






AlexNet
是基于
CNN
结构的神经网络模型,由
ALex
、
Hinton
等研究者共 同发明,曾于 2012
年的
ILSVRC
图像识别大赛上荣膺最佳表现
。在 ImageNet 数据集上,
AlexNet
的性能超过了所有的传统机器学习模型,开启了 深度学习在计算机视觉领域中的应用。
本篇文章将基于AlexNet利用JAFFE数据集进行训练,完成人脸表情识别任务。
首先来看看AlexNet的模型结构
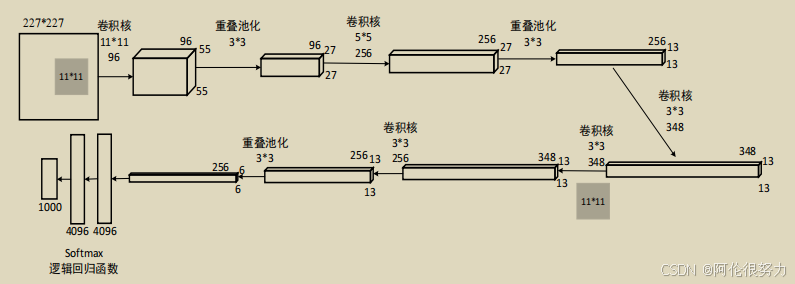
可以看到其实就是一堆的CNN的堆砌,但是效果就是不错
具体的参数可见代码
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=7):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 348, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(348, 348, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(348, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
以上就是模型结构了,接下来我们来看下我们用于训练和测试的数据集
JAFFE(Japanese Female Facial Expression)是一个经典的面部表情识别数据集,广泛用于情感计算和计算机视觉领域的研究。它包含了日本女性在不同表情下的面部图像,是研究面部表情识别的常用基准数据集之一。
-
样本数量:
-
JAFFE 数据集包含 213 张灰度图像。
-
这些图像来自 10 位日本女性,每位女性有 7 种基本表情。
-
-
表情类别:
-
7 种基本表情类别分别是:
-
Anger(生气)
-
Disgust(厌恶)
-
Fear(恐惧)
-
Happy(高兴)
-
Sad(悲伤)
-
Surprise(惊讶)
-
Neutral(中性)
-
-
-
图像格式:
-
图像为灰度图,分辨率为 256x256 像素。
-
每张图像以
.tiff格式存储。
-
-
标注信息:
-
每张图像都有对应的表情标签,方便用于监督学习任务。
-

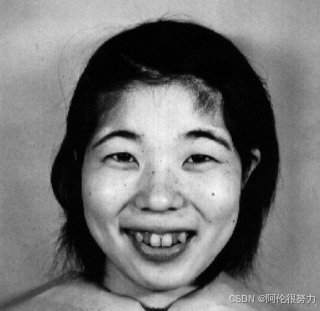
首先来讨论下图片的预处理
为了适应别的训练集,所以在预处理部分先将图像转为灰度,然后为了加强对比度使用直方图均衡化,然后为了适应模型的输入,重新扩展为RGB三通道图片,最后为了适应AlexNet模型输入,对图像中心裁剪 227*227,同时要对图像进行标准化。
接下来就是一些训练的参数的确定,损失函数我们使用交叉熵损失函数,优化器使用Adam
epochs = 200 lr = 0.001
代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets, models
from torch.utils.data import DataLoader, random_split
import os
from OriginAlexNet import AlexNet
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import cv2
import numpy as np
from PIL import Image
# 定义图像预处理方法
def preprocess_image(image):
# 1. 将图像转为灰度
image_gray = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
# 2. 进行直方图均衡化
image_eq = cv2.equalizeHist(image_gray)
# 3. 转换回三通道,复制灰度值到R, G, B通道
image_eq_rgb = cv2.cvtColor(image_eq, cv2.COLOR_GRAY2RGB)
# 将图像转换为PIL格式
return Image.fromarray(image_eq_rgb)
# 图像预处理管道
transform = transforms.Compose([
transforms.Resize(256), # 图像调整为 256*256
transforms.CenterCrop(227), # 中心裁剪 227*227
transforms.Lambda(lambda x: preprocess_image(x)), # 自定义预处理方法
transforms.ToTensor(), # 转为Tensor
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 标准化
])
# 加载数据集
dataset_path = "../jaffe"
full_dataset = datasets.ImageFolder(root=dataset_path, transform=transform)
# 划分训练集和验证集 (85-15)
train_size = int(0.85 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 初始化模型
model = AlexNet(num_classes=7).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss().to(device) # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练参数
num_epochs = 200
best_acc = 0.0
# 训练循环
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
epoch_loss = running_loss / len(train_dataset)
# 验证阶段
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
print(f"Epoch [{epoch + 1}/{num_epochs}] "
f"Train Loss: {epoch_loss:.4f} "
f"Val Acc: {acc:.2f}%")
# 保存最佳模型
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), "OriginAleNet_JAFFE.pth")
print(f"Training complete. Best validation accuracy: {best_acc:.2f}%")
最好的准确率在72.73%

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









