






一 深度学习基础
1. 什么是深度学习?它与传统机器学习有何不同?
答:首先要明确的一点是,深度学习是机器学习的一个子集。引用一个专家的定义“深度学习是一种机器学习的形式,使计算机能够从经验中学习并以概念层次结构的方式理解世界。”,何为从经验中学习?也就是拿既有数据对一个模型的训练,训练的是什么呢?当然是参数,但这种参数组织方式不同于传统机器学习。深度学习的参数的组织方式是一层一层的(比如神经网络每层神经元的权值w),传统的机器学习的参数可能往往是一种线性的组织形式(比如y=kx+b中的k),参数的组织形式表现出来的是深度学习是以概念层次结构来理解世界的,所以这也可能是高维复杂非线性问题上深度学习的表现碾压传统机器学习的原因之一。
在我看来,深度学习相比于传统机器学习,更具有黑盒的性质,一个多层的神经网络,你并不知道某一层到底是在处理什么,只是看得到最后的结果是符合预期的;机器学习就相对来的透明一些,也是这种黑盒的性质,深度学习在数理论证方面带来的挑战远大于传统机器学习。
还有一点就是,深度学习模型的复杂带来的是爆炸性增长的参数量,这也就导致深度学习相比于传统机器学习需要更多的训练数据,更久的训练时间,对硬件也带来不小的压力(OpenAI对于ChatGPT就是大力出奇迹,堆参数量,购买大量英伟达GPU用于训练模型)
2. 解释过拟合和欠拟合的概念。提供两种避免过拟合的策略。
答:简单的说,过拟合就是模型在训练过程中过于匹配训练数据了,在训练数据上表现出超高的准确度,在测试数据上表现较差。欠拟合就是模型训练的太少了,也许准确率在训练集上都达不到需求,就更不用说在测试数据集上有什么优秀的表现了。
方法一:最直接的方法就是调整数据集的训练测试的划分比例,适当的减少训练数据比例,多次尝试,找到适宜的比例。
方法二:就是在每轮训练之后,都拿测试集去测试模型,当测试集的准确率开始下降的时候(条件可以是持续的下降,单次的下降也许是偶然性),选择停止模型的训练,达到防止过拟合的目的。
3. 解释梯度消失和梯度爆炸的问题以及它们为何在训练深度神经网络时是重要的。
答:梯度消失和梯度爆炸是发生在利用反向传播算法中的链式法则来对神经网络进行模型训练的时候。(下图为链式法则)
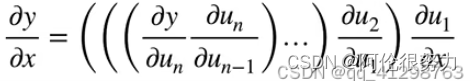
由链式法则可知,其实就是每层的导数不断累乘。当层数足够多的时候,若每层的梯度(导数)都小于1,那么越乘越小,以至于在靠近输入层的位置,梯度将趋近于0,这就是梯度消失。那么梯度爆炸则与之相反,若每层的梯度(导数)大于1,那么越乘越大,这时候很有可能导致数值溢出NAN,发生错误。
