







本文是自己学习对比学习的总结,如有问题,欢迎批评指正。
前言
有的paper将对比学习称为自监督学习(Self-supervised learning),有的将其称为无监督学习(Unsupervised Learning , UL)。自监督学习是无监督学习的一种形式。
自监督学习(Self-supervised learning)可以避免对数据集进行大量的标签标注。把自己定义的伪标签当作训练的信号,然后把学习到的表示(representation)用作下游任务里。
目的:学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同(通过代理任务引入更多的外部信息,以获得更通用(general)的表征)。
对比学习
首先要区分一下监督学习和无监督学习的区别。下图为两只猫和一只狗,监督学习的训练数据是有标签的,它的目的判断出下方图片是猫还是狗。而无监督学习的训练数据是没有标签的,它只需要判断出第一张和第二张是一类,第三张是一类就可以了!!!!!(至于图片描述的啥,对于无监督学习来说这不重要!)
将这三个图输入到一个神经网络中得到对应的特征向量f1、f2、f3。 在特征空间中f1,f2接近,f1,f3疏远(相似类别接近,不同类别疏远),如果不明白可以先看一下Embedding。为什么要说这个呢?以最左边的猫的图片为例,我们对其进行简单变换(平移、旋转等)得到两个新图(当然这两张图片还是猫!!没有变成狗!!对吧?),这两张新图对应的特征向量,
在特征空间中接近,或者说相似度很高。生成新图,通过编码器将它们转化成Embedding向量,训练使
,
接近,
,
疏远这个过程就是对比学习是无监督的!!,可以看出这个编码器是很关键的,它没有因为图片的变动,而把它编码成狗。那这有什么用呢?这可以作为一个pretext,当我们拥有的数据中不带标签的数据要远远大于带标签的数据的时候,我们可以用不带标签的数据进行对比学习的一个初始编码器,此编码器已经掌握了数据中的一部分特性,可以实现聚类功能,然后在用带标签数据进行微调。



对比学习的典型范式就是:代理任务+目标函数。下图为谷歌2020年谷歌(论文:A Simple Framework for Contrastive Learning of Visual Representations)提出的一个对比学习通用框架。
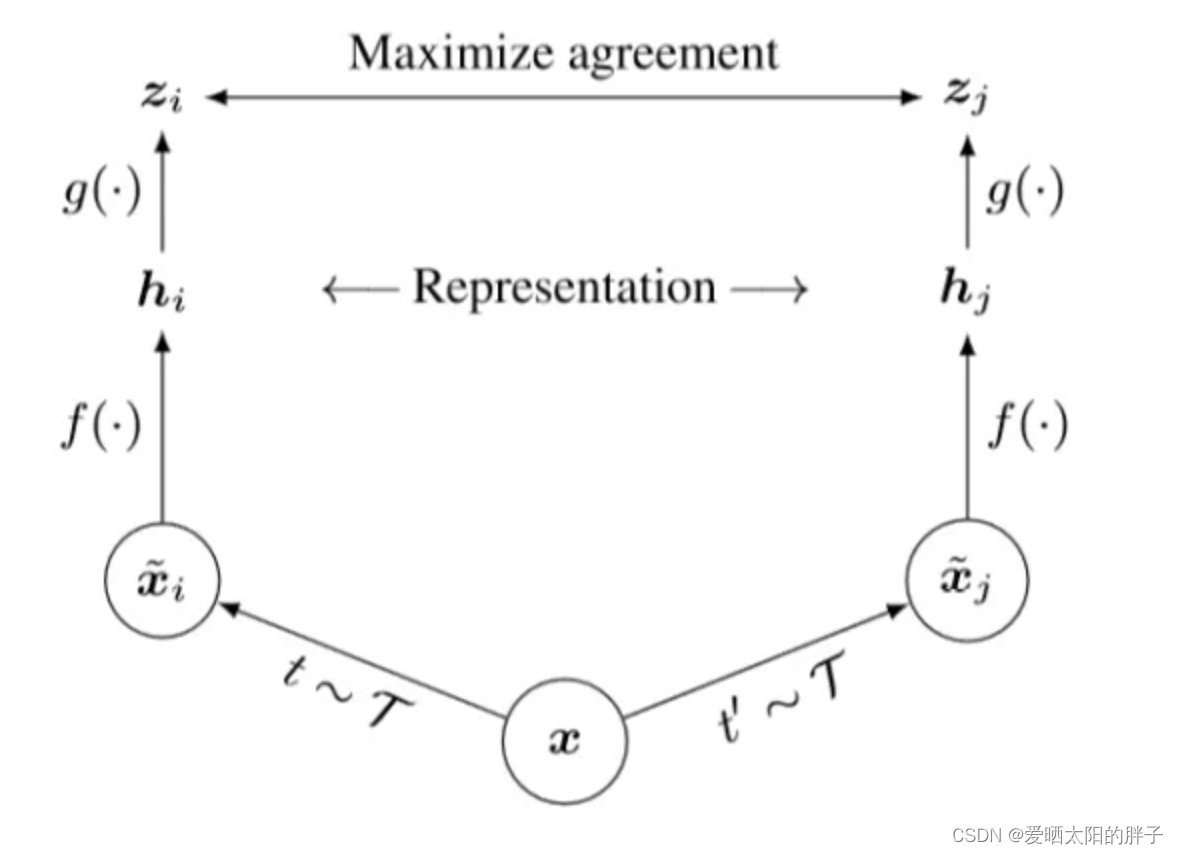
- 数据增强(代理任务)。对于同一样本
,经过数据增强生成
和
两个样本,simCLR属于计算机视觉领域的paper,例如图片的随机裁剪、随机颜色失真、随机高斯模糊。
- 特征提取编码器。
(⋅)就是一个编码器,用什么编码器不做限制。
和
可理解为embedding向量。
(MLP层)。SimCLR中强调了这个MLP层加上会比不加好。
- 目标函数作用阶段。对比学习中的损失函数一般是infoNCE loss(如下图二所示)
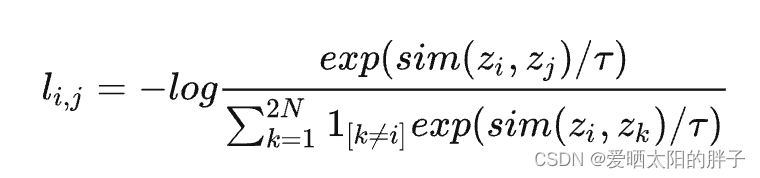
其中,N代表的是一个batch的样本数,即对于一个batch的N个样本,通过数据增强的得到N对正样本对,此时共有2N个样本,负样本是什么?SimCLR中的做法就是,对于一个给定的正样本对,剩下的2(N-1)个样本都是负样本,也就是负样本都基于这个batch的数据生成。论文使用的是余弦相似度,负样本只出现在分母上,可见要使损失最小,则正样本相似度必须大,负样本相似度必须小。















 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









