







进入电脑微信,找“文件资源传输助手”,复制失效的url,回车
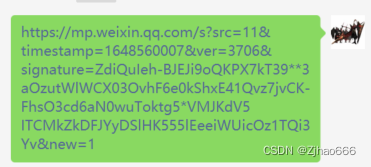
点击url,可以看到是微信浏览器的界面(如果没有顶上工具栏,随意拉伸一下界面即可)
选择左上角获取url的工具![]() ,自动就复制了
,自动就复制了
粘贴后即可得到永久链接: https://mp.weixin.qq.com/s/YaXEcgDORFw1nBj6hGJhnA
进入电脑微信,找“文件资源传输助手”,复制失效的url,回车
点击url,可以看到是微信浏览器的界面(如果没有顶上工具栏,随意拉伸一下界面即可)
选择左上角获取url的工具![]() ,自动就复制了
,自动就复制了
粘贴后即可得到永久链接: https://mp.weixin.qq.com/s/YaXEcgDORFw1nBj6hGJhnA

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 228
228