至于为何这两种问题的解决对于深度神经网络学习中是重要的?这是因为梯度往往就是进行权重更新(训练)的依据,若发生梯度消失,神经网络的参数得不到有效的更新,模型迭代将会变得异常缓慢,甚至停滞不前。
4. 什么是激活函数?请列举至少三种不同的激活函数,并说明它们各自的特点。
答:直接从输入端分析激活函数,输入的是上一层各个神经元与之对应权值相乘累加的结果(w1*x1+w2*x2+....wn*xn),然后经过激活函数得到一个输出,其实也就是神经元上运行的函数。激活函数往往是用于赋予神经网络非线性的属性,所以激活函数一般也是非线性的。假设没有激活函数,神经网络,层与层之间就是简单的累乘相加,这将退化成为传统机器学习的感知机,只不过是多层感知机罢了。
Sigmoid函数
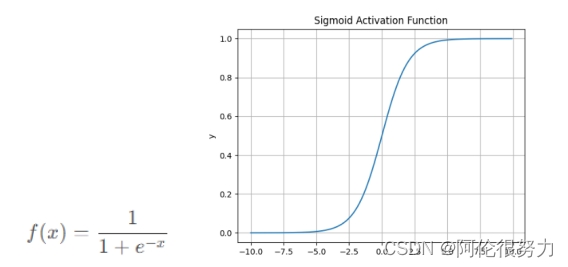
特点:函数的输出范围是 0 到 1,适合作为计算概率值比如用于表示二分类的类别或者用于表示置信度。梯度平滑,便于求导,也防止模型训练过程中出现突变的梯度。但是梯度值都小于0.25,容易发生梯度消失。
Tanh函数
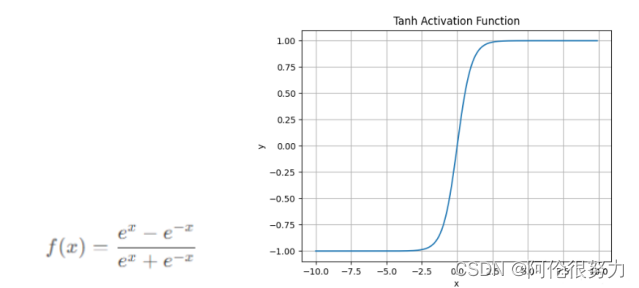
Tanh是“零为中心”的,负输入将被强映射为负,而零输入被映射为接近零。因此在实际应用中,Tanh会比Sigmoid更好一些。但是,Tanh还是没有解决梯度消失问题,而且依然是指数运算,资源消耗大。
ReLU激活
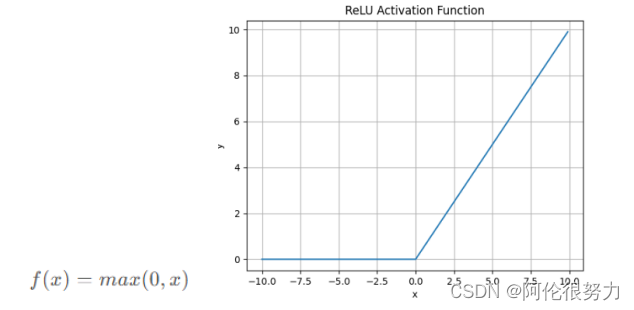
特点:ReLU解决了梯度消失的问题计算复杂度低,不需要进行指数运算,但是与Sigmoid一样,其输出不是以0为中心的。同时当输入为负时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
二 前馈神经网络
1. 什么是前馈神经网络,以及它是如何工作的?
答:前馈神经网络,顾名思义信息流的传播方向就是从前往后,它包括一个输入层,一个输出层,中间多个隐藏层。每一层都由多个神经元组成,每个神经元(神经元上是激活函数的处理)都要连接(连接上带有不同的权重)前一层的所有神经元,前一层的每个神经元的输出经过权重加和后输入当前的神经元。前馈神经网络的训练方式,通常采用前边所说的反向传播BP算法,进行权重的更新。
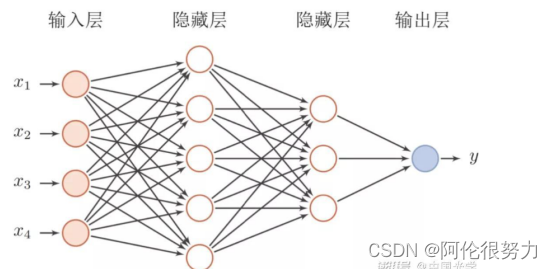
2. 解释什么是隐藏层?在前馈神经网络中增加隐藏层的数量有何影响?
