了模型在推理任务中的高效性和输出内容的可读性。另外,通过 “思考 - 回答” 双阶段训练模板,实现了推理过程的可追踪性,并为奖励计算提供了明确的基准,从而输出结构化的答案,让模型的推理更加透明、可靠
DeepSeek-R1 凭借其出色的性能、独特的特性和创新的技术,在 AI 领域中树立了新的标杆,为大模型的发展带来了新的思路和方向,有望在未来的 AI 应用中发挥更为重要的作用。
一、用 Ollama 下载模型
首先,我们需要安装 Ollama,它能够在本地运行和管理大模型。大家可以到 Ollama 官网:OllamaGet up and running with large language models.https://ollama.com/https://ollama.com/![]() https://ollama.com/点击下载,然后根据自己的系统选择适合的版本,这里以 Windows 系统为例。下载完成后点击安装,安装完成后安装窗口会自动关闭,此时系统托盘图标会出现一个常驻的 Ollama 标记。
https://ollama.com/点击下载,然后根据自己的系统选择适合的版本,这里以 Windows 系统为例。下载完成后点击安装,安装完成后安装窗口会自动关闭,此时系统托盘图标会出现一个常驻的 Ollama 标记。
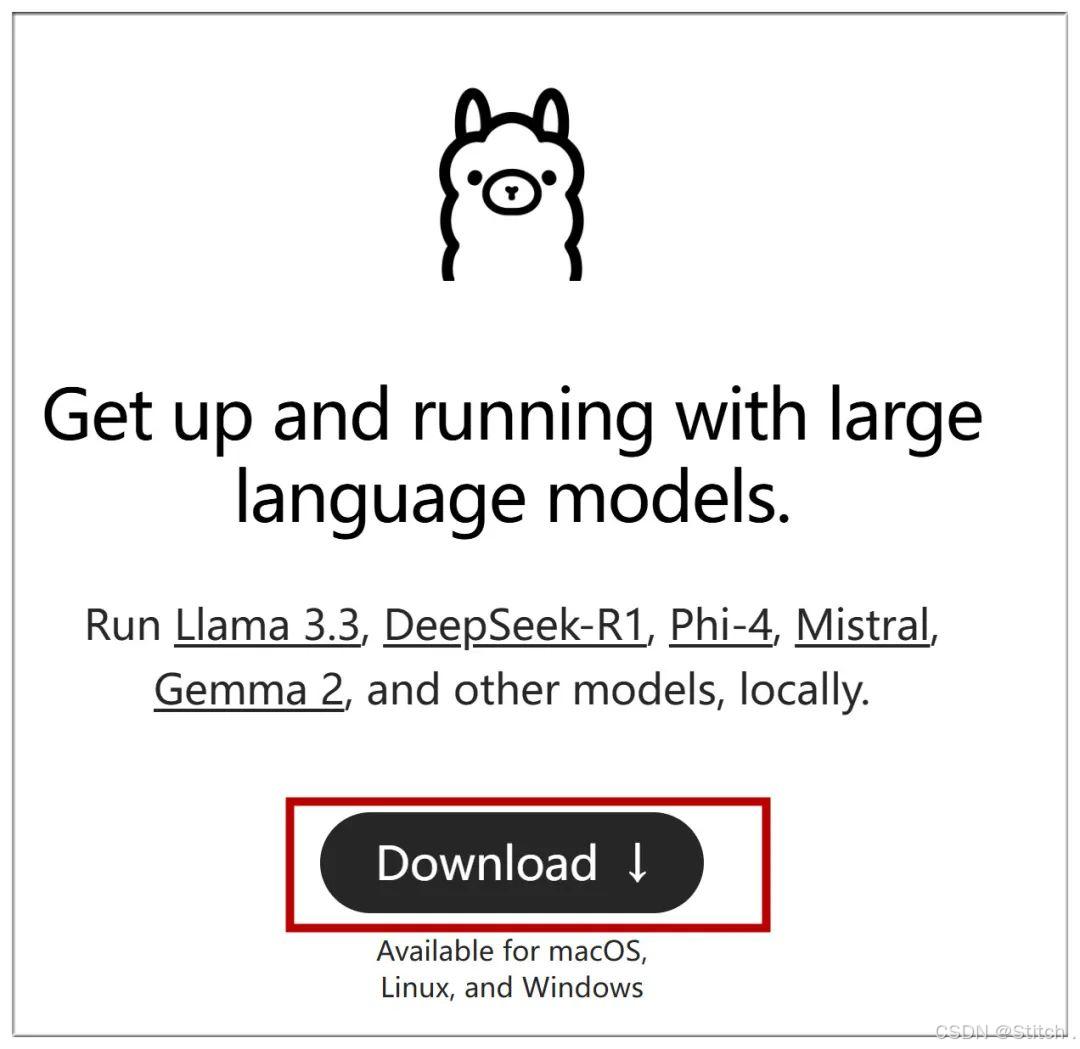
到Ollama官网:Download Ollama on Windowshttps://ollama.com/download/windows![]() https://ollama.com/download/windowsDownload Ollama on Windows 点击下载,然后选择适合自己系统的版本,这里选择Windows:
https://ollama.com/download/windowsDownload Ollama on Windows 点击下载,然后选择适合自己系统的版本,这里选择Windows:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











