







机器学习中的五种学习范式:监督学习(Supervised Learning)、半监督学习(Semi-supervised Learning)、无监督学习(Unsupervised Learning)、自监督学习(Self-supervised Learning)、零样本学习(Zero-shot Learning)
文章目录
- 机器学习中的五种学习范式:监督学习(Supervised Learning)、半监督学习(Semi-supervised Learning)、无监督学习(Unsupervised Learning)、自监督学习(Self-supervised Learning)、零样本学习(Zero-shot Learning)
引言
在机器学习的发展历程中,根据数据标注的多少和学习方式的不同,形成了多种学习范式。本文将详细介绍监督学习、半监督学习、无监督学习、自监督学习和零样本学习这五种学习方法与相关的重要概念(已经标黄),分析它们的原理、应用场景、优缺点以及发展趋势。
1. 监督学习(Supervised Learning)
1.1 基本概念
监督学习是最传统也是应用最广泛的机器学习方法,其核心在于通过带有标签的训练数据来学习输入与输出之间的映射关系。
1.2 工作原理
- 训练数据:包含输入特征X和对应的标签Y
- 学习过程:通过最小化预测值与真实标签之间的误差来优化模型参数
- 预测:对新的未知数据进行预测
1.3 常见算法
- 分类算法:决策树、支持向量机(SVM)、随机森林、神经网络
- 回归算法:线性回归、岭回归、LASSO回归
1.4 应用场景
- 图像分类
- 语音识别
- 垃圾邮件过滤
- 疾病诊断
1.5 优缺点
优点:
- 性能通常较高
- 结果可解释性强
- 应用广泛
缺点:
- 依赖大量标注数据
- 标注成本高
- 容易过拟合
2. 半监督学习(Semi-supervised Learning)
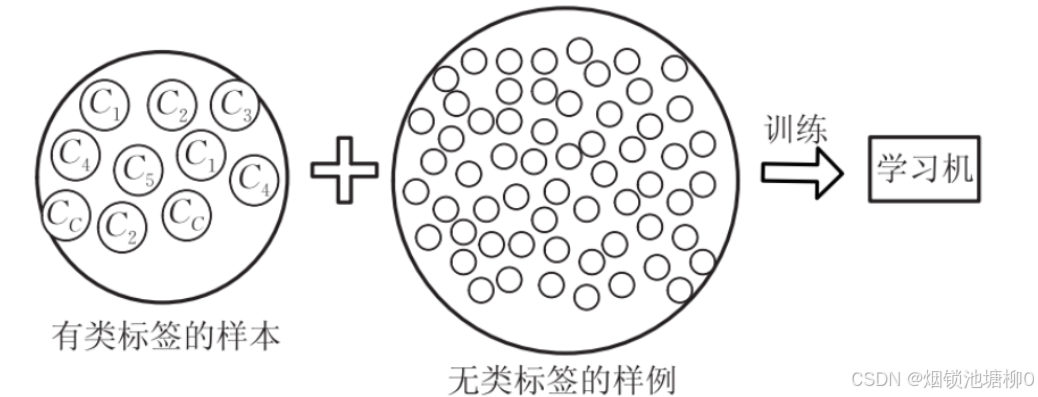
2.1 基本概念
半监督学习位于监督学习和无监督学习之间,它同时利用少量标记数据和大量未标记数据进行训练。
2.2 工作原理
- 利用少量标记数据训练初始模型
- 使用该模型对未标记数据进行伪标记
- 结合原始标记数据和伪标记数据继续训练模型
- 迭代优化直至收敛
2.3 分类
(这里的参考资料:一文看懂半监督学习(Semi-supervised Learning)和自监督学习(Self-Supervised Learning))
(1)归纳半监督学习(Inductive Semi-supervised Learning):
假定训练数据中的未标记样本并非待测的数据,而是用于提高模型泛化性能的额外信息
在训练时只使用训练数据,测试时面对的是全新的、从未见过的测试数据
目标是学习一个能够对未来新数据进行预测的通用模型
(2)直推半监督学习(Transductive Semi-supervised Learning):
假定学习过程中所考虑的未标记样本恰是待预测的数据,学习的目的就是直接对这些未标记样本进行分类
在训练模型时已经同时用到了训练和测试数据
直接将未标记样本作为预测对象,通过学习过程直接获得这些样本的标记
2.4 常见方法
- 自训练(Self-training)
- 协同训练(Co-training)
- 基于图的半监督学习
- 生成模型方法
2.5 应用场景
- 文本分类
- 医学图像分析
- 语音识别
- 网页分类
2.6 优缺点
优点:
- 减少标注数据需求
- 提高模型泛化能力
- 降低数据标注成本
缺点:
- 伪标签可能引入噪声
- 算法设计复杂
- 理论基础相对薄弱
3. 无监督学习(Unsupervised Learning)
3.1 基本概念
无监督学习不需要标记数据,它通过分析数据内在的结构和模式来发现数据中的规律。
3.2 工作原理
- 无需标签数据
- 通过数据的内在结构和分布特征进行学习
- 发现数据中的隐藏模式和关系
e.g. 一些数据集图片中有猫的图片也有狗的图片。
监督学习的训练数据是有标签的(有图,并且有与每一张图对应的“猫”与“狗”的答案),它的目的判断出给出的图片是猫还是狗。
无监督学习的训练数据是没有标签的(只有图,没有与每一张图对应的“猫”与“狗”的答案),它只需要判断出哪些图片是“第一类”,哪些图片是第二类就可以了。至于每一类具体是猫还是狗,这对于无监督学习来说不重要。