答:隐藏层是神经网络中介于输入层和输出层之间的层,可能有多个,也可能只有一个,甚至没有,没有隐藏层的神经网络退化成为感知机。因为神经网络的黑盒性质,训练好的神经网络模型仅输入层和输出层对用户可见,隐藏层对于用户来说是透明的,故名字隐藏层。
如果在前馈神经网络中增加隐藏层的数量,首先带来的就是参数的增长,这就意味着需要更多的训练数据和训练时间;其次,大量的参数带来更加复杂的模型,也许可以在高维复杂问题上得到更好的表现;隐藏层数的增加,导致了梯度消失\爆炸发生可能性的增加,给模型训练带来风险。
3. 什么是反向传播?简述其工作原理。
答:反向传播BP算法,指的是神经网络训练模型参数的时候,根据模型当次的预测结果(由前向传播得到)和真实结果之间的差异(损失函数),利用链式法则得到网络中每个权重的梯度(计算方向是从后往前的),应用梯度下降法进行权重的更新,其中更新幅度涉及到学习率。
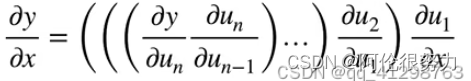
以下举个例子,具体说明如何进行反向传播更新权重:
首先是按照下图,进行前向传播,i1,i2是输入层的神经元,w1,w2等是权值,h1,h2,o1,o2等神经元所用的激活函数是Sigmod,下图详细展示了前向传播的计算过程,不在赘述。
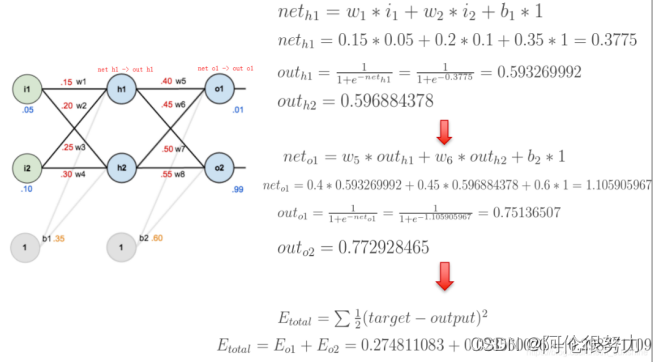
上图中的E_total就是误差,下面展示对w5反向传播过程:
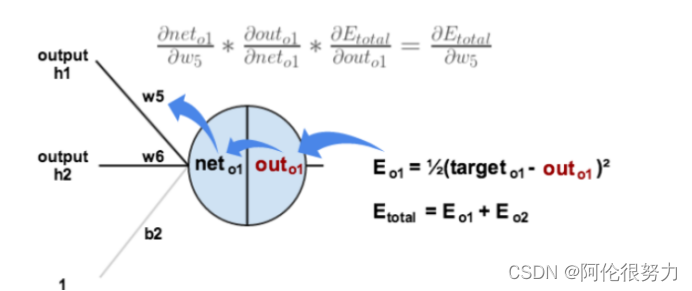
如前面所说的链式法则,放在此处的具体表达就是:
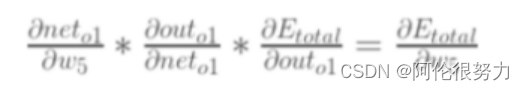
具体展开计算过程如下:
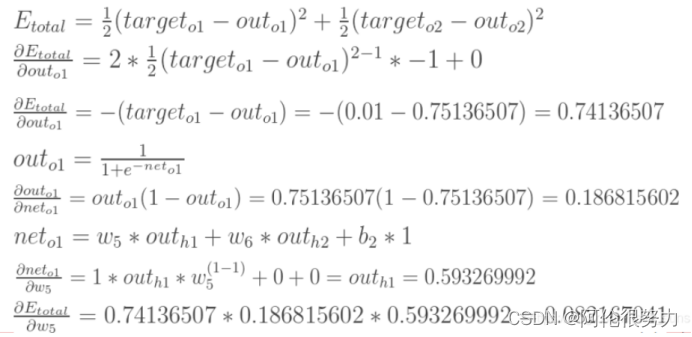
梯度算出来后,就可以进行权重的更新了,
![]()
![]() 是学习率,取0.5。
是学习率,取0.5。
![]()
这样就是对w_5的反向传播权重更新,别的同理。
CSDN上有个关于前向传播和反向传播的很形象的解释:
(1)前向传播:三个人在玩你画我猜的游戏,然后第一个人给第二个人描述,再将信息传递给第三个人,由第三个人说出画的到底是啥。
(2)反向传播:第三个人得知自己说的和真实答案之间的误差后,发现他们在传递时的问题差在哪里,向前面一个人说下次描述的时候怎样可以更加准确的传递信息。前一个人再向他的前一个人传递信息,就这样一直向前一个人告知。
(3)三个人之间的的默契一直在磨合,然后描述的更加准确。
