









1、word导出为txt
另存为纯文本txt格式,命名为paper_old.txt,选择这个配置
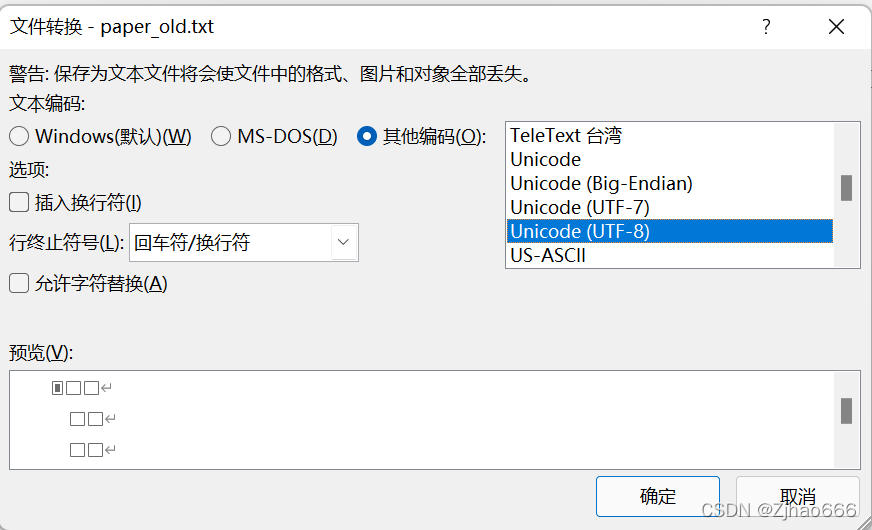
举例,得到如下的txt内容:
xxxxxxxxxxxxxxxxx[5]xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxx[3-4]xxxx
xxxxxxxxxxxasdasdasdxxx[1]
参考文献开始
[1] Lee B J, Lee J, Kim K E. Representation Balancing Offline Model-based Reinforcement Learning[C]//9th International Conference on Learning Representations, 2021, Virtual Event, Austria, May 3-7, 2021. 2021.
[2] 鲍军威. 基于知识的自动问答与问题生成的研究[D]. 哈尔滨工业大学, 2019.
[3] 乔振浩, 车万翔. 基于知识图谱的问答系统研究与应用[D]. 哈尔滨工业大学, 2020.
[4] 向伟富, 段贵多. 面向问答系统的知识图谱推理算法的研究与实现[D]. 电子科技大学, 2020.
[5] 刘良. 基于领域知识图谱的智能问答关键技术研究[D]. 电子科技大学, 2020.
注:“参考文献开始”那一行是手动加上去的,以区分前文的引用和后文的引文。
可见编号有两种类型:[x]或者[x-y]。
2、引文顺序检查
python文件citation_sort.py
输出:
- quotation_old2new_id.txt:旧引文编号->新引文编号,末尾再跟上未引用的旧引文编号
- quotation_new.txt:更新后的带编号新引文序列
- paper_new.txt:更新后的带引用正文+新版参考文献
注:paper_old.txt、citation_sort.py、quotation_old2new_id.txt、quotation_new.txt均在相同目录
import re
from ordered_set import OrderedSet
import collections
old_filename = 'paper_old.txt'
quotation_old2new_id_filename = 'quotation_old2new_id.txt'
quotation_new_filename = 'quotation_new.txt'
new_filename = 'paper_new.txt'
with open(old_filename, 'r', encoding='utf-8') as f:
file_lines = f.readlines()
quotation_start = False
cite_history = []
quotation_dict = collections.OrderedDict()
for line in file_lines:
line = line.strip('\n')
if line == '参考文献开始':
quotation_start = True
else:
if quotation_start == False:
# (\[\d+\]|\[\d+\-\d+\])
matchCite = re.findall(r'(\[\d+\]|\[\d+\-\d+\])', line)
if matchCite:
# print(matchCite)
for cite in matchCite:
cite = cite.replace('[', '').replace(']', '')
if '-' in cite:
start, end = cite.split('-')
start, end = int(start), int(end)
cite_temp = list(range(start, end+1))
cite_history.extend(cite_temp)
else:
cite = int(cite)
cite_history.append(cite)
else:
matchQuotation = re.search(r'(\[\d+\])\s(.+)', line)
id_old = int(matchQuotation.group(
1).replace('[', '').replace(']', ''))
quotation = matchQuotation.group(2)
quotation_dict[id_old] = quotation
# print(cite_history)
cite_history_OrderedSet = OrderedSet(cite_history)
# print(cite_history_OrderedSet)
# print(quotation_dict)
quotation_full = OrderedSet(quotation_dict.keys())
quotation_useless = quotation_full-cite_history_OrderedSet
print('未使用的参考文献:', list(quotation_useless))
# print()
quotation_old2new = collections.OrderedDict(
zip(range(1, quotation_full[-1]+1), [-1]*5))
# print(quotation_old2new)
count = 1
for id_old in cite_history_OrderedSet:
quotation_old2new[id_old] = count
count += 1
for id_old in quotation_useless:
quotation_old2new[id_old] = count
count += 1
# quotation_old2new_id_filename = 'quotation_old2new_id.txt'
# quotation_new_filename = 'quotation_new.txt'
with open(quotation_old2new_id_filename, 'w+', encoding='utf-8') as f:
for old_id, new_id in quotation_old2new.items():
f.write('%d->%d\n' % (old_id, new_id))
f.write('未使用的参考文献:' + str(list(quotation_useless)))
# quotation_new2old_temp = dict(
# zip(quotation_old2new.values(), quotation_old2new.keys()))
quotation_new2old = collections.OrderedDict()
for key, value in quotation_old2new.items():
quotation_new2old[value] = key
# print(quotation_new2old)
with open(quotation_new_filename, 'w+', encoding='utf-8') as f:
count = 1
for old_id, new_id in quotation_new2old.items():