(这里的参考资料:一文弄懂什么是对比学习(Contrastive Learning))
3.3 常见算法
- 聚类算法:K-means、DBSCAN、层次聚类
- 降维算法:PCA、t-SNE、UMAP
- 异常检测:孤立森林、One-Class SVM
- 生成模型:VAE、GAN
3.4 应用场景
- 客户分群
- 异常检测
- 推荐系统
- 特征学习
3.5 优缺点
优点:
- 无需标注数据
- 可发现未知的数据模式
- 适用于探索性分析
缺点:
- 结果难以评估
- 性能通常不如监督学习
- 解释性较差
4. 自监督学习(Self-supervised Learning)
4.1 基本概念
自监督学习是一种特殊的无监督学习方法,它通过从数据本身自动生成监督信号,无需人工标注。其无需人工标注的特性也使得有人将其作为无监督学习的一种特殊形式。
4.2 工作原理
- 从原始数据中构造预测任务
- 数据本身提供监督信号
- 通过解决这些预测任务学习有用的特征表示
4.3 常见方法
- 对比学习(Contrastive Learning):SimCLR、MoCo、BYOL
对比学习(Contrastive Learning)是一种自监督学习方法,其核心思想是学习如何将相似的样本表示得更接近,而将不相似的样本表示得更远离。这种方法不需要大量的人工标注数据,而是通过数据本身的结构来学习有用的特征表示。
对比学习的基本原理涉及到以下几个概念:
正负样本对:对比学习通常基于正样本对(positive pairs)和负样本对(negative pairs)的概念。正样本对是指应该被视为相似的样本,而负样本对是指应该被视为不相似的样本。
表示学习:对比学习的目标是学习一个编码器(encoder),将输入数据映射到一个特征空间,使得正样本对在特征空间中的距离较近,而负样本对的距离较远。
对比损失函数:常用的对比损失函数包括NCE(Noise Contrastive Estimation)、InfoNCE、Triplet Loss等。
常见的对比学习方法
SimCLR:由Google提出,通过对同一图像的不同数据增强视图作为正样本对,其他图像作为负样本,学习视觉表示。
MoCo:由Facebook AI提出,引入了动量编码器和队列机制,有效地利用了大量的负样本。
CLIP:由OpenAI提出,通过对图像和文本的对比学习,实现了跨模态的表示学习。 CPC:在语音和时序数据领域的对比预测编码方法。
- 掩码预测:BERT、MAE
- 上下文预测:Word2Vec (这里的参考资料:自监督学习 | (1) Self-supervised Learning入门)
Word2vec 是在 NLP 领域中的一个重要的算法。Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。
P.S. 在图像处理领域也有类似的“上下文”操作:研究人员通过一种名为 Jigsaw(拼图)的方式来构造辅助任务。我们可以将一张图分成 9 个部分,然后通过预测这几个部分的相对位置来产生损失。比如我们输入一张图中的小猫的眼睛和右耳朵,期待让模型学习到猫的右耳朵是在脸部的右上方的,如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的。[1]
还有一种方式是:将图片中的随机的一部分删掉,然后利用剩余的部分来预测被删掉的部分,只有模型真正读懂了这张图所代表的含义,才能有效的进行补全。[2]
还有一种使用方式是针对图片的颜色信息的,比如给模型输入图像的灰度图,来预测图片的色彩。只有模型可以理解图片中的语义信息才能得知哪些部分应该上怎样的颜色,比如天空是蓝色的,草地是绿色的,只有模型从海量的数据中学习到了这些语义概念,才能得知物体的具体颜色信息。这个模型在训练结束后可以做这种图片上色的任务。[3]
- 生成式预训练:GPT系列
4.4 应用场景
- 大规模预训练语言模型
- 计算机视觉表示学习
- 多模态学习
- 语音识别预训练
4.5 优缺点
优点:
- 不需要人工标注
- 可利用海量未标注数据
- 学到的表示通常具有良好的迁移能力
缺点:
- 预训练任务设计需要专业知识
- 计算资源需求大
- 下游任务仍可能需要微调
5. 零样本学习(Zero-shot Learning)
5.1 基本概念
零样本学习是指模型能够识别或分类在训练过程中从未见过的类别,通过学习类别之间的语义关系来实现。