注:以上图片来源于CSDN部分大佬博主,文字内容参考部分博客结合自己思考所得。
三 卷积神经网络(CNN)
1. 解释卷积层是如何工作的,并举例说明如何使用卷积层提取图像特征。
答:从输入和输出来理解卷积层,其实就是输入一个矩阵,在卷积层中,用卷积核去作用于这个矩阵,得到一个新的矩阵。
从左上角开始,卷积核就对应着数据的3*3的矩阵范围,然后相乘再相加得出一个值。按照这样的顺序,卷积核向右运动一个长度(步长为1的情况下),在重复上述过程,直到右边到头之后。下降一个长度(步长),再从左往右重复上述过程。这样之后就能得到一个新的矩阵作为卷积层的输出。
除此以外,还可以给卷积核设计不同的尺寸来构造属于自己的卷积层,比如步长,填充(可以用来保证原矩阵每个元素均匀的被使用,也能控制生成矩阵的大小),维度(也叫通道数)。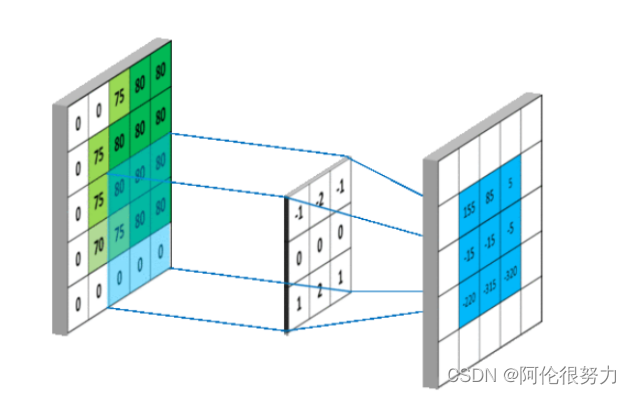
以下举个例子说明为何卷积操作可以提取图像特征(借鉴一篇知乎的文章能否对卷积神经网络工作原理做一个直观的解释? - 知乎 (zhihu.com))
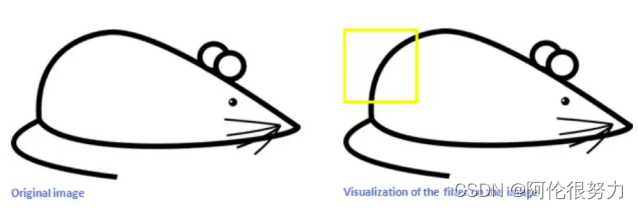
比如我现在要提取黄色框中的老鼠臀部曲线特征,那么如果只看黄色框中部分(右下图),那么我应该设计一个卷积核如左下图所示(白色的像素值为0,黑色为255,假设图像为单通道的)
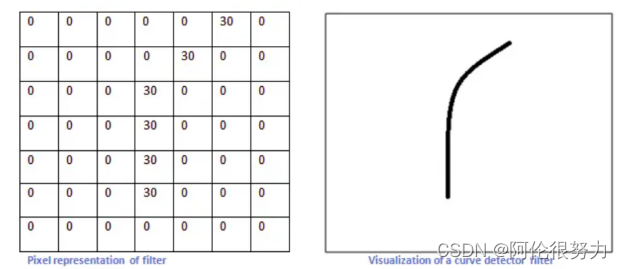
为什么要设计成这样的卷积核呢?因为用上面核作用到指定的黄色框区域时,按照卷积规则计算出来的值会很大,如下。
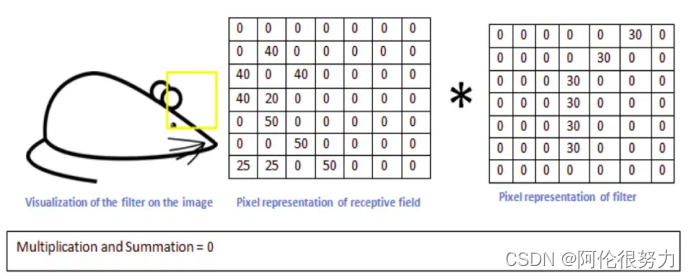
那么当卷积核运动到不是这个形状的区域时,进行卷积运算出来的结果就会很小。
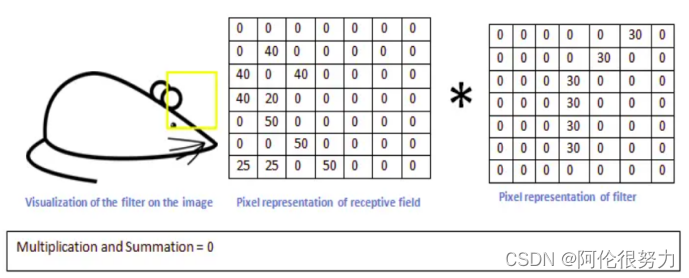
那么,这样就能很好的提取出原图的需要的特征位置了。
2. 解释卷积层、池化层和全连接层在卷积神经网络中各自的作用。
答:卷积层,这个是卷积神经网络的核心,如上题所述,卷积层最主要的功能就是特征提取,通过卷积核实现。
池化层,该层一般跟在卷积层的后面,最大的作用就是用于降低维度,这可以减少CNN的计算量,同时池化层也能用于特征的进一步提取,主要通过选择区域内的最大值(最大池化)或平均值(平均池化)。
全连接层,该层一般位于CNN的最后一层,将前面层级提取到的特征映射到最终的输出上,用于分类决策。
3. 为什么需要用卷积神经网络来处理图像问题?直接使用全连接网络有什么问题?