if count == quotation_old2new[quotation_useless[0]]:
f.write('*******以下为未引用文献********\n')
f.write('[%d]\t%s\n' %
(count, quotation_dict[quotation_new2old[new_id]]))
count += 1
# 重新编排原文的正文引用
quotation_start = False
with open(new_filename, 'w+', encoding='utf-8') as f:
for line in file_lines:
# line = line.strip('\n')
if line == '参考文献开始\n':
quotation_start = True
f.write(line)
else:
if quotation_start == False:
# (\[\d+\]|\[\d+\-\d+\])
matchCite = re.findall(r'(\[\d+\]|\[\d+\-\d+\])', line)
if matchCite:
# print(matchCite)
for cite in matchCite:
cite = cite.replace('[', '').replace(']', '')
if '-' in cite:
start, end = cite.split('-')
start, end = int(start), int(end)
start_new, end_new = quotation_old2new[start], quotation_old2new[end]
line = line.replace('[%d-%d]' % (start, end),
'[%d-%d]' % (start_new, end_new))
# cite_temp = list(range(start, end+1))
# cite_history.extend(cite_temp)
else:
cite = int(cite)
cite_new = quotation_old2new[cite]
line = line.replace('[%d]' %
(cite), '[%d]' % (cite_new))
# cite_history.append(cite)
f.write(line)
else:
break
# matchQuotation = re.search(r'(\[\d+\])\s(.+)', line)
# id_old = int(matchQuotation.group(
# 1).replace('[', '').replace(']', ''))
# id_new = quotation_old2new[id_old]
# line=line.replace('[%d]' % (id_new), '[%d]' % (id_old))
# quotation = matchQuotation.group(2)
# quotation_dict[id_old] = quotation
count = 1
for old_id, new_id in quotation_new2old.items():
if count == quotation_old2new[quotation_useless[0]]:
f.write('*******以下为未引用文献********\n')
f.write('[%d]\t%s\n' %
(count, quotation_dict[quotation_new2old[new_id]]))
count += 1
执行
python citation_sort.py得到quotation_old2new_id.txt:旧引文编号->新引文编号,末尾再跟上未引用的旧引文编号
1->4
2->5
3->2
4->3
5->1
未使用的参考文献:[2]以及quotation_new.txt:更新后的带编号新引文序列
[1] 刘良. 基于领域知识图谱的智能问答关键技术研究[D]. 电子科技大学, 2020.
[2] 乔振浩, 车万翔. 基于知识图谱的问答系统研究与应用[D]. 哈尔滨工业大学, 2020.
[3] 向伟富, 段贵多. 面向问答系统的知识图谱推理算法的研究与实现[D]. 电子科技大学, 2020.
[4] Lee B J, Lee J, Kim K E. Representation Balancing Offline Model-based Reinforcement Learning[C]//9th International Conference on Learning Representations, 2021, Virtual Event, Austria, May 3-7, 2021. 2021.
*******以下为未引用文献********
[5] 鲍军威. 基于知识的自动问答与问题生成的研究[D]. 哈尔滨工业大学, 2019.注释:“*******以下为未引用文献********”行为自动添加的额外行,为区分已用和未用的参考文献。
正文paper_new.txt长这样:
xxxxxxxxxxxxxxxxx[1]xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxx[2-3]xxxx
xxxxxxxxxxxasdasdasdxxx[4]
参考文献开始
[1] 刘良. 基于领域知识图谱的智能问答关键技术研究[D]. 电子科技大学, 2020.
[2] 乔振浩, 车万翔. 基于知识图谱的问答系统研究与应用[D]. 哈尔滨工业大学, 2020.
[3] 向伟富, 段贵多. 面向问答系统的知识图谱推理算法的研究与实现[D]. 电子科技大学, 2020.
[4] Lee B J, Lee J, Kim K E. Representation Balancing Offline Model-based Reinforcement Learning[C]//9th International Conference on Learning Representations, 2021, Virtual Event, Austria, May 3-7, 2021. 2021.
*******以下为未引用文献********
[5] 鲍军威. 基于知识的自动问答与问题生成的研究[D]. 哈尔滨工业大学, 2019.
可以作为修改为,检查引用和引文顺序是否修改正确的,辅助对照工具。
3、修改word的引文
方法:依照quotation_old2new_id.txt的方式,将箭头左边的编号,完整ctrl x剪贴后,放在右边对应位置。再ctrl a全选,f9刷新全文的引用编号。如图

注:如果要在第一个前面插文献x,建议先在1下面回车新建个空的2,把x先剪切到2,再把1剪切到2的下面,就行了。不然直接在[1]后面回车,会把原来的引文1干成两段,f9之后会出错的——原来指向文献x的就指向了文献1。。。。
最后,复制引文部分,到文件quotation_new_self.txt。
再和quotation_new.txt校验一遍是否相同即可(以下为未引用文献 行就不管了),比如用vscode打开文件夹,先右键quotation_new_self.txt“选择以进行比较”,再右键quotation_new.txt“与已选择的进行比较”。
除了我们自己加的“*******以下为未引用文献********”行,其他的都完全一致。

说明我们都改对了,游戏结束。

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