⚠ 请注意!有一组非常容易混淆的概念:
(1)Zero-shot Learning(零样本学习)
零样本学习是指模型能够识别或处理在训练过程中从未见过的类别或任务的能力。这种方法的核心思想是:
- 模型通过学习到的知识来泛化到新的、未见过的类别
- 不需要针对新任务或新类别提供专门的训练样本
- 通常依赖于类别之间的语义关系或属性信息
例如,一个经过训练的大型语言模型可以回答它在训练数据中从未明确学习过的问题,或者执行它从未专门训练过的任务,如翻译、摘要或代码生成。
(2)Prompt Tuning(提示词调优)
提示词调优又称指令微调,是一种轻量级的模型调整技术,主要应用于预训练语言模型。它的特点包括:
- 不修改模型的参数,而是通过优化输入**提示(prompt)**来提高模型在特定任务上的表现(
也就是我们日常所说的“调教AI”(bushi))- 比完全微调(fine-tuning)更加高效,需要的计算资源更少
- 可以为不同任务维护不同的提示词,而共享同一个基础模型
提示词调优的方法有多种,包括:
①连续提示词调优(Continuous Prompt Tuning):学习连续的、可优化的向量作为提示词
②离散提示词调优(Discrete Prompt Tuning):通过搜索或生成最佳的自然语言提示词
③前缀调优(Prefix Tuning):在输入序列前添加可训练的前缀向量
这两种技术在现代AI系统中都非常重要,特别是在大型语言模型(LLMs)的应用中。
其区别在于:零样本学习使模型能够应对新情况,解决模型泛化到新任务的问题;而提示词调优则提供了一种高效的方式来优化模型在特定任务上的表现,而无需完全重新训练模型(保持模型参数不变)。
5.2 工作原理
- 建立视觉特征与语义描述之间的映射
- 利用辅助信息(如类别属性或文本描述)
- 在测试时识别未见过的类别
5.3 常见方法
- 基于属性的方法
- 基于词嵌入的方法
- 生成式方法
- 大型语言模型的零样本能力
5.4 应用场景
- 稀有物种识别
- 新产品分类
- 跨语言任务处理
- 开放域问答
5.5 优缺点
优点:
- 能识别训练中未见过的类别
- 减少对标注数据的依赖
- 具有良好的泛化能力
缺点:
- 性能通常低于传统监督学习
- 需要高质量的辅助信息
- 领域适应性挑战大
6. 各学习范式的比较
| 学习范式 | 标注数据需求 | 计算复杂度 | 泛化能力 | 应用难度 |
|---|---|---|---|---|
| 监督学习 | 高 | 中 | 中 | 低 |
| 半监督学习 | 中 | 中-高 | 中-高 | 中 |
| 无监督学习 | 无 | 中 | 中 | 中-高 |
| 自监督学习 | 无(自生成) | 高 | 高 | 高 |
| 零样本学习 | 低(辅助信息) | 中-高 | 高 | 高 |
7. 未来发展趋势
- 多范式融合:不同学习范式的结合将成为趋势,如自监督预训练+少量监督微调
- 数据效率提升:减少对大规模标注数据的依赖
- 模型可解释性:增强模型决策过程的透明度
- 多模态学习:跨模态知识迁移与融合
- 持续学习:模型能够不断学习新知识而不遗忘旧知识
8. 总结
机器学习的不同学习范式各有优缺点,适用于不同的应用场景。随着技术的发展,这些方法之间的界限正变得越来越模糊,各种混合方法不断涌现。理解这些基本学习范式对于选择合适的机器学习方法解决实际问题至关重要。
希望这篇文章对你了解机器学习中的各种学习范式有所帮助!如果有任何问题,欢迎在评论区留言讨论🤓
参考文献
[1] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised Visual Representation Learning by Context Prediction. In ICCV 2015.
[2] Deepak Pathak et al. Context Encoders: Feature Learning by Inpainting. In CVPR 2016.
[3] Zhang, R., Isola, P., & Efros, A. A. Colorful image colorization. In ECCV 2016.


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