答:通过以下几个方面来对比下CNN和FCN在图像问题处理上的优劣。
一.参数数量和计算效率的问题。
对于FCN,假设一个图片的大小是W*H*D(W是宽,H是高,D是通道数),那么每个像素格作为一个输入,那么输入层的神经元个数就达到W*H*D 个,再算上其中神经元连接的权值,参数了将大的吓人,计算效率也将被拖累,而且效果可能不一定好。
对于CNN,利用卷积核进行类似于人眼的局部感受野,同时对于在某一卷积层,对同一个输入通过卷积核在原图像上的滑动共享同一个卷积核,这就大大减少了模型的参数量,计算效率也将得到提升。
二.局部感知能力。
对于FCN,由于输入的时候破坏了原图像的像素排列格式,这就给FCN识别像素之间的空间关系带来了挑战,因为按照图像中物体的规律,物体相关像素点应该是集中于某个部分的,FCN缺少了对这部分的考虑。
对于CNN,卷积核的卷积操作很好的考虑到了上述FCN所忽视的点,也更好的理解图像内容。
三.泛化性
对于FCN来说,同一张图片如果放大缩小,平移旋转,那么输出的结果很有可能会发生显著变化。
对于CNN来说,通过卷积层和池化层的搭配使用,CNN能够学习到平移不变性,即使图片发送上述改变,依然能正确识别。
四.层级结构的问题
RGB图像一般是三通道的
对于FCN来说,三层级的图像该如何输入呢?全部拆成线性排列,那么这样必定破坏图像原有的空间层级结构,从而影响最后的输出,
对于CNN来说,只需要拓展卷积核的维度,就能很好的解决。
五.端到端的学习
对于FCN来说,通常需要与手动设计的特征提取器结合起来使用,这就意味着特征学习和决策分类是分开的。
对于CNN来说,将全连接层放在网络的末尾,用来实现分类决策,输入是原图像像素数据,输出就是分类结果,无需额外步骤。
四 循环神经网络(RNN)
1. 什么是循环神经网络,以及它与前馈神经网络的主要区别是什么?
答:RNN是一种特殊的神经网络结构,它与FCN,CNN不同的是:它不仅考虑当前时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能。就像"人的认知是基于过往的经验和记忆"一样。
与前馈神经网络的区别就在于它的循环,具体的表现为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的(前馈神经网络,同一层的神经元之间是没有联系的),并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。如下的蓝色神经元之间靠W_s连接。
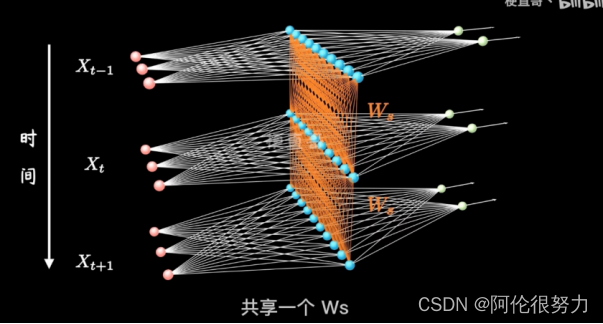
2. 什么是隐藏状态(hidden state)?它在循环神经网络中的作用是什么?
答:隐藏状态是指当前时间下某步骤的输入包括先前时间在该步骤的输出结果,也就是在同一尺度,不同时间维度下的信息。
隐藏状态是RNN的灵魂所在,作用在于允许RNN在处理序列数据时保持对先前信息的记忆。对于序列中的每个时间步,隐藏状态的更新都使用相同的权重矩阵(如第一题图中的W_s权重矩阵)。这意味着网络在处理整个序列时,会重复使用相同的参数来更新隐藏状态,从而实现参数共享。
3. 解释长短期记忆网络(LSTM)和门控循环单元(GRU)的基本原理和它们的用途。
答:首先是LSTM,这是基于RNN的变种,网络结构参考下图。
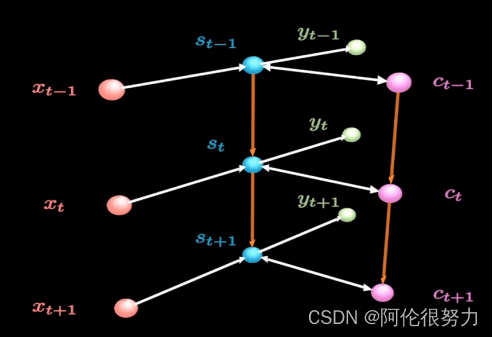
相比于RNN,LSTM增加了粉色部分的神经元,叫做long-term memory(长期记忆)。这样一来,要计算S_t的输出就变成了三个输入(X_t,S_t-1,C_t)。接下来看看,具体是网络的内部实现细节。
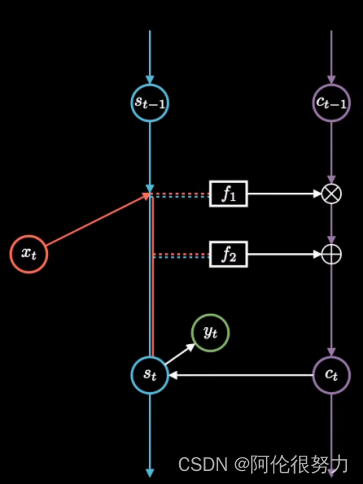
关键就是要弄明白新增加的long-term memory 是如何更新的。

关键在于f-1和f-2这两个函数,f-1利用的是sigmoid函数,介于0-1之间,这样矩阵元素相乘的时候会抹掉那些为0的元素,相对于选择性遗忘了部分记忆,由此 f-1也常被称作遗忘门,过滤重要特征,忽视无关信息。f-2则是利用到了sigmoid函数(再次对记忆进行选择)和tanh函数,取值在-1到1之间,相对于对过往记忆进行梳理归纳,所以f-2也被称作输入门。然后再按如下公式,更新C_t
![]()
以上就是LSTM相对于RNN增加的内容长期记忆,上述图片中的蓝色S神经元,也被称作短期记忆,保持两者的不断更新,相互作用,这就是LSTM成功的秘诀。
LSTM在自然语言处理(NLP),语言识别,时间序列预测方面都表现优异。
然后接下来分析GRU,GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。以下是一个GRU的示意图:

主要公式如下:
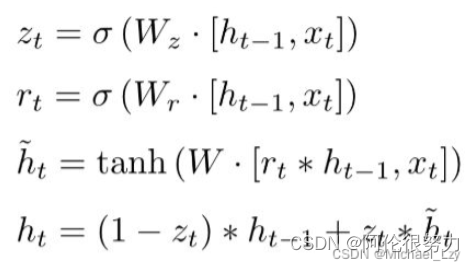
以上公式主要用于两个门 1)重置门,2)更新门
首先来看重置门:
这里W_r是一个权重矩阵。用这个权重矩阵对x_t和h_t-1拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入sigmoide函数,会得到r_t的值,该值用于下面公式的计算:
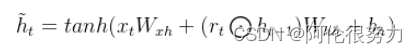
r_t的值越小,它与h_t-1哈达玛积出来的矩阵数值越小,再与权重矩阵相乘得到的值越小,![]()
也就是这个值越小,说明上一时刻需要遗忘的越多,丢弃的越多。
r_t的值越大, ![]()
值越大,说明上一时刻需要记住的越多,新的输入信息(也就是当前的输入信息)与前面的记忆相结合的越多。
当r_t的值接近0时,值也接近为0,说明上一时刻的内容需要全部丢弃,只保留当前时刻的输入,所以可以用来丢弃与预测无关的历史信息。
当r_t的值接近1时,值也接近为1,表示保留上一时刻的隐藏状态。
这就是重置门的作用,有助于捕捉时间序列里短期的依赖关系。
接下来看看更新门,更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,也就是更新门帮助模型决定到底要将多少过去的信息传递到未来,简单来说就是用于更新记忆。
更新门主要公式如下:
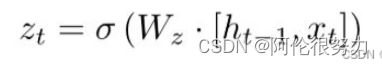
更新记忆表达式:
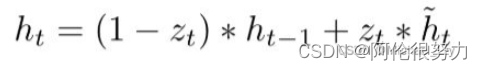
z_t越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。![]()
表示对上一时刻隐藏状态进行选择性“遗忘”。忘记h_t-1中一些不重要的信息,把不相关的丢弃。
表示对候选隐藏状态的进一步选择性”记忆“。会忘记 ![]()
中的一些不重要的信息。也就是对其中的某些信息进一步选择。
综上,该公式忘记传递下来的 h_t-1中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
门控循环单元GRU不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元。
GRU主要用途:
文本分类:GRU可以用于情感分析、主题分类等文本分类任务。
语音识别:GRU同样适用于处理语音信号,用于语音识别任务。
序列标注:在命名实体识别(NER)等序列标注任务中,GRU能够捕捉词与词之间的关系。
五 综合
1. 选取一个深度学习的应用案例(如图像识别、自然语言处理、声音识别等),描述使用哪种神经网络模型较为合适,并解释原因。
案例:图像识别
模型:卷积神经网络(CNN)
原因:
局部感知:CNN通过卷积层能够捕捉图像的局部特征,这使得它非常适合处理图像数据。
参数共享:卷积层中的权重在整个图像上共享,减少了模型的参数数量,降低了计算复杂度。
空间层级结构:CNN能够学习从简单到复杂的视觉模式,形成空间层级结构,这对于图像识别至关重要。
2. 在采用小批量随机梯度下降优化算法中,如何选择合适的批量大小?
在小批量梯度下降法中,批量大小(Batch Size)对网络优化的影响也非常大(主要表现在计算资源有限和模型参数巨大之间的矛盾)。一般而言,批量大小不影响随机梯度的期望,但是会影响随机梯度的方差。批量大小越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的学习率。而批量大小较小时,需要设置较小的学习率,否则模型会不收敛.学习率通常要随着批量大小的增大而相应地增大。一个简单有效的方法是线性缩放规则: 当批量大小增加m倍时,学习率也增加m倍。
3. 简述Adam算法中如何进行学习率调整和梯度估计修正的?
Adam结合了动量(Momentum)和RMSprop(Root Mean Square Propagation)两种算法的优点,通过计算梯度的一阶矩(即均值)和二阶矩(即方差)的指数衰减估计来调整每个参数的学习率。
学习率调整:
自适应学习率:Adam算法为每个参数维护各自的学习率,这是通过计算其梯度的一阶和二阶矩的运行平均值来实现的。
一阶矩估计(动量):计算梯度的指数加权平均值,类似于动量项,给快速变化的梯度提供惯性。
二阶矩估计(RMSprop):计算梯度平方的指数加权平均值,用于调整每个参数的学习率,类似于RMSprop,可以为每个参数提供单独的缩放。
学习率更新公式:最终的学习率是全局学习率乘以每个参数的自适应学习率。全局学习率通常由用户设置,而自适应学习率由算法动态计算。
梯度估计修正
偏差修正:Adam算法在计算一阶和二阶矩时使用指数衰减平均,这会导致偏差。为了修正这种偏差,算法在更新参数时对一阶和二阶矩进行了偏差校正。
一阶矩偏差修正:计算一阶矩时,使用![]()
进行校正,其中![]() 是一阶矩的衰减率,t是当前的迭代次数。
是一阶矩的衰减率,t是当前的迭代次数。
二阶矩偏差修正:计算二阶矩时,使用![]()
进行校正,其中![]() 是二阶矩的衰减率。
是二阶矩的衰减率。
更新规则:参数的更新规则是将当前参数减去全局学习率乘以偏差校正后的梯度。这个校正后的梯度提供了对参数更新方向和步长的自适应调整。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









